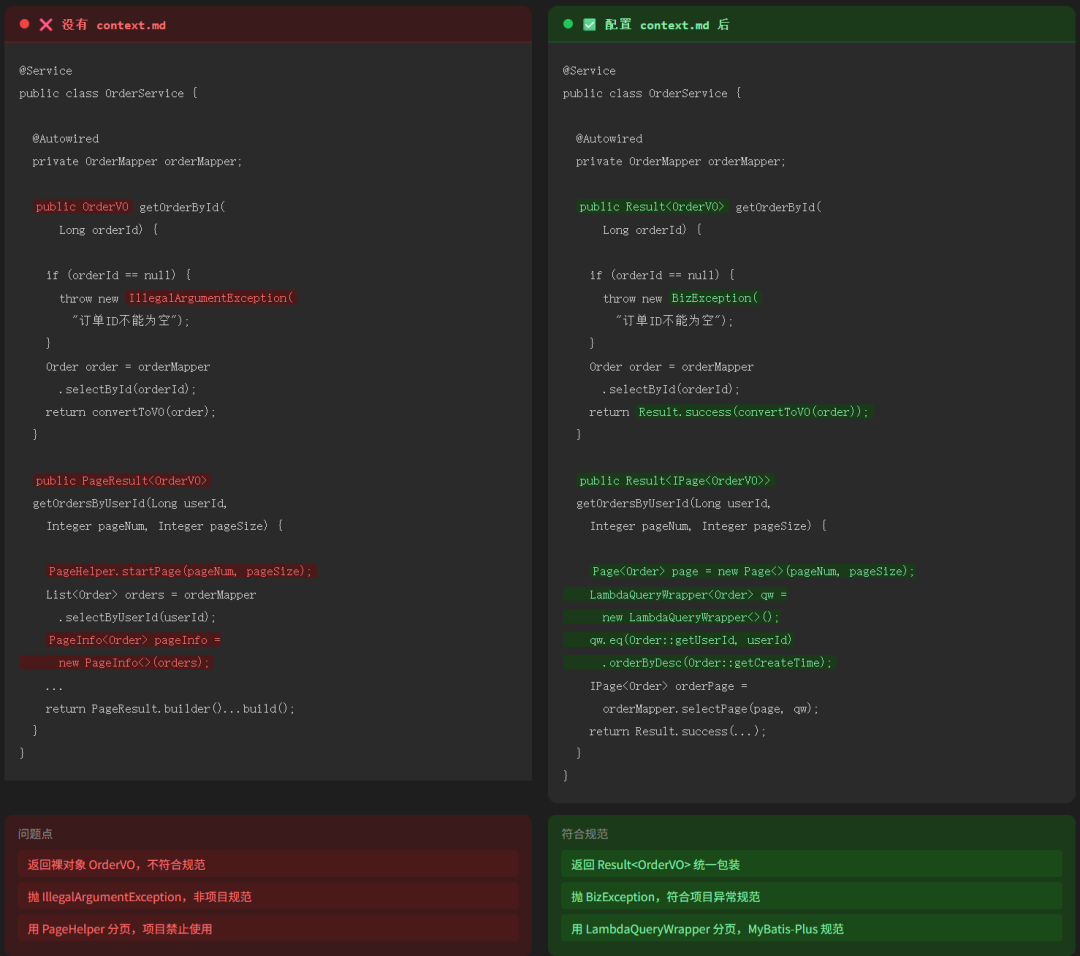
不买订阅!IDEA 接入 Claude + Codex 的终极方案,效率直接起飞!
