Claude 正在“GPT 化”?Opus 4.7 到底是进化,还是退化?
Opus 4.7 是目前最强的可用 Claude 模型——编程能力暴涨、视觉能力质变,Claude Code 之父 Boris Cherny 也亲自下场分享最佳实践。但社区里有个声音让人在意:它越来越不像 Claude 了。
摘要:Opus 4.7 是目前最强的可用 Claude 模型——编程能力暴涨、视觉能力质变,Claude Code 之父 Boris Cherny 也亲自下场分享最佳实践。但社区里有个声音让人在意:它越来越不像 Claude 了。
4月16日,Anthropic 正式发布 Claude Opus 4.7。
这是目前公开可用的最强 Claude 模型。我今天体验了一下,感受很直接:做技术活,这是目前最好用的 AI。
但用着用着,总觉得哪里不对劲。

先说好消息:这次升级有多夸张
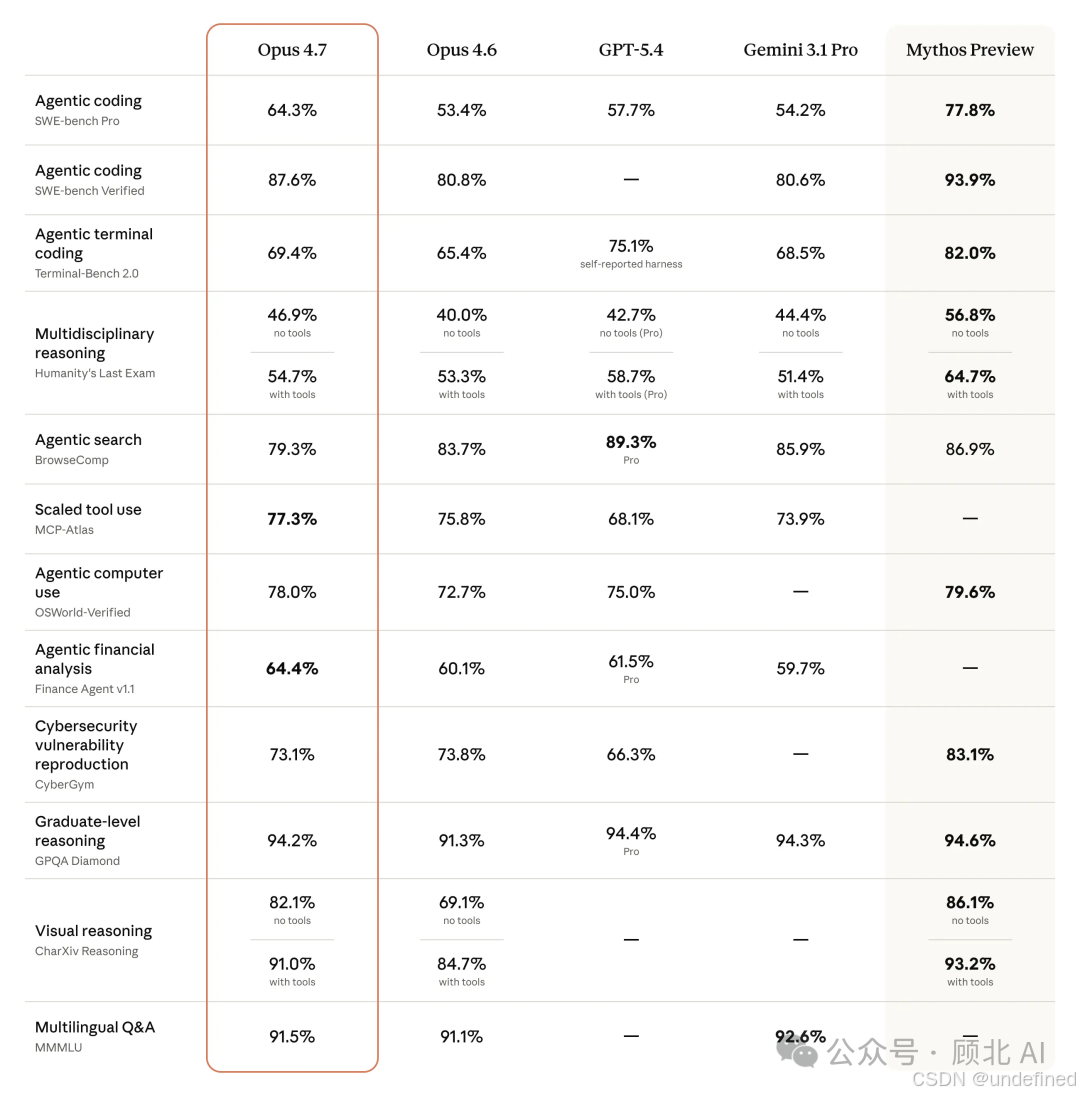
编程能力:真的上了一个台阶
数字说话——
-
SWE-bench Pro 得分 **64.3%**,比 Opus 4.6 足足高了 11 分
-
