【2026年4月】FusionXpark GB10 本地部署 Qwen3.6-35B-A3B详细流程
摘要 本文详细记录了在超聚变FusionXpark GB10服务器上部署千问团队开源的Qwen3.6-35B-A3B大语言模型的全过程。硬件配置采用NVIDIA Grace Blackwell架构的GB10服务器,配备6144 CUDA Core和128GB内存。部署过程主要包含七个步骤:1)使用conda创建Python3.10虚拟环境;2)检查CUDA环境;3)安装适配Blackwell架构的
写在前面
近日有幸拿到了超聚变的FusionXpark GB10来玩,又恰逢千问团队开源了Qwen3.6-35B-A3B,于是想尝试下在FusionXpark GB10上部署该模型,鉴于网络上这俩组合部署的资料较少,本贴记录一下整个部署流程。部署过程中踩了一些坑,查阅参考了很多资料,在此对部分相关资料的贡献者表示感谢,参考资料如下:
1.新手小白总结DGX Spark 安装Vllm 并运行的流程:https://forums.developer.nvidia.cn/t/dgx-spark-vllm-cuda13/28377
2.RTX pro 6000 black well最新架构下安装 PyTorch CUDA - 解决 sm_120 兼容性问题:https://blog.csdn.net/qq_41968196/article/details/157031195
本人技术水平有限,部署流程或许不那么完善,希望各位大佬多多批评指正。
一、硬件配置(官方公布)
硬件产品型号:FusionXpark™ GB10
架构:NVIDIA Grace Blackwell
GPU:Blackwell 架构
CPU:20 core Arm, 10 Cortex-X925 + 10 Cortex-A725 Arm
CUDA Core:6144
Tensor Core:第五代
Tensor Core:支持的数据格式TF32、FP16、BF16、INT8、FP8、FP6、FP4
RT Core:第4代
Tensor 性能:1 petaFLOP(FP4精度(稀疏值))
系统内存:128 GB LPDDR5x, 统一系统内存
显存接口 | 显存带宽:256 位 | 273 GB/秒
存储:具有自加密功能的 1 TB、2 TB、4 TB NVME.M2
USB:4 个 USB4 Type C
以太网:1 个 RJ-45 接口,10 GE
NIC:ConnectX-7 Smart NIC
Wi-Fi:Wi-Fi 7
蓝牙:BT 5.4
音频输出:HDMI 多通道音频输出
显示器接口:1x HDMI 2.1a
NVENC | NVDEC“1x | 1x
重量:1.2 kg
尺寸:150 mm L x 150 mm W x 50.5 mm H
OS:预装NVIDIA DGX OS
二、部署流程
本流程采用非docker的部署方式,主要使用conda配置虚拟环境,安装pytorch、vllm等必备环境,具体配置流程如下。
1. conda创建虚拟环境
下载miniconda的ARM64架构版本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
安装miniconda(路径可按需修改,建议放在 /home/$USER/miniconda3)
bash Miniconda3-latest-Linux-aarch64.sh -b -p $HOME/miniconda3
重启终端并验证安装成功
source ~/.bashrc
conda --version # 验证安装成功
创建虚拟环境
conda create -n vllm-test python=3.10 -y
进入虚拟环境
conda activate vllm-test
下面的步骤都在新创建的虚拟环境中执行!
