DeepSeek-V4出来了,今天你用了吗?(架构重大升级,一个字,干就完了)
DeepSeek-V4的同学,即日起登录其官网进行对话,使用的就是100W超长上下文的模型啦。),在token维度进行压缩,实现了超长上下文能力,并且相比于传统方法大幅降低了硬件的需求。2. 基础设施(通信计算优化,内核开发,批量计算,量化感知训练,推理框架);在未来的3个月内,我将对这些架构细节进行深究,感兴趣的同学敬请期待。就在今天, DeepSeek-V4腾空出世,宣告着AI正式迈入。他他实
就在今天, DeepSeek-V4腾空出世,宣告着AI正式迈入百万上下文普惠时代:DeepSeek-V4拥有100W超长上下文,在Agent能力、世界知识和推理性能上均有重大突破。
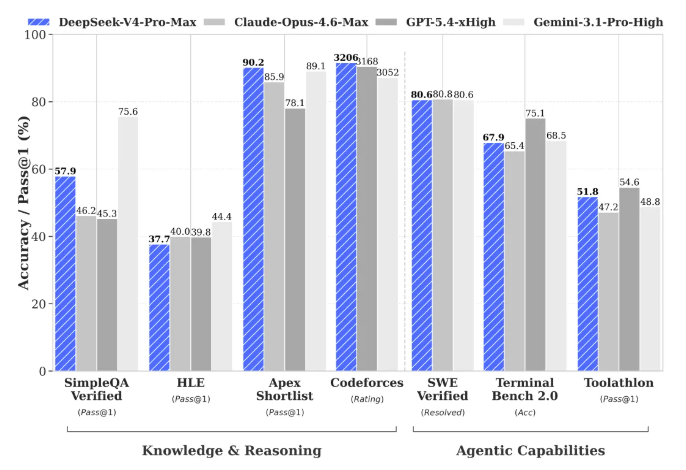
deepseek延续他一贯以来低调内敛的风格,没有说自己遥遥领先,而是说其性能“比肩”世界顶级闭源模型。
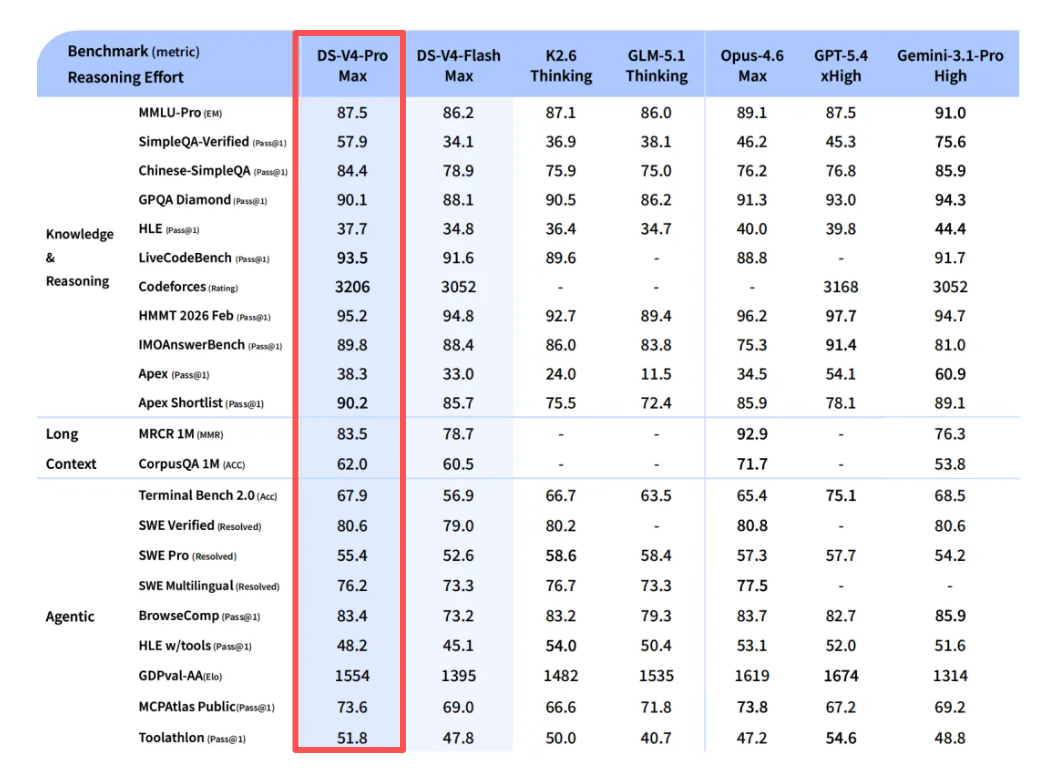
可以看到:
1. Agent编码评测中:V4体验已经优于Sonnet4.5,交付质量接近Opus4.6非思考模式,但仍与Opus4.6 思考模式存在一定差距;
2. 世界知识测评中:V4大幅领先其他开源模型,仅稍逊于顶尖闭源模型Gemini-Pro-3.1;
3. 在数学、STEM、竞赛型代码的测评中,DeepSeek-V4超越当前所有已公开评测的开源模型。
DeepSeek-V4为什么能够做到?