说实话,大多数开发不爱写单测的原因不是不知道重要,是写起来真的烦——Mock 一堆依赖,构造各种边界数据,花的时间比写功能本身还多。大多数人用 AI 写代码的方式是这样的:写到一半,切到浏览器,粘代码进 ChatGPT,问完把答案粘回来。你给它一个裸的代码片段,和给它一个有项目背景、技术栈、编码规范的完整上下文,回答质量差距可以在三倍以上。它看不到你的数据库结构,不知道你有哪些公共工具类,不清楚你
我用这套方案已经三个月了,今天把它完整写出来。 不是"AI 工具推荐"那种文章——那种文章你看完还是不知道怎么用。这篇是我真实在 Java 项目里跑通的工作流,包括踩过的坑、配置细节、以及为什么这样设计。
这套方案能给 Java 开发带来什么
在说怎么配之前,先说结论,方便你判断值不值得花时间看下去。
CRUD 不再是负担。Java 项目里有相当一部分工作是高度结构化的——建表之后写 Entity、写 Mapper、写 ServiceImpl、写 Controller,逻辑清晰但繁琐。这类代码 Claude 结合你的表结构和项目规范可以直接生成,符合你的命名规范、符合你的分层结构、不需要大改。一个中等复杂度的增删改查模块,以前我要写两三个小时,现在二十分钟。
代码 Review 有了真正的对话。以前自己 Review 自己写的代码,很容易陷入"看起来没问题"的盲区。现在提交前把改动扔给 Claude,让它从并发安全、SQL 性能、异常处理三个维度过一遍,找出我自己没意识到的问题。它不会只说"这段代码有问题",它会告诉你具体在哪行、为什么有问题、改成什么样。
单元测试终于不再拖着不写。说实话,大多数开发不爱写单测的原因不是不知道重要,是写起来真的烦——Mock 一堆依赖,构造各种边界数据,花的时间比写功能本身还多。让 Claude 来生成,你只需要告诉它要覆盖哪些场景,它把 JUnit5 + Mockito 的框架代码都搭好,你检查逻辑对不对就行。
重构有了可以商量的对象。遇到历史遗留的烂代码,以前只能硬着头皮看。现在可以把一整个类粘给 Claude,问它"这段代码有哪些坏味道,怎么一步步重构风险最低"。它会给出有优先级的重构路径,从影响范围最小的改起,不是让你一口气推翻重写。
本质上是把重复劳动外包给了 AI,把思考留给自己。架构设计、业务决策、性能优化——这些还是你的事。但样板代码、测试代码、文档注释这些工作,让 AI 来干,你来审。这才是合理的分工。
先说清楚问题在哪
大多数人用 AI 写代码的方式是这样的:写到一半,切到浏览器,粘代码进 ChatGPT,问完把答案粘回来。或者装了 Copilot,但它根本不知道你项目的上下文,补全出来的代码经常驴唇不对马嘴。
这不是"AI 辅助开发",这是"AI 辅助复制粘贴"。
真正的问题是:AI 不在你的项目里。它看不到你的数据库结构,不知道你有哪些公共工具类,不清楚你的异常处理规范,每次对话都要重新解释一遍背景。上下文割裂,效率当然上不去。
我折腾这套方案的出发点就一个:让 AI 真正住进你的项目。
为什么是 Claude + Codex,而不是一个
