重磅首发|清微智能RAISA软件栈Day-0护航DeepSeek-V4落地
清微智能基于成熟的软硬件协同架构,携手智源众智FlagOS,在模型发布当天完成了DeepSeek-V4-Flash版本的全量算子适配与验证,成为国内首批实现该模型全量算子兼容的芯片厂商。RAISA 涵盖了从兼容主流框架的应用层,到支持Triton与自研高性能算子库的编程语言与算子库层,再到实现全局优化的编译器层,以及提供全流程开发者工具链的基础软件层。兼容主流的生态战略,构建了从底层驱动到上层行业
今日,DeepSeek-V4预览版正式发布并开源,大模型正式进入百万上下文普惠时代。
清微智能基于成熟的软硬件协同架构,携手智源众智FlagOS,在模型发布当天完成了DeepSeek-V4-Flash版本的全量算子适配与验证,成为国内首批实现该模型全量算子兼容的芯片厂商。
“发布即落地”的效率,来自于清微智能RAISA软件栈的全链路支撑。在可重构算力上,国产大模型拿到了开箱即用的通行证。
01.
架构创新
MoE驱动百万长文本
作为 DeepSeek-V4 系列中主打快捷高效的版本,DeepSeek-V4-Flash 在架构创新与推理效能上实现了跨越式突破。
极致的参数效能
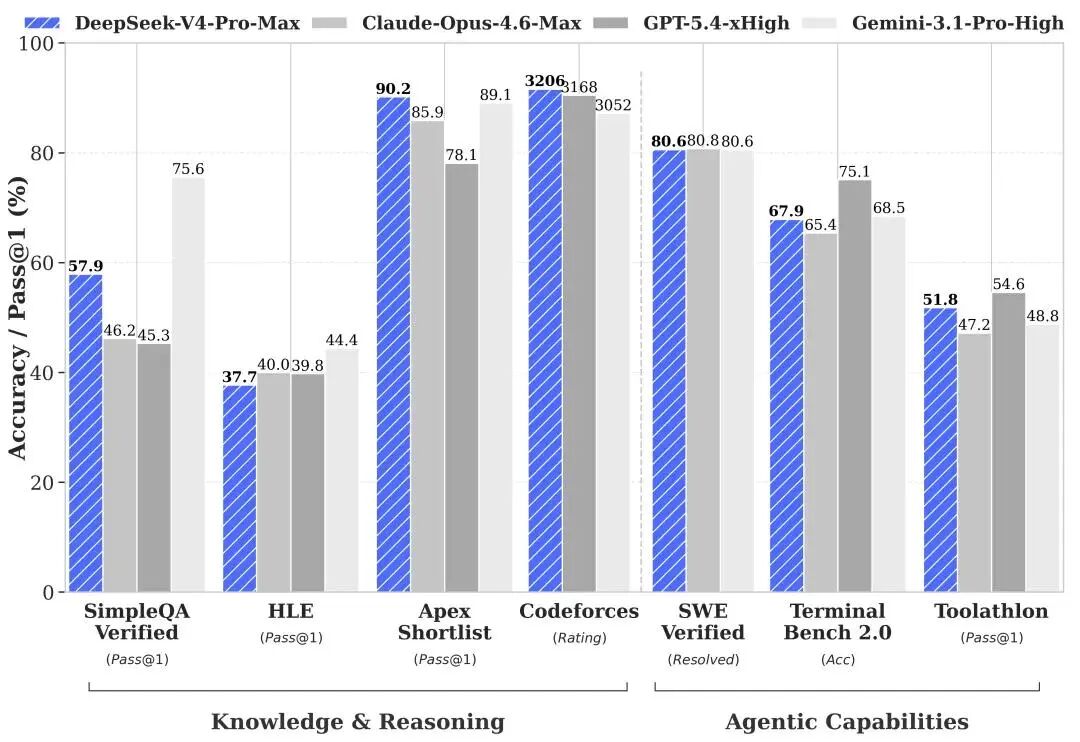
模型采用先进的混合专家(MoE)架构,总参数量达284B,而实际运行时的激活参数仅为13B 。这种设计在提供接近旗舰版推理能力的同时,大幅提升了推理速度并降低了显存开销。
百万上下文标配
依托首创的token维度压缩技术及 DSA(DeepSeek Sparse Attention)稀疏注意力机制,DeepSeek-V4-Flash 原生支持 1M(一百万)超长上下文窗口。这使得模型在处理长文档解析、复杂 Agent 任务时具备全球领先的效率。
出色智能体能力
在 Agent 评测中,DeepSeek-V4-Flash在代码生成、文档生成及多轮对话等核心任务上展现出强大实力,是企业级 AI 应用落地的理想底座。
02.
