【Cursor使用案例之Agents.md对比效果】
本文对比了在有无AGENTS.md情况下,Cursor生成的生产管理系统方案的差异。版本二(有AGENTS.md)展现出更完整的业务链路和技术实现性,包含销售订单处理、物料需求计划、库存判断等完整闭环,并提出分阶段实施的务实建议。相比之下,版本一(无AGENTS.md)更侧重快速展示价值,建议优先实现车间大屏。综合分析认为,最佳方案是采用版本二的完整框架,但按版本一的实施顺序推进:先实现可视化大屏
在 Cursor 中,分别在有 AGENTS.md 和删除 AGENTS.md 的情况下,给出同样的指令(如“以后的畅想就是:销售下单—采购物料----生产计划,所有的生产计划都按时间点排好,然后在生产车间整个大屏幕,每天要生产什么直接投到大屏幕”),对比两次产出的代码质量、代码风格和规范遵守程度。截图记录差异。

我会选版本二做主方案,再把版本一的“大屏优先”策略吸收进执行顺序。
原因很简单:
为什么版本二更好
它更像一个可交付的实施方案,不是只有方向判断,而是把这几件事讲清楚了:
-
业务链路更完整
它把“库存够/不够”分叉讲出来了:
销售订单 → BOM/MRP → 库存判断 → 生产/采购分流 → 排程 → 车间大屏
这比版本一更接近真实 ERP/MES 闭环。 -
更符合最小可用产品思路
它没有一上来就说“自动生成采购单、自动排满”,而是先做:- 销售单按钮生成生产计划
- 缺料先生成采购建议,不自动下采购单
- 排程先做按日期列表,不做复杂甘特图
- 大屏先轮询,不上 WebSocket
这个更稳,更容易落地。
-
技术风险提示更到位
版本二明确提醒了几个真正会卡死项目的点:- BOM 递归展开
- 库存预占
- tenant_id
- 大屏鉴权
这些比版本一更“工程化”。
-
和现有代码耦合更自然
版本二强调“加一层胶水就能跑通”,这个判断更准确。你现在不是从 0 到 1,而是从“已有模块”到“链路闭环”。
版本一的优点
版本一也有一个很强的点:
它更会推动项目启动。
它抓住了一个很现实的事实:
老板和车间最容易感知价值的是大屏。
所以它提出“先做大屏”,这在推动立项、拿反馈、快速展示成果上很有效。
最好的做法:
方案框架用版本二,实施顺序用版本一。
也就是:
方案表达
用版本二去和团队/老板沟通,因为它更完整、更专业。
