Day 0 支持 Qwen3‑Coder‑Next:在 AMD GPU 上部署新一代代码大模型
与真实 IDE 场景的高适配性:得益于 256k 上下文长度以及对多种 scaffold 模板的适配能力,模型可以无缝接入多种 CLI / IDE 平台(如 Claude Code、Qwen Code、Qoder、Kilo、Trae、Cline 等),覆盖丰富的开发环境。- 先进的 Agentic 能力:通过精心设计的训练流程,模型在长链路推理(long-horizon reasoning)、复杂
Day 0 支持 Qwen3‑Coder‑Next:在 AMD GPU 上部署新一代代码大模型
原文作者:Andy Luo, Haichen Zhang

我们很高兴宣布:阿里巴巴最新开源代码大模型Qwen3-Coder-Next[1] 已在 AMD GPU 上实现 Day 0 支持。本文将基于 AMD ROCm™ 7 软件栈和 vLLM 上游优化,演示如何在 AMD GPU 上快速部署 Qwen3-Coder-Next 模型家族。
这篇部署指南主要面向正在构建下一代Agentic 工作流的AI 开发者、系统架构师、DevOps / 平台工程团队。
通过在AMD GPU 上支持 Qwen3-Coder-Next 系列,开发者可以在单卡上高效跑通 256k 超长上下文窗口,同时处理复杂的代码生成、重构和多轮推理任务。
传统上,部署最前沿的代码大模型往往需要在“参数规模”与“推理深度”之间做权衡。Qwen3-Coder-Next 通过只激活 3B 参数(总参数量 80B),却实现接近 80B 级模型的能力,在这一点上打破了固有瓶颈,带来:
- 高性价比:在相对较小的硬件资源下,就能支撑复杂代码Agent 的部署。
- 生产级稳定性:通过更强的推理与错误恢复能力,有效缓解“执行过程产生幻觉”的问题。
- 硬件选择自由度:在高带宽大显存的AMD GPU 上提供顺滑的 Day 0 运行路径,帮助用户避免被特定厂商绑定。