深度融合
FlagOS打通全量算子
DeepSeek V4 模型共使用了约 67 个算子,并引入了全新的注意力机制,这对底层芯片的算子库覆盖率与编译能力提出了严峻挑战 。
在此次 Day-0 适配中,清微智能通过与 FlagOS 系统的深度融合,实现了算子层面的重大突破。
全量算子无缝支持
清微智能芯片深度接入 FlagOS 核心算子库 FlagGems,不仅完美支持了 DeepSeek V4 所需的全部 67 个算子,更通过 Triton 语言的高效重写,使算子性能全面超越了传统实现方式。
FLIR破除性能瓶颈
针对 Transformer 推理场景下大量小算子频繁调用带来的开销,清微智能借助 FlagOS 的 FLIR 技术,消除了竞争与解释器开销,极大提升了端到端推理吞吐量。
Triton-TLE攻克高难度计算
面对决定长上下文效率的 TopK Selector 等关键算子,依托 FlagTree 编译器的 Triton-TLE 扩展与自动调优工具,清微智能智算底座实现了高效的片上数据管理与算子加速。
03.
清微RAISA
定义全栈算力
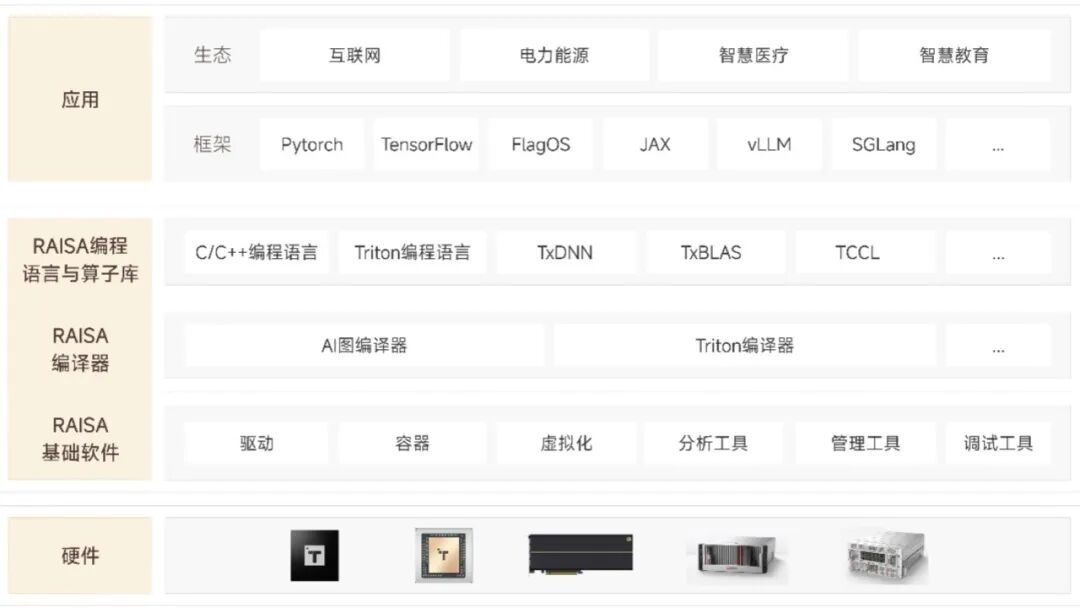
作为衔接底层硬件与上层应用的关键枢纽,清微智能RAISA软件栈基于“软件定义硬件”的技术理念、自主可控的技术底蕴、兼容主流的生态战略,构建了从底层驱动到上层行业应用的全链路、一体化软件体系,彻底破解了国产算力适配难、部署繁、优化慢的行业痛点。
四层协同,构建完整体系
RAISA 涵盖了从兼容主流框架的应用层,到支持Triton与自研高性能算子库的编程语言与算子库层,再到实现全局优化的编译器层,以及提供全流程开发者工具链的基础软件层。
三重突破,极致赋能开发者
凭借分层架构的灵活设计,RAISA软件栈兼顾了易用性、可编程性,且能充分发挥硬件性能,已得到客户侧广泛认可。
易用性:深度兼容 CUDA 生态算子,支持近千个主流算子,已完成包括 DeepSeek、Qwen 全系列在内的 200 余个大模型适配。
可编程性:开发者无需深入了解底层硬件细节,即可利用 C/C++ 或 Triton 语言高效完成定制化开发。
性能最大化:通过编译器全局优化,彻底隐藏通信与访存延迟,智算集群实测大模型硬件利用率达到行业领先水平。
此次Day-0跑通DeepSeek-V4-Flash全量算子,验证了清微从芯片到RAISA软件栈的全链路响应能力,也是清微智能与 FlagOS 社区深度协同、赋能开源生态的又一里程碑。
在完成Flash 版本首发的同时,团队正全力推进顶级旗舰模型DeepSeek-V4-Pro 的适配与深度优化。
将“快速适配”做成常态,让更多国产模型在清微算力上发布即跑通,清微不喊口号,只交结果。
往期推荐
|
1 |
|
|
2 |
END

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)