Claude Opus 4.7 正式发布,编程能力大幅提升,创始人已经不看代码过程了!
Auto mode、Recaps、Focus mode、effort level 这些功能加在一起,指向的是同一个方向:让你花更少的时间盯着终端,花更多的时间在真正需要人类判断的事情上。Agentic search(BrowseComp)拿了 79.3%,反而比 Opus 4.6 的 83.7% 低,也低于 GPT-S.4 的 89.3%。4.7 在这方面做了优化,对于写 system promp
昨天我们刚聊了 "Opus 4.7 最快本周见",结果当晚 Anthropic 就官宣了。速度比预想的还快。
这次不是挤牙膏式的小更新。从跑分数据到实际体验,Opus 4.7 在编码能力上的提升非常明显,Claude Code 也跟着加了一波新功能。更重要的是,Claude Code 创始人 Boris Cherny 第一时间分享了 6 个实用技巧,直接告诉你怎么把 4.7 的能力榨干。
下面一个一个说。
跑分:编码指标全面拉升
先看硬数据。
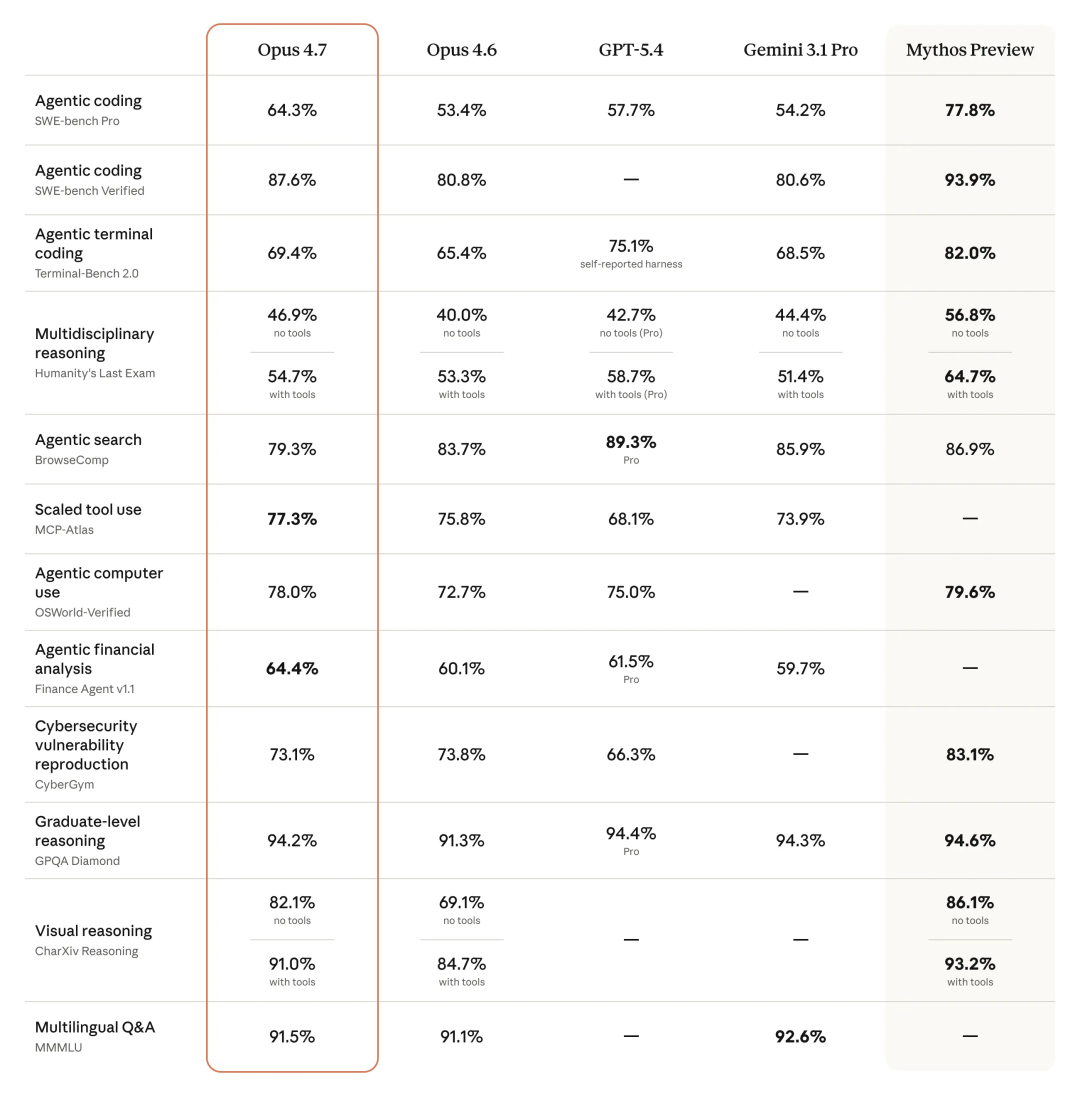
SWE-bench Pro(衡量 Agent 自主解决真实 GitHub issue 的能力):Opus 4.7 拿到 64.3% ,Opus 4.6 是 53.4%,将近 11 个百分点的跳跃 。同场竞技的 GPT-5.4 是 57.7%,Gemini 3.1 Pro 是 54.2%,都被拉开了距离。
SWE-bench Verified 上更夸张,直接到了 87.6% 。
第三方实测数据也在印证这个趋势。 Cursor CEO Michael Truell 说 CursorBench 得分从 58% 涨到 70%,是他们编码基准上"最清晰的一次跳跃"。Rakuten 的生产任务解决量 提升了 3 倍 。CodeRabbit 代码审查的召回率 提高了 10% 以上 。
Warp 创始人 Zach Lloyd 提到一个很有意思的细节:之前 Opus 4.6 搞不定的并发 bug,4.7 直接给破了。 Devin CEO Scott Wu 的评价是,Opus 4.7 可以"连贯工作数小时",深度调查能力有了质的飞跃。
其他领域的反馈也值得一看。 Scale AI 首席产品官 Mario Rodriguez 说编码基准提升了 13%,其中包含 4 个前代模型完全无法解决的任务。 Notion AI 负责人 Sarah Sachs 的数据很具体:多步工作流提升 14%,工具调用错误 减少了三分之一 。 Stripe 技术副总裁 Clarence Huang 表示 Opus 4.7 正在加速他们的开发交付周期。 Databricks CTO Hanlin Tang 反馈文档推理错误减少了 21%,在企业级分析任务上表现拉满。做安全方向的 Qodo CEO Itamar Friedman 提到,Opus 4.7 通过了 3 个 TBench 测试任务,还识别出了竞争对手遗漏的问题。