DeepSeek从来都不靠营销,而是他他实实的做架构优化。
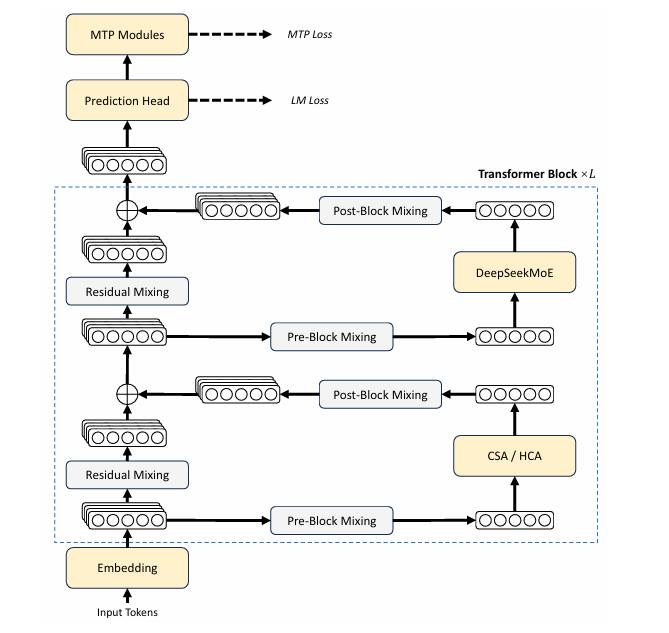
混合注意力机制(CSA/HCA)核心架构图
在系统架构上,DeepSeek-V4开创了一种全新的混合注意力机制(Hybrid Attention),在token维度进行压缩,实现了超长上下文能力,并且相比于传统方法大幅降低了硬件的需求。
画外音:没办法,人家根本就不卖卡给咱们。
混合注意力机制,主要由两部分构成:
CSA(Compressed Sparse Attention)稀疏压缩注意力
HCA(Heavily Compressed Attention) 超级压缩注意力
DeepSeek采用它们交错配置的混合架构,大幅降低了长文本场景中的注意力计算成本。
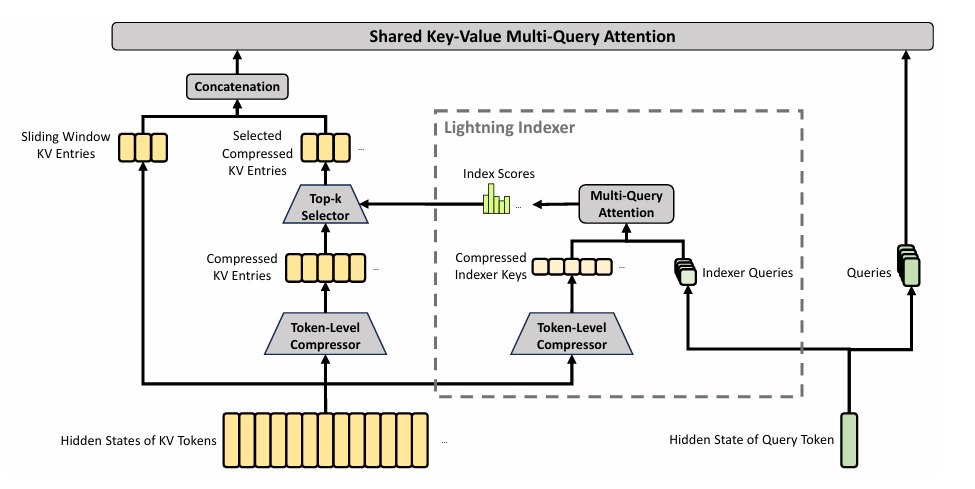
CSA(稀疏压缩注意力)架构图
CSA集成了压缩和稀疏注意力策略:首先将m个token的KV缓存压缩为k个条目,每个查询token只关注k个压缩后的KV条目即可。
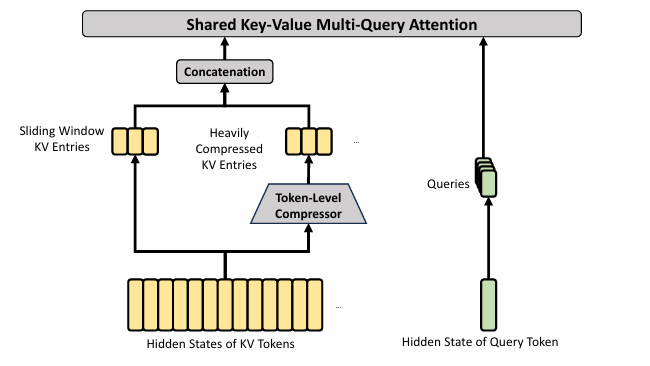
HCA(超级压缩注意力)架构图
HCA则旨在实现极端压缩,将m个token的KV缓存合并为一个条目。CSA和HCA的混合架构显著提高了DeepSeek-V4系列的长上下文效率,使百万token上下文在实践中成为可能。
初步看下来,DeepSeek-V4在:
1. 整体架构;
2. 基础设施(通信计算优化,内核开发,批量计算,量化感知训练,推理框架);
3. 预训练;
4. 后训练;
等多个模块进行了系统性优化。
由于资料今天才发布,其中的架构细节还没有深究,在未来的3个月内,我将对这些架构细节进行深究,感兴趣的同学敬请期待。
等不及的同学,可以先自行查阅英文原版:
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
当然,对于只想体验DeepSeek-V4的同学,即日起登录其官网进行对话,使用的就是100W超长上下文的模型啦。
DeepSeek-V4发布推文里最后四句话:不诱于誉,不恐于诽,率道而行,端然正己。和一直搞技术,做架构的我们一样,他他实实搞技术,做架构的人和公司,结果总不会太差。
未来3个月,一起冲,干!共勉!
阅读原文,直达DeepSeek官方发布推文。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 0
0 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)