Temperature 和 Top-p 到底在调什么?从大模型生成原理讲清楚这两个参数
很多人第一次注意到 temperature 和 top-p,并不是在论文里,而是在产品界面里。比如在 Google AI Studio 的 Run settings 面板中,就可以直接调整 model parameters;如果你改用 Gemini API,也会在里看到topP这样的字段。也就是说,这两个参数不是学术讨论里的边角料,而是今天实际调用大模型时就摆在开发者面前的“生成控制旋钮”。问题也
很多人第一次注意到 temperature 和 top-p,并不是在论文里,而是在产品界面里。比如在 Google AI Studio 的 Run settings 面板中,就可以直接调整 model parameters;如果你改用 Gemini API,也会在 generationConfig 里看到 temperature、topP 这样的字段。也就是说,这两个参数不是学术讨论里的边角料,而是今天实际调用大模型时就摆在开发者面前的“生成控制旋钮”。问题也因此很自然:它们到底在控制什么,为什么只改一个小数,模型的输出风格就会明显变化?
大模型的结构
要回答这个问题,先别急着上复杂公式。把大模型先看成一个“预测下一个词”的系统就够了。你给它一句话开头,比如“今天天气真”,模型不会直接在内部想出一整句完整答案,而是会先看上下文,然后对词表里所有可能接在后面的 token 打分。这个“打分”不是我们平时说的概率,而更像是模型对每个候选词的偏好强弱。Transformer 的经典论文里也明确写到,解码器输出会经过一个线性变换,再经过 softmax,最终变成“下一个 token 的预测概率”。所以从最朴素的直觉看,大模型生成文本其实就是一条很简单的链路:先算分数,再把分数变成概率,最后从这些概率里选一个 token 出来。
如果再把这条链路说得更形象一点,可以把它理解成三个动作。第一步,模型根据前文给每个候选 token 打一个“倾向分”;第二步,这些分数经过 softmax,被压成总和为 1 的概率分布;第三步,系统按这个分布做一次采样,选出真正要输出的那个 token。选完以后,这个 token 会被接回原句,成为新的上下文,模型再重复同样的过程。因此,大模型并不是“一次性写完全文”,而是在不断重复“评分—变概率—抽取”的循环。
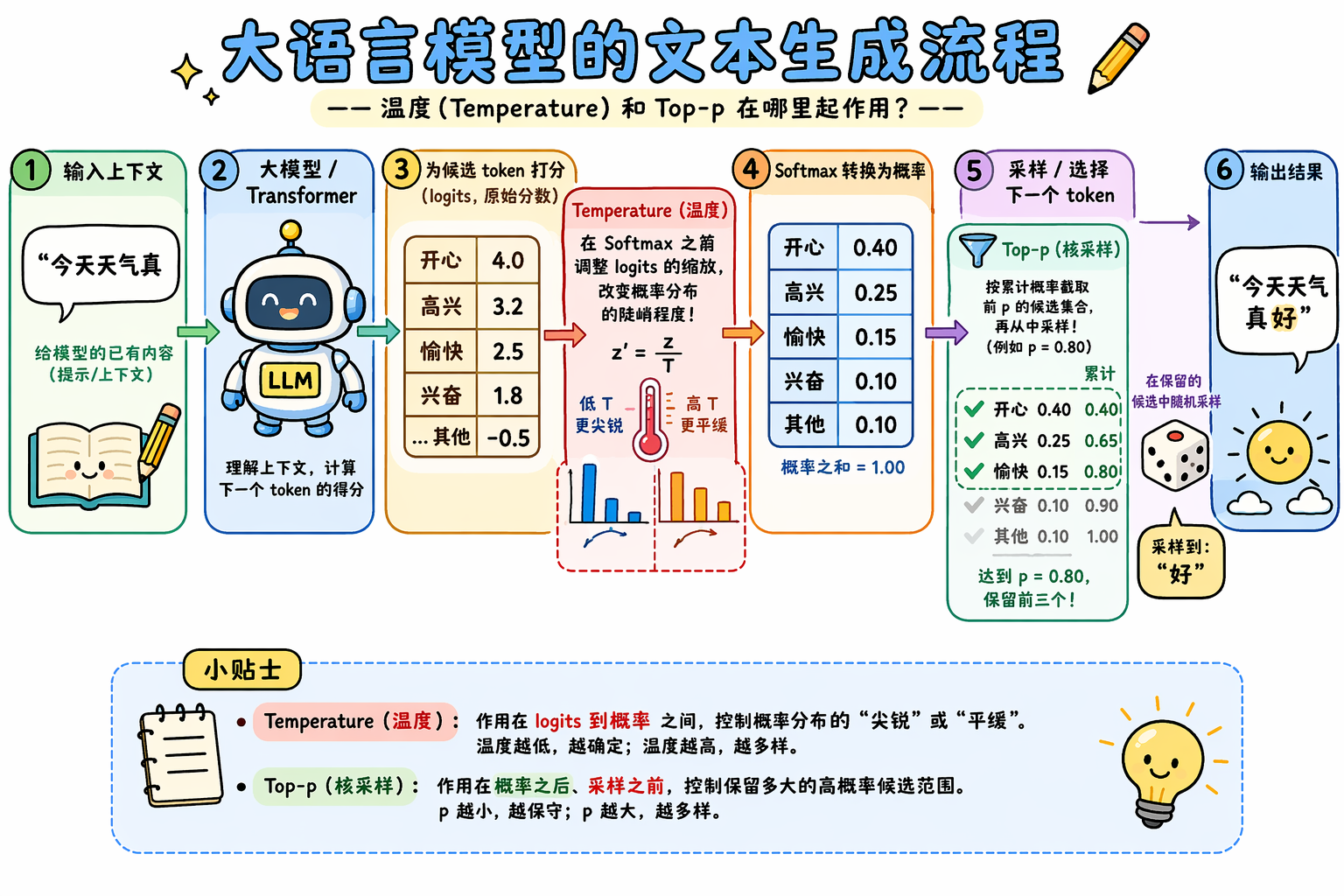
Temperature 的公式作用
上面这条链路里,temperature 起作用的位置,正好就在“分数变概率”这一步。假设模型对所有候选 token 给出的原始分数是 z1,z2,…,znz_1, z_2, \dots, z_nz1,z2,…,zn,这些分数通常叫做 logits。如果不加 temperature,那么 softmax 之后第 iii 个 token 的概率就是:
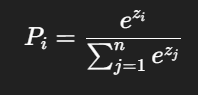
而引入 temperature TTT 之后,公式会变成:
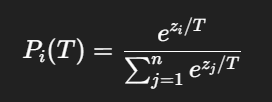
也就是说,temperature 并不是在 softmax 后面再随便调一下概率,而是在进入 softmax 之前,先把所有 logits 都除以一个 TTT。这一步看起来只是一个简单的缩放,但会直接改变整个概率分布的形状。
如果 T=1T=1T=1,那么公式和原始 softmax 完全一样,temperature 不产生额外影响。如果 T<1T<1T<1,例如 T=0.5T=0.5T=0.5,那么每个 logit 都会被“放大”一倍。原本大的分数会变得更大,原本小的分数会变得更小,于是 softmax 输出的概率分布会更尖锐,最高概率 token 的优势会被进一步拉大,模型就更倾向于选择最稳妥、最确定的答案。相反,如果 T>1T>1T>1,例如 T=1.5T=1.5T=1.5 或 T=2T=2T=2,那么 logits 会被压缩,分数之间的差距被缩小,最后得到的概率分布会更平缓,原本概率较低的 token 也更有机会被采样到,模型输出就会更发散、更多样。
这个过程可以用一个简单例子直观看出来。假设某一步只有两个候选 token,它们的 logits 分别是 4 和 2。
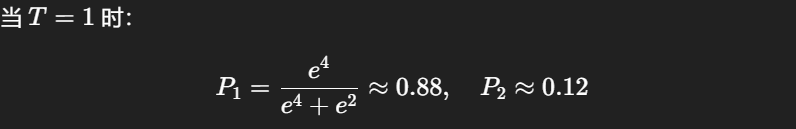

这时概率高度集中在第一个 token 上,输出会非常保守。
而当 T=2T=2T=2 时,相当于 logits 变成 2 和 1:

可以看到,第二个 token 的机会明显变大了,模型更愿意尝试“不那么标准但也合理”的选项。
所以从公式本质上说,temperature 做的事情可以概括为一句话:它通过缩放 logits,来控制 softmax 之后概率分布的尖锐程度。 低 temperature 让分布更尖,高 temperature 让分布更平。前者更偏向确定性输出,后者更偏向多样性输出。它并不改变模型“认为谁最好”的排序,但会改变“最好和次好之间到底差得有多大”,而这正是它能显著影响生成风格的根本原因。
Top-p 是什么
如果说 temperature 主要是在调“概率分布的陡峭程度”,那么 top-p 更像是在调“模型到底允许自己在多大的候选范围里做选择”。
前面说过,大模型会先给所有候选 token 打分,再通过 softmax 变成一组概率。到了这一步,其实词表里每个 token 都有一个概率,只是有的很高,有的几乎可以忽略不计。top-p 做的事情,就是先把这些 token 按概率从高到低排好,然后只保留前面那一部分“最有可能的候选”,直到它们的累计概率达到设定的阈值 ppp。
