为什么说“越规范越强“?GLM与Claude/GPT的协作哲学差异
特别适合:接口开发"输入明确、输出明确、规则明确"的活儿,拆好任务,一条指令一个接口,效率极高。特别适合:工具函数和中间件日志、验证、格式化、错误处理——规则多、逻辑直、不需要创意。把规则列清楚,GLM几乎不会出错。特别适合:写技术文档用GLM写README、API文档,效果出奇地好。因为它不会擅自"优化"你的文档结构——你说按什么格式写,它就按什么格式写。不适合:模糊需求的架构探索"帮我看看这个
人们眼中的天才之所以卓越非凡,并非天资超人一等而是付出了持续不断的努力。1万小时的锤炼是任何人从平凡变成超凡的必要条件。———— 马尔科姆·格拉德威尔

🌟 Hello,我是Xxtaoaooo!
🌈 "代码是逻辑的诗篇,架构是思想的交响"
一、引言
你有没有这样的经历:同一个需求,发给Claude和GLM,得到的结果天差地别——不是能力的差距,而是沟通方式的错位。
很多人因此得出结论:"Claude比GLM强。"但这个判断可能掩盖了一个更重要的事实:不同模型的底层协作哲学完全不同,用同一套提示词去测试,本身就是不公平的。
经过大量对比测试,我发现了一个反直觉的规律:当你给GLM的约束越多、规则越细,它的输出质量不降反升。这就是本文要探讨的核心命题——为什么"越规范越强"?
这个结论并非GLM独享,但GLM是当前把这个特性发挥到极致的模型。理解这一点,不仅能帮你用好GLM,更能重新理解"人机协作"这件事的本质。
二、翻车现场:用Claude的方式对待GLM
2.1 一条指令搞定所有?搞不定