Anthropic 内部 93 题编程基准,解决率提升 **13%**,其中有 4 道题是 4.6 和 Sonnet 4.6 都解不出来的
-
CursorBench 通过率 **70%**,4.6 是 58%
-
Rakuten 的生产环境测试:4.7 解决的任务数量是 4.6 的 3 倍
但数字是死的,让我印象最深的是这个:
有人让 Opus 4.7 从头用 Rust 写了一个完整的 TTS(文字转语音)引擎——神经网络模型、SIMD 内核、浏览器 Demo 全套。写完之后,它把自己的输出喂给一个语音识别器,跟 Python 参考实现做对比,自我验证了一遍。
这是几个月的高级工程师工作量,模型自主完成的。
以前说"AI 辅助编程",现在越来越接近"AI 自主工程"。
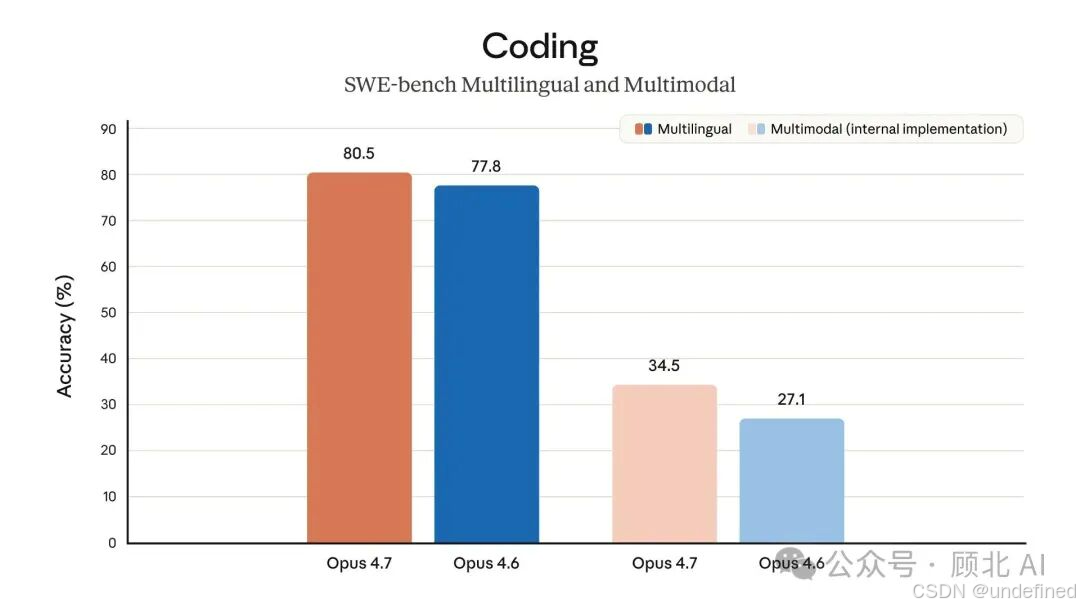
视觉能力:质变,不是量变
之前 Claude 处理图片一直是个短板,这次算是补课了。
最大分辨率从 1568px 直接跳到 2576px(约 3.75MP),超过原来的 3 倍。更重要的是,坐标和像素现在是 1:1 映射,做计算机使用(computer use)的时候再也不用手动算缩放比例了。
效果有多明显?