2. 检查系统当前环境
运行nvidia-smi查看CUDA版本为13.0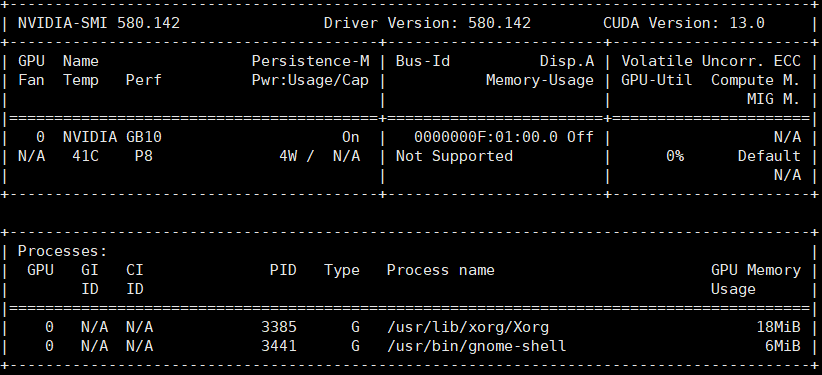
运行nvcc --version查看版本
3. 安装pytorch及相关依赖
这里一定要进入pytorch官网,按下图一样选择正确的版本来安装,因为显卡的架构是NVIDIA Grace Blackwell,版本过早或过新都不能很好的实现vllm、CUDA、pytorch之间的兼容,12.8版本是经过测试后能够稳定运行的版本。
pytorch官网:https://pytorch.org/get-started/locally/
版本选择
安装命令可以一并把torchaudio安装上
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
安装后输入如下命令检查安装是否正确
python -c "import torch; print(f'PyTorch: {torch.__version__} | CUDA: {torch.version.cuda} | 可用: {torch.cuda.is_available()}'); [print(f' GPU {i}: {torch.cuda.get_device_properties(i).name} | 显存: {torch.cuda.get_device_properties(i).total_memory/1e9:.2f}GB') for i in range(torch.cuda.device_count())] if torch.cuda.is_available() else print(' ❌ 未检测到GPU'); torch.randn(1024,1024,device='cuda'); print('✅ 显存读写测试通过')"
输出以下结果证明pytorch安装没问题,注意这里是pytorch版本号+cu128
4. 安装vllm及相关依赖
官方建议安装版本大于等于0.19.0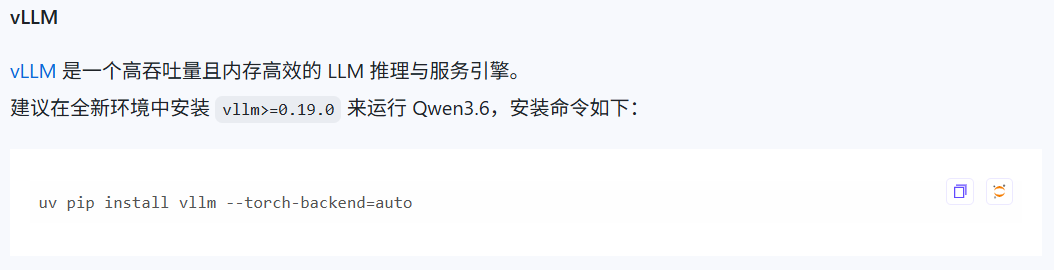
也可以执行下面命令安装vllm
pip install vllm
安装后,执行环境验证命令
python -c "import warnings, torch, vllm; warnings.filterwarnings('ignore'); print(f'vLLM: {vllm.__version__} | PyTorch: {torch.__version__} | CUDA: {torch.version.cuda}'); [print(f'GPU {i}: {p.name} | 显存: {p.total_memory/1024**3:.2f} GB | 计算能力: ({p.major}, {p.minor})') for i, p in enumerate([torch.cuda.get_device_properties(i) for i in range(torch.cuda.device_count())])] if torch.cuda.is_available() else print('❌ 未检测到GPU')"
显示如下结果,这时出现了一个关键问题,pytorch版本降级并且成为cpu版本
看上面安装log发现安装vllm时自动把之前装好的pytorch卸载了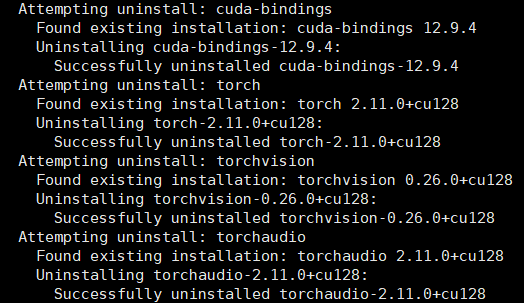
5. 更新pytorch版本并检查环境(重要)
到这一步,因为vllm自动卸载了安装的pytorch,所以要重新强制覆盖安装pytorch,对应vllm 0.19.1 的pytorch版本必须是2.10.0,使用如下命令
pip3 install torch==2.10.0 --index-url https://download.pytorch.org/whl/cu128 --force-reinstall
