Anthropic 发布 Claude Opus 4.7,性能如何?
先说结论,opus 4.7性能上有不少提升,但我看下来,进步体感应该没有从 4.5 到 4.6 那么大,但毕竟 Opus 4.6 都这么好用了,4.7只会更好用,而且经常写代码的朋友都知道,当模型的某个Benchmark很高的时候,提升一点点,在使用感受上会更不一样,毕竟意味着新的模型能解决更多corner case。从4.5到4.6有巨大飞跃(从 67.8% 到 84.0%,+16.2%),而从
Datawhale干货
作者:桔了个仔,Datawhale成员
对于 A 社,该骂骂,但该用的时候,还是得用。刚躺在床上,看到opus 4.7的消息,马上弹起来滚进书房开始用了。
先说结论,opus 4.7性能上有不少提升,但我看下来,进步体感应该没有从 4.5 到 4.6 那么大,但毕竟 Opus 4.6 都这么好用了,4.7只会更好用,而且经常写代码的朋友都知道,当模型的某个Benchmark很高的时候,提升一点点,在使用感受上会更不一样,毕竟意味着新的模型能解决更多corner case。
不过,
为什么 Opus 4.7 这次只给个 0.1 版本号
年前大家都说claude 5快要发布了,结果现在才发布4.7。但可能是因为Mythos在手,opus直接叫5.0太狂了。毕竟A 社发布页自己都承认了:Opus 4.7 的能力不如 Mythos Preview,但 Mythos 因为 cyber 能力太强,只走 Project Glasswing 的有限发布。
所以 Opus 4.7 这个 0.1 版本号的真实含义是:A 社还没掏出底牌。我对下一个大版本(不管叫 Claude 5 还是 Mythos 正式版)的兴奋度,比对 4.7 本身还高一点。
不过,既然发布了,我的第一个疑问是,
opus从4.5到4.6升得多,还是4.6到4.7升得多?
首先先说4.5 到 4.6的升级。我之前写过一个回答
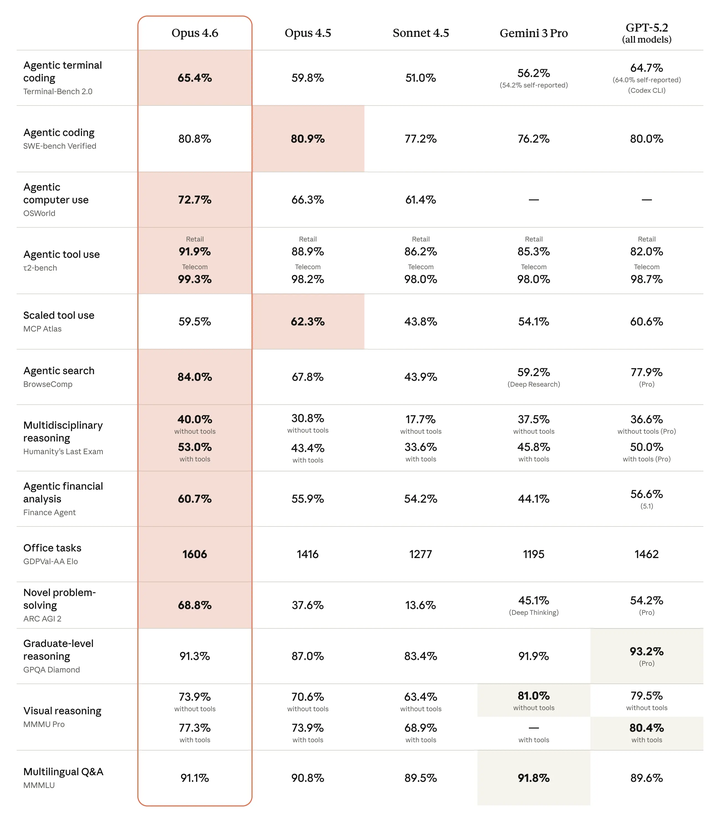
可以看到,其提升主要集中在Agentic coding和Agentic search上,同时,ARC AGI 2(抽象推理)从37.6% → 68.8%,几乎翻倍。这是当时给的性能对比图。
而4.7比起4.6呢?这是对比图
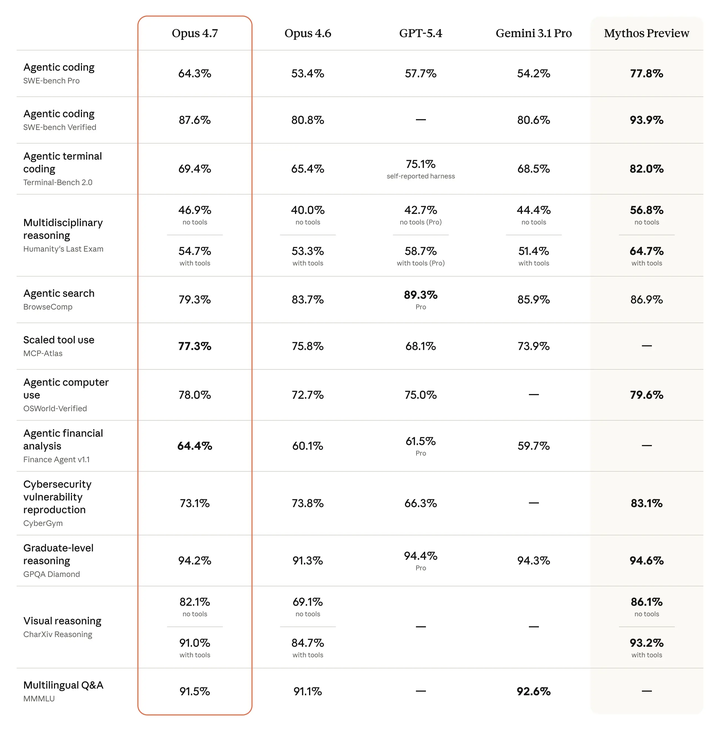
虽然这两个表在row上不能直接对比,但认真看,还是可以发现问题。
首先讲讲进步的地方吧。总结一下,在这几个维度上,Opus 4.7 实现了大幅的性能提升:
-
agentic coding方面,SWE-bench Verified这一块进步很大,可以看到4.6 vs 4.5: 几乎原地踏步。4.5 分数为 80.9%,4.6 分数为 80.8%(甚至微降了 0.1%)。不过,4.7 的分数跃升至 87.6%,相比 4.6 提升了 6.8%,进步可谓挺大; 在 Verified 版本上,4.7 的进步远超 4.6(4.6 基本没进步)。这标志着 4.7 在处理中等难度的软件工程任务时,可靠性有了大幅阶梯式的提升。
-
视觉推理 (Visual Reasoning)方面,opus 4.6 比 4.5只多3.3%(无工具下从 70.6% 到 73.9%);而4.7 vs 4.6就 出现了爆发式增长,多了13.0%(无工具下从 69.1% 跳升至 82.1%,)。这是 4.7 改进最明显的地方。
-
