Claude Code 省 Token 终极指南:同样干活,3k 和 30k 的差距藏在这些细节里
前言
用 Claude Code 一段时间之后大概都会注意到,同样实现一个功能,有人 3k token 搞定,有人要烧掉 30k。差距不在 Claude,而在使用方式。
这篇指南就聚焦4个核心问题,帮你吃透省Token的关键:
-
你花的每一笔Token,到底消耗在了哪里
-
你输入内容的方式:正在悄悄浪费Token
-
Claude 的干活方式:也会隐性消耗Token
-
你安装的基础设施:正在每一轮对话中静默消耗Token
读完应该能看懂 /cost 输出、知道怎么配 .claude/settings.json、改掉 3–5 个正在烧 token 的对话习惯。
一、先搞懂:你花的每一笔Token,到底消耗在了哪里
基础认知|一次对话的 input,是个"不断扩张的包"
Claude API 按 input + output 分开计费。input 是你发给 Claude 的所有内容,output 是 Claude 生成的回复。Input 单价更便宜,但累积量大;output 单价贵,但量小。
很多人以为自己发出去的就是那一行问句,实际上 Claude Code 每次请求带过去的内容远不止此。常见的"塞进 input 的东西"包括:
-
System prompt: Claude Code 自带的系统指令
-
CLAUDE.md: 你项目里的约定文件
-
扩展声明: 启用的 MCP / Skills / Plugins 等的 name、description、参数 schema
-
历史对话: 从 session 开始到现在的所有消息
-
工具结果: Read / Grep / Bash 返回的内容
-
当前这一轮的 user 消息
这份清单还会继续长。Claude Code 每加一个新能力,input 就多一类来源。
这些可以分为4类:
-
系统侧:System prompt + CLAUDE.md + MCP / Skills 等扩展声明(固定开销)
-
历史侧:之前的对话消息(越聊越贵)
-
工具侧:Read / Grep / Bash 等返回的内容(最容易失控)
-
当前侧:你这一轮说的话
工具侧决定单轮会不会突然爆炸,历史侧决定会不会"聊着聊着越来越贵"。
关键机制|Prompt Cache:直接省 50% 成本的隐藏技巧
Prompt Cache 的简化版规则:
从 system prompt 开始的前缀,如果和最近某次请求完全一致,这部分 input 的价格只需要 10%(只付读取费用,不付重新计算的费用)。
算一下:如果你的 system prompt + CLAUDE.md 一共 5k token,每轮对话这 5k 都命中 cache,实际只花了 500 token 的价格。
命中条件有 3 个,缺一不可:
-
前缀字节完全一致: 任何一个字符变化,从变化点开始往后的所有内容都 cache miss
-
同一个模型:cache 是按模型隔离的,sonnet 写的 cache,opus 读不到
-
在 TTL 内: Claude Code 默认走 5 分钟档(Anthropic API 还有 1 小时档,但 write 要付 2× 价格,CC 默认不开)
必学技巧|看懂 /cost 输出,快速定位 Token 浪费点
Claude Code 里随时可以 /cost,输出长这样:
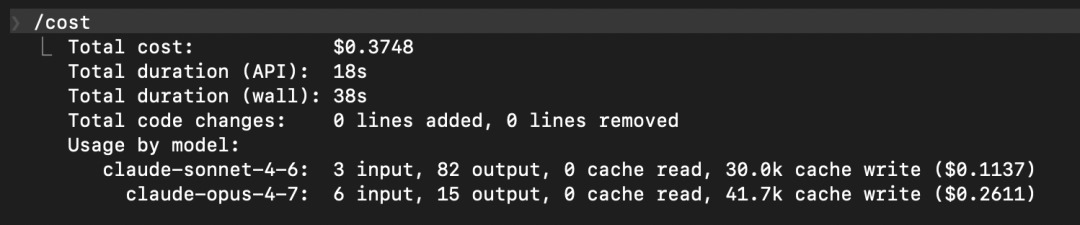
-
按模型分开列:当你启动了不同模型的subagent,会出现混合调用,不同模型的收费价格不一样
-
input / output 是全价:数字越小越好
-
cache read 越高越好:这部分只付 10% 价格
-
cache write 越低越好:每次 write 都是全价,只有后续命中 read 才能摊销回来
二、踩坑预警:你输入内容的方式,正在悄悄浪费Token
坑 1:大段非结构化文本直接贴(最普遍的烧钱操作)
最普遍的烧钱方式:把一坨没整理过的文本直接塞给 Claude。
你把 3000 行原始日志整段粘贴过去,Claude 拿到之后第一件事也是"从噪音里挑出关键那几行",得到的结论和你先筛到 30 行再发几乎一样。
最典型的场景是崩溃日志整段粘贴。"我把日志贴给你看看。"adb logcat -d 几千行;服务端 access log + error log 整段拽过来;某个进程从启动到崩溃的全部输出整段贴。
真正有诊断价值的 stack trace 通常只占 5%–20%,剩下全是时间戳、线程号、ActivityManager / Choreographer / dispatcher 这类系统噪音。
同样的思路适用于 git diff 整段贴、让 Claude 跑 build / test 时几千行输出全进 context 等场景。要么你先 grep / tail / --stat 过滤再贴,要么把规则写进 CLAUDE.md,让 Claude 跑长输出命令时默认带 | tail -100 或 | grep -E "ERROR|FAIL"。
下面举个例子:
方式 A: 如果你一股脑将所有报错日志贴上去问 帮我看看这个crash是什么原因,修复建议是什么?