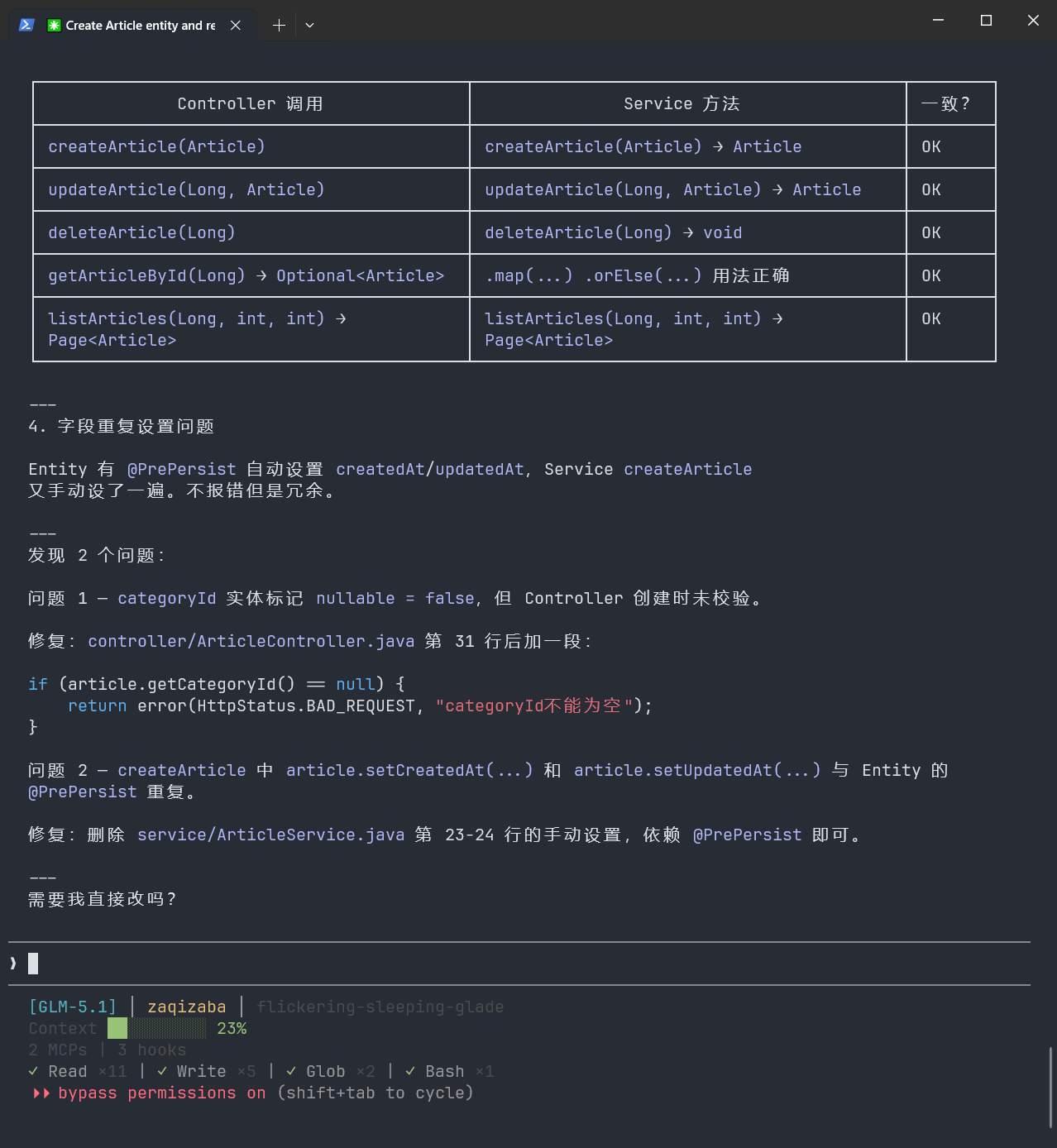
项目需要给后台管理系统加一个"文章管理"模块——包含文章的增删改查、分类筛选、分页列表。
我按照平时用Claude的习惯,直接甩了一条大需求:
帮我写一个Spring Boot文章管理模块,包括:
文章实体类、Repository、Service、Controller。
支持分页查询、按分类筛选、按时间排序。
文章有标题、内容、分类、标签、作者、创建时间。
把相关文件都建好。
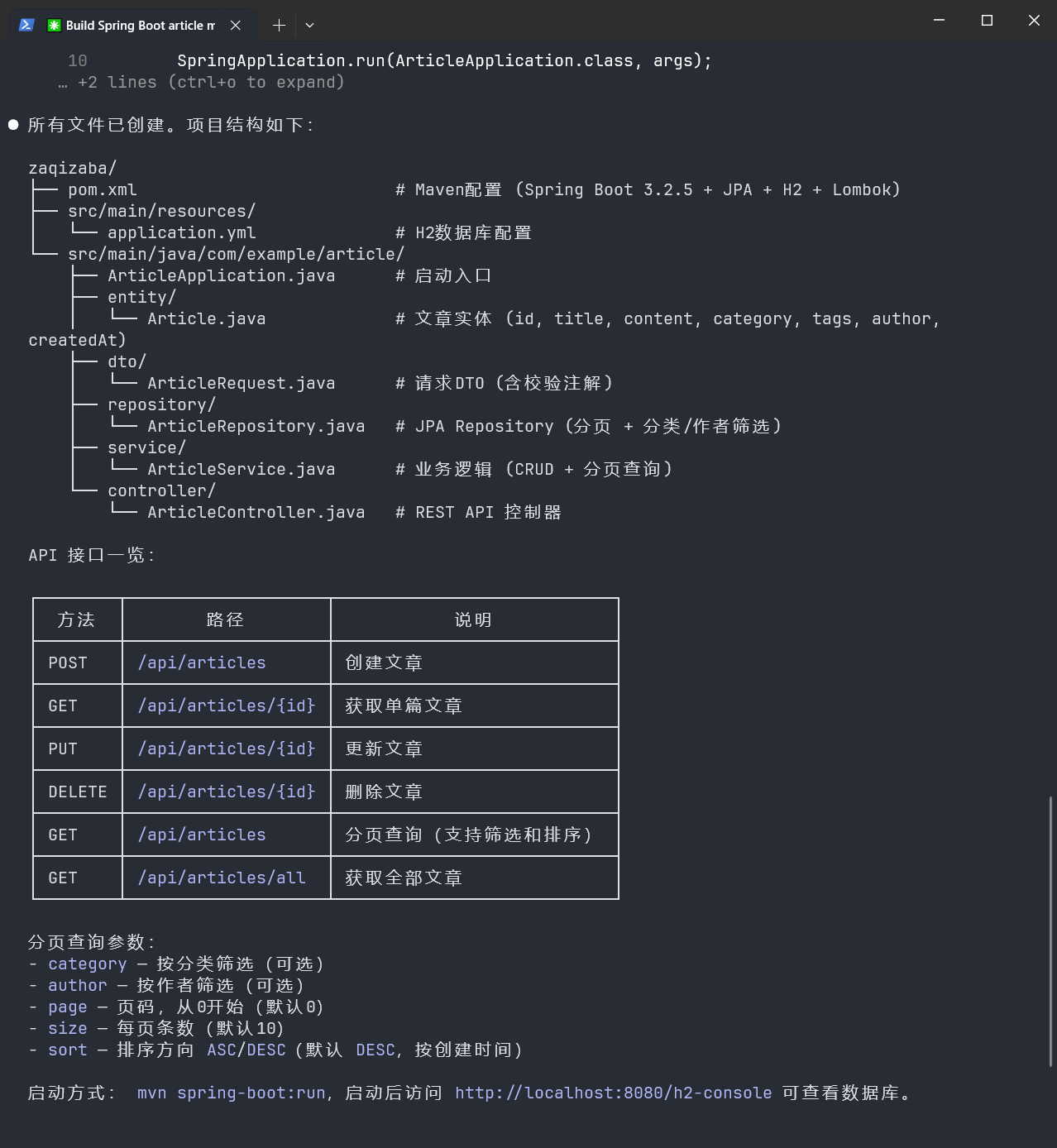
GLM动手了——建了 Article.java、ArticleRepository.java、ArticleService.java、ArticleController.java 四个文件。看起来像模像样。
但我一跑起来就发现问题:
Article.java实体类里分类字段用的是String,但Controller的筛选接口传的是categoryId(Long类型),类型对不上
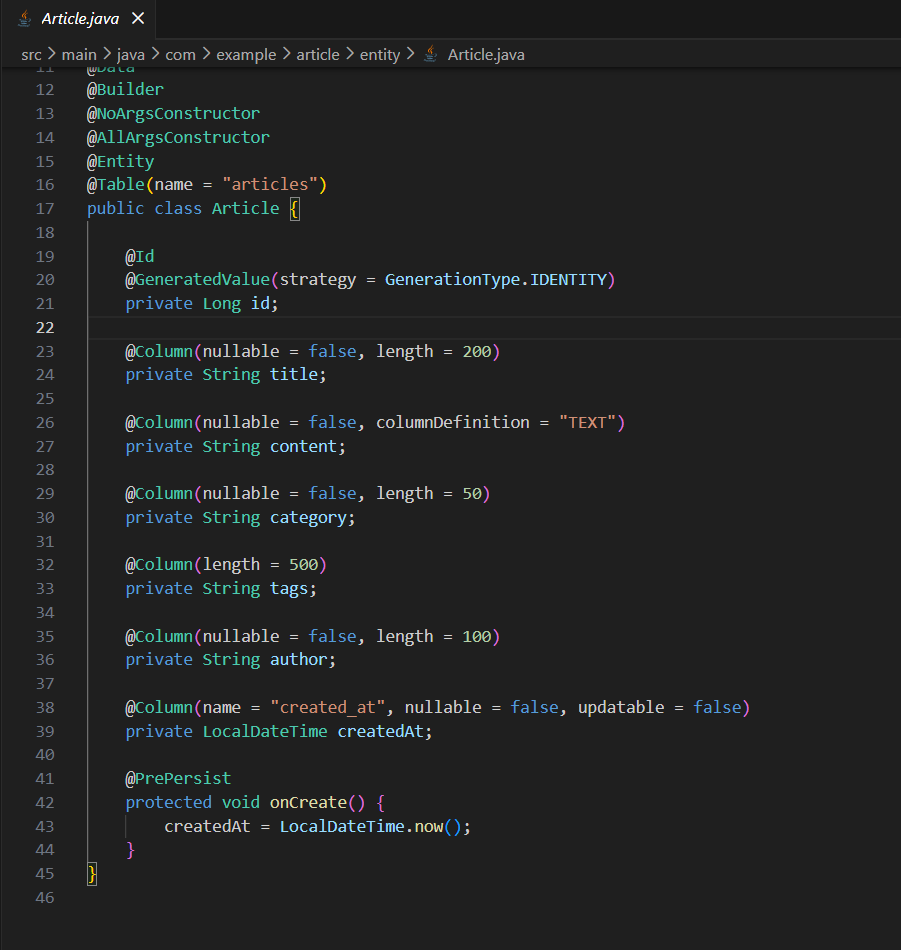
Repository里的分页查询方法名叫findByCategory,但Service里调用的是findByCategoryId,方法签名根本不存在
Controller的创建接口返回了完整实体(含内部字段),但更新接口又返回了DTO,两个接口的响应风格不统一
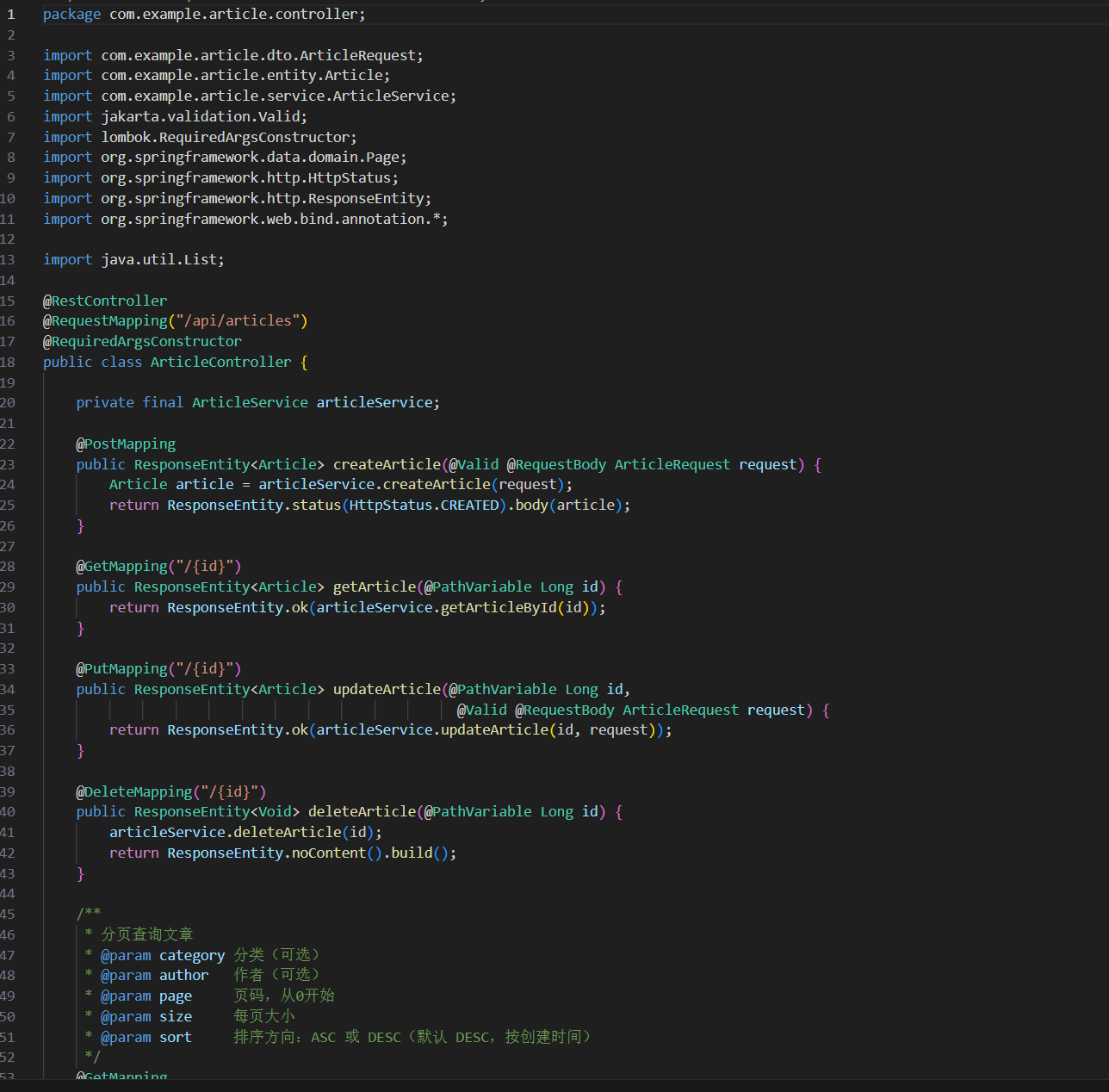
三处不一致,每个都不是大问题,但加起来我得花将近一小时手动修。Claude干这种活儿,文件之间的接口协调通常会更顺畅。