可以把它写成一个很简单的形式。假设排好序后的概率是:
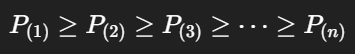
那么 top-p 会取前面最小的一组 token,使得它们的累计概率满足:
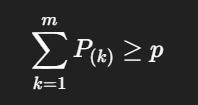
这其实就够了。它表达的意思很直白:模型不会从整个词表里随便选,而是只会在“最有希望”的那一小部分候选里继续抽样。
比如某一步里,模型算出来几个候选词的概率分别是:
“开心” 0.40,
“高兴” 0.25,
“愉快” 0.15,
“兴奋” 0.10,
“雀跃” 0.05,
其他词加起来 0.05。
如果这时候 top-p 设成 0.8,那么系统只需要保留前四个词,因为它们的累计概率已经达到:
0.40+0.25+0.15+0.10=0.900.40 + 0.25 + 0.15 + 0.10 = 0.900.40+0.25+0.15+0.10=0.90
后面的“雀跃”和其他更小概率的词,就直接不参与这次采样了。也就是说,top-p 不会去改变“开心”和“高兴”谁更可能,它只是先划定一个范围:模型这一步只能在这些相对靠谱的候选里选,别跑得太远。
所以从直觉上看,top-p 控制的是候选池大小。
ALL IN ALL
所以,从原理上看,temperature 和 top-p 并不是在改变模型“知道什么”,而是在改变模型“怎么从自己知道的东西里说出来”。它们不决定模型是否懂你的问题,更多决定模型在输出时是偏向唯一最优解,还是愿意在一小片合理答案之间进行探索。前者更像“把最可能的话说出来”,后者更像“在合理范围内允许一些变化”。对于写代码、抽取信息、做结构化问答这类任务,通常会更偏向低随机性;而对于文案、创意写作、头脑风暴这类任务,则更可能需要更宽松的采样空间。Google 的文档也把 temperature 明确归为 response generation 时控制随机性的参数,把 top-p 定义为控制候选 token 累计概率范围的参数。
回到一开始的问题:为什么在 Google 的界面里,你只是改了两个小数,回答风格就像换了个人?答案就是,这两个参数正好卡在大模型生成链路里最敏感的那一截——“最后到底选哪个 token”。模型前面的大部分计算,负责形成一个可能答案的概率地形图;而 temperature 和 top-p,决定的是你要在这张地形图上走得多稳、多窄,还是多活、多开。理解了这一点,再去看这些参数,就不会觉得它们只是调节“创造力”的神秘旋钮,而会知道:它们其实是在直接干预大模型的采样机制。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)