刚刚!DeepSeek V4 终于发布了 。。。
同时,DeepSeek-V4-Flash-Max在拥有更大的推理预算时,其推理性能与 Pro 版本相当,但由于其参数规模较小,在纯知识任务和最复杂的智能体工作流程方面自然略逊一筹。我们推出DeepSeek-V4系列的预览版,其中包括两个强大的混合专家 (MoE) 语言模型——DeepSeek -V4-Pro(1.6T 参数,已激活 49B)和DeepSeek-V4-Flash (284B 参数,已
欢迎大家进群,前200人直接加入 !

就在刚刚,DeepSeek V4正式发布了权重,技术报告,官方也公布了API价格。
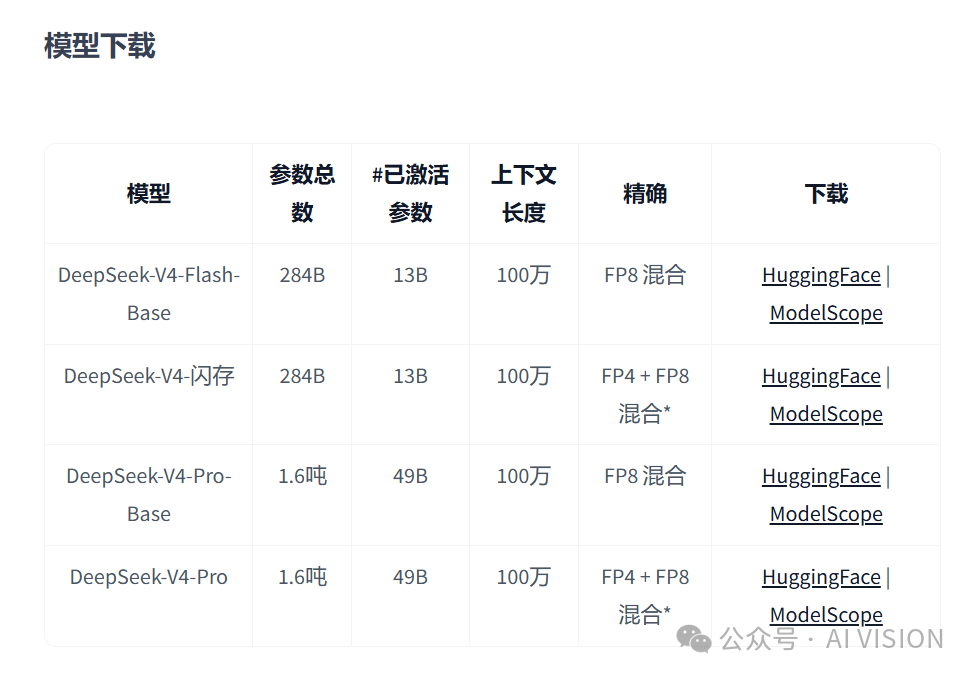
DeepSeek-V4提供Pro和Flash两个版本的模型,权重均已上传huggingface,分别为1.6T-A49B和284B-A13B的MoE模型。
https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash
根据介绍:
我们推出DeepSeek-V4系列的预览版,其中包括两个强大的混合专家 (MoE) 语言模型——DeepSeek -V4-Pro(1.6T 参数,已激活 49B)和DeepSeek-V4-Flash (284B 参数,已激活 13B)——两者均支持一百万个标记的上下文长度。
DeepSeek-V4系列在架构和优化方面进行了多项关键升级:
混合注意力架构:我们设计了一种混合注意力机制,结合了压缩稀疏注意力(CSA)和高度压缩注意力(HCA),以显著提高长上下文效率。在 100 万个词元的上下文设置下,与 DeepSeek-V3.2 相比,DeepSeek-V4-Pro 仅需27% 的单词元推理浮点运算次数和10% 的键值缓存。
流形约束超连接(mHC):我们引入 mHC 来加强传统的残差连接,增强跨层信号传播的稳定性,同时保持模型的表达能力。
Muon优化器:我们采用Muon优化器以实现更快的收敛速度和更高的训练稳定性。
