【卷卷漫谈】你的opus4.6降智了吗?!Claude Code 质量翻车复盘
上周五,Anthropic 悄悄更新了一篇工程博客,标题很朴素:《An update on recent Claude Code quality reports》。翻译成人话就是:我们要解释一下,为什么最近有用户说 Claude 变笨了。说实话,我看到这篇博客的第一反应是:终于承认了。过去一个月,Twitter、Hacker News、Reddit 上关于"Claude Code 变差了"的讨论就
(内心os:难怪之前的opus4.6不如之前聪明了)Anthropic 公开承认了 Claude Code 过去一个月的质量下降,并把它拆解成了三个独立事故、三种不同根因。看完这份报告,我的感受是:大厂翻车不可怕,可怕的是翻车之后不知道怎么复盘。Anthropic 这份"手术刀式"的复盘,值得所有做 AI 产品的团队抄作业。
上周五,Anthropic 悄悄更新了一篇工程博客,标题很朴素:《An update on recent Claude Code quality reports》。
翻译成人话就是:我们要解释一下,为什么最近有用户说 Claude 变笨了。
说实话,我看到这篇博客的第一反应是:终于承认了。
过去一个月,Twitter、Hacker News、Reddit 上关于"Claude Code 变差了"的讨论就没断过。有人吐槽它开始健忘,有人抱怨它执行到一半就卡住,有人说它变得特别话痨问东问西,还有人说它推理时间变短了但质量也跟着跳水。
Anthropic 的工程师们没有在社交媒体上跟用户对线,而是闷头查了一个月,最后交出了这份报告。
一、三件事,三个问题,三种教训
报告最核心的价值是把"质量下降"这个模糊投诉拆解成了三个独立的、因果关系完全不同的事故。
这个拆解本身就很有价值。因为很多团队在面对"产品变差了"这种复合投诉时,习惯性地会去找一个统一的原因——模型变差了、RLHF方向歪了、数据污染了。但 Anthropic 的工程师发现:这三个问题根本不是同一个原因,它们只是恰好在时间线上重叠了,所以看起来像是"全面退化"。
事故一:默认推理档位从"高"调成"中"(3月4日 → 4月7日修复)
Claude Code 在2月发布 Opus 4.6 时,把默认推理档位设成了 "high"。工程师们的解释是:Opus 4.6 在 high 模式下有时候会"想太久",导致用户界面看起来像死机了一样。
所以他们改了——把默认档位调成 "medium",理由是内部测试显示 medium 能在"稍微降低一点智能"的前提下大幅降低延迟,而且不会遭遇偶发的超长尾延迟,还能帮用户省着用 token 上限。
这个决策听起来是合理的对吧?甚至有点像在做用户调研后的理性优化。
但问题来了:用户在评论区直接开骂了。
用户反馈的核心是:我不介意等,我宁愿等久一点拿到的结果更好;你们凭什么替我选"省 token"而不是"要质量"?