模型概览
- 极致效率与显著性能:Qwen3-Coder-Next 只激活 3B 参数(总参数 80B),即可达到许多活跃参数为其 10–20 倍模型的性能水平,非常适合成本敏感的 Agent 场景部署。
- 先进的 Agentic 能力:通过精心设计的训练流程,模型在长链路推理(long-horizon reasoning)、复杂工具调用(tool usage)以及执行失败后的恢复能力方面表现突出,适合在动态代码任务中长期稳定运行。
- 与真实 IDE 场景的高适配性:得益于 256k 上下文长度以及对多种 scaffold 模板的适配能力,模型可以无缝接入多种 CLI / IDE 平台(如 Claude Code、Qwen Code、Qoder、Kilo、Trae、Cline 等),覆盖丰富的开发环境。
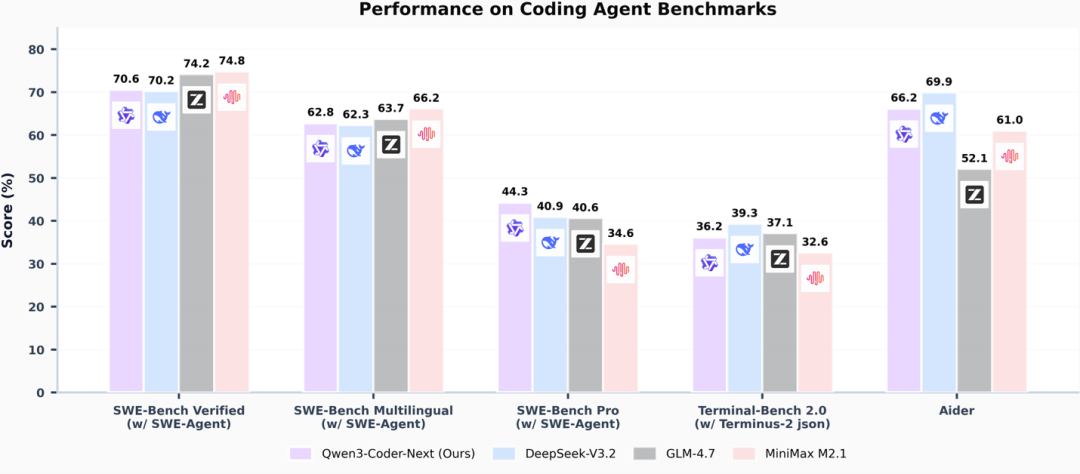
图1:代码智能体基准测试性能表现
在AMD GPU 上通过 vLLM 运行 Qwen3-Coder-Next
ROCm™ 7 与 vLLM 的集成,使得用户可以充分利用AMD GPU 上的 192GB HBM 显存容量。
- 超长上下文支持:使用FP8 精度时,可以在单张 GPU 上直接服务完整的 256k 上下文长度。这对于需要仓库级(repo-level)上下文的代码任务尤为关键,而许多硬件平台在显存上往往难以支撑。
- 吞吐与时延优化:tensor parallelism,开发者可以在保持较低时延的同时提升吞吐,满足例如 Claude Code 或 Trae 这类 IDE 即时交互场景对响应时间的要求。
在开始之前,请确保:
- 已拥有 AMD GPU 的算力环境
- 已正确安装并配置 ROCm 相关驱动和软件栈
Step 1:安装并上手 vLLM
你可以直接安装最新版vLLM Python wheel*:
uv venvuv .venv/vin/activateuv pip install vllm --extra-index-url https://wheels.vllm.ai/rocm/0.15.0/rocm700
*依赖:Python 3.12、ROCm 7.0、glibc ≥ 2.35(Ubuntu 22.04+)
或者,你也可以直接使用预构建好的vLLM upstream Docker 镜像:
docker run -it \ --entrypoint /bin/bash \ --device /dev/dri \ --device /dev/kfd \ --network=host \ --ipc=host \ --group-add video \ --security-opt seccomp=unconfined \ -v $(pwd):/workspace \ -v ~/.cache/huggingface:/root/.cache/huggingface \ --name Qwen3-Coder-Next \ vllm/vllm-openai-rocm:v0.15.0
Step 2:启动 vLLM 服务
使用多卡tensor parallel 启动 Qwen3-Coder-Next:
vllm serve Qwen/Qwen3-Coder-Next --tensor-parallel-size 2 --enable-auto-tool-choice --tool-call-parser qwen3_coder
- 为了获得更优性能,推荐使用:--tensor-parallel-size 4。
- 如果希望利用 AMD GPU单卡 192GB HBM 的优势,以 FP8 精度跑满 256k 上下文,可以直接使用 FP8 版本单卡部署:
vllm serve Qwen/Qwen3-Coder-Next-FP8 --tensor-parallel-size 1 --enable-auto-tool-choice --tool-call-parser qwen3_coder
Step 3:验证精度
下面使用lm_eval 在 GSM8K 上做一个基础精度检查:
python -m lm_eval --model local-completions \ --model_args '{"model": "Qwen/Qwen3-Coder-Next", "base_url": "http://localhost:8000/v1/completions", "num_concurrent": 256, "max_retries": 10, "max_gen_toks": 2048}' \ --tasks gsm8k \ --batch_size auto \ --num_fewshot 5 \ --trust_remote_code
得到的精度表现良好:

图2:GSM8K 准确率
Step 4:尝试实际编码场景
Agentic Coding 示例
Qwen3-Coder-Next 在工具调用(tool calling)能力上表现出色。你可以像官方示例[2] 中那样直接定义或复用工具。下面展示了一段典型的 tool call 输出(节选):
Choice(finish_reason='tool_calls', index=0, logprobs=None, message=ChatCompletionMessage(content=None, refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[ChatCompletionMessageFunctionToolCall(id='chatcmpl-tool-a4c3ba14abecbb9f', function=Function(arguments='{"input_num": 1024}', name='square_the_number'), type='function')], reasoning=None, reasoning_content=None), stop_reason=None, token_ids=None)
模型会根据上下文自动选择合适的工具,并给出结构化的tool call 参数,方便在后端执行真实代码或调用外部服务。
Coding 能力评估
Qwen3-Coder-Next 在多语言、多任务的编程能力上表现突出。我们使用了一个覆盖多个维度的测试集合,对其编程能力进行了系统评估,主要包括:
- 算法实现:二分查找,各类排序算法,常见数据结构等
- Web 开发:React 组件,REST API 实现,CSS 布局等
- 数据库设计:SQL 查询,模型设计与建模,规范化相关任务
-系统设计:常见架构模式,可扩展性相关概念与设计
- 多语言支持:Python、JavaScript、SQL、C++ 等多种主流语言