我们使用超过32T 个多样化且高质量的词元对两个模型进行预训练,随后进行全面的后训练流程。后训练流程采用两阶段范式:首先,通过 SFT 和 GRPO 强化学习独立培养领域特定专家;其次,通过策略内蒸馏进行统一模型整合,将不同领域的专家技能整合到一个模型中。
DeepSeek-V4-Pro-Max是 DeepSeek-V4-Pro 的最高推理模式,显著提升了开源模型的知识能力,稳居目前最佳开源模型之列。它在编码基准测试中取得了顶尖性能,并在推理和智能体任务方面显著缩小了与领先的闭源模型之间的差距。同时,DeepSeek-V4-Flash-Max在拥有更大的推理预算时,其推理性能与 Pro 版本相当,但由于其参数规模较小,在纯知识任务和最复杂的智能体工作流程方面自然略逊一筹。
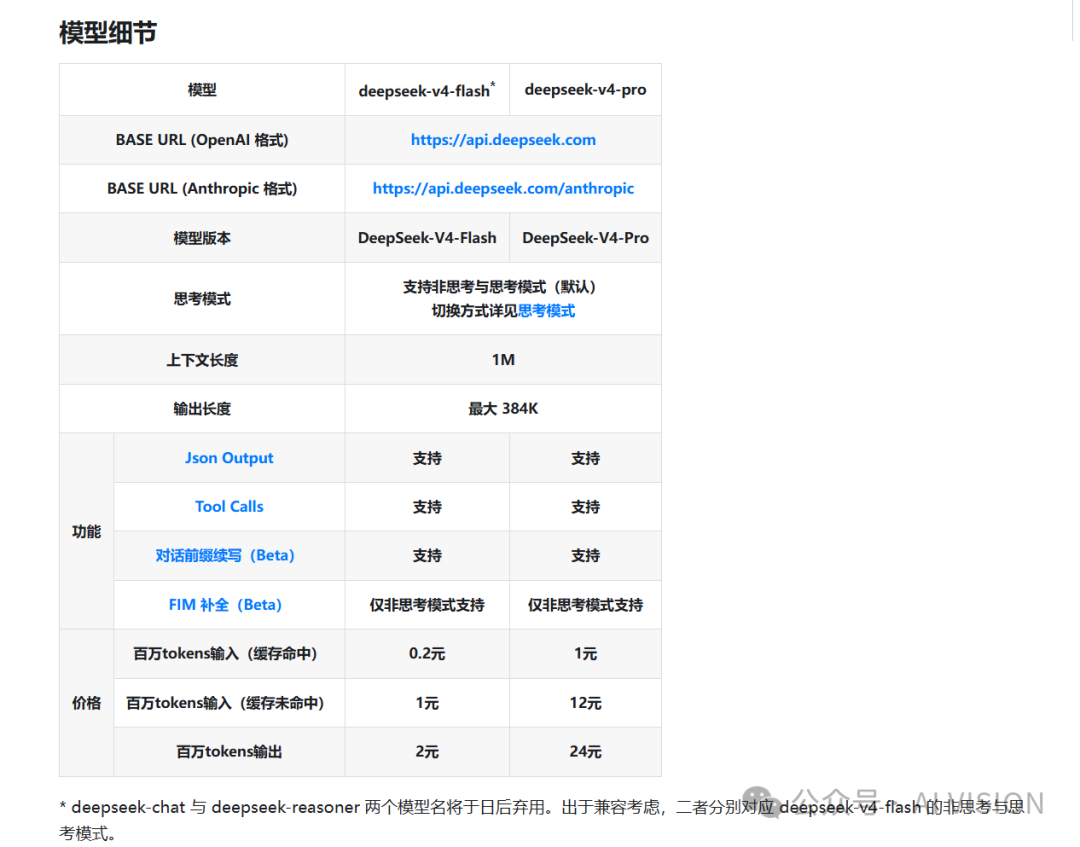
根据DeepSeek官方API页面,其中有介绍到deepseek-v4-flash、deepseek-v4-pro,上下文的长度为1M,输出长度最大384K。
与此同时,一个昇腾CANN的账号也显示了Deepseek V4昇腾首发的直播预告,时间为今晚19:00。
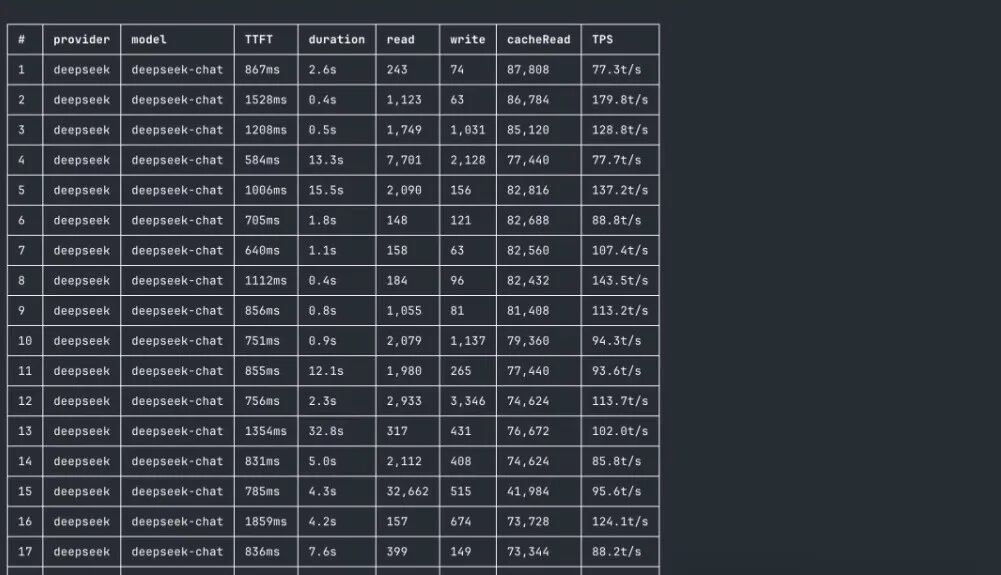
昨天,DeepSeek稳定上线的API模型表现出了惊人的性能指标。据网友实测,该模型的吞吐量达到了惊人的平均约130 TPS,同时有着很高的KV缓存命中率,远超其他国产模型服务的表现。这或许意味着DeepSeek在高性能低成本的 Infra 方面取得了新进展。相信 DeekSeek 将带领我们走向更低成本的token大生产时代,让 AI 能真正普惠大众。

⭐点赞、转发、在看一键三连⭐

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 0
0 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)