国产三巨头谁更强:Kimi K2.6、GLM-5.1、Qwen3.6-Plus
国产AI模型三强对比:GLM-5.1、Kimi K2.6和Qwen3.6-Plus在编码能力上均接近Claude顶级水平(SWE-bench分数76%-78%),但各具特色。GLM-5.1擅长8小时持续任务,适合企业自动化;Kimi K2.6代码生成快,个人开发首选;Qwen3.6-Plus支持百万级上下文,适合大项目。性价比远超Claude,价格仅6-39元/月。建议根据需求选择:个人开发选Ki

最近国产各厂家争先恐后的发布最新模型,如果你不知道应该选择哪个请完整的看完这篇文章。
GLM 5.1:由 ** 智谱 AI(Z.ai)** 开发,是一款主打长程智能体编程的开源模型,支持 8 小时持续自主作业,采用 MIT 开源协议。
KIMI K2.6:由 ** 月之暗面(Moonshot AI)** 推出,是其 Kimi 系列的旗舰版本,主打多模态与长上下文能力。
QWEN 3.6+(Qwen3.6-Plus):由 ** 阿里巴巴(阿里云通义千问团队)** 发布,是聚焦代码智能体与百万级上下文的旗舰大模型。
参数对比:
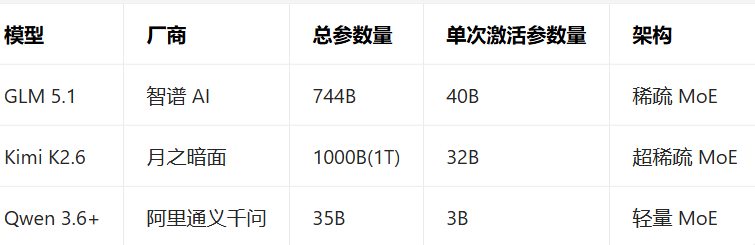
GLM-5.1、Kimi K2.6、Qwen3.6-Plus 三大国产编程大模型,均对标 Claude 顶级能力。
三者 SWE-bench Verified 跑分集中在 76%–78%,纸面数据看似旗鼓相当。
但实际落地差距悬殊,选错模型,开发效率直接腰斩。
核心差异:三者综合编码实力接近,核心优势赛道完全分化。
GLM-5.1 长任务连续作战能力顶尖,
Kimi K2.6 代码极速生成,
Qwen3.6-Plus 百万级超长上下文碾压同级。
再看一下数据:
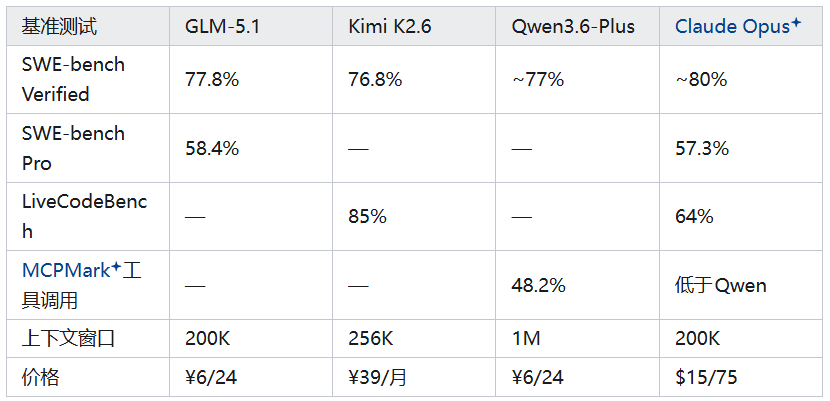
三款模型的 SWE-bench Verified 分数都在 76.8%~77.8%,和 Claude Opus + 的~80% 差距极小,说明在通用代码修复能力上,已经站在了同一梯队。
其中 GLM-5.1 以 77.8% 领先,在更难的 SWE-bench Pro 上,更是以 58.4% 反超了 Claude 的 57.3%,复杂工程的攻坚能力突出。
各自的王牌赛道,各有绝活
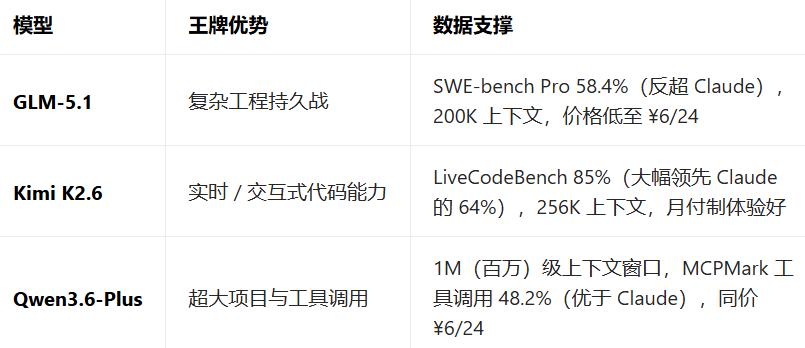
性价比:国产全面碾压
GLM-5.1、Qwen3.6-Plus 仅需 ¥6/24 的价格,就能提供对标 Claude 的能力,成本只有 Opus+($15/75)的几十分之一。
即使是 Kimi K2.6 的 ¥39 / 月,也比按次付费的 Claude 成本低得多,且有专属优化的交互式体验。
怎么选择适合自己的模型:
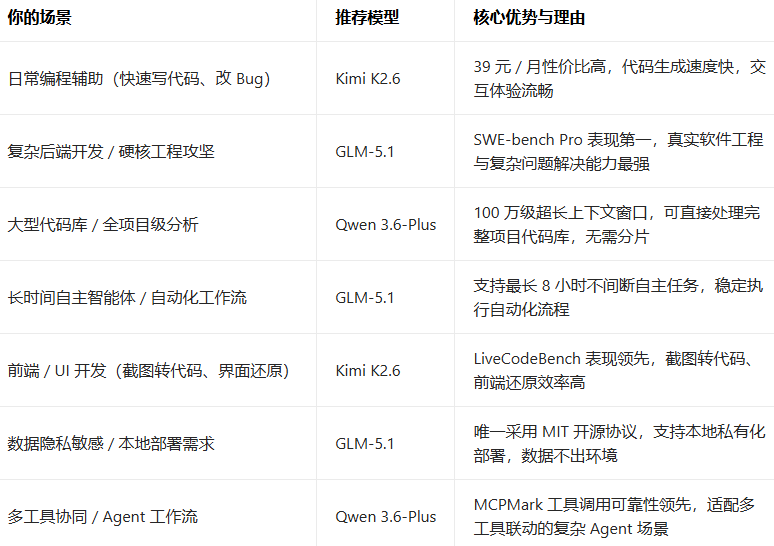
实战建议:
给大家的真实选型建议
个人写代码,无脑冲 Kimi K2.6 就完事了39 块钱一个月,日常写代码、调 Bug 完全够用,速度快、体验也稳。除非你要搞本地部署、处理百万级大项目,不然别折腾,用它最省心。
搞企业级大项目、自动化流程,必须看 GLM-5.1它在真实工程任务上的成绩比 Claude 还强,还能 8 小时不间断跑任务,做自动化工作流太香了。而且是 MIT 开源的,金融这种要合规的行业,本地部署也完全没问题。
项目代码库特别大、要做复杂 Agent,就上 Qwen3.6-Plus100 万 token 上下文真的能塞下整个大项目,工具调用也是三个里最稳的,做多工具协同的 Agent 首选。但要注意,现在还是预览版,用 OpenRouter 会收集数据,敏感代码千万别用,等正式版再上生产。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)