Claude Code 升级 4.7 后,同样的代码 token 翻了快一半,你的配额还够用吗?
现在拆开了,模型能分别注意到每个部分。核心原因不是单价变了,而是同样的会话内容变成了更多的 token,缓存读取是大头,平均缓存前缀从 86K token 涨到了 115K,每轮都多读这些 token,80 轮下来差距就出来了。如果工作场景对指令精度要求高,复杂的多步骤任务、严格的格式要求、长链路的自动化流程,4.7 的改进是有价值的,少一次格式错误可能省下好几轮重试的 token。Max 的配额
点击上方卡片关注我
设置星标 学习更多AI出海知识
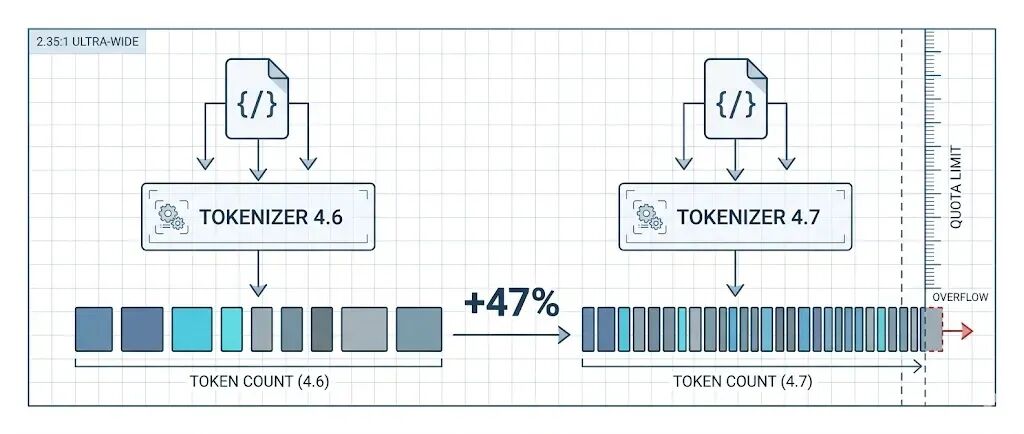
上周 Anthropic 发了 Claude Opus 4.7,升级指南里有一句不太起眼的话:“新 tokenizer 使用的 token 数大约是 4.6 的 1.0 到 1.35 倍。”
听起来没什么,但有人拿真实数据测了一遍,发现官方给的范围太保守了。
实测数据
claudecodecamp 的作者用 Anthropic 官方的 count_tokens API,拿同一份内容分别过 4.6 和 4.7 的 tokenizer,纯粹比较 token 数量的差异。
先看 Claude Code 用户日常接触最多的内容类型:
CLAUDE.md 文件(5KB):4.6 是 1399 个 token,4.7 是 2021 个。涨了 44.5%。
用户 prompt:涨 37.3%。Markdown 博客文章:涨 36.8%,Git commit log:涨 34.4%,终端输出:涨 29.1%。Python stack trace:涨 25.0%。代码 diff:涨 21.2%。
七类内容加权平均:1.325 倍。