XBOW 做了测试,视觉敏锐度基准:**4.7 是 98.5%,4.6 只有 54.5%**。几乎翻倍。
他们原话说:"我们最大的 Opus 痛点基本消失了,这解锁了一整类之前用不了的工作场景。"
对于需要截图分析、读复杂图表、做 UI 自动化的场景,4.7 是真的有感提升。
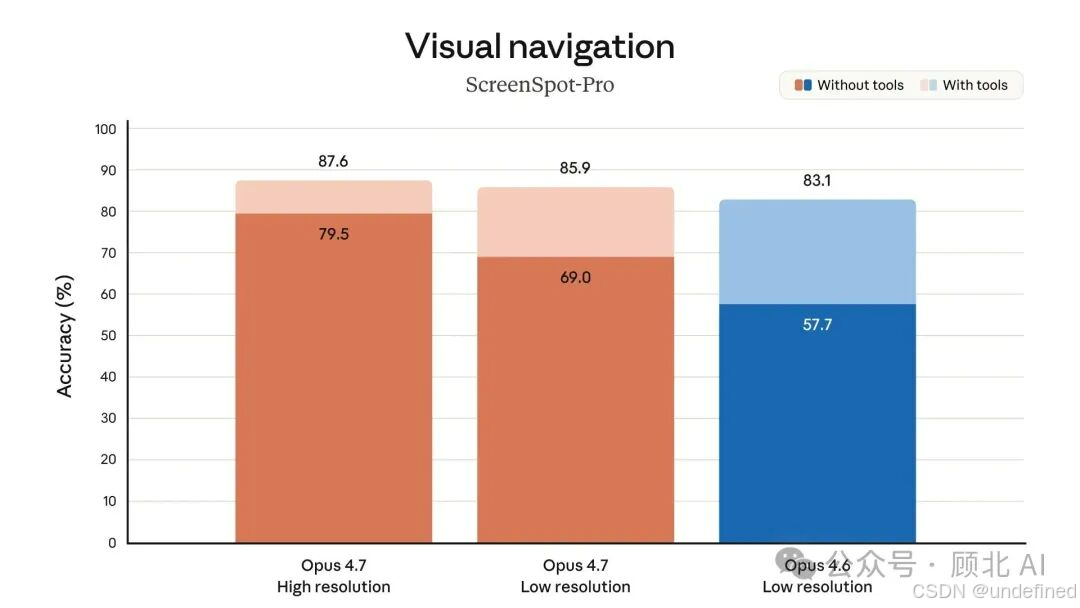
Agent 能力:更稳了,不是更快了
这一点我觉得比较重要,但容易被忽略。
4.7 最大的改进不是"更聪明",而是更可靠——
-
长时间运行任务更稳定,工具调用错误减少了 1/3
-
内存能力提升:它能更好地在文件系统里记笔记,跨会话记住上下文
-
首个通过 Notion "隐式需求测试"的模型(就是那种你没说但你明显期待的事情,它能主动做)
简单说:4.7 是那种你可以真正放手让它跑的模型,而不是时刻需要盯着的实习生。
新功能速览:哪些真的值得用
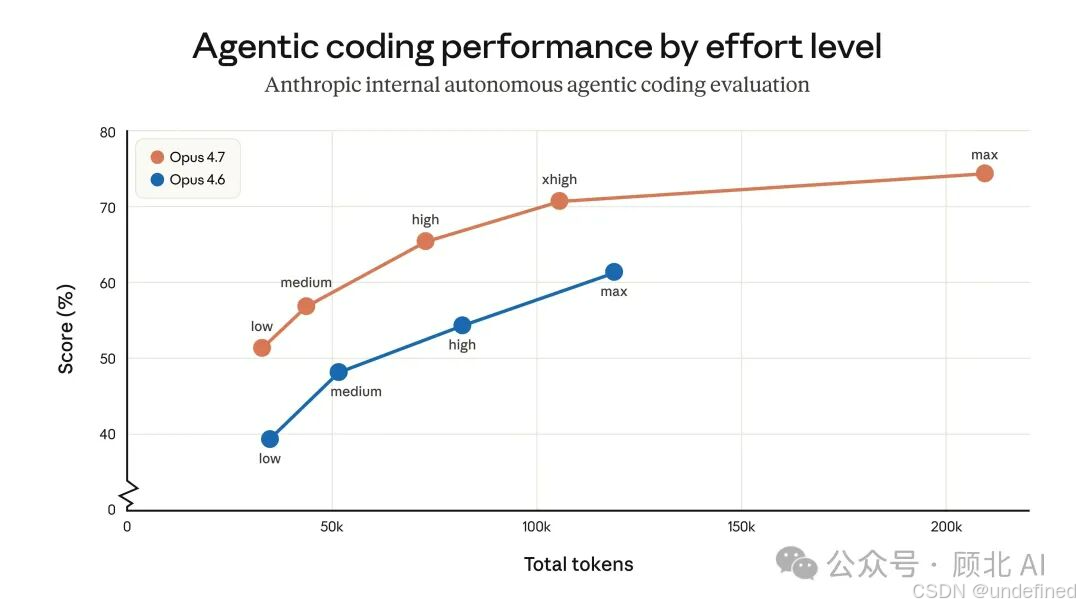
xhigh 努力等级
这是新增的一档,介于 high 和 max 之间。Claude Code 的默认值已经从 high 改成了 xhigh。
自适应思考(Adaptive Thinking)
之前的 Extended Thinking 需要你手动设置 budget,现在换成了自适应——模型自己决定什么时候深度思考,什么时候快速回答。官方说在内部测评里,自适应思考的效果超过了固定 budget 的 Extended Thinking。
Task Budgets(beta)
给 Agent 设一个 token 预算,让它在预算范围内自己安排优先级。对于长流程任务很有用,省得跑到一半超出预算突然停掉。
/ultrareview 命令
在 Claude Code 里输入 /ultrareview,它会做一次深度代码审查,专门找那种"谨慎的 reviewer 才会注意到的"问题。Pro 和 Max 用户现在有 3 次免费额度。
API Breaking Changes 提醒
如果你在 API 层集成 Claude,注意三个变化:
-
thinking: {budget_tokens: N}被移除,只支持{type: "adaptive"} -
temperature、top_p、top_k设置非默认值会直接报 400 错误 -
新 tokenizer 可能让相同输入多消耗 0~35% 的 token
定价没变:输入 25/百万 tokens。
Claude Code 之父的 6 条实战心法
4.7 发布当天,Boris Cherny(Claude Code 的创始人)在推上发了一串使用心得。他说自己过去几周一直在内测,"感觉生产力极高"。
我把他的建议整理了一下,这是真正的第一手经验,值得认真看。
心法一:用 Auto Mode,彻底告别权限提示