35.1k input, 1.2k output, 0 cache read, 61.5k cache write
方式 B: 如果你换个方法,通过 grep -E "FATAL|Exception|^\s+at\s" crash.log 只是将异常的出现关键信息输出并且提供。
636 input, 687 output, 25.6k cache read, 1.5k cache write
900 行 logcat 整段粘贴 ~35k input vs grep 过滤后 ~0.6k input 约 55 倍差距
坑 2:开放式提问 vs 精准提问(差 3 倍 Token 的细节)
把你已经知道的信息前置给 Claude,这几乎是最简单的省钱动作:知道要动哪个目录、哪个文件、哪个函数,就直接说。
对比两种提问:
-
开放式:"帮我了解一下这个项目的整体结构",Claude 会 ls、Read README、Grep 关键文件、Read 核心源码,10+ 次工具调用很正常
-
精确式:"
src/services/下有哪些文件,分别 export 什么",2–3 次工具调用搞定
开放式提问
963 input, 2.5k output, 234.7k cache read, 32.2k cache write
精确式提问
435 input, 1.4k output, 83.1k cache read, 29.8k cache write
同一个项目,开放式提问 ~235k cache read vs 精准提问 ~83k cache read 约 3 倍差距
坑 3:挤牙膏多轮 vs 一次说清(多轮对话的隐形浪费)
多轮对话 ≠ 多次独立请求。每一轮的 input 都包含前面所有轮次的完整历史。
不是禁止多轮对话,如果是新需求、真的改变思路的多轮是合理的。但你一开始就知道要什么,就一次说清楚。
演示一下:
使用多轮对话
分 5 轮依次向 Claude Code 发送需求,每一轮都基于前一轮的结果继续补:
-
第 1 轮:
帮我写一个 React 登录表单 -
第 2 轮:
加上邮箱格式校验 -
第 3 轮:
密码要检查强度(长度 8 位以上,包含大小写和数字) -
第 4 轮:
错误提示改成 toast 形式 -
第 5 轮:
样式用 Tailwind 重写一遍
每轮结束后执行 /cost 记录一次累计消耗。最终 5 轮完成后的 /cost 截图如下:
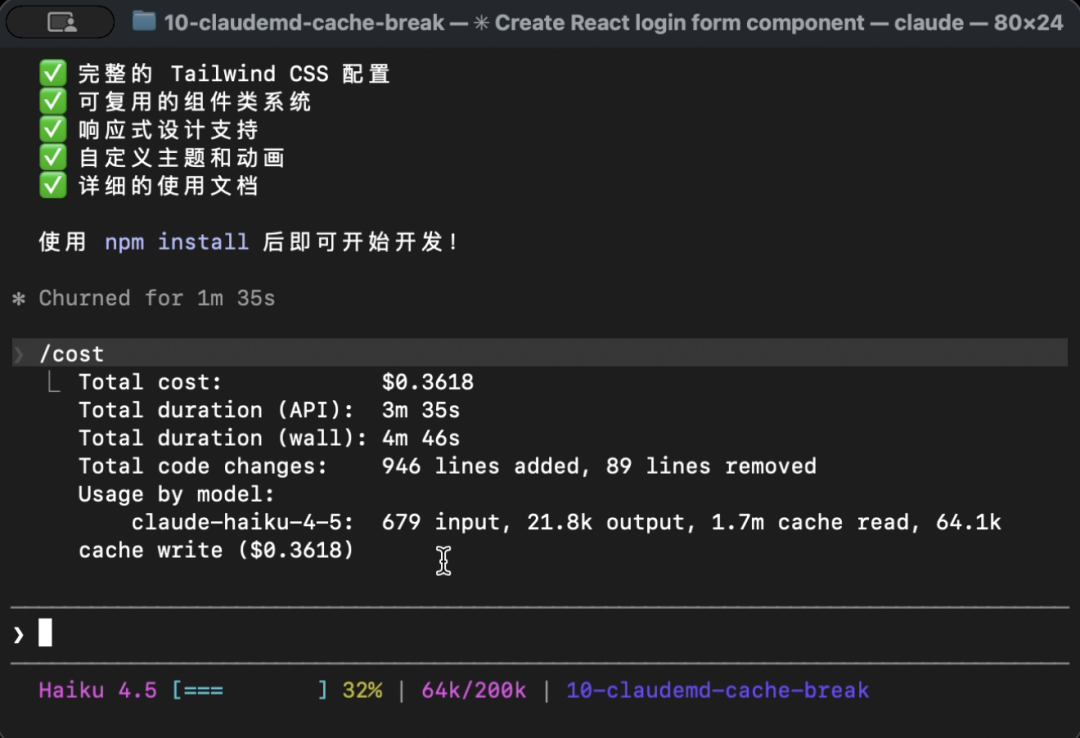
使用一轮对话
开新会话,一次性把全部需求说清:
帮我写一个 React 登录表单,要求:邮箱格式校验;密码强度校验(8 位以上,含大小写和数字);错误用 toast 提示;样式用 Tailwind。等 Claude 一次性写完,执行 /cost,截图如下:
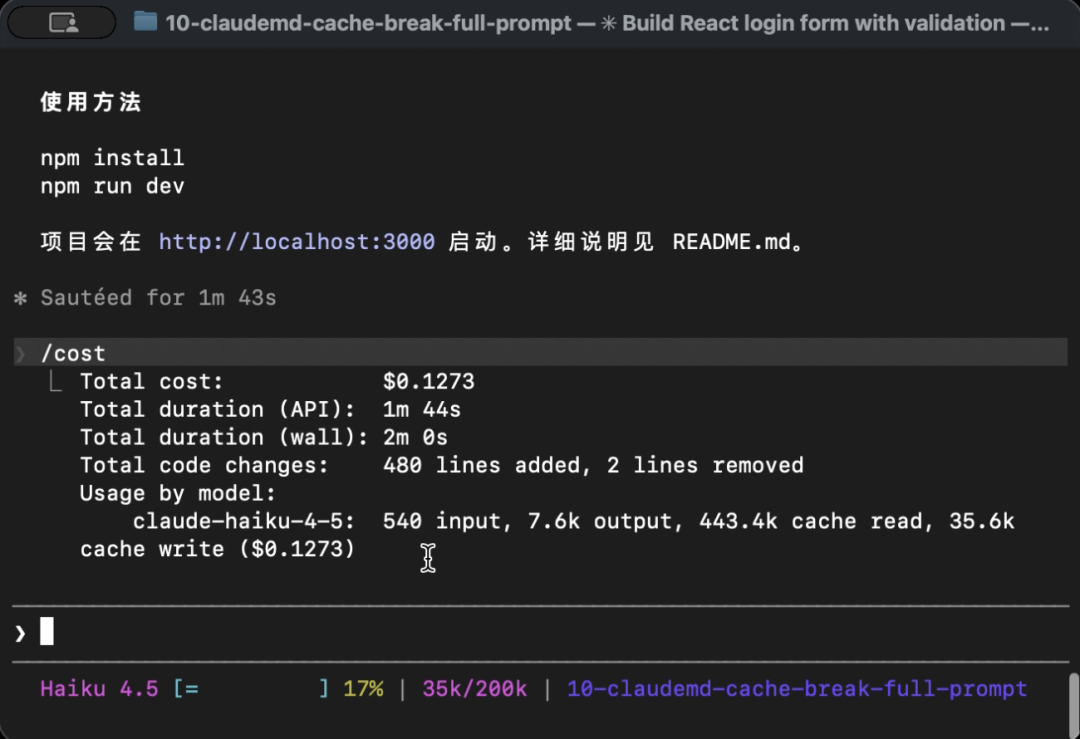
单位:
in= input,out= output,cr= cache read,cw= cache write
|
轮次 |
单轮花费 (in / out / cr / cw) |