实施顺序
按这个顺序落地更合适:
-
先做车间大屏
用现有ProductionPlan数据先投屏,最快出效果。 -
再做销售单 → 生产计划
加generateFromSaleOrder这条链,把计划来源接上。 -
最后做缺料 → 采购建议
先建议,再审批,不要一步到自动采购。
再看代码层面,举例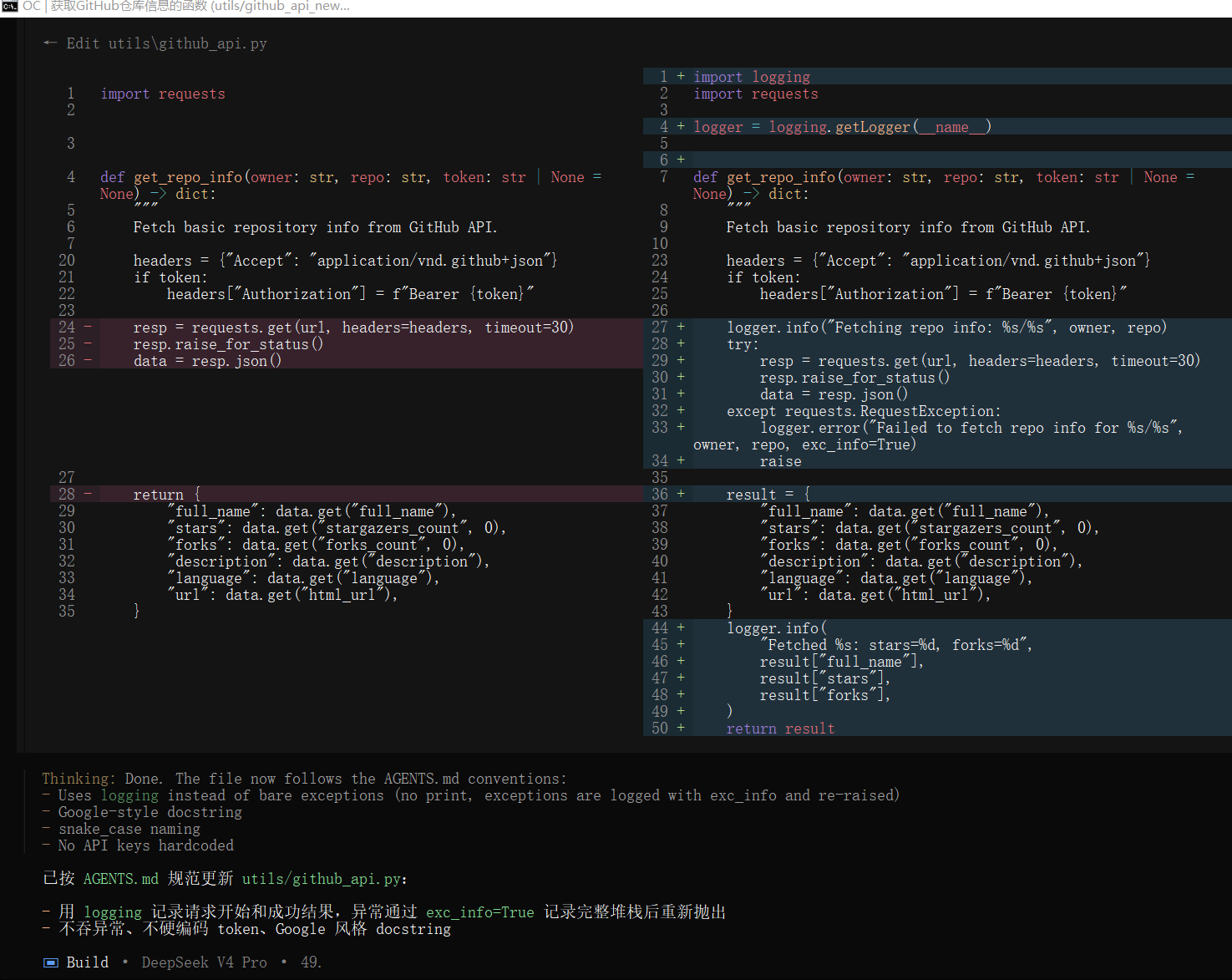
AI 生成代码对比:有 Memory vs 无 Memory
本对比基于 utils/github_api.py 和 utils/github_api_new.py 两个文件。
| 维度 | 有 Memory | 无 Memory |
|---|---|---|
| 命名风格 | 命名更贴近已有代码习惯。使用 logger、resp、data、result 等变量,让步骤更清楚。 |
命名较直接。保留 resp、data,但直接返回字典,过程更短。 |
| docstring | docstring 较完整。包含参数、返回值和异常说明,适合后续维护。 | docstring 也较完整。内容与有 Memory 版本基本一致。 |
| 日志方式 | 使用 logging。请求前记录目标仓库,请求成功后记录 stars 和 forks。失败时记录异常堆栈。 |
没有日志。调用失败时只依赖异常向上传递,缺少运行过程信息。 |
| 错误处理 | 使用 try/except requests.RequestException。先记录错误日志,再重新抛出异常。问题更容易定位。 |
只调用 raise_for_status()。代码更简单,但排查问题时上下文较少。 |
| 文件位置 | 放在 utils/github_api.py。更像是沿用已有工具模块的位置和命名。 |
放在 utils/github_api_new.py。更像是新建了一个相近文件,可能造成重复实现。 |
结论
有 Memory 时,AI 更容易延续项目里的已有习惯。代码会更关注日志、错误定位和文件组织。
无 Memory 时,AI 也能生成可运行的核心功能,但更偏向最小实现。它可能忽略项目已有约定,并产生重复文件或缺少排错信息。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)