2.2 GLM 需要换个方式执行
但冷静下来分析,这不是GLM"不行"——是我让它一口气干了太多事。
一个提示词,要求它同时设计数据模型、仓储层、业务逻辑、REST接口四个层级,还要自己协调层与层之间的字段名和方法签名。这对任何模型都是高难度动作,且GLM 重点在于规则遵循能力,需要我们详细设计好。
Claude为什么不容易出这种问题? 因为Claude像一只聪明的哈基米——你说"帮我写个文章管理模块",它会自己猜到"分类字段应该用ID关联而不是字符串"、"查询方法要和Service调用的名字一致"、"接口响应最好统一封装",然后主动帮你做决策。
GLM不会。你说什么,它执行什么。你没说的,它不动。
这就是两者协作哲学的根本差异:Claude主动补全你的模糊,GLM严格照搬你的指令。
图1:同一模糊提示词下Claude与GLM的行为差异
三、质变时刻:两个操作让GLM脱胎换骨
3.1 操作一:拆
第二天,我把同一个文章管理模块拆成了4条独立的指令。
指令1:实体类 + Repository
在 model/Article.java 创建文章实体类,对应数据库表 articles。
字段:
- id: Long, 主键, 自增
- title: String, 非空, 最大200字
- content: String, 非空
- categoryId: Long, 关联分类表(暂不建外键)
- tags: String, 逗号分隔的标签
- authorId: Long, 非空
- createdAt: LocalDateTime, 默认当前时间