累计花费 (in / out / cr / cw) |
|---|---|---|
|
Turn 1 |
415 / 3.1k / 219.3k / 33.7k |
415 / 3.1k / 219.3k / 33.7k |
|
Turn 2 |
26 / 1.0k / 103.0k / 3.1k |
441 / 4.1k / 322.3k / 36.8k |
|
Turn 3 |
42 / 2.2k / 189.9k / 4.8k |
483 / 6.3k / 512.2k / 41.6k |
|
Turn 4 |
82 / 4.5k / 442.7k / 7.4k |
565 / 10.8k / 954.9k / 49.0k |
|
Turn 5 |
114 / 11.0k / 745.1k / 15.1k |
679 / 21.8k / 1.7m / 64.1k |
|
一次说清单轮 |
540 / 7.6k / 443.4k / 35.6k |
540 / 7.6k / 443.4k / 35.6k |
约 4 倍差距(1.7m vs 443.4k cache read)。而且 Claude 一开始就知道最终目标,一次说清的代码反而更干净* 少了"先加 A 再加 B 再改 C"的补丁痕迹。*
坑 4:无意中清空缓存(最隐蔽的浪费)
前面讲 Prompt Cache 时提过命中要满足三条:前缀字节一致、同一个模型、在 5 分钟 TTL 内。后两条最容易被你日常操作触发清空,而你完全没感觉。
(a) 长时间中断后 resume
开会去了、下班回来、第二天接着昨天的 session(claude --resume)。 5 分钟 TTL 早过了。第一轮要把 system + 整段历史全价 write 一次,30k 起步很正常。
拿前面举的一个例子,resume 过后发一句 hi 试试看:
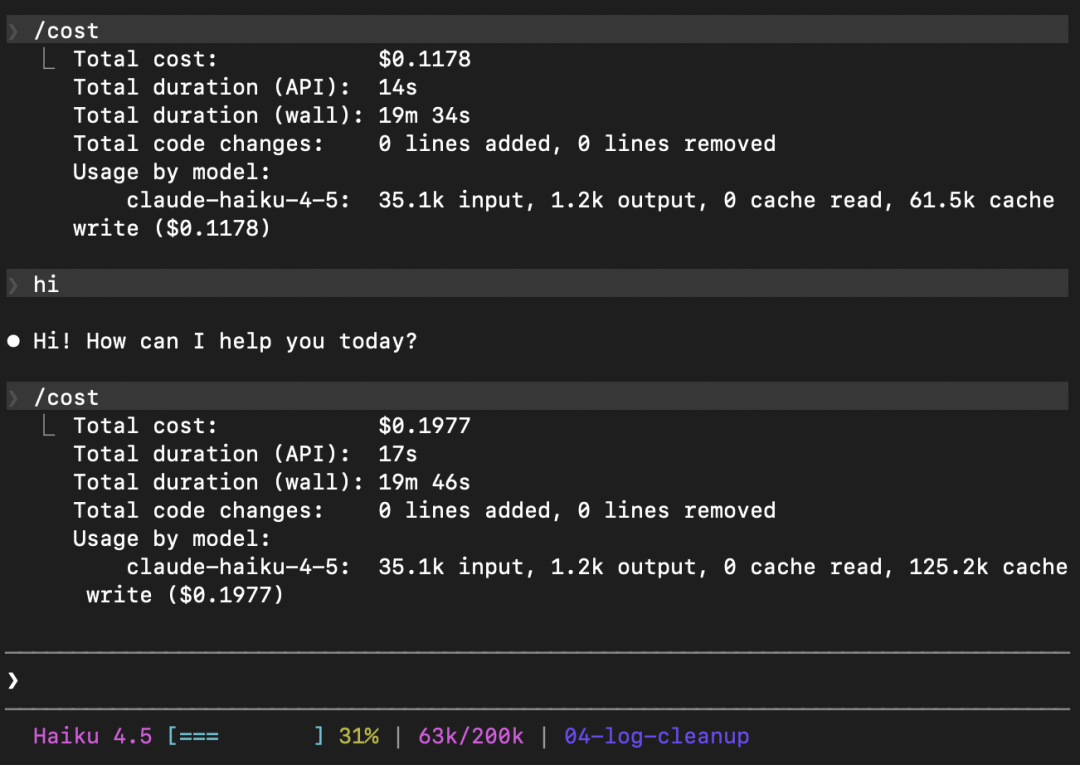
能看到这句 "hi" 重新进行 cache write 了,说明没有命中缓存,重新计费了。
这件事本身没法完全避免(你不可能为了省 cache 一直挂着),但可以避免雪上加霜:
-
长时间不用之前先
/compact,让重写的那一份更小 -
短时间离开(去倒杯水),别专门
/clear,清掉了 cache 也跟着没了 -
拆任务的话,连续做完一个再切下一个,别拖到下午再回来续
(b) 切换模型
Cache 是按模型隔离的。手动 /model 切到别的模型,那第一轮就是一次全价 write。
接着上面的那种情况,切换到 sonnet 再发个 hi 试试看:
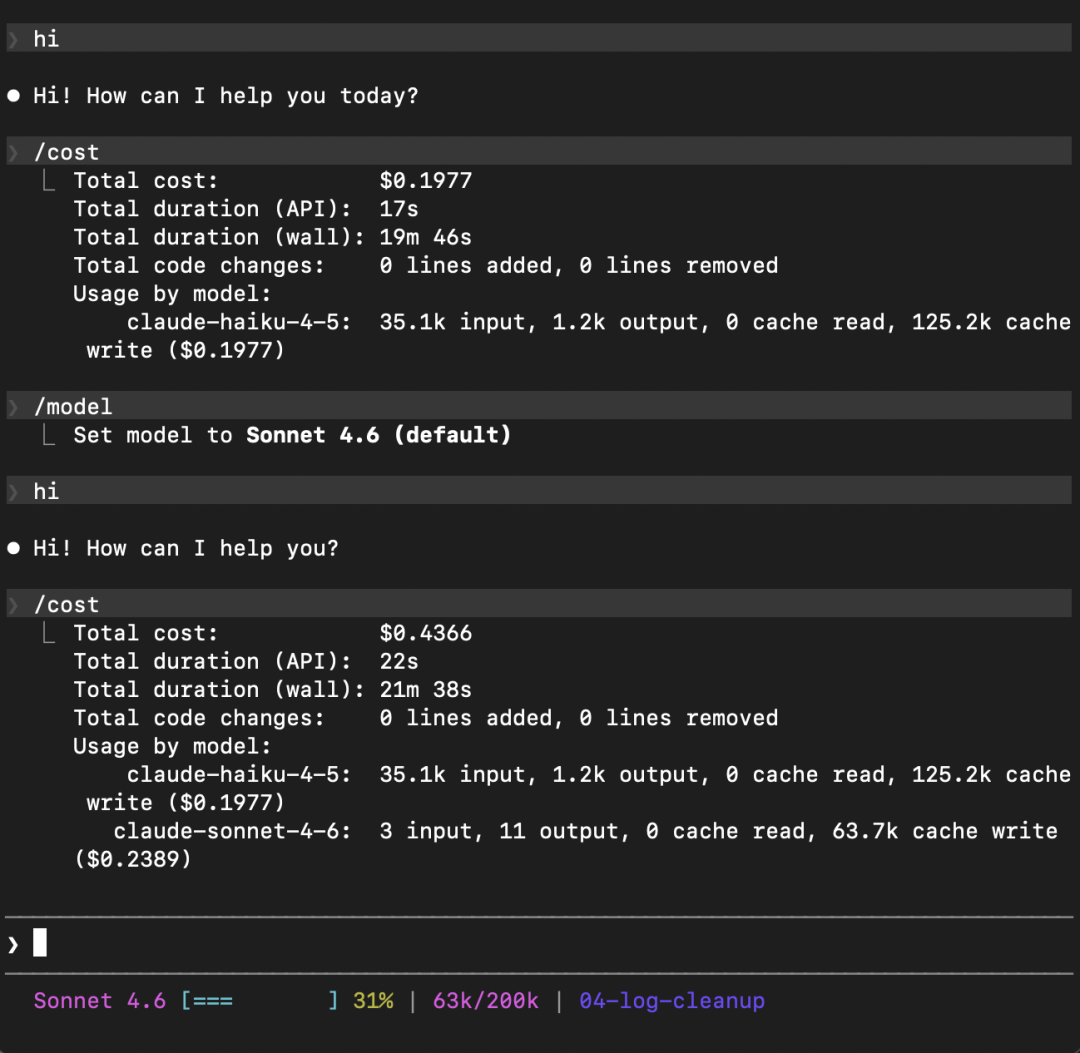
0 cache read, 63.7k cache write这就是切模型的代价。
实践上的取舍:
-
别频繁手动切模型。要切就一段任务都用同一个,别一句话一切
-
"用 opus 出方案、用 sonnet 写代码"这种工作流听起来省钱,但每次切换那一轮的 write 成本要一起算进去,短任务可能不划算