图3:编码能力测试
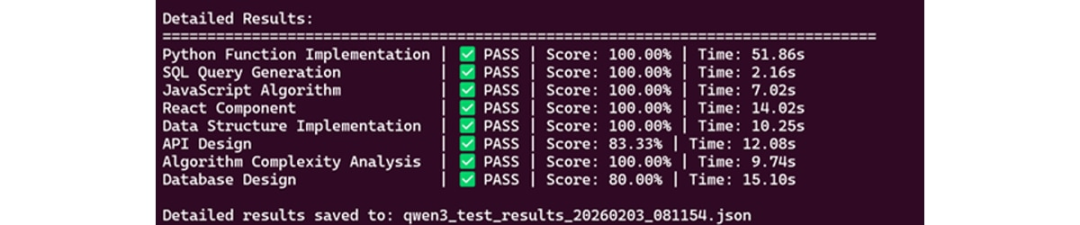
图4:编码能力测试结果
在覆盖8 个维度的综合测试中,Qwen3-Coder-Next 在多种编程任务上的成功率表现稳定,展现出良好的实际工程适配性。
总结
本文介绍了阿里巴巴Qwen3-Coder-Next 模型家族在 AMD GPU 上的 Day 0 支持情况,并展示了:
- 模型在多语言、多领域编程任务上的综合能力表现
- 如何基于 vLLM 在 AMD GPU 上部署 Qwen3-Coder-Next
- 如何启用专门的 tool-calling parser,支持各类 Agentic 编码场景
- 如何在 GSM8K 等任务上快速验证模型精度
通过这套方案,你的开发团队可以立即在最新一代AMD 硬件上,构建稳定可靠的 Agent 驱动编码平台(如代码助手、自动重构工具、跨仓库分析等)。
后续的技术文章将进一步深入:Kernel 级性能剖析,自定义 attention 内核实现,AMD ROCm 软件栈与 Qwen 模型的持续联合优化实践。
敬请关注。
致谢
参与本次工作与验证的AMD 成员包括:Yi Gan、Hattie Wu,以及 Qwen 团队的贡献与协作。
附加资源
- 加入 AMD AI Developer Program[3],获取 AMD Developer Cloud 资源、专家支持、培训和开发者社区。
- 访问 ROCm AI Developer Hub[4],查看更多基于 AMD GPU 的 AI 教程、开源项目与技术博客。
- 了解AMD ROCm Software[5]。
- 了解 AMD GPU[6]。
- 模型与代码下载:
-
Modelscope[1]
-
Hugging Face 集合[7]
-
GitHub 仓库[8]
参考链接
-
Qwen3-Coder-Next(Modelscope):https://www.modelscope.cn/collections/Qwen/Qwen3-Coder-Next
-
Agentic coding 示例(Hugging Face 文档):https://huggingface.co/Qwen/Qwen3-Coder-Next#agentic-coding
-
AMD AI Developer Program:https://www.amd.com/en/developer/ai-dev-program.html
-
ROCm AI Developer Hub:https://www.amd.com/en/developer/resources/rocm-hub/dev-ai.html?utm_source=web&utm_medium=amd&utm_campaign=deepseek_blog
-
AMD ROCm Software:https://www.amd.com/en/products/software/rocm.html
-
AMD GPU:https://www.amd.com/zh-cn/products/accelerators/instinct.html
-
Qwen3-Coder-Next(Hugging Face Collection):https://huggingface.co/collections/Qwen/qwen3-coder-next
-
Qwen3-Coder GitHub 仓库:https://github.com/QwenLM/Qwen3-Coder

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 0
0 0
0- 0


 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)