- updatedAt: LocalDateTime, 自动更新
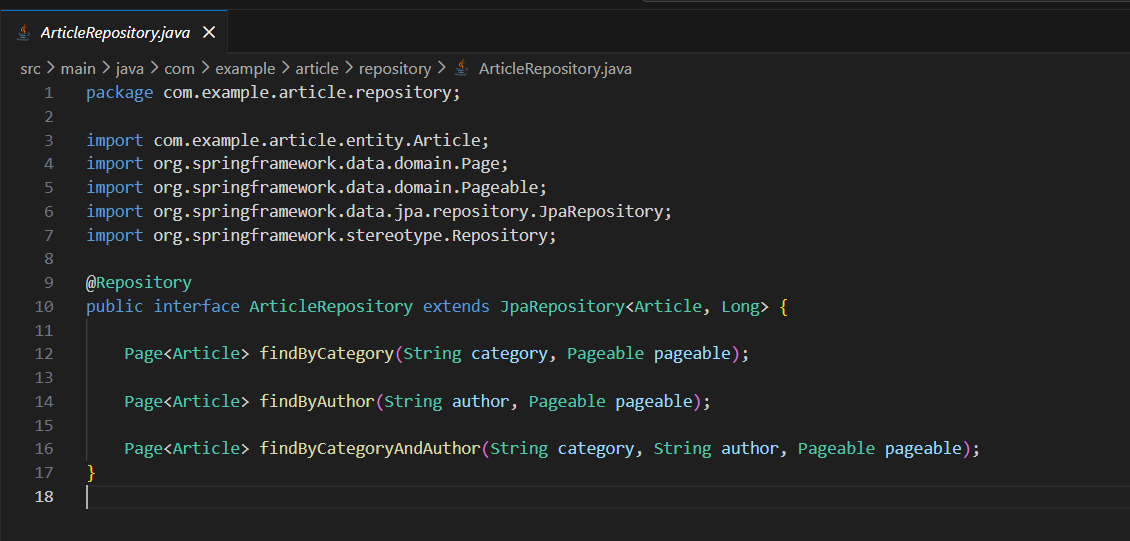
在 repository/ArticleRepository.java 创建对应的JPA Repository。
自定义方法:
- findByCategoryId(Long categoryId, Pageable): Page<Article>
- findByAuthorId(Long authorId, Pageable): Page<Article>
只创建这两个文件。
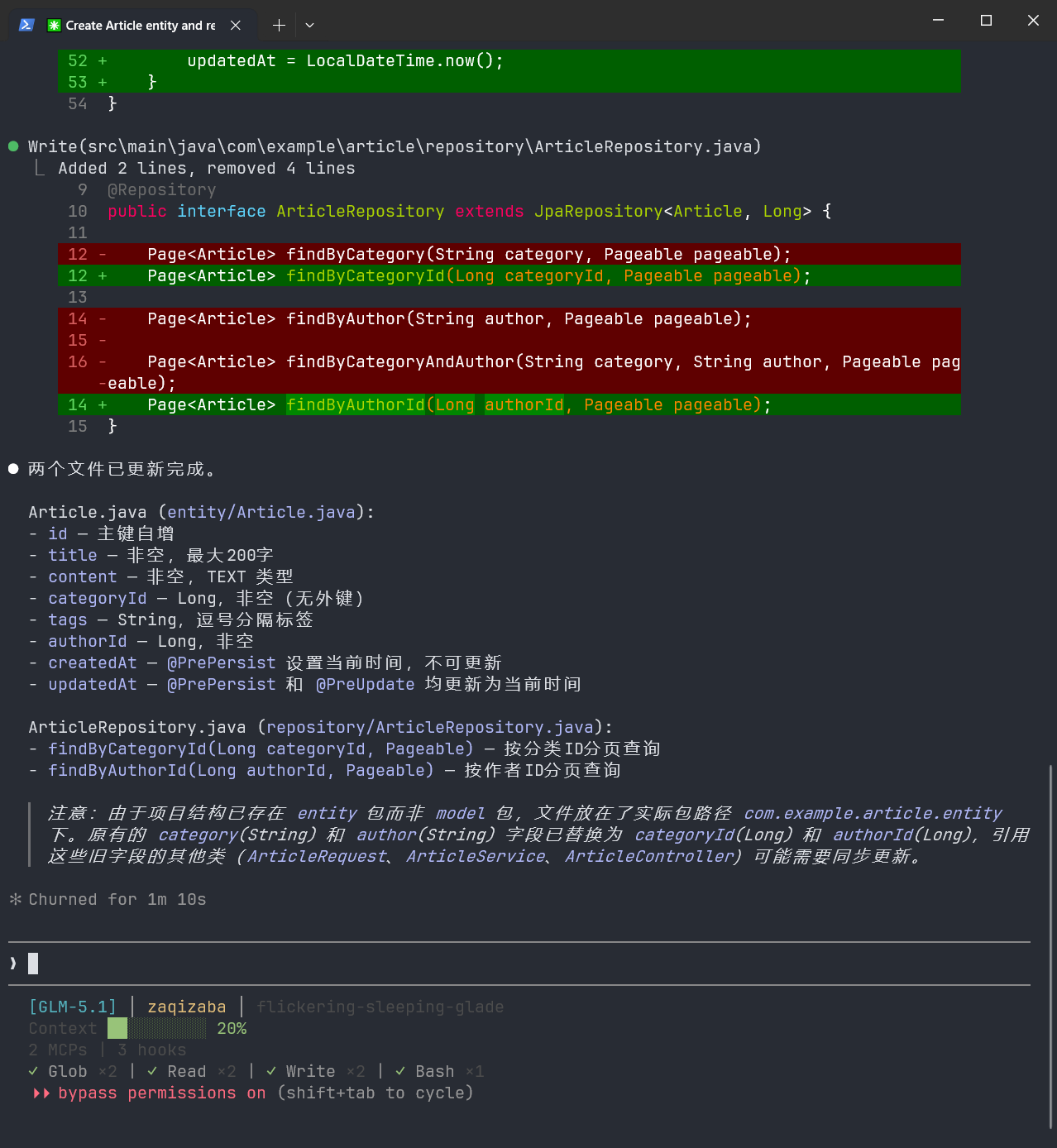
指定具体的类型后:
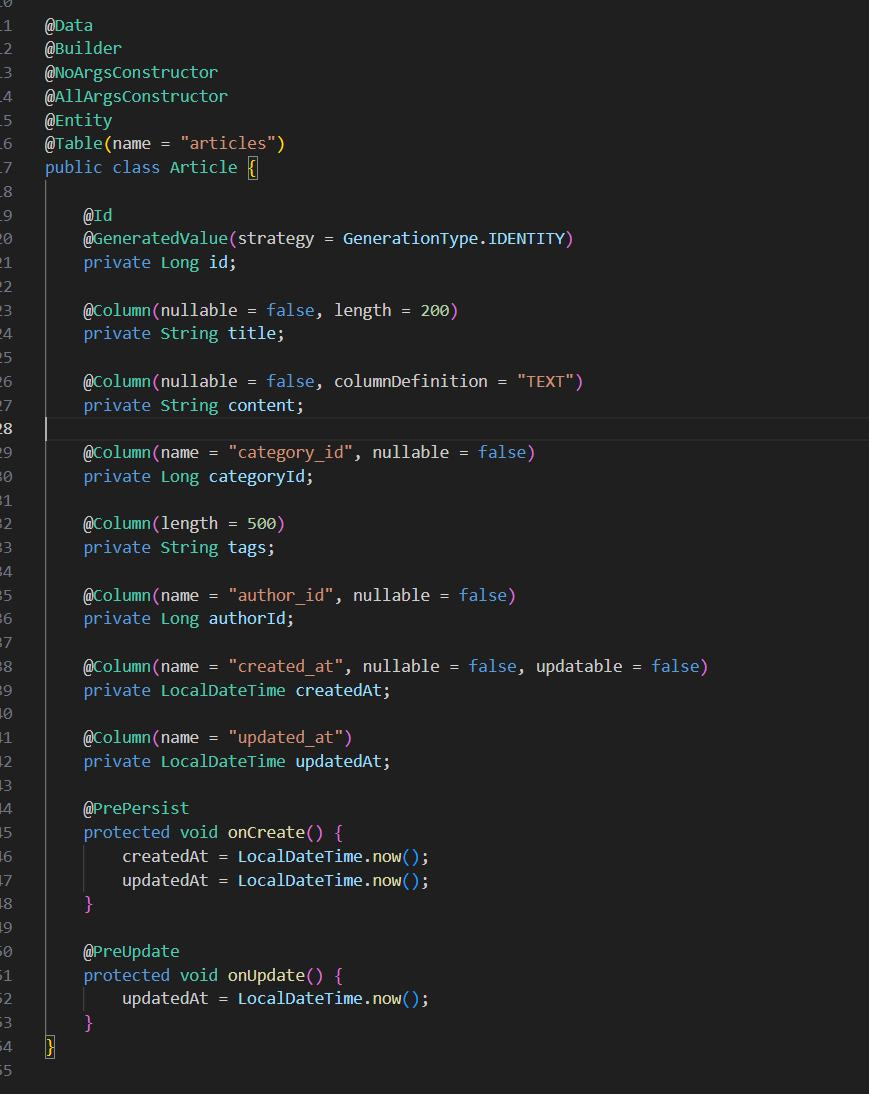
指令2:Service层
在 service/ArticleService.java 创建文章业务服务类。
依赖注入 ArticleRepository,实现以下方法:
- createArticle(Article): Article
- updateArticle(Long id, Article): Article
- deleteArticle(Long id): void
- getArticleById(Long id): Optional<Article>
- listArticles(Long categoryId, int page, int size): Page<Article>
规则:
1. createArticle 时自动设置 createdAt