三、避坑指南:Claude 干活方式,也在偷偷耗 Token
核心坑:Read 整文件 vs Grep 精确定位(差 4 倍 Token)
很多人最爱说的一句话:"你先看看这个文件"。
然后 Claude 把 1500 行的文件 Read 进来,你其实只想改一个按钮的回调。
每个项目都有这种文件:上千行业务页面、几年没拆过的工具类、一个 god class 包了 200 个方法。
用法:
-
改一个点 → 用 Grep 定位
-
理解整体架构 → 用 Read
改一个点的流程:Grep 关键字 → 拿到行号 → 只读匹配行上下 5 行 → Edit。
试一下两种情况的差异,我们让Claude Code修改代码,将 handleClick37 这个函数点击弹窗改成 alert。
Read 读取整个文件
76 input, 1.8k output, 245.4k cache read, 108.6k cache write
Grep 定位
422 input, 1.0k output, 110.8k cache read, 28.7k cache write
1500 行的文件改一个 handler:Read 整文件 ~109k cache write vs Grep 定位后局部读 ~29k cache write 约 4 倍差距
更省事的做法是直接把范围圈出来给 Claude:如果你用 VS Code 的 Claude Code 插件,选中对应的代码行再提你的修改,Claude 会把这段选区直接当作上下文,根本不需要再去 Read / Grep 找位置。终端里写 prompt 时也可以手动加上 @path/to/file:120-145 这种行号定位。
顺带一提,有些比较智能的模型会自己先 Grep 再局部 Read,不过养成习惯更好。
嫌每次提醒自己麻烦的话可以直接写进 CLAUDE.md:
修改已知位置时,先用 Grep 定位行号,再只读匹配行上下几行;除非要理解整体架构,否则不要 Read 整个大文件。进阶技巧:让 Claude 先出方案再动手(但别每次都开 plan mode)
Claude Code 自带 plan mode(Shift+Tab 切换),会强制 Claude 先出方案、等你 approve 再开工。网上经常看到"先 plan 省 token"的说法,这个说法需要加限定条件。
生成 plan 本身要消耗 token:Claude 要读一遍相关代码、组织一段结构化的方案输出,这都是实打实的开销。对于小需求(明确知道改哪、只动一两个文件、改动意图清晰),plan 阶段多出的这部分消耗,后面往往省不回来,实测这类场景直接动手反而更便宜。
真正值得 plan 的是大需求:
-
改动范围大、跨多个文件或模块
-
不熟悉的代码区域,Claude 需要先摸清结构
-
需求本身有多种合理实现(比如"加日志"可以是中间件、可以是装饰器、可以是 handler 内手动打),你心里其实有个具体偏好
