刚刚Opus 4.7发布,相比4.6核心变化,与Claude Code搭配最佳实践
中提到过,两项变化会影响 token 用量,一是更新了 tokenizer,二是模型在更高 effort 等级下,尤其是在更长会话的后续轮次中,更倾向于进行更多思考。Opus 4.7 的 token 用量和行为表现,会因为你的部署方式不同而变化,尤其取决于你是在运行单轮输入、更加自主且异步的编码智能体,还是多轮交互、同步配合的编码智能体。与 Opus 4.6 相比,它更擅长处理模糊问题,在找 bu
Claude Opus 4.7 正式发布:
Anthropic 今天发布了 Opus 4.7。定价与 4.6 持平(每百万 Token 为 $5 / $25),现已在 API、Amazon Bedrock、Google Vertex AI 和 Microsoft Foundry 同步上线。
相比 Opus 4.6 的核心变化:
- 编程能力(显而易见的提升): 在最复杂、长周期的软件工程任务中进步最大。早期测试者反馈,现在可以将以前需要人工监督的工作直接交给它。Opus 4.7 现在会在提交结果前自行验证输出。
- 视觉能力: 支持长边最高 2,576px(约 375 万像素)的图像,比以往任何版本的 Claude 提升了 3 倍以上。这对于需要读取密集截图和提取图表的“电脑操作智能体(Computer-use agents)”来说是真正的杀手锏。
- 指令遵循: 现在会非常“字面化”地解读指令。Anthropic 明确警告:针对 4.6 优化的提示词(Prompts)可能会失效或产生非预期输出。现有的测试框架需要重新调优。
- 记忆力: 在跨多会话的长程工作中,基于文件系统的记忆处理能力更强。
- 现实世界知识工作: 在 Finance Agent(金融智能体)评测和 GDPval-AA(针对金融、法律等高经济价值知识工作的第三方评测)中达到了行业领先水平(SOTA)。
今日上线的新功能:
- 新增
xhigh努力等级: 介于 high 和 max 之间。允许用户在“推理深度”与“响应延迟”之间进行更精细的控制。Claude Code 现已将所有方案的默认值设为xhigh。 - 任务预算(Task budgets): API 端开启公开测试。
- Claude Code 中的
/ultrareview: 专属的审查模式,用于标记 Bug 和设计缺陷。Pro 和 Max 用户拥有 3 次免费额度。 - 自动模式(Auto mode)扩展: 现已面向 Claude Code Max 用户开放。Claude 可以代表你做出决策,减少干扰,且风险低于“完全跳过权限确认”。
坦诚的注意事项(Caveats):
- 新分词器(Tokenizer): 同样的输入内容,Token 消耗会增加 1.0 到 1.35 倍,具体取决于内容类型。
- 思考成本: 在高努力等级下,Opus 4.7 会思考得更久,尤其是在智能体多轮对话的后期,输出的 Token 数量会更多。
- 安全概况: 与 4.6 大致持平。提升了诚实度和抗提示词注入(Prompt Injection)的能力,但在受控物质的伤害减少建议方面,规避机制略微变弱。
- 定位: 能力依然弱于 Claude Mythos Preview(符合预期),后者仍处于 Anthropic 的限量发布阶段。Opus 4.7 是网络安全保护措施的“试验场”,这些技术最终将支持 Mythos 的大规模推广。
总结:相对于 4.6,这是一次极具意义的升级,精准击中了 Anthropic 核心客户群最在意的三个痛点:Agent 编程的可靠性、电脑操作 Agent 的视觉能力,以及 GDPval-AA 等知识工作基准表现。
虽然明显逊色于 Mythos,但依然是一个非常扎实的迭代更新!