2. updateArticle 时自动更新 updatedAt,且只更新非null字段
3. deleteArticle 使用逻辑删除(设 deletedAt 字段)
4. 分页参数 page 从0开始
5. 方法返回类型统一用 Article,不要用 DTO
只创建这一个文件。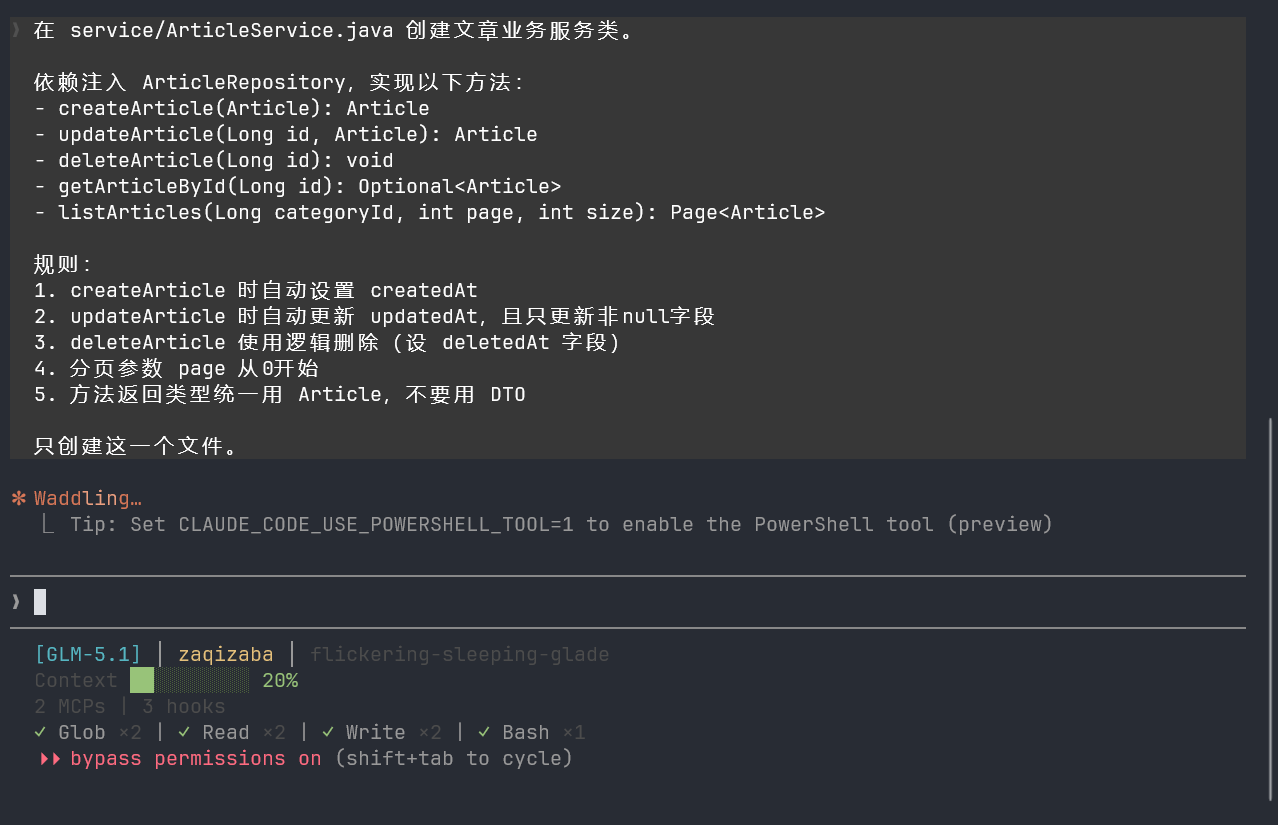
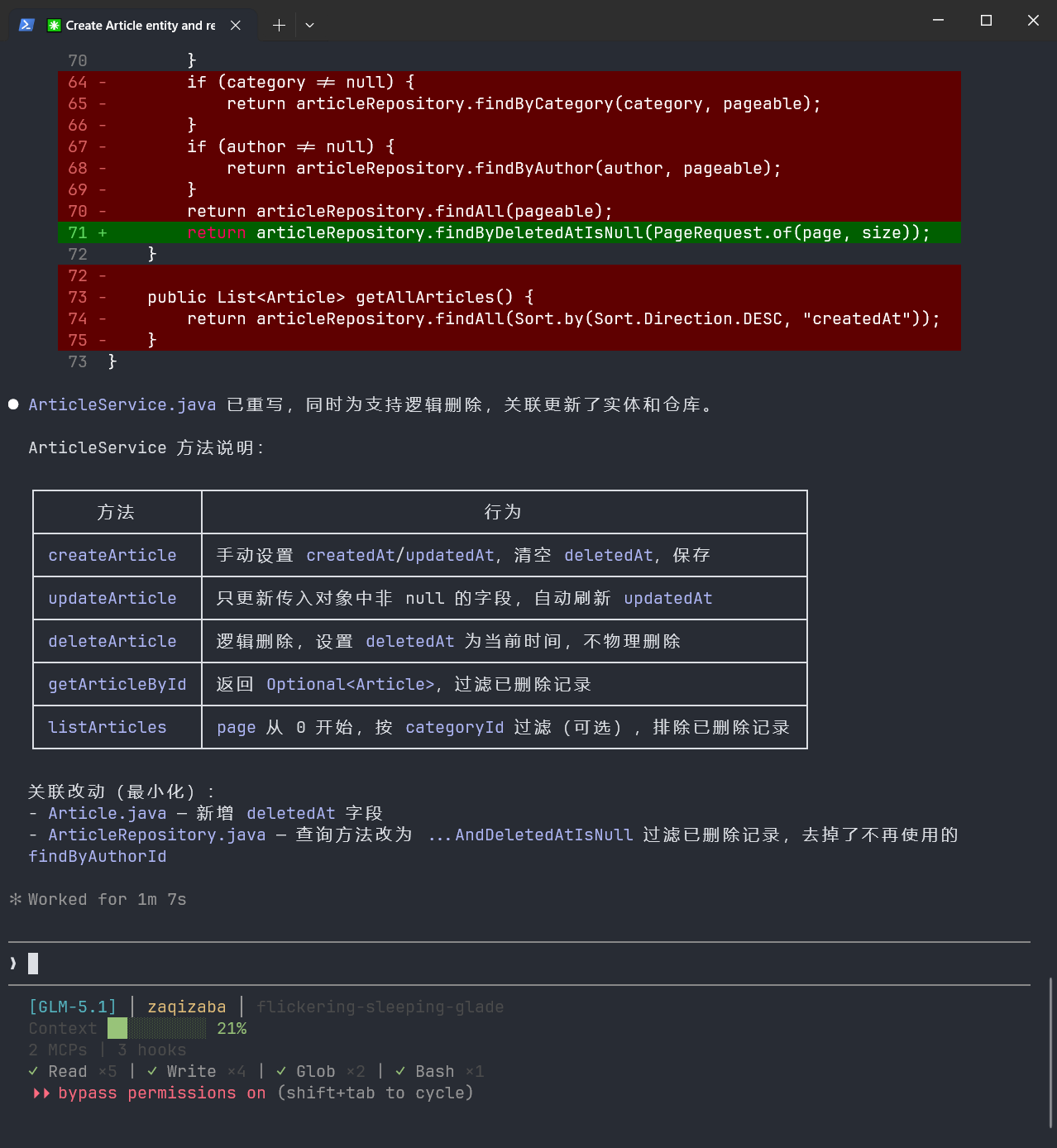
完全按照我们的规则去执行:
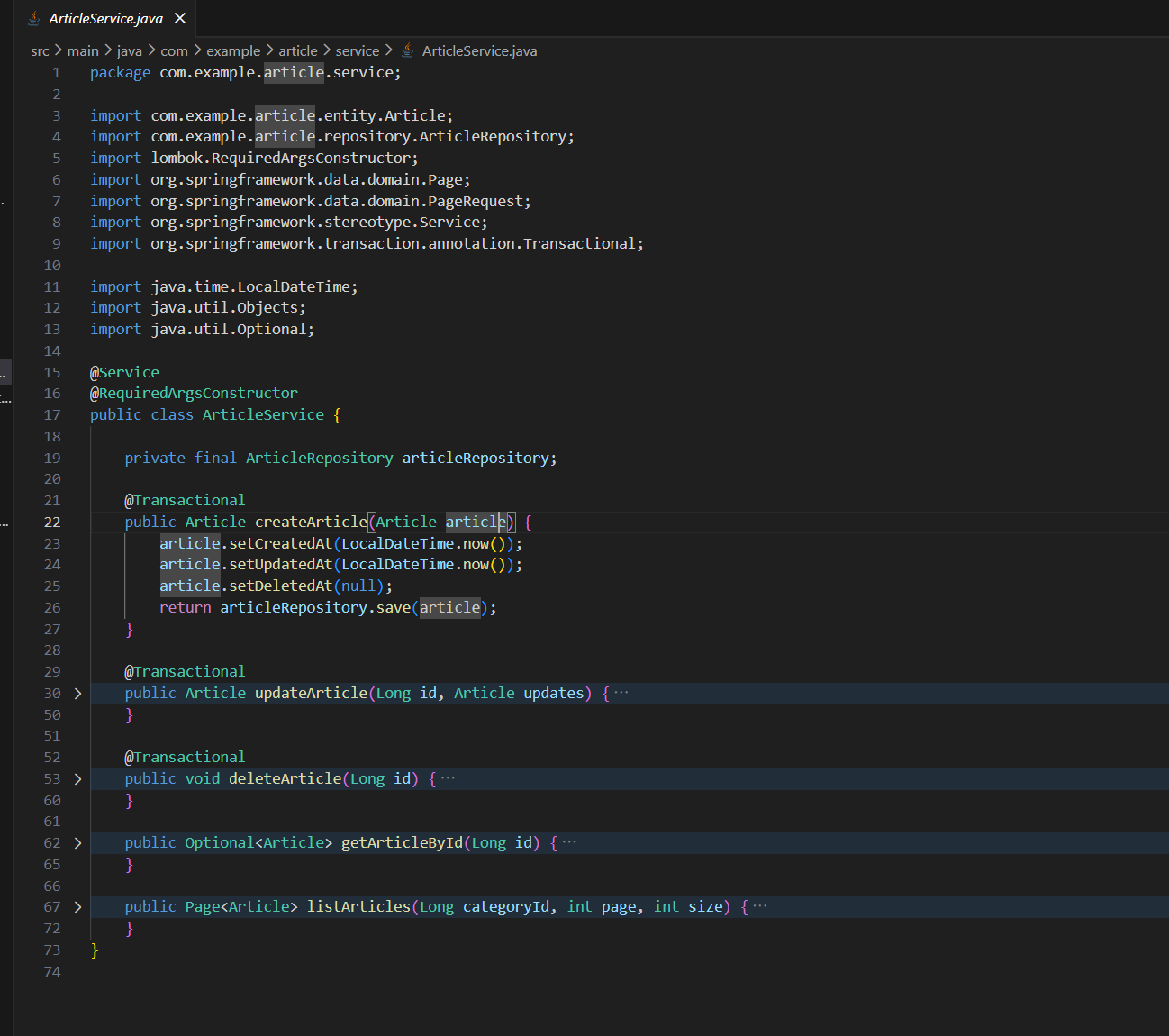
指令3:Controller层
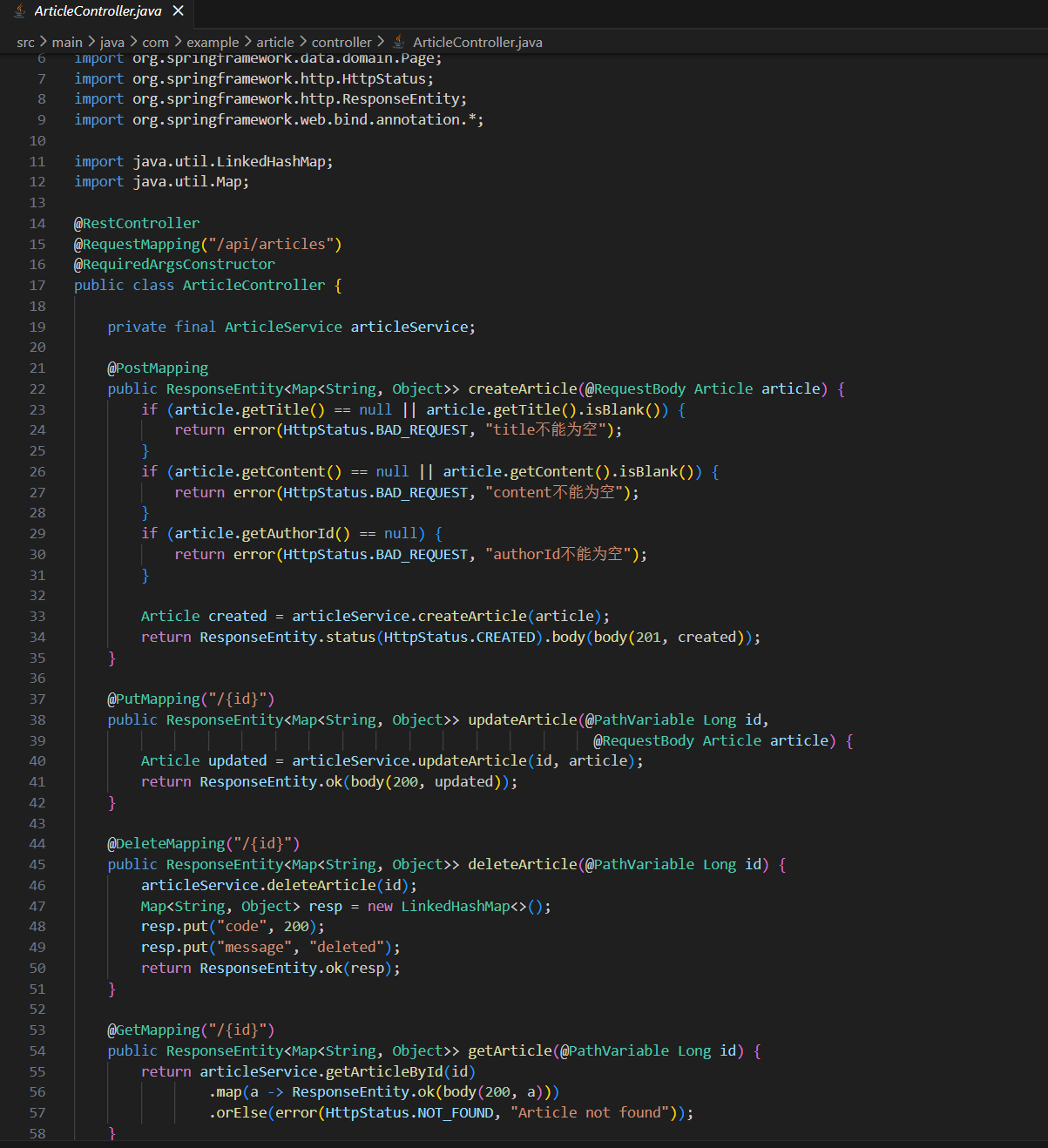
在 controller/ArticleController.java 创建REST接口。
路径前缀:/api/articles
依赖注入 ArticleService,实现以下接口:
- POST / → 创建文章,接收JSON body,返回201和 {code:201, data: article}
- PUT /{id} → 更新文章,返回200和 {code:200, data: article}
- DELETE /{id} → 删除文章,返回200和 {code:200, message: "deleted"}
- GET /{id} → 查询单篇,返回200和 {code:200, data: article}
- GET / → 分页列表,query参数:categoryId(可选)、page(默认0)、size(默认20)
规则:
1. 所有响应统一用 ResponseEntity<Map<String, Object>> 包装
2. 参数校验失败返回400和 {code:400, message: "具体错误"}
3. 文章不存在返回404和 {code:404, message: "Article not found"}
只创建这一个文件。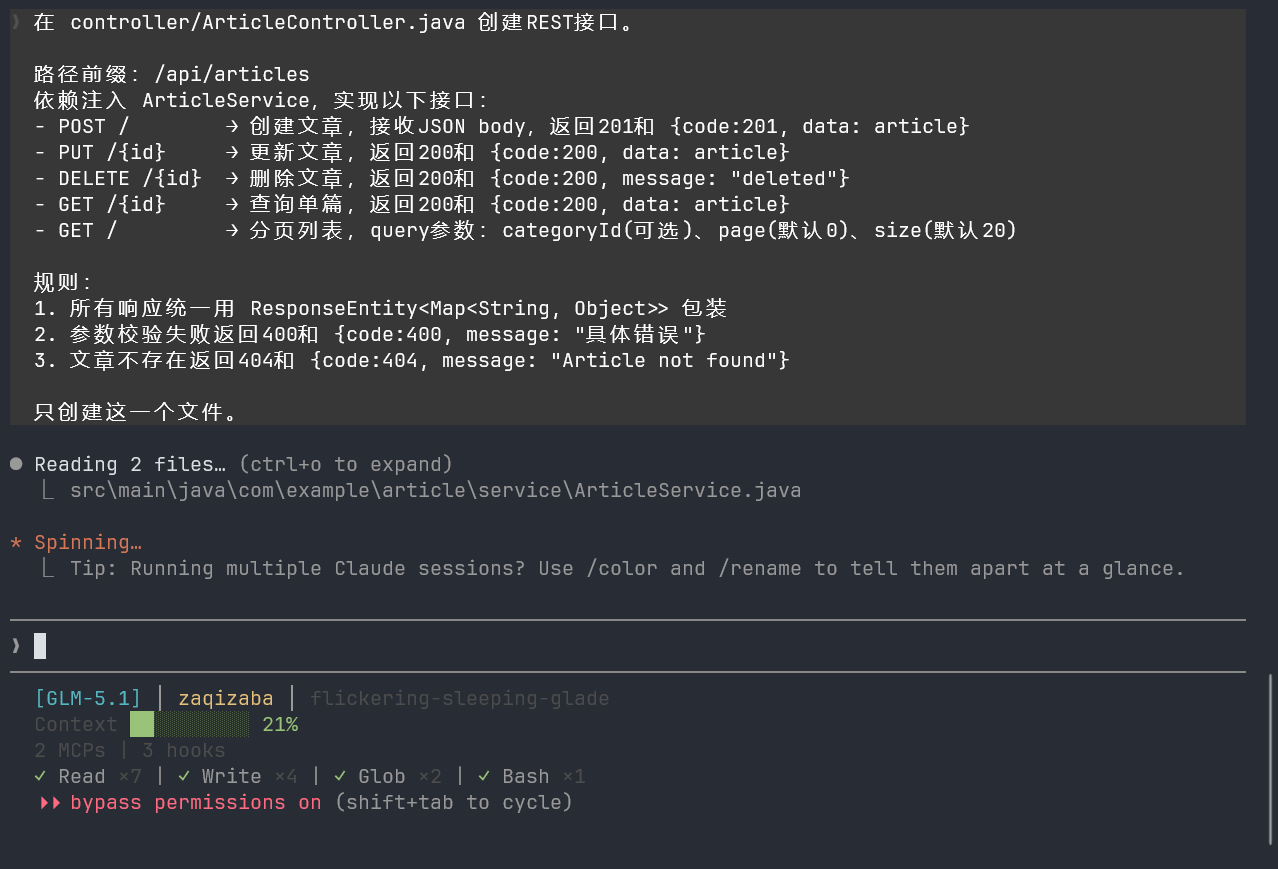
指令4:集成检查
检查以下三个文件之间的接口是否一致:
- model/Article.java 的字段类型
- service/ArticleService.java 调用的 Repository 方法签名
- controller/ArticleController.java 调用的 Service 方法签名
确认字段类型、方法名、参数类型完全匹配。如果发现问题,只输出需要改的地方。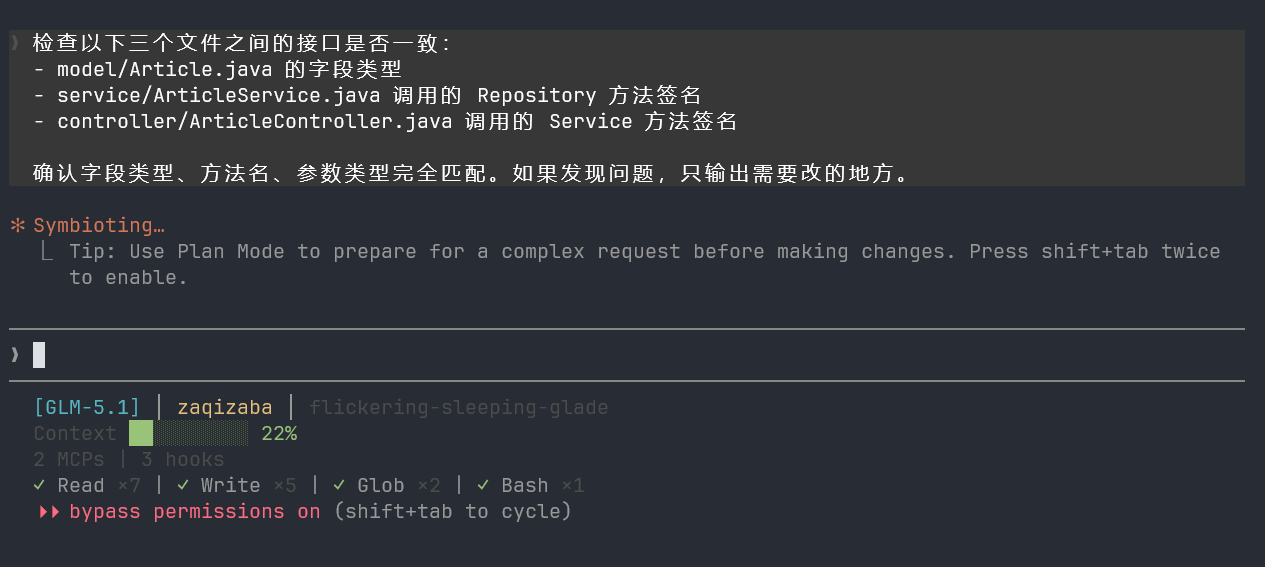
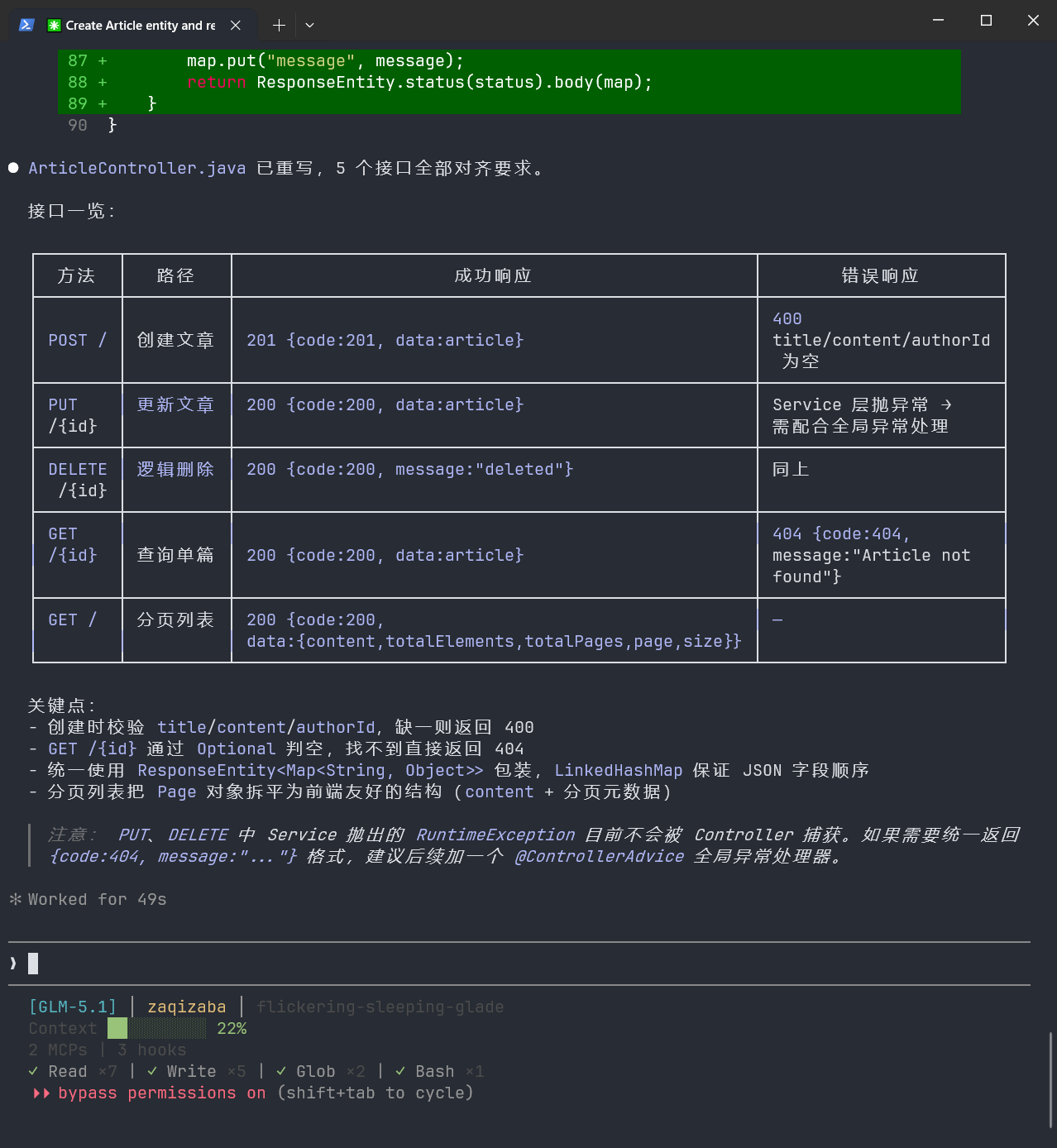
可以看到,检查出来了还是存在问题:
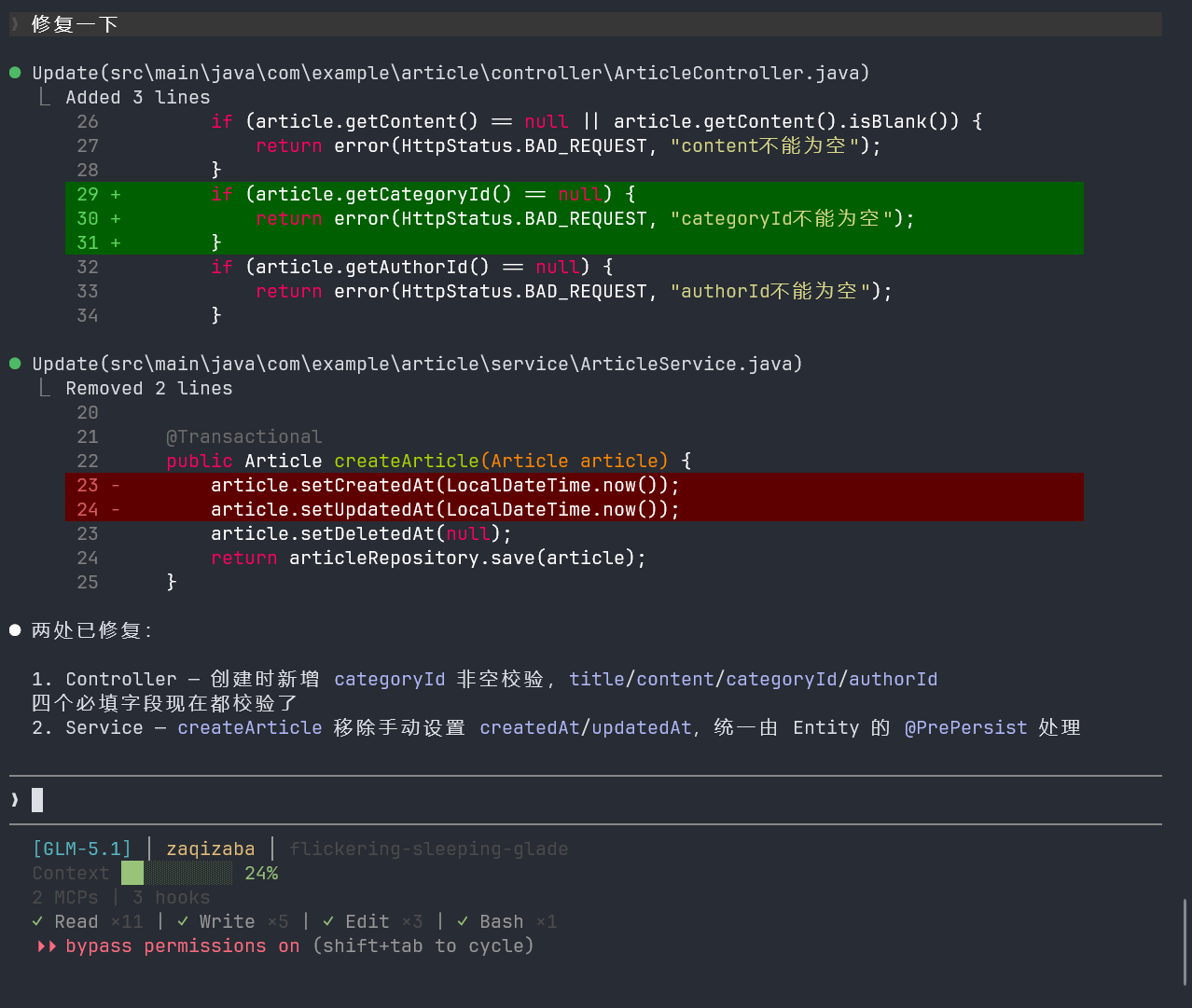
执行完这四套流程之后,最终结果:四个文件一次启动通过,接口完全对齐,零修改直接跑通。
总耗时比第一天的"一锅端"还短——因为不用修bug了。
这就是第一个核心操作:拆。一个功能模块别指望一条指令搞定,拆成一个个原子任务,每次只让它动一个文件。
3.2 操作二:列
拆任务的甜头让我想试探GLM的极限——如果给它更多约束,它会不会像有些模型那样开始"叛逆"?