这是 Boris 第一条建议,也是我觉得改变最大的一条。
以前让 Claude 跑长任务,你要么一直守着点"允许",要么用 --dangerously-skip-permissions(有风险,不推荐)。
现在 Auto Mode 是第三条路:权限请求会自动路由给一个分类模型来判断是否安全,安全就自动批准,不用人工介入。
实际效果:你让一个 Claude 开始跑,然后可以切到下一个 Claude 做别的事情,完全不用守着。
Max、Teams、Enterprise 用户现在都可以用。CLI 里按 Shift+Tab 切换,Desktop 和 VSCode 插件里有下拉选项。
心法二:用 /fewer-permission-prompts 技能调校权限
这是 4.7 同步发布的新技能,我之前没注意到。
它会扫描你的会话历史,找出哪些 bash 命令和 MCP 指令是安全的、但一直在触发权限提示,然后给你一份建议清单,告诉你哪些命令可以加进权限白名单。
如果你不用 Auto Mode,用这个来减少权限中断,体验会顺很多。

心法三:用 Recaps 掌握长任务进度
这个功能之前已经上线,为 4.7 做了优化。
Recaps 是 Agent 完成阶段后的简短总结——"做了什么、下一步是什么"。对于那种跑了几分钟或几个小时的长任务,回来的时候能快速知道进度在哪里,不用自己翻日志。

心法四:开 Focus Mode,只看结果
Boris 说他最近一直在用 CLI 里的 Focus Mode——隐藏所有中间过程,只显示最终结果。
他的原话很有意思:"模型已经到了我基本信任它会执行正确命令、做出正确修改的程度。我只看最终结果就够了。"
在 CLI 里用 /focus 开关切换。
心法五:设对努力等级
Boris 自己的习惯是:**大多数任务用 xhigh,最难的任务用 max**。
这里有个细节:max 只对当前会话生效,下次新开会话会重置;xhigh 及以下的等级是粘性的,下次开会话还在。
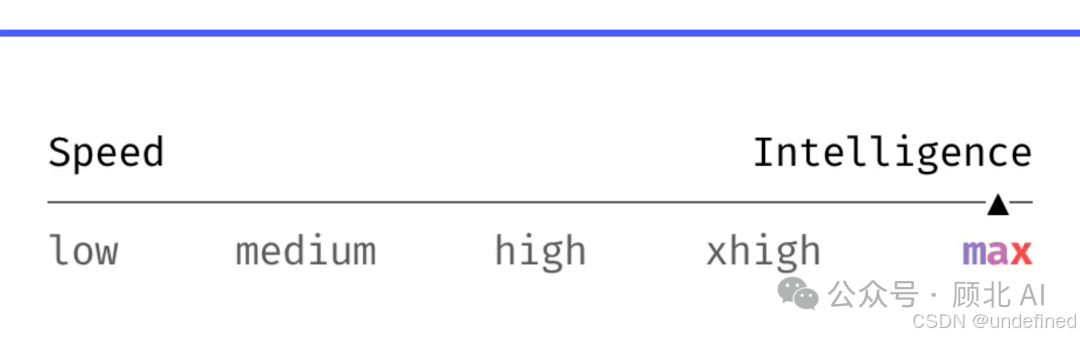
关于努力等级的选择,他的建议很实用:
|
等级 |
适合什么 |
|---|---|
low
/ |
成本敏感、延迟敏感的简单任务 |
high |
同时跑多个并发会话,平衡质量和成本 |
xhigh |
大多数编程/Agent 任务的默认选择 |
max |
测评、极难问题、不差钱的重要任务 |
在 CLI 里用 /effort 设置。
心法六:让 Claude 能验证自己的工作
这是 Boris 一直在讲的核心原则,这次再次强调:给 Claude 一个验证自己结果的方式,能让输出质量提升 2~3 倍。
具体怎么做?
-
后端任务:确保 Claude 知道怎么启动你的服务/服务器,做端到端测试
-
前端任务:用 Claude Chromium 扩展,让它能直接控制浏览器