Claude Code 负责人 Boris Cherny 也总结了关于 Opus 4.7 的重磅更新!这次更新的核心在于增强了模型的 Agent(代理)能力,让它能更自主地处理长期任务。
1/ 自动模式 = 告别权限弹窗
Opus 4.7 非常擅长处理复杂且耗时长的任务,例如深度调研、代码重构、构建复杂功能,以及持续迭代直到达到性能基准。
在过去,当模型执行此类长任务时,你只有两种选择:要么像“当保姆”一样守在旁边盯着它运行,要么就得冒风险使用 --dangerously-skip-permissions(危险:跳过权限确认)参数。
我们最近推出了“自动模式”(Auto mode)作为一种更安全的替代方案。 在这种模式下,所有的权限请求都会被路由到一个基于模型的分类器,由它来判定该命令是否可以安全运行。如果判定安全,系统就会自动批准执行。
这意味着当模型运行时,你再也不需要守在旁边。 不仅如此,这还意味着你可以并行运行多个 Claude 实例。一旦其中一个 Claude 开始进入状态(cooking),你就可以把注意力转向下一个。
自动模式现已面向 Max、Teams 和 Enterprise 用户开放,支持 Opus 4.7。
- CLI: 按
Shift-tab即可进入自动模式。 - 桌面版或 VSCode: 在下拉菜单中选择即可。
2/ 新技能:/fewer-permission-prompts
我们还发布了一项名为 /fewer-permission-prompts 的新技能。 它会扫描你的会话历史,识别出那些本质安全、但在执行时会反复触发权限弹窗的常用 bash 和 MCP 命令。
随后,它会为你推荐一个清单,建议你将这些命令添加到权限的白名单 (allowlist) 中。
你可以利用这个功能来精细化调整权限设置,避免不必要的干扰——特别是如果你不打算开启“自动模式 (auto mode)”的话,这个功能尤为实用。
3/ 内容回顾(Recaps)
为了给 Opus 4.7 的发布铺路,我们本周早些时候上线了 Recaps(回顾)功能。 Recaps 是对 Agent 已完成工作和后续计划的简短总结。
当你离开一个长时间运行的会话,几分钟或几小时后再回来查看进度时,这个功能极其好用。
4/ 专注模式(Focus mode)
我最近非常喜欢 CLI(命令行界面)中新增的“专注模式”。 它会隐藏所有的中间执行过程,让你完全专注于最终结果。
目前的模型已经进化到了这样一个阶段:我基本上可以放心地信任它能运行正确的命令并进行准确的修改。我只需要关注最终的产出。
使用 /focus 命令即可切换开启或关闭。
5/ 配置你的“努力程度”(Effort level)
Opus 4.7 采用了“自适应思考”机制,而非固定的“思考预算”。 如果你想微调模型的思考深度,我们建议调整 Effort(努力程度)。
- 低 Effort: 响应速度更快,token 消耗更低。
- 高 Effort: 获得最顶尖的智能水平和执行能力。
我个人在大多数任务中会使用 xhigh(极高),而在处理最棘手的任务时会开启 max(最高)。需要注意的是,max 级别仅对当前会话生效;而其他的 Effort 级别具有“粘性”,设置后会延续到你的下一个会话中。
使用 /effort 命令即可设置你的努力程度。
6/ 为 Claude 提供验证工作的途径
最后,务必确保 Claude 有办法验证它自己的工作成果。 这向来是将 Claude 产出效率提升 2-3 倍的秘诀,而在 4.7 版本中,这一点比以往任何时候都更重要。
验证的方式因任务而异:
- 后端开发: 确保 Claude 知道如何启动你的服务器或服务,从而进行端到端(E2E)测试。
- 前端开发: 使用 Claude Chromium 浏览器扩展,让 Claude 能够直接控制浏览器。
- 桌面应用: 使用 Computer Use(电脑操作)功能。
我个人近期的很多 Prompt(提示词)通常是这样的:“Claude,做某某任务 /go”。/go 是一个组合技能,它会让 Claude 自动执行以下流程:
- 利用 bash、浏览器或 Computer Use 进行端到端自测。
- 运行
/simplify技能(简化/重构代码)。 - 直接提交一个 PR。
对于长时间运行的任务,验证至关重要。因为只有这样,当你过几分钟或几小时回来查看进度时,你才能确信代码是真正跑通的。