不过也要说实话, Mythos Preview 在多项指标上依然压着 Opus 4.7 ,比如 SWE-bench Verified 拿到了 93.9%,Agentic terminal coding 是 82.0%。所以 Opus 4.7 不是全场最强,但在 Anthropic 的产品线里,确实是一次大跳步。
Claude Code 创始人的 6 个实用技巧
Boris Cherny 说他过去几周一直在用 Opus 4.7 做日常开发,"生产力提升明显"。他总结了 6 条上手建议,每条都很实在。
1. 开 Auto mode,告别权限弹窗
Opus 4.7 擅长的就是长时间跑复杂任务,比如深度调研、重构代码、构建完整功能模块,一边迭代一边自我验证直到达标。以前跑这种任务你得一直盯着它弹权限确认框,现在切到 Auto mode(快捷键 Shift+Cmd+M,选 3)就行了。模型自己跑,你只看结果。
2. 用 /fewer-permission-prompts 减少打扰
这是一个新上的 skill。它会扫描你的历史会话,找出那些反复弹权限确认但实际上很安全的 bash 命令和 MCP 调用,然后推荐你把这些命令加到允许列表里。跑一次就能省掉后续大量的重复确认。
3. Recaps:离开一会儿,回来快速接上
这是为了配合 Opus 4.7 专门做的功能。当 Agent 跑了好几分钟甚至几个小时的长任务,你中间去干别的事了,回来看到一屏幕日志不知道从哪接上。Recaps 会给你一段简短的摘要:它做了什么,下一步是什么。比如 "Fixing the post-submit transcript shift bug. The styling-flash part is shipped as PR #29869",一目了然。
4. Focus mode:只看结果,不看过程
Boris 说他现在越来越信任模型的中间操作了。Focus mode 就是把 CLI 里所有中间步骤都藏起来,只展示最终结果。 "模型已经到了一个让我信任它去跑对的命令、做对的修改的阶段,我只看最终结果就行了。" 这句话从 Claude Code 创始人嘴里说出来,分量不小。
5. 调节 effort level,在速度和智力之间找平衡
Opus 4.7 用的是 adaptive thinking(自适应思考),不再是固定的 thinking budget。你可以通过 effort level 来控制它想多久。从 low 到 max 一共五档,新增的 xhigh 档位在 high 和 max 之间,适合那些"需要深度思考但又不想等太久"的场景。简单任务用 low 或 medium 省 token,复杂任务拉到 xhigh 或 max 让它想透。
6. 给 Claude 一个验证自身工作的方式
Boris 强调,这一条一直都很重要,但到了 4.7 更加关键。你要确保 Claude 有办法检查自己干的活对不对。后端任务就让它跑测试,前端任务就让它截图对比,数据任务就让它跑校验脚本。做到这一点,产出质量 能提升 2-3 倍 。
视觉和其他能力升级
编码之外,还有几个值得关注的点。