再看 12 种标准内容类型:
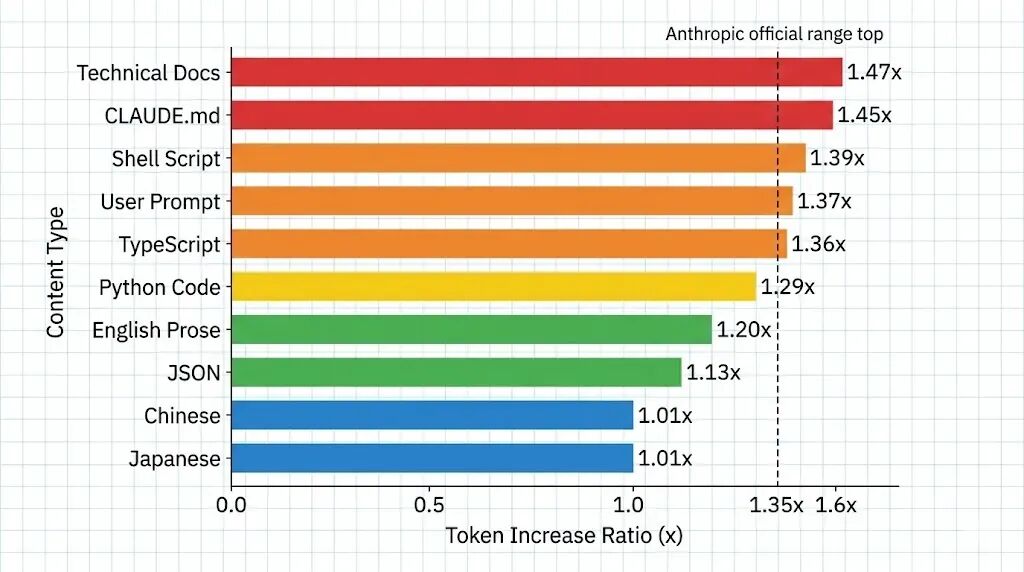
涨幅最大的:英文技术文档 1.47 倍,Shell 脚本 1.39 倍,TypeScript 1.36 倍。
涨幅最小的:中文 1.01 倍,日文 1.01 倍,CSV 数据 1.07 倍。
一个规律很明显:英文和代码涨得最多,中日韩文几乎没变。
为什么 token 变多了
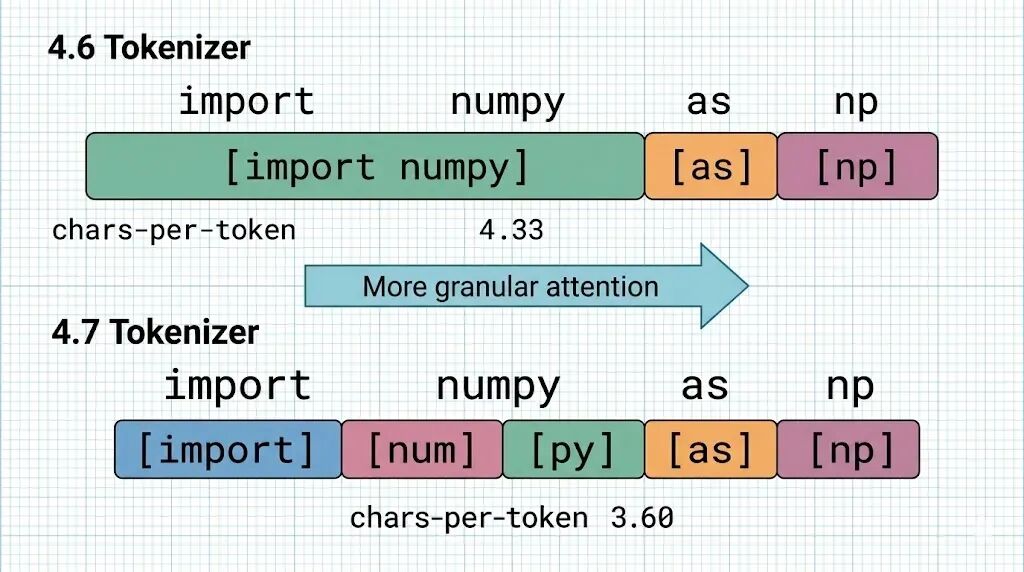
tokenizer 的核心是 BPE(Byte-Pair Encoding),简单说就是把常见的字符组合合并成一个 token,出现频率越高的组合合并得越长。
4.7 的 tokenizer 反过来做了,把一些长合并拆短了。
直观感受:英文的每 token 字符数从 4.33 降到了 3.60。TypeScript 从 3.66 降到 2.69,同样的文本,切成了更多更小的碎片。
代码比英文散文受影响更大,原因是代码里重复的高频字符串多——关键字、import 语句、变量名,这些正好是 BPE 会合并成长 token 的东西。拆短之后,这些地方涨幅最大。
中日韩文没怎么变,说明新 tokenizer 主要改了拉丁字母和代码相关的词表,非拉丁部分基本保留了。
Anthropic 为什么要这么做
同样的内容多花 token,价格不变,配额不变,Anthropic 显然是拿 token 换了什么别的东西。
官方说法:更精确的指令跟随,特别是在低 effort 模式下,模型不会默默地把一个条目的指令泛化到另一个条目上。
原理不难理解:token 越短,attention 能关注到的粒度越细,以前一个长 token 可能把 import 和后面的模块名粘在一起,模型只能整体理解。现在拆开了,模型能分别注意到每个部分。