-
桌面应用:用 computer use
Boris 自己的 prompt 风格是这样的:
Claude 做 [任务描述] /go
/go 是他自己建的 skill,会触发三步动作:
-
用 bash、浏览器或 computer use 做端到端自测
-
运行
/simplify技能清理代码 -
自动发起 PR
他说:"对于长时间运行的任务,验证尤其重要——这样当你回来的时候,你知道代码是可以用的。"
但有件事,我必须说
上面这些都是好消息。现在说点让我有点不舒服的。
Opus 4.7 在写作风格上,变了。
官方文档里有这么一句,写得比较低调,但明眼人都懂:
"More direct, opinionated tone with less validation-forward phrasing and fewer emoji than Claude Opus 4.6's warmer style."
翻译过来:更直接、更强硬、更少先肯定你、更少 emoji。
用 Claude 用久了的人都知道那种感觉——你发一段代码让它检查,4.6 会说"这段代码整体思路很清晰,不过有几个地方可以优化一下...";4.7 直接说"第 12 行有 bug,改成 X 即可。另外逻辑有问题,建议重构。"
结果一样准确,但感觉完全不同。
社区里已经有不少人说:4.7 "说话越来越像 GPT 了"。干、硬、工具感。少了那种"AI 同事"的协作温度,多了"工具返回结果"的距离感。
对于写作任务,这个变化更明显。创意写作、长文润色、有风格的内容创作——4.7 明显不如 4.6。那种 Claude 特有的"有温度的文字"变淡了。
这其实是个挺值得讨论的取向问题。
更像工具,还是更像同事?
Anthropic 选择了前者——至少在这个版本里是这样。这对编程、对 Agent、对追求准确性的任务是好事;但对于把 Claude 当写作伙伴、当思维碰撞对象的用户,4.6 可能还是更顺手的。
我自己的方案是:写代码用 4.7,写文章用 4.6。两个场景的需求真的不一样。
总结:一句话概括 Opus 4.7
这是目前最强的 AI 编程工具,但它正在用"更像机器"换取"更能干活"。
如果你是开发者,强烈推荐升级,配合 Boris 的那 6 条实践用起来,提效非常明显。
如果你主要用 Claude 做写作、创作、或者重视那种有温度的交流感,建议先测一测 4.7,再决定要不要切换。
你们用下来感觉怎么样? 4.7 有没有让你感受到那种"它变了"的感觉?评论区聊聊。
我是顾北,关注我,解锁更多AI资讯信息
谢谢你阅读我的文章~
我们下期再见!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 5
5 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)