4月7日,Anthropic 把默认档位改回去了。Opus 4.7 默认 xhigh,其他型号默认 high。
教训一:产品档位设计是用户体验,不是技术决策。 让用户为延迟付出代价是用户的权利,不要替他们做这个权衡——除非你真的做过足够大的用户调研并且有数据支撑。
事故二:缓存优化把历史推理内容清空了(3月26日 → 4月10日修复)
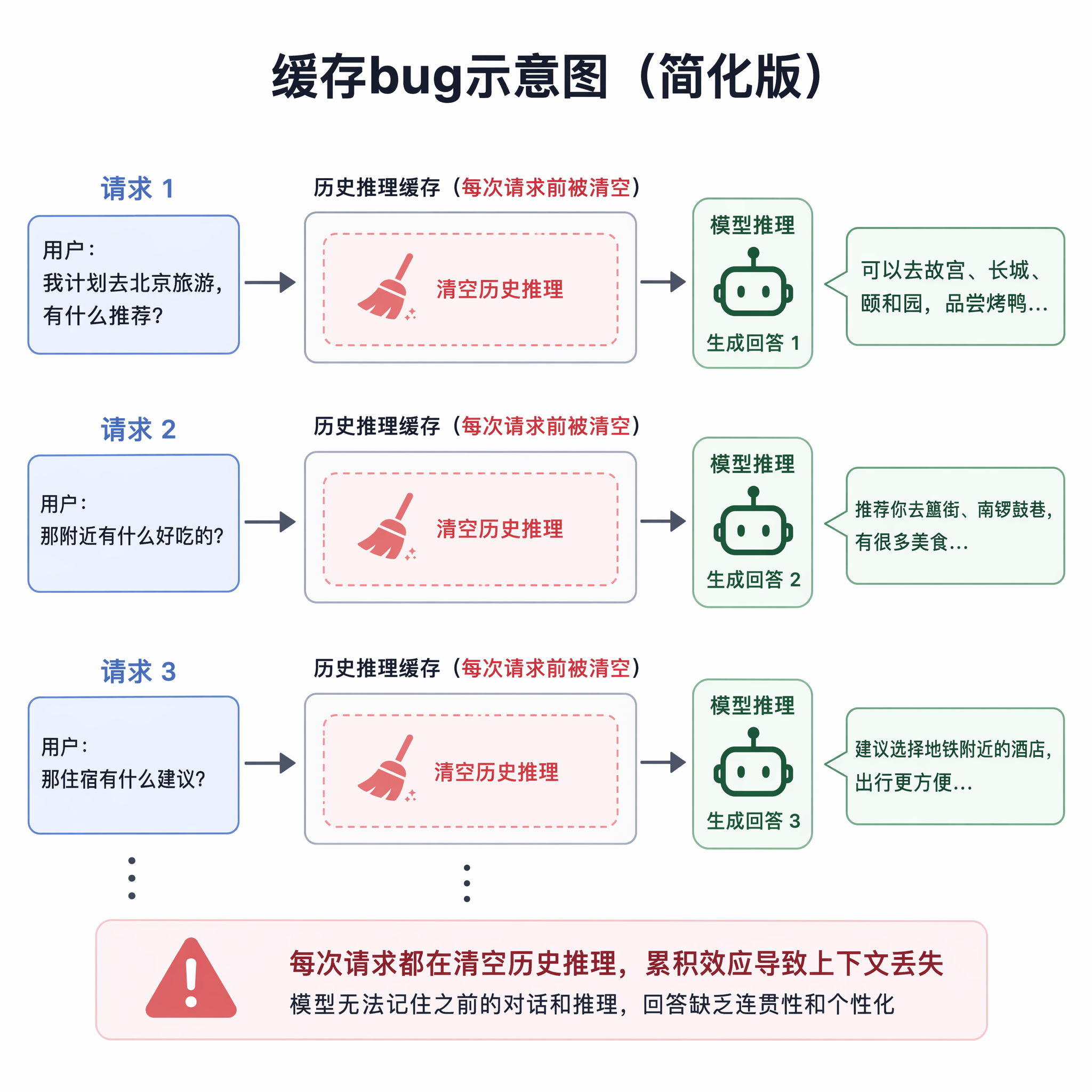
这个事故最有技术含量,也是造成"健忘"投诉的直接原因。
先科普一个背景:Claude Code 在执行任务时会把推理过程写入对话历史,这样下一轮对话时 Claude 能"记着"自己之前为什么选了某个方案、为什么排除了其他选项。这个推理历史是上下文的一部分,对保持任务连贯性非常重要。
Anthropic 的工程师在3月26日做了一个优化:他们在 API 请求里加了一个缓存层,用来在用户恢复一个超过1小时不活跃的会话时减少 token 消耗。设计上很简单——如果一个会话已经idle超过1小时,下次请求反正会 cache miss,那不如直接把旧的推理历史清理掉,减少传到 API 的 token 数量,这样既能省钱又能降低延迟。
实现方式是调用 clear_thinking_20251015 这个 API header,配合 keep:1 参数,意思是"只保留最近一段推理"。
代码逻辑写的是:如果 session idle 超时,就清理一次历史推理。
但实际跑起来变成了:每次请求都在清理历史推理。
Bug 在于,那个"idle超时"的判断条件被设计成"每次请求都检查",而不是"每个session只检查一次"。所以一旦 session 跨过 idle 阈值,后续的每一次请求都会触发清理逻辑,把历史推理一块一块地蚕食掉。
更糟糕的是,这个清理动作还会导致 cache miss——因为 cache 的 key 包含了请求内容,清理后下次请求内容变了,所以 cache 失效。这直接造成了另一个副作用:用户报告的 token 消耗比预期快。
Anthropic 自己在报告里承认:这个 bug 经过了多层检查——人类代码 review、单元测试、端到端测试、自动化验证、内部 dogfooding——全部通过了,但还是漏了。
为什么?