这位作者还跑了 IFEval 测试来验证,结果:严格模式下 4.7 比 4.6 高了 5 个百分点(85% → 90%)。宽松模式持平。
提升不大,但方向一致,真正分出胜负的场景是多约束链式指令,比如一个 prompt 同时要求全大写、包含特定词、控制字数、指定格式,4.6 容易在其中一个约束上翻车,4.7 更稳。
一次会话贵了多少
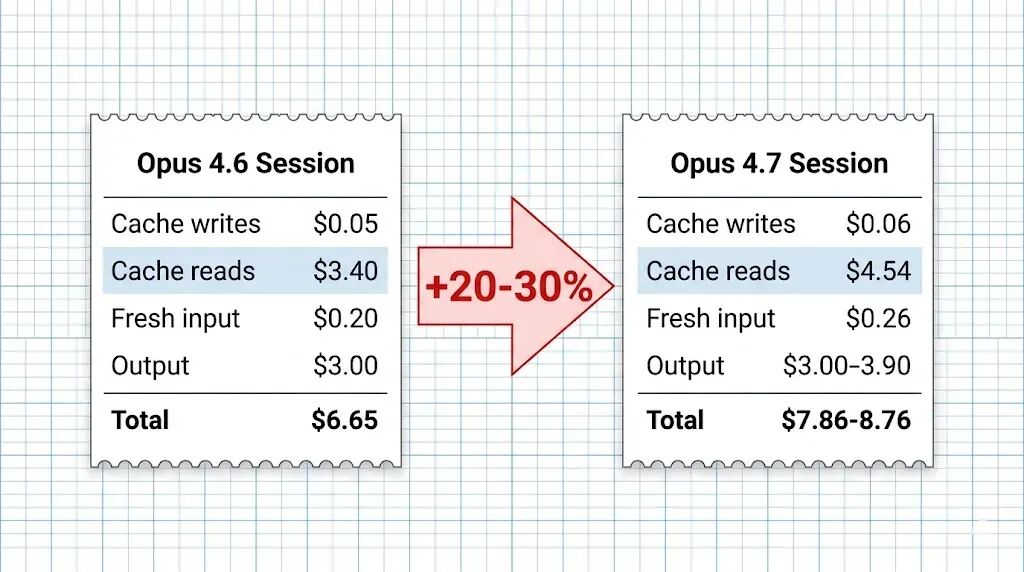
作者算了一笔很实在的账,假设一次 80 轮的 Claude Code 会话:
4.6 的成本:大约 $6.65。
4.7 的成本:大约 8.76。
贵了 20% 到 30%。
核心原因不是单价变了,而是同样的会话内容变成了更多的 token,缓存读取是大头,平均缓存前缀从 86K token 涨到了 115K,每轮都多读这些 token,80 轮下来差距就出来了。
对 Max 用户的影响更大
API 用户受的是成本影响,Max 计划的用户受的是配额影响。
Max 的配额按 token 数算,不按美元算,同样的工作量消耗更多 token,意味着你的 5 小时窗口更快用完。
一个在 4.6 上能跑满窗口的会话,换到 4.7 可能提前耗尽配额。
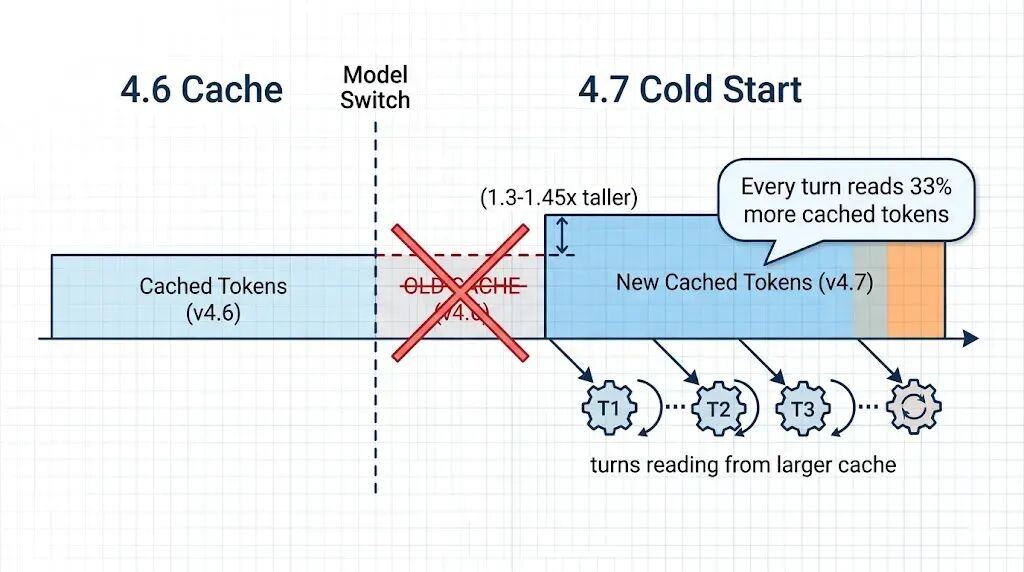
缓存也受影响
第一次用 4.7 必须冷启动,Anthropic 的缓存按模型分区,从 4.6 切到 4.7 会让所有缓存前缀失效,而且冷启动写入的前缀比 4.6 大 30% 到 45%。
缓存体积按比例增长,CLAUDE.md 部分多了 44.5% 的 token,每轮缓存读取也多读这么多。
历史 token 数不再可比,如果你的监控或计费是基于历史 token 数做基线的,切模型当天会看到一个阶跃变化。