这个问题值得认真说,因为它涉及两种 AI 的本质差异。
Claude 是理解型模型,擅长在大量上下文里找关系、做推断。你把一整个模块的代码丢给它,它能说清楚哪里耦合过重、哪个地方存在并发风险、改动 A 会不会影响 B。它的短板是补全延迟,实时行内补全体验一般。
Codex 是生成型模型,针对代码场景做了专项优化,延迟极低。你写了一行注释,它能立刻帮你把实现补出来。但它不擅长大范围的语义理解,让它分析一个复杂模块的架构问题,回答质量就一般了。
两个模型分工不同,不是竞争关系,而是互补。用一个字概括:Claude 负责想,Codex 负责写。
硬要只用一个的话,你会发现要么补全太慢打断思路,要么理解太浅给不出有价值的建议。所以这套方案的核心设计就是让两者同时在线、各司其职。
把 Claude 接进 IDEA
工具选 Continue,这是目前在 IDEA 里接自定义 AI 体验最好的插件。不用 Cursor 的原因很简单——我不想换 IDE,我在 IDEA 上有七八年积累的快捷键和配置,迁移成本太高。Continue 是插件,无缝嵌入,右侧多了个对话面板,其他什么都没变。
Settings → Plugins 搜索 Continue,安装重启。
安装完成后点 Restart IDE。重启完毕,IDEA 右侧边栏会出现 Continue 图标。
点击 Continue 图标展开面板,找到底部的齿轮图标,点进去会打开 ~/.continue/config.json。
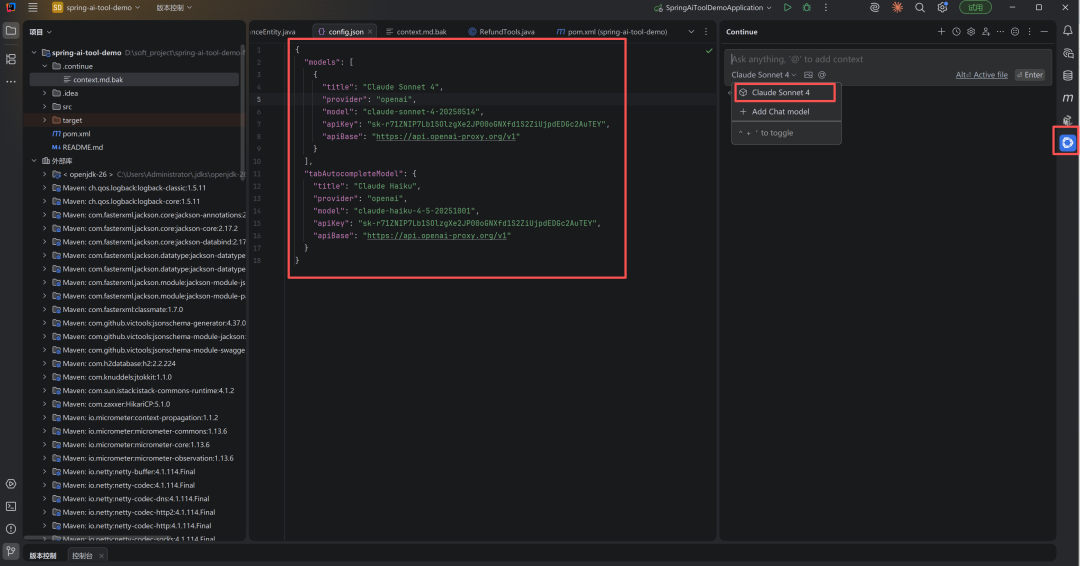
在 config.json 里写入配置:
{
"models": [
{
"title": "Claude Sonnet 4",
"provider": "openai",
"model": "claude-sonnet-4-20250514",
"apiKey": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxx",
"apiBase": "https://api.openai-proxy.org/v1"
}
],
"tabAutocompleteModel": {
"title": "Claude Haiku",
"provider": "openai",
"model": "claude-haiku-4-5-20251001",
"apiKey": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxx",
"apiBase": "https://api.openai-proxy.org/v1"
}
}主对话用 Sonnet 4,理解能力强;自动补全用 Haiku,便宜快。
让 Claude 真正读懂你的项目——这一步大多数人跳过了
这是整套方案里最重要的一步,也是绝大多数人配完 API Key 就结束了、然后发现"好像也没什么用"的根本原因。
AI 的能力上限取决于它掌握的上下文质量。你给它一个裸的代码片段,和给它一个有项目背景、技术栈、编码规范的完整上下文,回答质量差距可以在三倍以上。
