给 Claude Code 一个任务,它的内部发生了什么?
从外层的 Supporting Systems 支撑基建,到内层无限流转的query_loop,Claude Code 的强大源于其严密且克制的系统工程。技术概念的浪潮总是一波接着一波,但底层的本质却始终如一。希望这篇文章,可以帮助你从底层拨开 Agent 的迷雾,在动手落地的路上走得更稳一点。😊。
开篇
最近在学习拆解 Claude Code 的底层源码。面对几十万行的代码,一开始确实会有一种无从下手的感觉。
但再复杂的系统,也一定有它的主心骨。这篇文章,不是把整个项目讲一遍,而是切入它最核心的部分:query_loop。把这个的逻辑理解清楚了,其他外围的支撑基建也就顺理成章了。
希望这份从整体架构到核心query_loop的梳理,能对你在学习 Claude code 的过程中有所帮助~
一共会分为以下两部分:
-
Claude code 的两层分工架构
-
深入query_loop:一次请求到底经历了什么?
Claude Code 的两层分工架构
在之前的文章《拆穿tools=tools:从工具调用到Deep Research架构》中提到过工具调用的本质。其实在 Claude Code 的整体架构设计中,这种分工合作的理念体现得更加淋漓尽致。
Claude Code 项目的本质,是一个工作流驱动的 AI Agent 系统。可以把它拆解为一个极简公式:
Claude Code = LLM + Harness
除了模型,其他部分都是harness。😨 那这个 Harness 具体都包含了些什么呢?👇
下面这张架构图把它划分为了内外两层:Runtime(内层运行时) 和 Supporting Systems(外层控制层)。
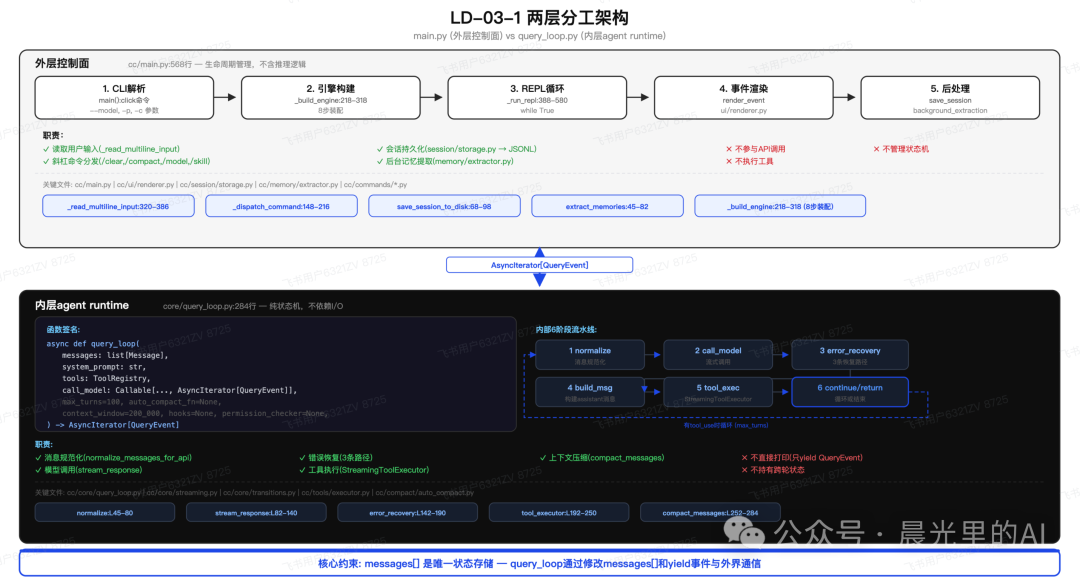
1、Runtime(运行时主循环)
👉 这是系统的核心,也是整个 Agent 动起来的引擎。
它本质上就是 query_loop,是真正干活的车间流水线。在这个循环里,包含了:
-
messages/transcript的状态流转 -
模型调用与流式事件消费(Model Streaming)
-
tool_use与tool_result的工具执行与结果回写 -
回合的推进(Turn)以及退出条件判断(Stop_reason)
-
当然,还包括为了保障循环不崩溃的容错机制(如 retry、max_turns 和触发式的 compact)。
可以把它想象成一个项目经理,不断地在客户(User)、大脑(LLM)和跑腿小弟(Tools)之间来回搬运信息,直到项目节点(Stop_reason)达标为止。(这部分也是下一章重点拆解的内容~)
2、Supporting Systems(支撑系统)
如果说上面的 Runtime 是工作流水线,那这一层就是保障车间运转的基建与后勤库。
模型不能在真空中运转,🙂↔️它需要手脚,也需要备忘录和安全员。这个外层的支撑系统就由下面这些模块装配而成,可以分为四个维度:👇
1. 入口与装配:
比如 main.py、REPL 交互界面和 QueryEngine。
👉 它负责解析用户的输入并准备初始环境,可以把它理解为系统的「任务发布大厅」。
2. 能力系统:
包含了 tools、AgentTool 抽象层以及 MCP 协议。
👉 它们负责把「读写文件」、「搜索网络」等复杂动作,封装成模型看得懂、调得动的 API。
3. 约束扩展:
包含了 permissions(权限校验)、hooks(生命周期钩子)以及 prompt sections(局部提示词)。
👉 它们是系统的「安全护栏」,防止模型失控或越权执行危险代码。
4. 持久化上下文:
包括 memory(记忆提取)、session(会话持久化)、compact(上下文压缩)以及 prompt builder。
👉 它们构成了 Agent 的「长短期记忆库」,决定了系统能记住什么、该忘记什么。
总结一下~
代码(Runtime)搭建了骨架,决定了流程怎么跑;模型(LLM)只是在特定节点被唤醒做决策;Prompt 负责设定每个阶段的行为边界;而工具(Tools)和记忆(Memory)则是被随时调用的客体。
深入query_loop:一次请求到底经历了什么?
建立起全局的认知后,下面就来看看系统中最核心的部分:query_loop。
这个 query_loop 本质是一个 while(True) 的状态机循环,每次迭代主要经历四个核心阶段。
比如以一个真实场景为例:用户输入“帮我看看 README.md 里写了什么”。👇(下面是一段伪代码,会更方便理解~)

通过这段伪代码,我们可以看到整个过程的数据流转:
-
用户输入:被包装成 UserMessage 追加到 messages 列表中。
-
Phase 1 整理:由于大模型是失忆症患者,每次都要把整个 messages 列表发给它。所以发送前必须做 normalize ,确保对话总是 user/assistant 交替的合法格式。
-
Phase 2 决策与行动:模型开始输出。在这里,系统并没有呆呆地等待模型把所有字打完,而是采用了流式分发。当识别到安全的读取类工具被触发时,直接让 Python 脚本这个跑腿小弟并发去执行,极大提升了响应速度。
-
Phase 4 结果回填:这是理解 Agent 的最关键一步。Python 脚本执行完读取 README 文件的操作后,代码会将读取到的文件文本打包成 ToolResultBlock,并伪装成 UserMessage 塞回 messages 列表。
-
进入下一轮:带着带有文件内容的完整上下文,再次进入 query_loop。模型这次看到上下文里有足够的信息了,决定直接总结回答,并输出 stop_reason == "end_turn",循环终止。
理清了上述的流转逻辑后,再进一步想一想,当模型输出end_turn,跳出这个无限循环后,它这一路的思考和动作,也就随着函数结束而消失了吗?
这个问题呼应了之前的文章《上下文不等于记忆》中探讨过的上下文与记忆的核心差异。在 query_loop 里,记忆的沉淀悄然发生在了这两个关键节点:
1、短时上下文的「快照浓缩」
在 Phase 1,如果粗略估算token预算快要触顶,系统就会触发压缩算法。它不会粗暴截断旧记录,而是将旧消息总结成一条边界消息。
这就像是会议室的白板写满了,项目经理把过往讨论提炼成一张摘要便签贴在角落,然后继续开会。
👉 这是低成本将「上下文」转化为「记忆」的第一步。
2、任务结束的「本地轻量归档」
当主循环彻底结束,这条包含完整链路信息的 Transcript 会被存入文件。
👉 这里没有选择向量数据库,而是使用「本地保存 + 渐进式加载」的极简设计,完美支持了Rewind(回退)机制:一旦用户需要撤销某步操作,底层的记忆状态机会精准回滚,不会留下任何干扰数据。
总的来看,cc内部所谓的神奇能力,拆开来看,不过是一次次严谨的状态维护、API请求、本地代码执行、字符串的拼接,以及将每一次交互的结晶,稳稳地沉淀进本地档案中。💼
最后
从外层的 Supporting Systems 支撑基建,到内层无限流转的 query_loop,Claude Code 的强大源于其严密且克制的系统工程。
技术概念的浪潮总是一波接着一波,但底层的本质却始终如一。
希望这篇文章,可以帮助你从底层拨开 Agent 的迷雾,在动手落地的路上走得更稳一点。😊

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)