值不值
这是一个典型的工程权衡:用更多的 token 换更精确的指令跟随。
如果工作场景对指令精度要求高,复杂的多步骤任务、严格的格式要求、长链路的自动化流程,4.7 的改进是有价值的,少一次格式错误可能省下好几轮重试的 token。
如果主要做简单的问答或者短会话,这个 20-30% 的成本增加可能感知不明显。
一个实用建议:如果你用 API,可以自己跑一下 count_tokens 对比,看看你的典型输入在两个模型之间的差距是多少。
三行 Python 就能测:
from anthropic import Anthropic
client = Anthropic()
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
r = client.messages.count_tokens(
model=model,
messages=[{"role": "user", "content": your_text}],
)
print(f"{model}: {r.input_tokens} tokens")这样你能精确知道自己的场景受多大影响,而不是看别人的平均数。
欢迎关注,这个账号还会持续分享更多AI编程、出海工具、实战经验、踩坑记录。
想了解更多可以加我 vx: 257735 聊。

出海赚钱案例:一个人做了个开源UI库,不融资不投广告,45天30万美元
出海赚钱案例:一个人用 PHP 做到月入 17 万美金,利润率 99%!
(2026年最新)Codex CLI 国内使用全攻略:终端 + VSCode + Cursor + Opencode 四种姿势全搞定

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)