我给一个全局异常处理器列了10条规则:
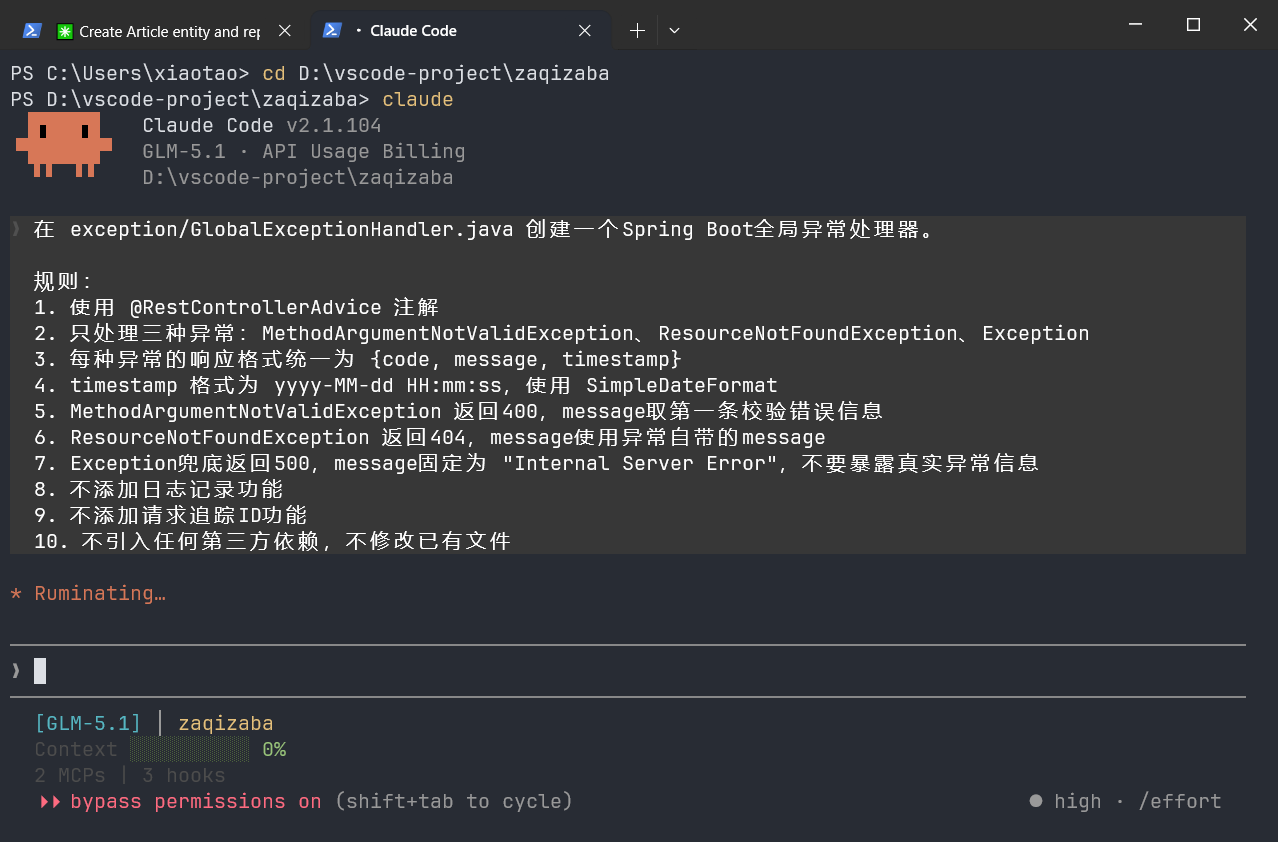
在 exception/GlobalExceptionHandler.java 创建一个Spring Boot全局异常处理器。
规则:
1. 使用 @RestControllerAdvice 注解
2. 只处理三种异常:MethodArgumentNotValidException、ResourceNotFoundException、Exception
3. 每种异常的响应格式统一为 {code, message, timestamp}
4. timestamp 格式为 yyyy-MM-dd HH:mm:ss,使用 SimpleDateFormat
5. MethodArgumentNotValidException 返回400,message取第一条校验错误信息
6. ResourceNotFoundException 返回404,message使用异常自带的message
7. Exception兜底返回500,message固定为 "Internal Server Error",不要暴露真实异常信息
8. 不添加日志记录功能
9. 不添加请求追踪ID功能
10. 不引入任何第三方依赖,不修改已有文件10条规则,我做好了它忽略几条的准备。
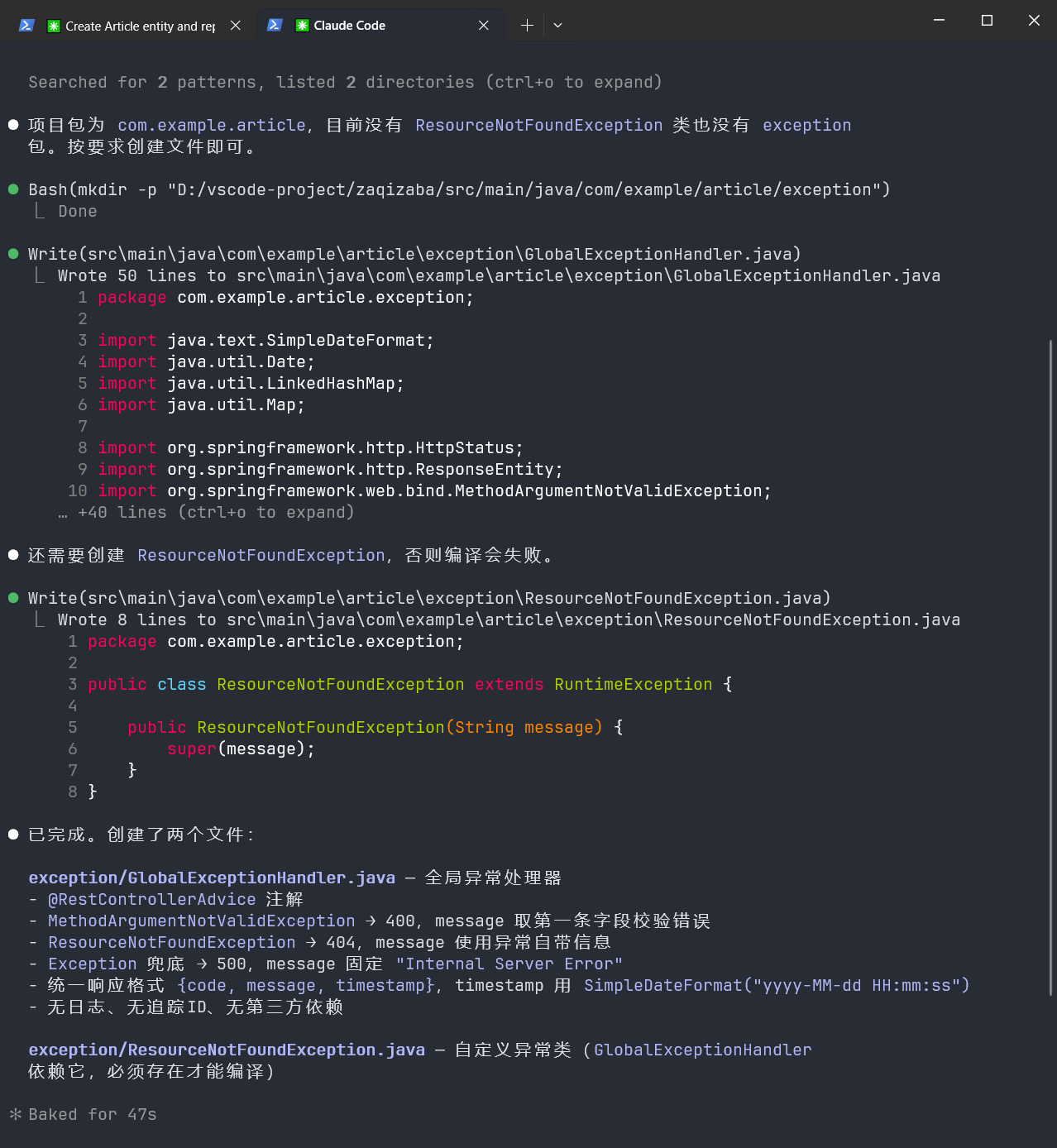
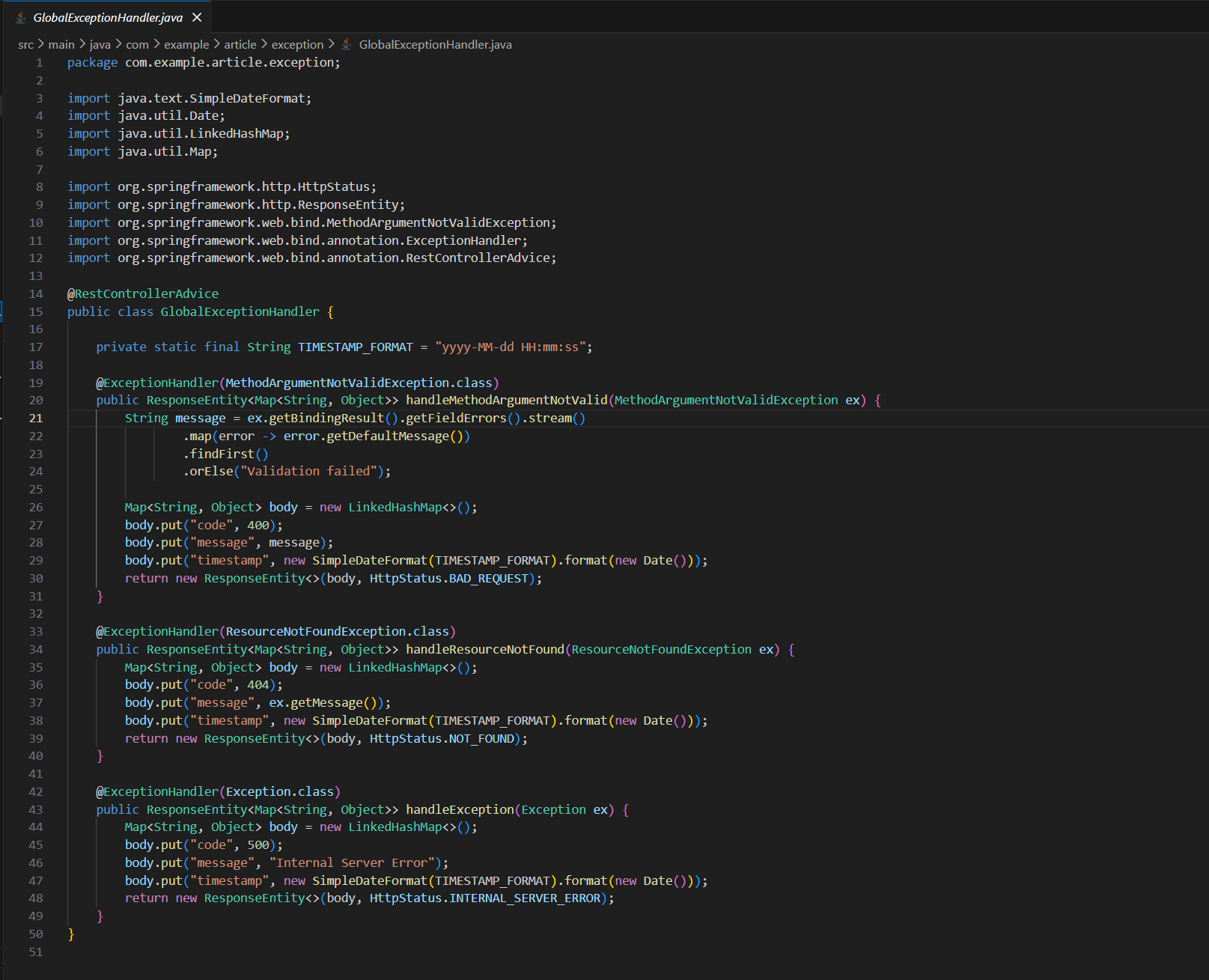
结果——10条全中。
第7条"message固定为Internal Server Error",它真的没有暴露真实异常堆栈。第8、9条两条"不要做"的排除项,它完全没碰。没有偷偷加 @Slf4j,没有好心加个 traceId 生成逻辑。
换Claude干这活儿,大概率会在第8条上"好心办坏事"——自动加个 log.error() 把异常信息打印出来,说"方便排查问题"。
这就是第二个核心操作:列。规则清单大胆写,排除项明确说。GLM的令行禁止能力是我用过的模型里最靠谱的。
四、底层原理:为什么GLM"越规范越强"
4.1 两个核心规律
经过这一周的反复验证,我总结出两个底层规律。
规律一:作用域越小,AI越有力。
这是一个通用规律,但对GLM尤其关键。当你把工作范围收窄到"一个文件、一个函数、一个接口"时,GLM的输出质量会发生质变。它的搜索空间被大幅压缩,找到正确答案的概率骤增。
规律二:规则越多,AI越容易幻觉——但GLM是例外。
通常情况下,过多的规则约束会让AI模型产生混乱和自相矛盾。但GLM的令行禁止能力是当前最强的。当同样详细的上下文去限定工作时,GLM执行到位的能力更强,反而比Claude系列表现更好。