因为两个不相关的独立实验干扰了问题复现:一个是内部消息队列相关的纯服务端实验,另一个是 thinking 显示逻辑的改动在大多数 CLI session 里掩盖了这个 bug。再加上这个 bug 只在一个边角case("旧 session 恢复")才会触发,而这个场景在常规测试里很少被覆盖。
教训二:测试的边界条件永远小于产品实际运行的边界条件。 你的单元测试、集成测试、dogfooding 测试,本质上都是在你已知的路径上打转。真正的问题往往藏在"正常使用不会触发、但用户实际环境会触发"的边角 case 里。
事故三:减少冗长的 system prompt 把代码质量搞差了(4月16日 → 4月20日修复)
第三个事故是4月16日引入的,4月20日回滚,只存在了4天。
Anthropic 在 system prompt 里加了一条指令,让 Claude"减少冗长输出"。这个改动的出发点是好的——确实有用户抱怨 Claude 在代码任务里太话痨,一边写代码一边解释为什么要这么写,用户体验不好。
但问题在于:这条"减少冗长"的指令跟其他已有的 prompt 改动叠加在一起,产生了一个副作用——Claude 在代码任务里变得过于追求"简洁",以至于开始跳过必要的解释、减少测试用例的生成、删掉了那些"虽然长但有用的推理过程"。
这又是一个典型的组合效应。单独看"减少冗长"这条指令,没什么问题。单独看其他 prompt 优化,也没太大问题。但放在一起——尤其是跟"medium 推理档位"叠加——直接影响了代码输出质量。
教训三:prompt 的改动具有组合效应,单点测试看不出全局影响。 每次改 system prompt,本质上都是在对模型的整个行为空间做扰动。你加的一句话,可能在某个维度上压制了模型的某项能力,而那个维度恰好是用户最依赖的。
二、这份复盘报告为什么值得学
复盘报告我见过很多,大多数长这样:
"由于 XX 原因导致了 YY 问题。我们已经修复并加强了测试。以后会继续努力为用户提供高质量的服务。"
这种报告的废话含量极高,看了等于没看。
Anthropic 这份报告不一样。它有几个特征:
第一,它承认了"内部测试没发现问题"这个事实,但没有用它当挡箭牌。 很多公司的复盘会强调"我们做了充分测试",言下之意是"用户有问题是他们运气不好"。Anthropic 反而花了大量篇幅解释测试为什么没拦住这个 bug,以及未来打算怎么补上测试覆盖的盲区。
第二,它没有甩锅给外部因素。 不是说"LLM本身有随机性",不是说"算力不足影响模型表现",不是说"用户使用方式不符合预期"。每一个问题都被精确定位到了具体的代码改动、具体的决策逻辑、具体的测试盲区。
第三,它给出了具体的结构性改进行动,而不是泛泛的"加强测试"。 比如报告里提到要 back-test 那些有问题的 PR,用 Opus 4.7 对着代码仓库做完整的上下文理解,然后对比修复前后的输出差异。这个做法本质上是把 AI 模型当成了代码审查工具——用更强的模型来审查改动的安全性。
三、钱学森框架下的系统稳定性分析
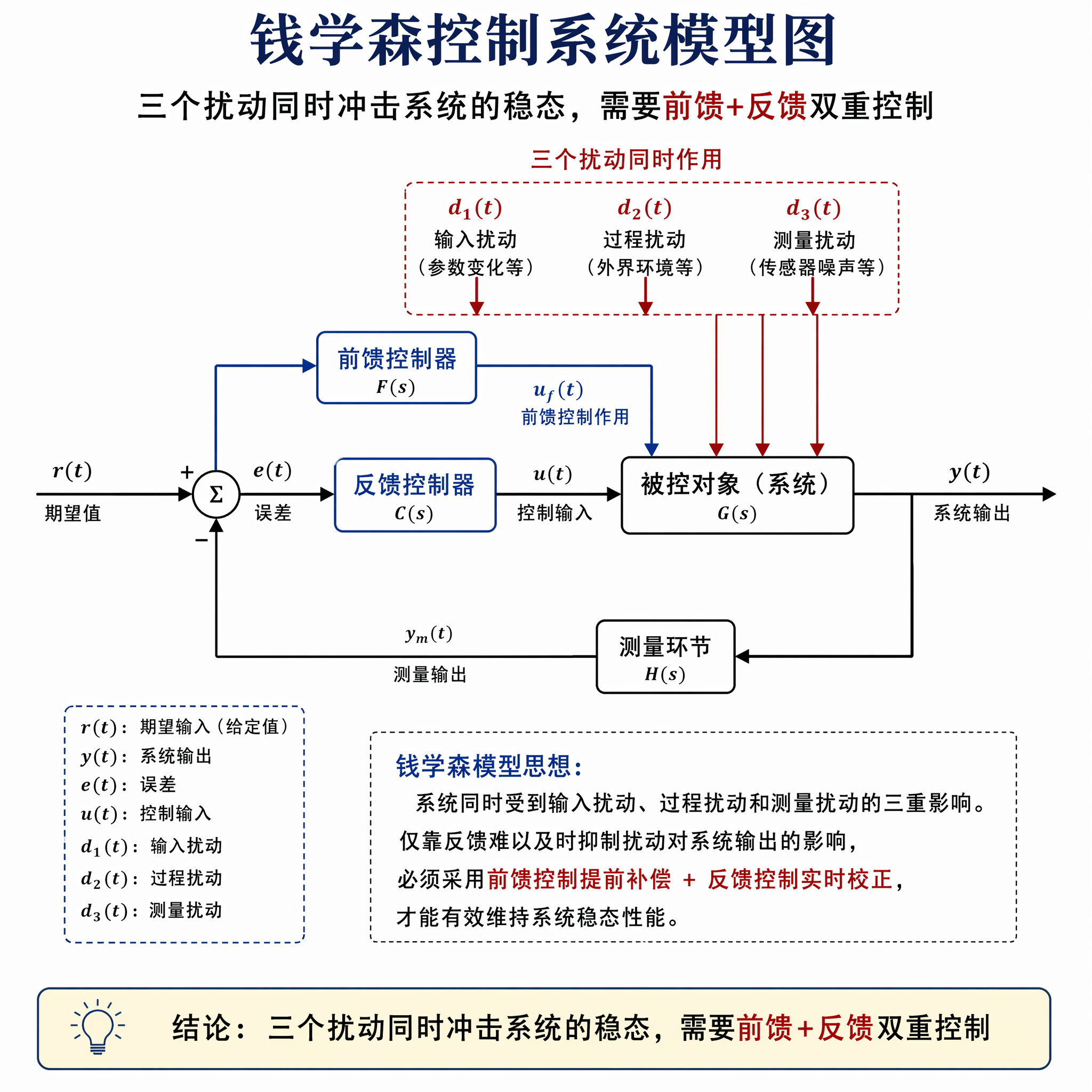
如果用钱学森《工程控制论》的视角来看这次 Claude Code 事件,它本质上是一个控制系统在受到多重扰动后失去稳态的过程。
Claude Code 的稳态是什么?是用户在代码任务上的满意度,以及模型输出的质量基线。这个稳态被三个"扰动"同时冲击:
- 扰动1(推理档位下移):降低了智能输出的上界
- 扰动2(推理历史被清空):破坏了上下文连续性,导致重复劳动
- 扰动3(冗长抑制prompt):压制了必要输出,降低了任务完整性
三个扰动各自独立,但在时间线上重叠后,它们的组合效应导致了系统整体的发散——用户感知到的不是"三个小问题",而是"Claude 整体变差了"。
工程控制论的核心问题是:怎么让系统在扰动存在的情况下依然保持稳定?