在项目根目录新建 .continue/context.md:
## 项目背景
B2B 采购平台后端,服务约 200 家企业客户,日均订单约 3 万笔。
## 技术栈
- Java 17 + Spring Boot 3.2
- MyBatis-Plus 3.5,禁止写原生 SQL,统一走 LambdaQueryWrapper
- MySQL 8.0 主从分离,AbstractRoutingDataSource 实现读写分离
- Redis 7.0,分布式锁用 Redisson,缓存用 @Cacheable 注解
- RocketMQ 5.0,订单超时、库存扣减走消息队列
## 编码规范
- 统一返回 Result<T>,禁止直接返回 POJO
- 业务异常继承 BizException,由 GlobalExceptionHandler 统一处理
- 金额字段统一用 BigDecimal,禁止 float/double
- ID 用 IdGenerator 雪花算法生成,禁止数据库自增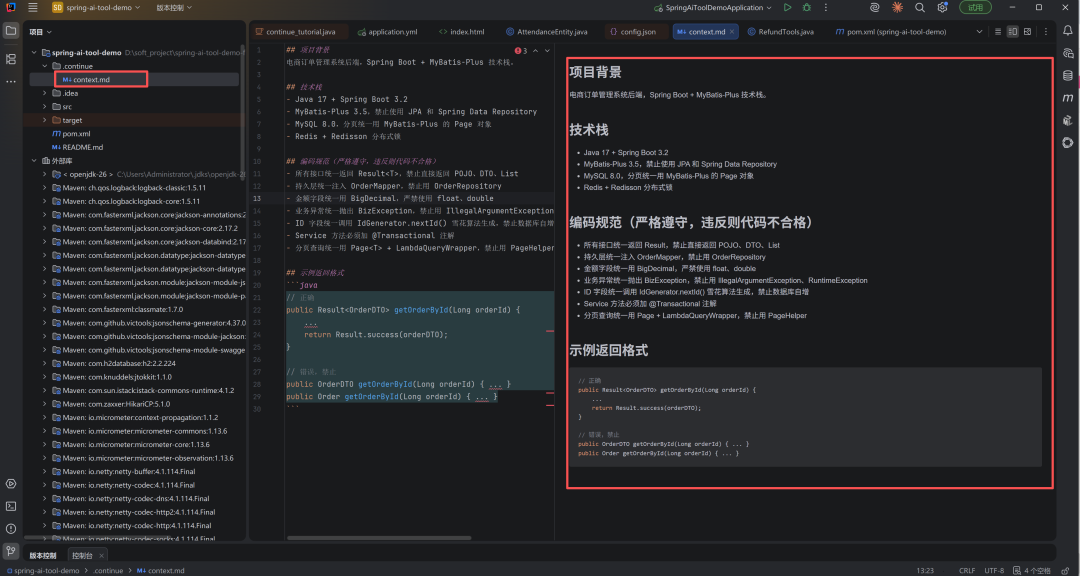
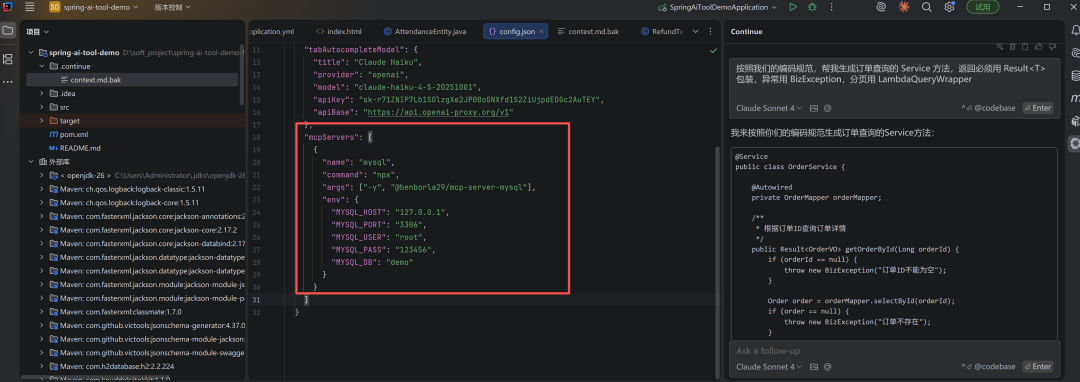
MCP:让 Claude 直接连上你的数据库
这是个进阶配置,但用过之后很难回头。
MCP(Model Context Protocol)是 Anthropic 推出的一套标准协议,允许 AI 通过统一接口连接外部数据源。你可以把它理解成 AI 世界的 JDBC——定义了 AI 和外部工具之间的交互规范,不同数据源只需要实现这套协议,Claude 就能直接调用。Continue 已经支持了。
在 config.json 里追加 mcpServers 字段:
{
"mcpServers": [
{
"name": "mysql",
"command": "npx",
"args": ["-y", "@benborla29/mcp-server-mysql"],
"env": {
"MYSQL_HOST": "127.0.0.1",
"MYSQL_PORT": "3306",
"MYSQL_USER": "root",
"MYSQL_PASS": "yourpassword",
"MYSQL_DB": "your_db_name"
}
}
]
}
保存后重启 IDEA,Continue 对话框底部工具栏会出现数据库连接图标。
配完之后在对话里直接说:「帮我根据 purchase_order 表结构生成 Entity 和 ServiceImpl,符合我们的编码规范」,它会先查表再生成,金额自动 BigDecimal,ID 自动雪花算法。
Codex 怎么接
Codex 有两条路,取决于你的情况。
如果公司买了 GitHub Copilot,直接用就行。OpenAI 在 2025 年把 Copilot 底层升级成了 Codex 增强模型,Settings → Plugins 搜 GitHub Copilot 装上登录即可。