多学科推理 (Multidisciplinary Reasoning - Humanity's Last Exam)方面,4.6 vs 4.5在无工具表现提升约 9.2%,4.7 vs 4.6呢?虽然基数已高,但无工具表现仍提升了 6.9%,且在有工具辅助下维持了稳定增长。
但有个地方,4.7反而退步了,那就是Agentic Search。从4.5到4.6有巨大飞跃(从 67.8% 到 84.0%,+16.2%),而从 4.6到4.7,则出现了回落(从 83.7% 降至 79.3%,-4.4%)。这可能反映了 4.7 在搜索策略上变得更加审慎,或者测试集标准有所变化。
另外,这次 A 社在 effort 等级里塞了个新档位叫 xhigh,夹在 high 和 max 中间,给用户更多的成本控制能力。Claude Code 里默认 effort 直接提到 xhigh。
这次和模型一起发布的两个新东西
xhigh档
这次 A 社在 effort 等级里塞了个新档位叫 xhigh,夹在 high 和 max 中间。Claude Code 里默认 effort 直接提到 xhigh。
这个小改动看着不起眼,但做 Agent 的人会懂。之前 high 和 max 之间差一档,high 有时不够用,max 又太烧钱烧 token。现在 xhigh 补了这个缝。配合同时上线的 API task budgets(让开发者给 Claude 设置 token 预算),做 long-running Agent 的成本可控性好了一截。
/ultrareview 和 Auto mode
Claude Code 这次加了个 /ultrareview slash command,会专门跑一遍仔细的 review,找一个认真的 reviewer 能发现的 Bug 和设计问题。
另外,Auto mode 扩展到了 Max 用户。简单讲就是 Claude 在做 long task 的时候可以自己决定某些授权,不用每一步都卡你一下。
Opus 4.7好用吗?
opus 4.7才发布,我暂时还没一手经验分享,不过A社在发布模型之前,总喜欢和合作方一起测评,我点开发布页我去看了各家合作方给的评价,例如大家都熟悉的Cursor和Notion
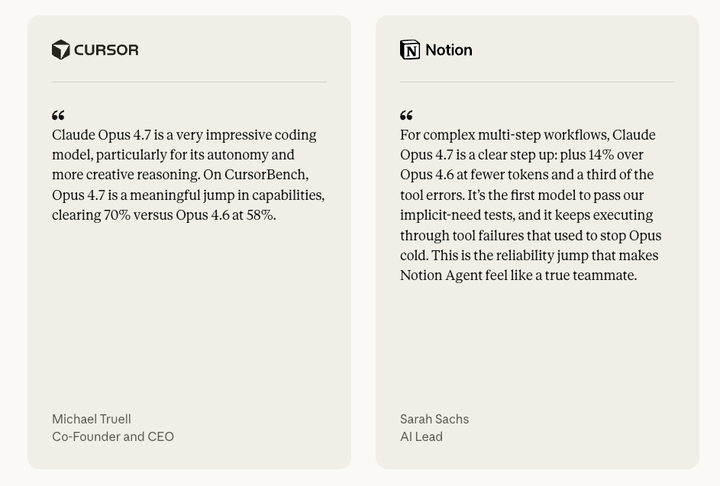
Cursor: 自家 CursorBench 上,4.7 跨过 70%,4.6 只有 58%。
Notion: 多步工作流上 Opus 4.7 比 4.6 好了 14%,用了更少的 token,tool 错误只有 4.6 的三分之一。这个组合才是最关键的:更准 + 更省 + 更稳。
一共27个,我就不一一总结了。

小坑
这里有个点值得细说:Opus 4.7 用了新的 tokenizer,虽然价格没变,还是 5/25 美金每百万 token,但同样的输入内容,token 数会多 1.0~1.35 倍。
加上 4.7 在高 effort 下思考得比 4.6 多,整体输出 token 也会增加。官方测下来净效应是正向的(花更少钱做更多事),但如果你是 API 用户,切过去之前最好在自己的真实 traffic 上跑一下 A/B。

好了,先写这么多,后续我肯定会在实际项目里继续用 4.7,有翻车案例和惊喜再回来更新。写完这篇文章,我算是对opus 4.7哪里好哪里不怎么好有所了解了,等上班试试了。
参考资料:
1. https://www.anthropic.com/news/claude-opus-4-7


一起“点赞”三连↓

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)