Anthropic 给出的答案是:单点修复不够,需要系统级的测试和监控。他们提到要建立"back-test"机制,用更强的模型(Opus 4.7)来审查改动的安全性。这本质上是在系统中加入了前馈控制——在改动上线前,通过模拟的方式提前预测可能的偏差,而不是等用户报告了再补救。
四、从这次事件看 AI 工程化的真实挑战
Claude Code 这次翻车,折射出一个正在成为行业共识的深层矛盾:
AI 产品在工程层面极度复杂,但在发布节奏上又被要求快速迭代。
Claude Code 是一个运行在用户本地机器上的 CLI 工具,它需要跟 Anthropic 的 API、用户本地的开发环境、不同型号 Claude 的特性、推理档位机制、上下文管理逻辑做复杂的交互。每一个维度都有大量的参数和边界条件。
在这种复杂度下,想要通过人工代码 review + 常规测试来保证每次改动都不引入退化,本质上是一个不可能完成的任务。
那怎么办?
答案可能就在 Anthropic 报告的最后那段话里:用更强的模型来审查改动的安全性。这本质上是用 AI 辅助 AI 开发——用 Opus 4.7 充当代码审查员,在改动上线前做全面的影响评估。
这个方向很值得跟进。但它也带来了新的问题:当 AI 开始审查 AI 的代码时,谁来审查审查者的判断?
回到钱学森的那句话:"用不太可靠的元件,可以做出非常可靠的系统。" Anthropic 的工程师们大概也有类似的认知——他们没有把 Claude Code 定位成"完美的代码助手",而是承认它会出问题、会退化、需要持续监控和修复。真正重要的是:系统有没有自我感知和自我修正的能力?
这次翻车证明了 Claude Code 至少还有这个能力——它能发现问题,能定位根因,能回滚改动,能向用户解释原因。这比很多"装死"的系统已经强太多了。
五、给所有 AI 开发团队的 checklist
基于这次事件,我整理了一个行动清单,供做 AI 产品开发的团队参考:
发布前检查:
- 每个 prompt 改动都要做组合影响分析,而不是单点测试
- 边界条件测试要覆盖"旧 session 恢复""长时间 idle 后继续"等边角场景
- 用更大规模的模型对有问题的 PR 做 back-test,模拟完整上下文理解
- 档位/参数改动要给用户明确的 opt-in/opt-out 机制,不要替用户做质量/速度权衡
发布后监控:
- 建立用户反馈的实时告警机制,而不是等周会汇总
- 对核心指标(任务完成率、用户满意度、平均轮次)做持续监控和同比环比
- 当多个维度同时出现下降趋势时,要警惕"组合效应"而不是孤立分析
组织层面:
- 复盘报告要刨根问底,不要用"模型有随机性"来搪塞
- 区分"bug导致的退化"和"设计决策导致的体验变化",处理方式不同
- 保持用户沟通渠道透明,翻车不可怕,装死才可怕

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 22
22 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)