如果要自己接 Codex API,在 Continue 的 config.json 的 models 数组里追加:
{
"title": "OpenAI Codex",
"provider": "openai",
"model": "gpt-4o",
"apiKey": "sk-r71ZNIP7Lb1SOlzgXe2JP00oGNXfd1S2ZiUjpdEDGc2AuTEY",
"apiBase": "https://api.openai-proxy.org/v1"
}OpenAI API Key 在 platform.openai.com → API Keys 生成,流程和 Anthropic 一样。
日常开发的真实工作流
配置完是基础,用法才是关键。下面是我开发一个新接口的完整流程,没有夸张成分。
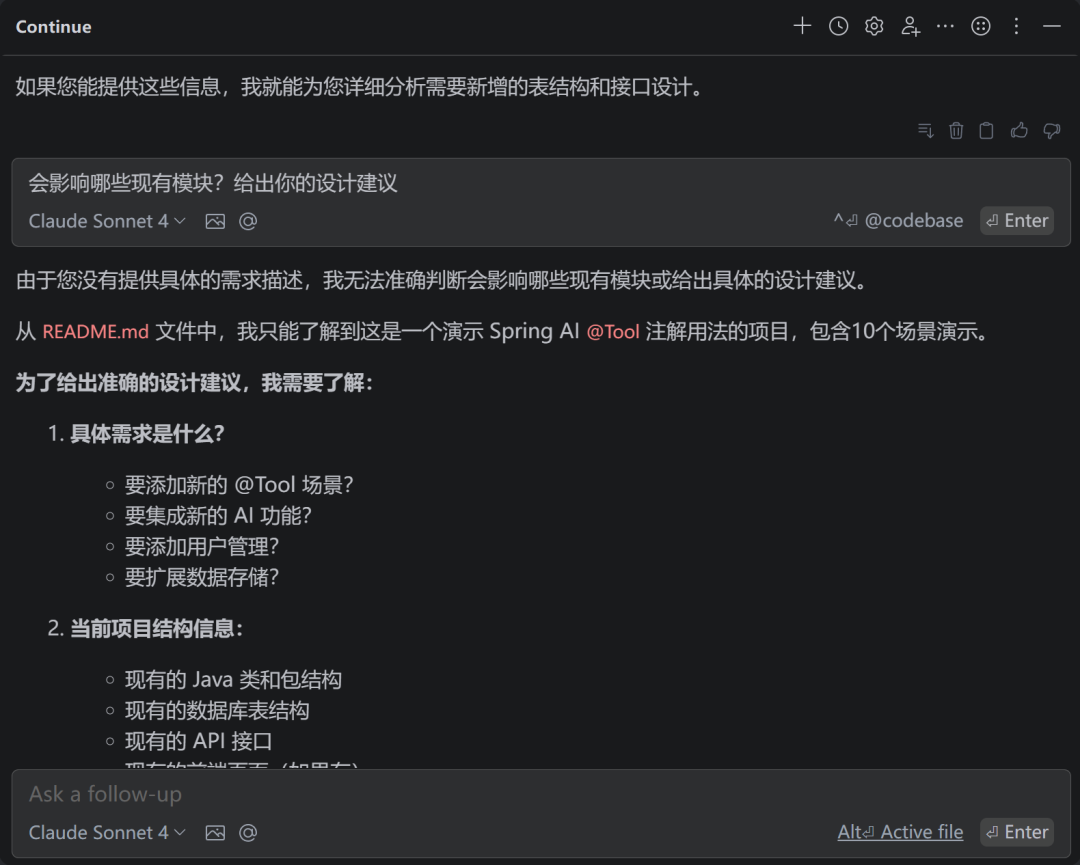
接到需求,产品给了一个文档,说要新增「供应商批量报价」功能。我先把需求文档整段粘进 Continue,问 Claude:
「基于我们现有的项目结构,这个需求需要新增哪些表、哪些接口?会影响哪些现有模块?给出你的设计建议。」
Claude 结合 context.md,告诉我需要新建 supplier_quote 和 supplier_quote_item 两张表,建议参考现有 purchase_order 的分层结构,库存扣减需要注意并发控制,沿用现有 Redisson 方案。这个分析我自己来想至少二十分钟,Claude 不到一分钟。
写业务逻辑时,Codex 在旁边实时补全。写一行注释,它把实现补出来。
写完核心业务方法后,选中代码,Cmd + L 发给 Claude 生成单测。
几个真实踩过的坑
Haiku 补全偶尔不遵守项目规范。在 context.md 里把禁止项写得越明确越好,比如"禁止用 float/double 存金额"比"金额用 BigDecimal"效果更好——强调禁止比强调应该更有效。实在不行就把补全模型换成 Sonnet。
MCP 在 Windows 上报 command not found。npx 路径解析问题,把 command 改绝对路径:
"command": "C:\\Program Files\\nodejs\\npx.cmd"context.md 超过 200 行效果反而变差。信息太多,Claude 抓不住重点。只写规范和禁止项,不要把整个设计文档塞进去。
写在最后
这套方案花了我大约两个下午配置和调试,之后就一直在用,没有再折腾过。
它不是银弹,复杂的业务决策还是要自己想,AI 没法替你做架构设计。但它能把那些「写起来繁琐但没有太多思维含量」的工作接管掉——CRUD 代码、单元测试、接口文档、Git commit message——这部分工作大概占了很多后端工程师日常时间的 30%-40%。
把这些时间腾出来,你可以做更有价值的事。
如果配置过程中遇到问题,欢迎评论区留言。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)