等了数月,DeepSeek V4 来了!打破最强闭源垄断。
全球 AI 圈期待已久的 DeepSeek-V4,今天正式发布上线,并同步开源。没有过多预热,没有大张旗鼓的发布会,依然是那个熟悉的 DeepSeek 风格——低调亮相,实力说话。

双版本齐发,满足不同需求
此次发布推出两个版本:

两个版本的最大输出长度均达到 384K Tokens,百万上下文窗口正式成为"标配水电煤",而非高端专供。
技术亮点:效率与性能的双重突破
这一次,DeepSeek 不只是把参数堆大,而是在架构层面做了真正的创新:
-
混合注意力机制 全新结合压缩稀疏注意力(CSA)与高度压缩注意力(HCA),在 Token 维度进行深度压缩,让长文本处理的计算量大幅降低。
-
流形约束超连接(mHC) 增强传统残差连接,提升信号在深层网络中的传播稳定性,让大模型训练更稳、更可控。
-
Muon 优化器 加速模型收敛,提高训练稳定性,训练数据规模分别达到 32T(Flash)与 33T(Pro)Tokens。
效率提升数据一目了然:
-
计算量(FLOPs)降低 73%
-
KV 缓存大小减少 90%
更强的能力,更低的资源消耗——这才是真正有价值的技术进步。
性能表现:比肩顶级闭源,领跑全球开源
DeepSeek-V4-Pro 的表现,让业内为之一振:
- Agent 能力:编码体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式。
- 世界知识:大幅领先其他开源模型,仅稍逊于 Gemini-Pro-3.1。
- 推理性能:数学、STEM、竞赛型代码全面超越所有开源模型,比肩顶级闭源。
一句话总结:DeepSeek-V4,打破了最强闭源模型的垄断。
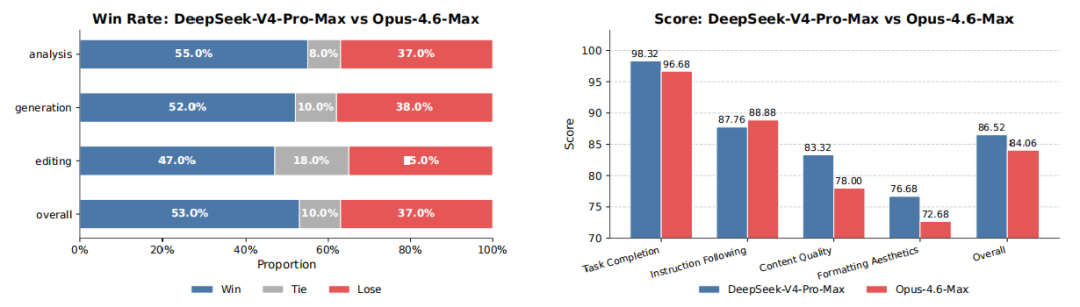
在官方发布的技术文档中通过左图展示了DeepSeek-V4-Pro-Max在各类中文白领任务中均优于Opus-4.6-Max,非损失率达到令人印象深刻的63%,并在分析、生成和编辑任务中展现出持续优势,右图中显示的详细维度评分突出了该模型在任务完成和内容质量方面的核心优势。
双模式运行,灵活适配复杂场景
两个版本均支持:
- 非思考模式:快速响应,适合实时交互。
- 思考模式:支持设置思考强度(high / max),复杂 Agent 场景建议使用 max 强度,释放模型最大推理潜力。
API 层面,同步支持 OpenAI ChatCompletions 和 Anthropic 两套接口,迁移几乎无成本。
⚠️ 注意:旧版模型名(deepseek-chat、deepseek-reasoner)将于 2026年7月24日 正式停用,请提前做好迁移规划。
「不诱于誉,不恐于诽,率道而行,端然正己。」
这句《荀子》里的话,被 DeepSeek 悄悄写在了文章末尾。
不追热度,不造声势,只管埋头把事情做对。这或许,正是中国 AI 该有的样子。
关于 BitaHub
BitaHub 是专注于 AIGC 方向的国产算力平台,为 AI 开发者、科研团队和企业用户提供稳定、高效的算力支持与模型部署服务。无论是大模型训练、推理加速,还是 AIGC 应用落地,BitaHub 都能提供灵活的算力调度方案,让每一份算力真正服务于创新。
BitaHub,助力国产算力。让世界,看见中国模型。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)