安装完成后会提示vllm版本和已安装的cuda-binding版本不匹配,可以忽略不管
直接用命令验证环境
python -c "import warnings, torch, vllm; warnings.filterwarnings('ignore'); print(f'vLLM: {vllm.__version__} | PyTorch: {torch.__version__} | CUDA: {torch.version.cuda}'); [print(f'GPU {i}: {p.name} | 显存: {p.total_memory/1024**3:.2f} GB | 计算能力: ({p.major}, {p.minor})') for i, p in enumerate([torch.cuda.get_device_properties(i) for i in range(torch.cuda.device_count())])] if torch.cuda.is_available() else print('❌ 未检测到GPU')"
结果如下代表环境配置完成,可以看到vllm、pytorch、CUDA版本都能正确显示,显卡可以识别
6. 下载Qwen3.6-35B-A3B
我们使用modelscope下载模型,先下载modelscope库
pip install modelscope -q
使用如下命令下载模型,可以修改模型下载到的位置
modelscope download --model Qwen/Qwen3.6-35B-A3B --local_dir /data/models/Qwen3.6-35B-A3B
检查下载文件是否完整
7. vllm启动Qwen3.6-35B-A3B
执行下述命令使用vllm启动模型,注意要更改模型存放路径,启动大约需要3~5分钟
vllm serve ~/models/Qwen3.6-35B-A3B \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--gpu-memory-utilization 0.92 \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--enable-chunked-prefill \
--max-num-seqs 5
出现如下内容就大功告成了,模型启动成功
8. 测试运行
可以通过下面命令来测试模型是否正常工作
#查看模型名字
curl http://localhost:8000/v1/models | python -m json.tool
输出结果如下,其中的第一个id字段内记录的是模型名字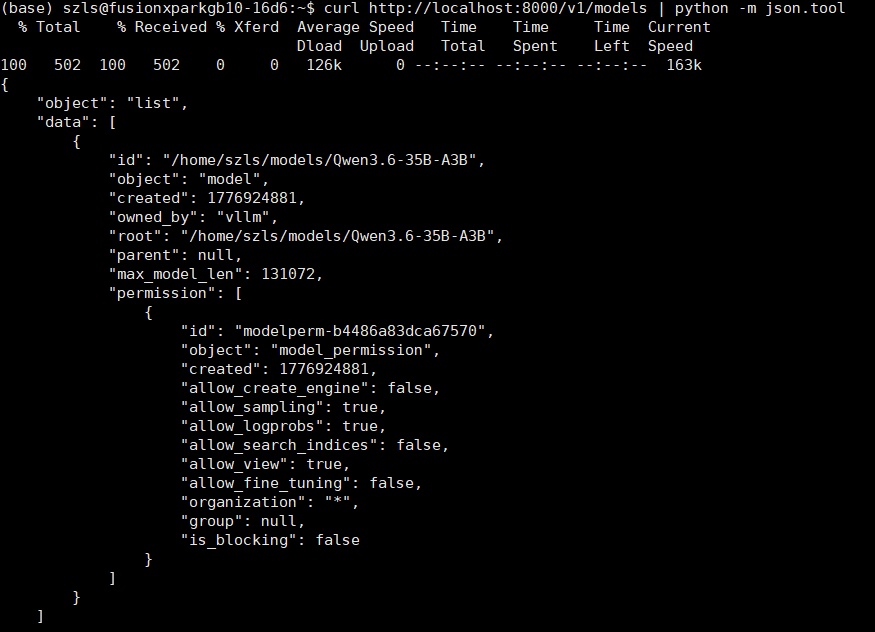
再使用下面的命令来测试模型是否能够正常调用
curl -N http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "替换为你的模型名字",
"messages": [{"role": "user", "content": "你好,给我讲个100字小故事"}],
"max_tokens": 500
}'
输出结果如下,模型能够正常工作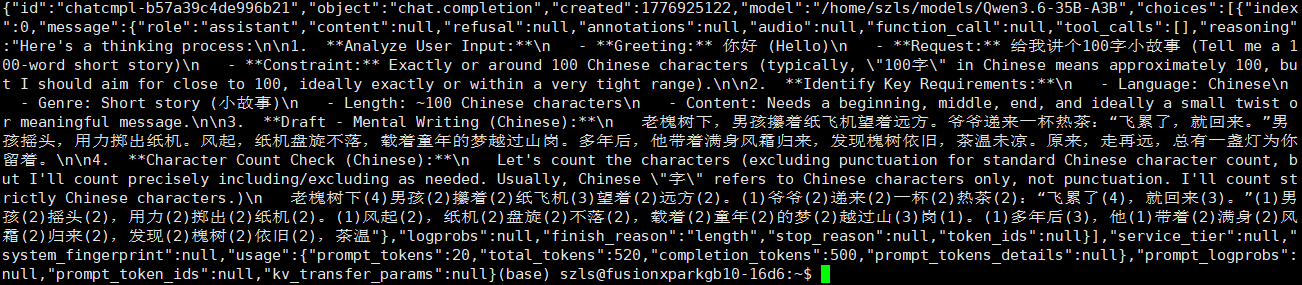
正常调用时,后台可以看到输出速度约为30 tokens/s
写在最后
到这里模型部署成功,在实际使用中,本人遇到了开思考后模型死循环、输出乱码、反复思考不输出等问题,不开思考感觉有些问题的处理能力又不太够,虽然设置过各种参数,但效果都不太好,目前本人还没有找到特别好的解决办法,如果各位大佬有解决办法也希望一起讨论。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)