这类任务里 Claude 一旦方向走错,代价不是"再写一遍"那么简单,错的实现、读过的无关文件、走错方向的对话,全部留在 history 继续吃 token。这种场景下,plan 阶段多花一点 output,换后面避免一次几万 token 的返工,很划算;顺带产出的代码也更干净,少了"先加 A 再加 B 再改 C"的补丁痕迹。
一个简单判断:
小需求、目标明确 → 直接做,别 plan大需求、路径不确定 → 先 plan,在方案阶段就把你的特殊要求(选型、风格、边界条件)提出来,比事后推翻便宜得多
Plan mode 是好东西,但不是每次都开。
效率工具:Subagent 把脏活外包(避免主会话臃肿)
有一类任务天生需要"扫一大堆文件":统计某类 export、全项目找某个废弃 API 等。
直接在主会话做的问题是所有被读过的文件都会留在主会话的 context 里。之后每问一个新问题,Claude 都要把这坨"历史 Read 结果"再处理一次。
把这种任务派给 subagent(Explore / general-purpose),subagent 在独立 context 里跑,主会话只拿到最终那段文字总结。
我们可以再做一个小实验。
先让Claude Code去读取一批文件,然后我们再继续干十件事情,看看Token的消耗情况。
使用Read 读取60个文件,然后再干十件事情
读取文件后
3.7k input, 7.7k output, 98.5k cache read, 75.6k cache write连续做10个任务之后
3.9k input, 23.1k output, 1.7m cache read, 93.6k cache write
使用subagent 读取60个文件,然后再同样的十件事情
读取文件后
440 input, 7.1k output, 75.6k cache read, 71.3k cache write连续做10个任务之后
540 input, 14.8k output, 398.8k cache read, 78.6k cache write
读取 60 个文件后 Token 消耗接近,但连续追问 10 个新问题:主会话 ~1.7m cache read vs subagent ~398.8k cache read 约 4 倍差距(input 侧 3.9k vs 540,差距更夸张)
续命命令:/compact 和 /clear 的使用时机(别滥用)
Claude Code 用了一天之后响应越来越慢、/cost 里 input 越来越高,不是 Claude 变笨,是 session 历史越堆越长。每一轮对话都要把从 session 开始到现在的所有消息作为 input 重新发一次。叠加前面讲过的 5 分钟 cache 过期,长时间挂着的 session 既贵又慢。
两个续命命令:
-
/compact:读完整段历史,写成一份摘要替换原来的消息(适合"想继续当前任务") -
/clear:完全重置(适合"开新任务")
/clear 是免费的,没什么好说的。关键是 /compact,别当成无脑的"清爽一下"按钮来用。