视觉分辨率翻了 3 倍多。 最长边支持到 2,576 像素,大约 375 万像素。XBOW 视觉准确率从 54.5% 飙升到 98.5% 。对于需要截图分析 UI、读取文档内容的开发场景来说,这个提升很实用。 Vercel CEO Aj Orbach 称赞 Opus 4.7 在仪表板和数据界面构建上的表现"是目前见过最强的"。
指令遵循更精确了。 之前的模型有时候会"宽松解释"你的指令,你说 A 它理解成 A'。4.7 在这方面做了优化,对于写 system prompt、搭 Agent 工作流的开发者来说,意味着更少的调试和更可预期的输出。
Task budgets(任务预算)进入公测。 你可以给一次任务设定 token 消耗上限,让模型在预算内自主规划。跑 Agent 任务的时候,成本更可控。
Claude Code 新增 /ultrareview 命令。 启动一个专门的代码审查会话,通读你的所有改动,像一个认真的 reviewer 一样指出问题。
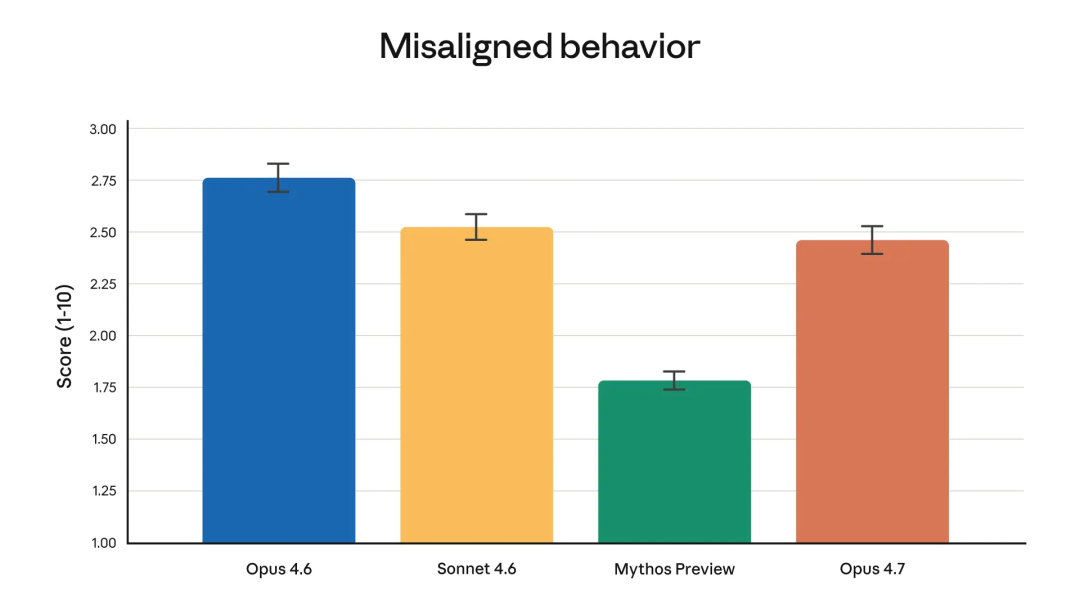
需要注意的地方
两个点要提前知道。
第一,Opus 4.7 换了新的分词器,同样的输入文本 token 数量可能增加 1.0 到 1.35 倍 。虽然官方说净收益为正,但对 token 成本敏感的应用需要提前评估。
第二,Opus 4.7 并不是所有维度都领先。Agentic search(BrowseComp)拿了 79.3%,反而比 Opus 4.6 的 83.7% 低,也低于 GPT-S.4 的 89.3%。多学科推理 54.7% 对比 GPT-S.4 的 58.7% 也不占优。 它的强项非常明确:编码、视觉、工具调用。 在知识推理和搜索类任务上,竞争对手并不差。
定价和可用性
价格没变,输入
25/百万 token,和 Opus 4.6 一样。API 模型 ID 是 claude-opus-4-7。
已经在 claude.ai、Claude Platform、Amazon Bedrock、Google Cloud Vertex AI 和 Microsoft Foundry 上全面可用。
写在最后
从昨天的爆料到今天的正式发布,Anthropic 的节奏越来越快。2 月份 Opus 4.6,4 月份 Opus 4.7,两个月一个大版本。SWE-bench Pro 从 53.4% 到 64.3%,视觉准确率直接翻倍。
Boris Cherny 在推文最后说了一句话,我觉得挺准确的: "用老的工作流,Opus 4.7 是一个不错的提升;但如果你愿意调整工作流去适应它更长时间运行、更 agentic 的特性,它就是一个显著的飞跃。"
对于每天用 Claude Code 写代码的开发者来说,这次升级值得认真对待。不只是模型变强了,更重要的是工具链也在跟着进化。Auto mode、Recaps、Focus mode、effort level 这些功能加在一起,指向的是同一个方向:让你花更少的时间盯着终端,花更多的时间在真正需要人类判断的事情上。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 9
9 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)