将 Claude Opus 4.7 与 Claude Code 搭配使用的最佳实践
以下是来自 Anthropic 最新发布的如何与 Claude Code 搭配的说明
Opus 4.7[1] 是我们目前公开可用的最强通用模型,尤其适合编码、企业工作流,以及长时间运行的智能体任务。与 Opus 4.6 相比,它更擅长处理模糊问题,在找 bug 和做代码审查方面强得多,能够更稳定地跨会话保持上下文,也能在更少指令的情况下推理那些定义不够清晰的任务。
我们在发布公告[1]中提到过,两项变化会影响 token 用量,一是更新了 tokenizer,二是模型在更高 effort 等级下,尤其是在更长会话的后续轮次中,更倾向于进行更多思考。因此,当你用 Opus 4.7 替换 Opus 4.6 时,通常需要做一些调校,才能拿到最佳表现。对 prompt 和 harness 做几处小调整,往往就能带来明显差异。
这篇文章会介绍有哪些变化,以及如何在 Claude Code 中更有效地使用 Opus 4.7。
如何组织交互式编码会话
Opus 4.7 的 token 用量和行为表现,会因为你的部署方式不同而变化,尤其取决于你是在运行单轮输入、更加自主且异步的编码智能体,还是多轮交互、同步配合的编码智能体。在交互式场景里,它会在用户轮次之后进行更多推理,这会提升它在长会话中的连贯性、指令遵循能力和编码质量,但也往往会消耗更多 token。
为了在 Claude Code 中充分发挥 Opus 4.7 的效果,我们发现,最好把 Claude 当成一个可以委派任务的能干工程师,而不是一个需要你逐行带着走的结对程序员:
- 在第一轮里就把任务说清楚。 描述清晰的任务说明,如果包含意图、约束、验收标准,以及相关文件位置,就能给 Opus 4.7 提供足够上下文,从而产出更强结果。相反,如果把模糊需求分散到很多轮里逐步补充,通常既会降低 token 效率,有时也会拉低整体质量。
- 减少必须发生的用户交互次数。 每多一轮用户输入,都会增加推理开销。尽量把问题打包,同时给模型足够上下文,让它可以持续推进。
- 在合适的时候使用auto mode[2]。 如果某项任务里你信任模型能在不频繁确认的情况下安全执行,那么 auto mode 可以缩短整体周期。对于那些你已经在一开始提供完整上下文、并且会长时间运行的任务,它尤其合适。现在 Claude Code Max 用户已经可以在研究预览中使用 auto mode,你可以通过
Shift+Tab打开它。 - 为已完成任务设置通知。 你可以让 Claude 在任务完成时播放提示音,它也能自己创建基于 hook 的通知。
Opus 4.7 推荐的 effort 设置
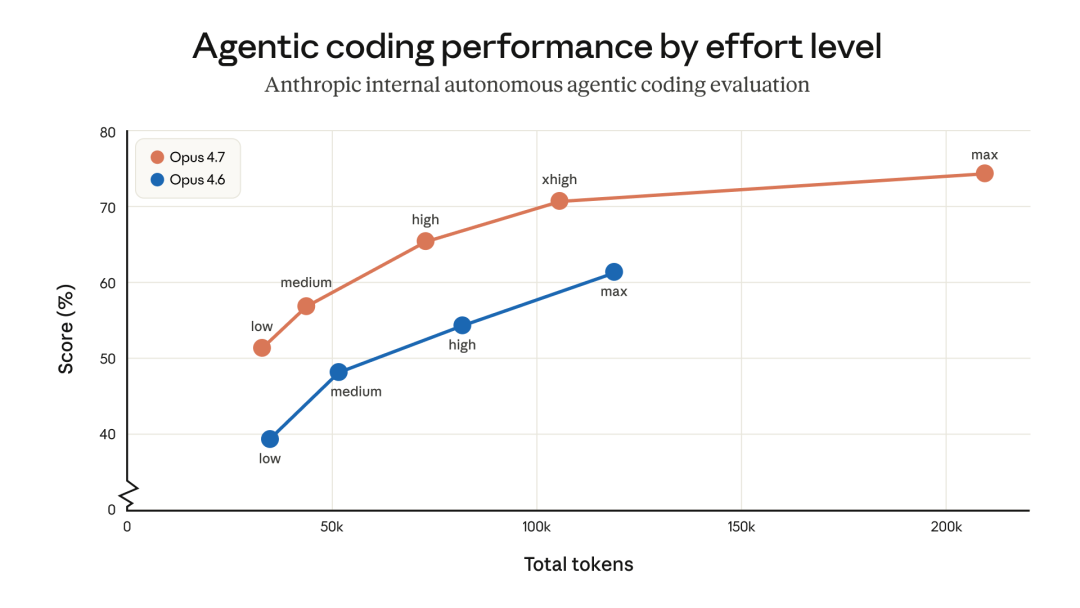
Claude Code 中,Opus 4.7 现在的默认 effort 等级是 xhigh。这是一个位于 high 和 max 之间的新等级,让用户在处理困难问题时,能更细致地控制推理深度与延迟之间的权衡。我们推荐在大多数智能体编码任务中使用 xhigh,尤其是那些对智能水平敏感的任务,比如设计 API 和 schema、迁移遗留代码、以及审查大型代码库。
下面是各个 effort 等级的额外建议:
medium和low:适合对成本敏感、对延迟敏感,或者范围明确且较小的工作。面对更难的任务时,模型能力会弱于更高 effort 等级,但它依然优于同等级下运行的 Opus 4.6,有时甚至还会用更少的 token。high:在智能水平与成本之间取得平衡。如果你在并发运行多个会话,或者希望减少花费而又不想明显牺牲质量,可以选high。xhigh(默认、推荐):最适合大多数编码和智能体使用场景。它具备很强的自主性与智能水平,同时不像max那样,在长时间智能体运行中容易出现 token 用量失控。max:可以在真正困难的问题上再挤出一点性能,但收益会递减,而且更容易出现过度思考。建议只在有意识地使用它时开启,比如在评测里测试模型上限,或者面对极度依赖智能水平、且不敏感于成本的任务。
如果你正在升级到新模型,我们建议你重新实验不同 effort,而不是简单照搬旧设置。你也可以在同一个任务过程中切换 effort 等级,以更有效地控制 token 用量和推理强度。
我们把 Opus 4.7 的默认 effort 设置成 xhigh,因为我们认为这对大多数编码任务来说都是最佳选择。如果你已经在使用 Claude Code,但此前没有手动设置 effort 等级,那么你会被自动升级到 xhigh。当然,你仍然可以手动调整。