compact 不是免费操作:Claude 要读完整段历史再写一份总结,这一步本身就要消耗一笔 output(output 单价还比 input 贵)。之后这份摘要要被后续轮次重复利用够多次,前面多付的这笔钱才摊得回来。如果你 compact 完下一秒就切到完全无关的话题,等于白白多付一次费用,还不如直接 /clear。
比较划算的 compact 时机:
-
历史已经很大(
/context占用明显、响应变慢),再带着它走每轮都在烧钱 -
当前任务要进入下一阶段,但还想保留前面的结论。比如做完方案调研要进实现、做完实现要进联调,前面的结论摘要一下继续用
-
compact 后还要连续对话多轮,轮数越多越能摊薄 compact 本身的成本
反过来,这些情况别 compact:
-
短时间内离开一下(去倒水、开个短会),cache 没过期前历史还能复用
-
彻底换主题 / 开全新任务 , 直接
/clear,不要 compact -
每做完一两轮就 compact 一次 , 预付成本根本摊不回来
一句话:/compact 和 plan mode 一样,是工具不是习惯,别滥用。
四、隐形陷阱:你的基础设施,每轮都在静默扣钱
陷阱 1:未屏蔽构建产物和依赖目录(最易忽略)
绝大多数项目一开始都没配。
随口问 Claude "项目里有哪些 interface 定义",它 Grep 一下命中了 src/generated/api-types.ts
这是一个自动生成的 3000 行类型文件。Claude 觉得有用,Read 进上下文,input tokens 瞬间冲到 40k。
很多动态生成的代码平时我们都不怎么需要。
还好 Claude Code 的 Grep 和 Glob 默认遵守 .gitignore。但是万一 generated 文件被提交了,Grep 能找到、Read 就能读。
两道防线一起上。.gitignore 把 generated 目录加上(业务允许的话),同时在 .claude/settings.json 里配一份:
{
"permissions": {
"deny": [
"Read(**/node_modules/**)",
"Read(**/dist/**)",
"Read(**/build/**)",
"Read(**/.next/**)",
"Read(**/generated/**)",
"Read(**/*.generated.*)",
"Read(**/Pods/**)",
"Read(**/DerivedData/**)",
"Read(**/*.lock)",
"Read(**/*-lock.json)",
"Read(**/*.lock.yaml)"
]
}
}放在项目根的 .claude/settings.json,防止读取大量动态生成的代码。
没配置的情况:
项目里存在自动生成的 src/generated/api-types.ts(约 3000 行),且未加入 .gitignore,.claude/settings.json 也没有配置 Read 的 deny 规则。
向 Claude Code 提问:
帮我看看项目里都有哪些 interface 定义Claude 会用 Grep 搜索 interface 关键字,命中 src/generated/api-types.ts,随后 Read 整个文件进上下文。执行 /cost:
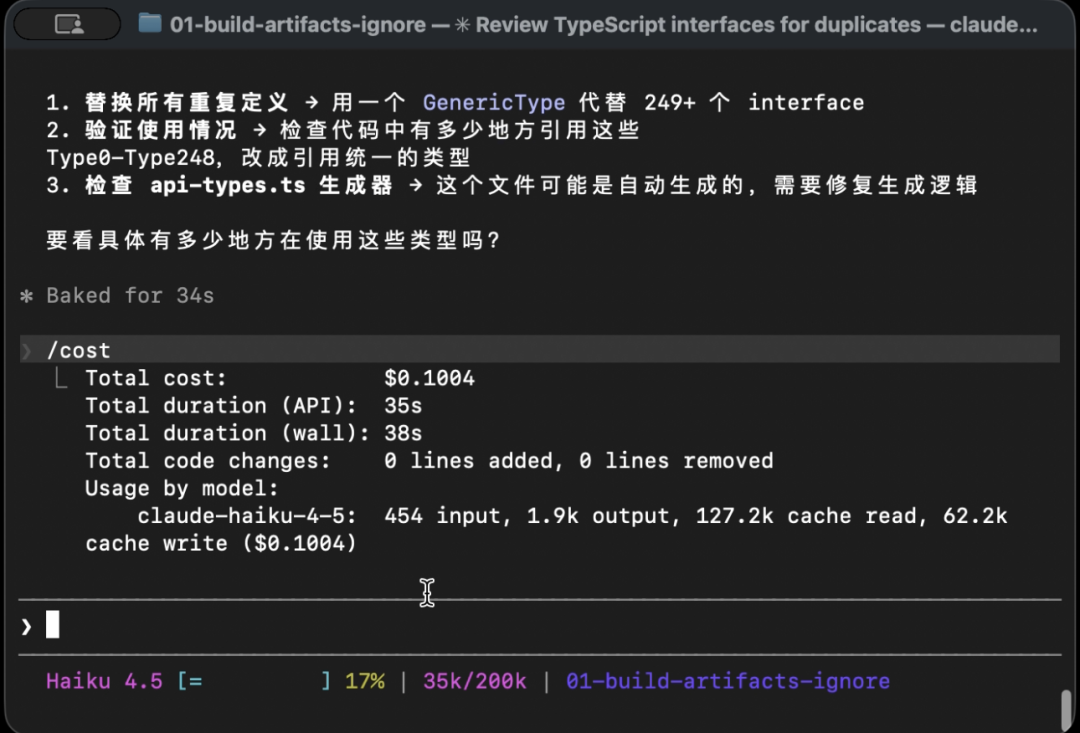
454 input, 1.9k output, 127.2k cache read, 62.2k cache write
配上 .gitignore 和 .claude/settings.json 之后:
把 src/generated/ 加入 .gitignore,同时在项目根 .claude/settings.json 配好上文给出的 permissions.deny 规则,重启会话。
向 Claude Code 发送相同的提问:
帮我看看项目里都有哪些 interface 定义这次 Grep 自动跳过 generated/ 目录,Claude 只会读到真正由人编写的源码文件。执行 /cost:
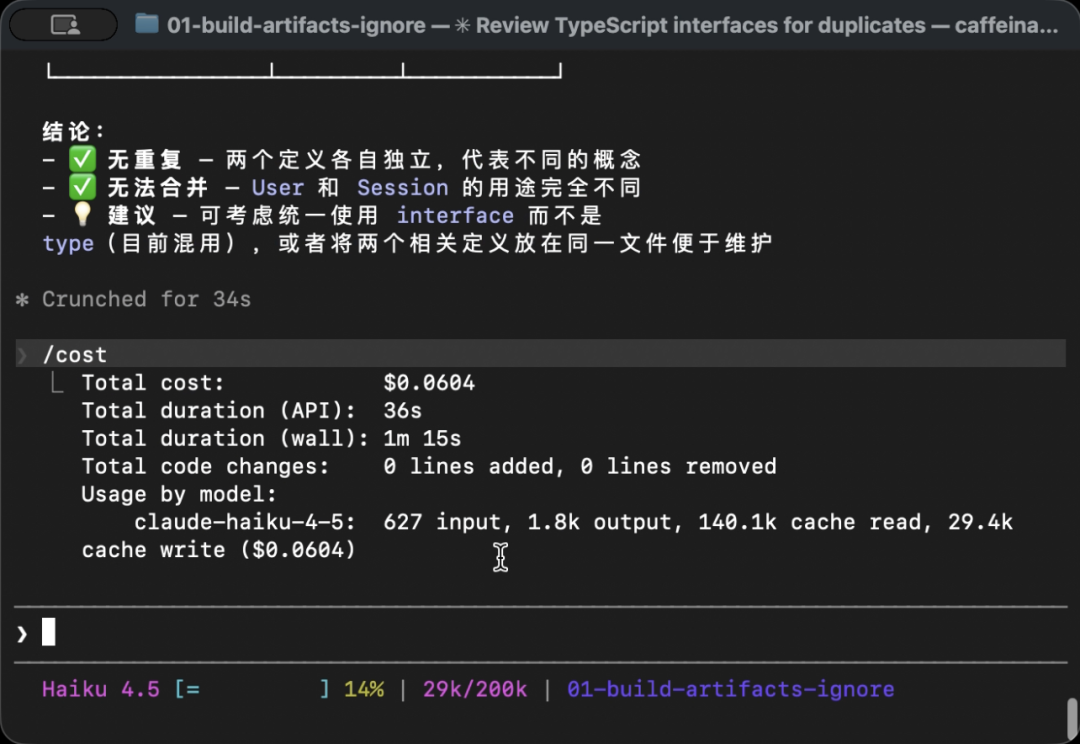
627 input, 1.8k output, 140.1k cache read, 29.4k cache write
陷阱 2:MCP 和 Skills 的"入场费"税(Token 刺客)
各种工具虽好,但都是 Token 刺客,打开 /mcp 就能直接看到。
每个已启用的 MCP 工具(name + description + input schema)都会被注入 system prompt。
Skills 是同一回事。每个启用的 Skill 都会把它的元数据(name + description + 触发条件)注入 system prompt 让 Claude 知道有这个能力可以调用。
如果你安装了 50 个 skill,3 个 MCP(里面大约有 50 个 tool),发了一句 "hi":
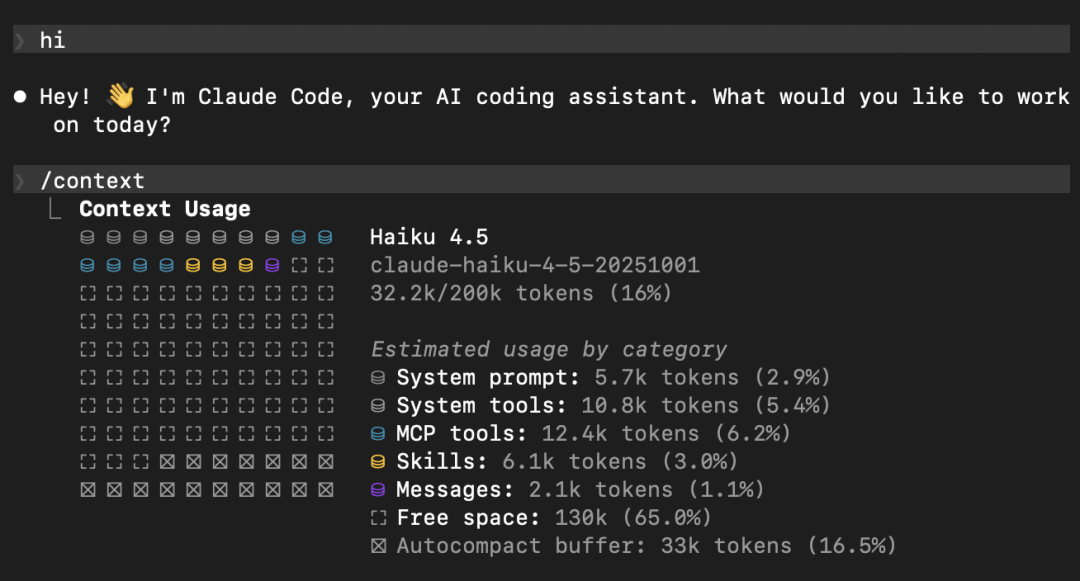
可以看到 MCP 和 Skill 就占用了几乎一半的上下文。
假设一天聊 50 轮,你为没用过的 MCP 多付了 100 万 token。Skills 也一样,且现在大家更容易装一堆 Skill 来"以防万一"。
建议整理规则:
-
这周用过的 MCP / Skill → 留在 global 配置
-
只有特定项目要用的 → 用项目级配置启用
-
半年没用的 → 直接砍掉,需要时再装回来
陷阱 3:CLAUDE.md 的两个写法陷阱(隐性膨胀)
CLAUDE.md 是 Prompt Cache 的主战场,也是 system 侧最容易膨胀的部分。有两个最常见的错误。
(1)写得太大,冗余信息过多
第一周 200 行写得很克制;半年后 1500 行,各种约定、踩坑、模板、edge case 都有。每一轮对话哪怕只问 "hi",都要把这 1500 行带进 input。
5–8k 的 CLAUDE.md 即便命中 cache 也每轮要付 cache read 费用,更关键的是占 context window。
到底要不要写进 CLAUDE.md:
这个东西是不是 Claude 不知道就会犯的错?