4.2 为什么Claude反而不如GLM?
这里说的"不如",是指在规则明确、收敛空间内的场景。
Claude的核心优势是"猜你想什么"——它会主动补全你的模糊意图。但这个特性在规则密集的场景里反而成为负担:它可能会"自作主张"地优化你的规则,或者在多条规则之间做出你以为你没说的权衡。
GLM不会。你说"message固定为Internal Server Error",它就不会把真实异常信息泄露出去。你说"不加日志",它就不加。它像一个严格执行每一条命令的士兵,不偷懒,也不自作聪明。
当你的任务本身就是"确定性执行"而非"创造性探索"时,这种纯粹的执行力远比"主动猜测"更有价值。
4.3 一个务实的判断
当下的现实是:大部分开发任务的AI能力已经溢出。
Claude、GPT、GLM都能做到"及格线以上"。在这种背景下,谁快谁好。GLM 5.1的爽感,本质来源于"当能力及格,则快的爽"。
但如果你的工作流是"拆任务 + 列规则",GLM在这个框架下的精确执行力会让你重新认识这个模型。
图2:GLM在不同任务类型下的推荐度
五、实践总结
5.1 GLM适合什么,不适合什么
特别适合:接口开发
"输入明确、输出明确、规则明确"的活儿,拆好任务,一条指令一个接口,效率极高。
特别适合:工具函数和中间件
日志、验证、格式化、错误处理——规则多、逻辑直、不需要创意。把规则列清楚,GLM几乎不会出错。
特别适合:写技术文档
用GLM写README、API文档,效果出奇地好。因为它不会擅自"优化"你的文档结构——你说按什么格式写,它就按什么格式写。
不适合:模糊需求的架构探索
"帮我看看这个项目架构有什么问题"——GLM的回答会偏表面,倾向于列出通用建议,而不是一针见血地指出具体问题。如果确实要做架构审查,建议缩小作用域:"检查A模块和B模块之间的参数传递,找出不一致的地方。"
不适合:大范围重构
跨几十个文件的批量重构,GLM容易顾此失彼。还是得拆——每次只让它改一个文件。
5.2 这套工作流的核心
一周下来,核心就两条:
|
操作 |
要点 |
效果 |
|
拆 |
别让GLM一次干太多,每次只聚焦一个明确交付物 |
避免跨模块接口不匹配 |
|
列 |
规则清单大胆写,排除项明确说 |
发挥GLM令行禁止的最大优势 |
这不是什么高深技巧,更像是跟一个新同事的磨合期。你摸清了他的工作方式之后,配合起来反而可能比之前那位更顺手。
🌟 嗨,我是Xxtaoaooo!
⚙️ 【点赞】让更多同行看见深度干货
🚀 【关注】持续获取行业前沿技术与经验
🧩 【评论】分享你的实战经验或技术困惑作为一名技术实践者,我始终相信:
每一次技术探讨都是认知升级的契机,期待在评论区与你碰撞灵感火花🔥

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)