如何与自适应思考配合
Opus 4.7 不支持带固定 thinking budget 的 Extended Thinking。 取而代之的是,Opus 4.7 提供了 adaptive thinking,也就是自适应思考。这意味着每一步是否思考都是可选的,模型会根据上下文自己决定何时投入更多思考。它可以快速回应简单查询,在某个步骤不需要思考时直接跳过,并把 thinking tokens 投入到最可能真正有帮助的地方。放到整个智能体运行过程中看,这会累积成更快的响应速度和更好的用户体验。
这一版本中的自适应思考有了明显提升,尤其是 Opus 4.7 不再那么容易过度思考。
如果你想更精确地控制思考频率,可以直接在 prompt 里写明:
- 如果你想让它多想一点, 可以试试类似这样的提示:
Think carefully and step-by-step before responding; this problem is harder than it looks. - 如果你想让它少想一点, 可以试试类似这样的提示:
Prioritize responding quickly rather than thinking deeply. When in doubt, respond directly.这样可以节省 token,但在更难的步骤上可能会损失一些准确性。
值得注意的行为变化
在 Opus 4.6 和 4.7 之间,有几项默认行为已经发生变化。如果你之前针对旧模型精细调过 prompt 或 harness,这些变化值得提前了解。
响应长度会根据任务复杂度校准。 Opus 4.7 默认不会像 Opus 4.6 那样偏啰嗦。对于简单查询,你会得到更短的回答;对于开放式分析,回答会更长。如果你的使用场景依赖某种特定长度或文风,最好在 prompt 里明确写出来。我们的经验是,提供你想要的语气和风格的正向示例,比使用否定式的“不要这样写”说明更有效。
模型调用工具的频率更低,但会进行更多推理。 这在很多情况下会带来更好的结果。如果你希望它更多地使用工具,比如在智能体工作过程中更积极地搜索或读取文件,就需要明确告诉它,应该在什么情况下、出于什么原因使用这些工具。
它默认会生成更少的 subagent。 Opus 4.7 会更谨慎地判断何时把工作委派给 subagent。如果你的使用场景适合并行 subagent,比如跨多个文件分头处理,或者同时处理多项相互独立的任务,我们建议你把这个要求明确写出来。例如:
如果某项工作你自己在单次响应里就能直接完成,比如重构一个你已经看得到的函数,那就不要生成 subagent。只有在需要跨多个项目并行展开,或者同时读取多个文件时,才在同一轮里生成多个 subagent。
接下来可以尝试什么
Opus 4.7 在长时间运行任务上的表现优于此前的模型。这让它特别适合那些过去主要受限于人工监督成本的任务,比如复杂的多文件修改、定义模糊的调试、跨服务代码审查,以及多步骤的智能体工作。
我们建议先把 effort 保持在 xhigh,然后看看第一轮输入究竟能把任务推进多远。
你还可以进一步阅读我们的Opus 4.7 prompting guide[3]以及 Claude Code 的context and session management[4]文章。
参考阅读
References
- Opus 4.7: https://www.anthropic.com/news/claude-opus-4-7
- auto mode: https://claude.com/blog/auto-mode
- Opus 4.7 prompting guide: https://platform.claude.com/docs/en/build-with-claude/prompt-engineering/claude-prompting-best-practices
- context and session management: https://claude.com/blog/using-claude-code-session-management-and-1m-context

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)