是 → 写 不是(仅供人类参考的背景知识、历史决策、TODO) → 挪到
docs/,需要时让 Claude 现读
写到 700 行就该审一遍。
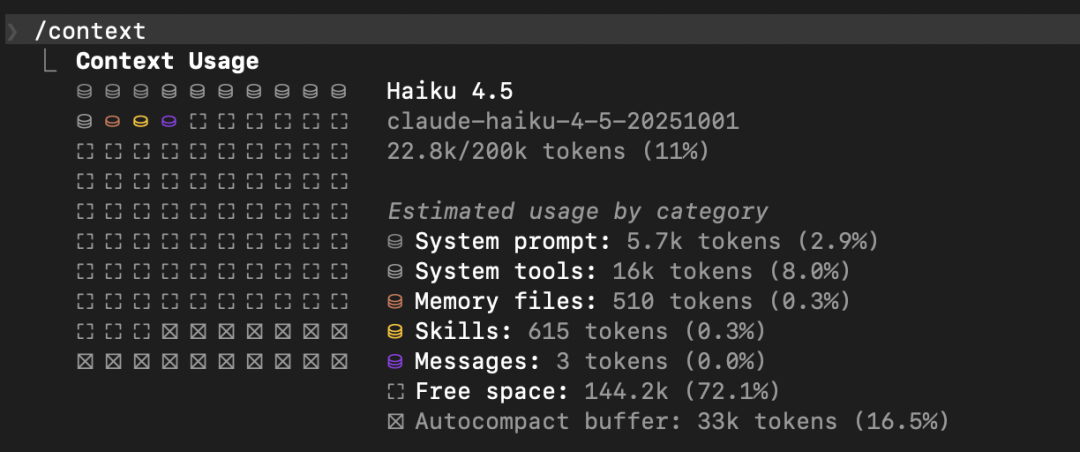
使用 50 行的 CLAUDE.md
使用 1500 行的 CLAUDE.md
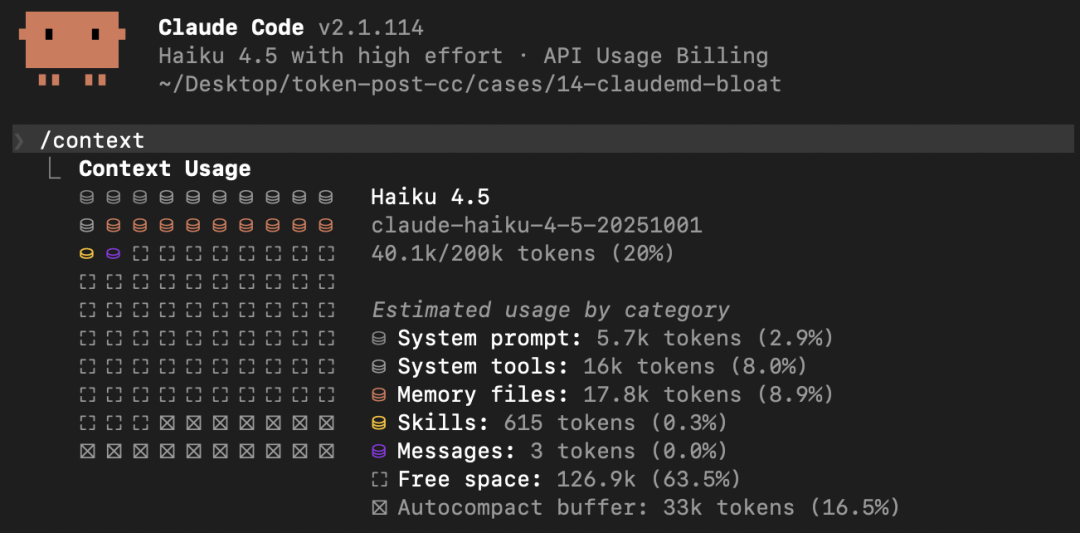
1500 行 CLAUDE.md 裁到 50 行:单轮 input 18k → 0.5k。50 轮/天 全年累计 ≈ 3 亿 token。
(2)放动态内容击穿 Cache
很多人在 CLAUDE.md 里写:
Last updated: 2026-04-19 14:32:05
Current sprint: Sprint 42
Active TODOs:
- [ ] Fix login bug (@zhangsan, due 4/20)每次改动都更新,挺贴心。但 Prompt Cache 命中条件是前缀字节完全一致,现在这一个时间戳的变化,让后面所有稳定内容一起 cache miss。
下面做一个两种情况的实验,先不修改CLAUDE.md ,连续发两条消息看是否能够命中缓存。 接着退出会话,修改CLAUDE.md后再进入会话发送一条消息查看是否能够命中缓存。
没改 CLAUDE.md 时约 70k input 全部命中 cache read;改完之后 70k 全 miss,重新 cache write 一遍 相当于这部分 input 从 10% 价翻回全价,贵约 10 倍
如果你有"自动更新 CLAUDE.md"的脚本一定要把它去掉。
两个错误合在一起的原则:
CLAUDE.md 不是项目知识库,是给 Claude 的开场白。
该放:代码规范、目录约定、常用命令、禁用写法(且总量克制)
不该放:时间戳、未完成 TODO、历史决策、长尾边界条件、给人看的背景
写在最后:Token 账单,是你工程习惯的镜子
Token 账单就是你工程习惯的镜子,哪些文件不该被读、提问前有没有整理过信息、有没有给 Claude 划过任务边界、"基础设施"是不是太重。
下次看到 /cost 里那个数字,别只当成账单。
想了解更多转转公司的业务实践,点击关注下方的公众号吧!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)