DeepSeek V4 + PowerBI,BI 游戏结束
但模型是脑子,Power BI 是手,中间还缺一个把脑子和手接起来的"神经系统",它要听懂业务人的人话,要读懂 Excel、Word、PDF,要调用 Power BI 的语义模型,要在本地跑通整条链路。你说"帮我做一个 2024 年全年销售看板,突出华北区和华南区的对比",CC 调度 DeepSeek V4 生成看板配置、选图表、定布局、配色方案、下钻逻辑,十分钟出初稿。过去做 BI,业务人、BI
今天 DeepSeek V4 预览版上线,你可能已经刷到一堆"性能对标 Claude、价格十分之一"的通稿。
站在 BI 从业者的角度,DeepSeek V4 真正重要的不是参数有多大、跑分有多高,也不是 1M 上下文(Gemini 两年前就这么玩了)。是它同时做到三件前沿闭源模型一件都做不到的事:
-
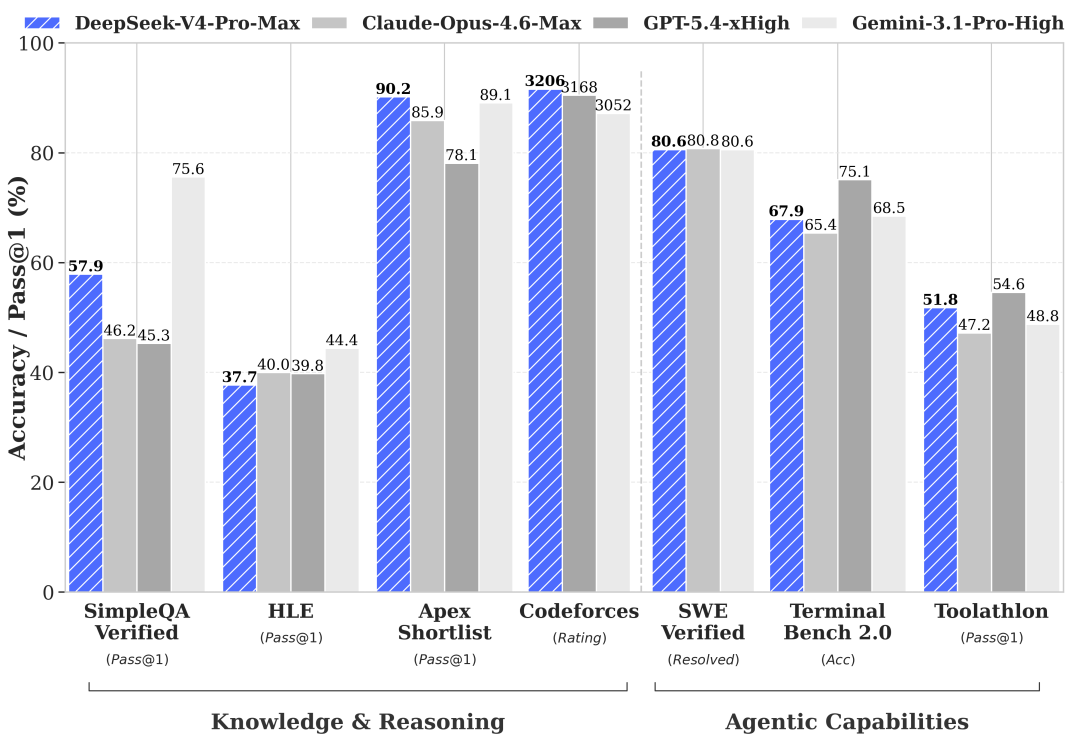
开源 MIT 协议 + 前沿水平:1.6T MoE 开源权重,可以完全本地私有化部署。Kimi K2 之前是开源最大,1.1T;GLM-5.1 是 754B。DeepSeek V4 是第一个把前沿性能开源给你的
-
价格打到地板:API 输入 1元/百万tokens、缓存命中 0.2元/百万tokens,更别说自部署后的边际成本基本为零
-
昇腾芯片原生适配:国产算力就能跑,信创合规场景第一次有真解
过去 AI + BI 这个组合为什么雷声大雨点小?不是模型不够强,是这三道墙一道都过不去,数据不敢上云、高频调用烧不起、硬件卡脖子买不到。
今天 DeepSeek V4 一次把三道墙全拆了。
但模型是脑子,Power BI 是手,中间还缺一个把脑子和手接起来的"神经系统",它要听懂业务人的人话,要读懂 Excel、Word、PDF,要调用 Power BI 的语义模型,要在本地跑通整条链路。
这个位置,就说我们的业务 AI 伙伴,CC。
DeepSeek V4(大脑)+ CC(神经系统)+ Power BI(手脚),这套组合今天开始真正跑通。下面六件事,过去任何一个都卡在某道墙上,现在全打通。
业务思路智能化
做过 BI 项目的都知道,真正难的从来不是技术,是业务需求梳理。
业务方说"我想看销售情况",翻译成 BI 语言是什么?看什么维度、什么粒度?对比哪段时间?核心指标还是过程指标?要不要分渠道、分区域、分品类?
过去靠 BI 顾问一遍遍开会、访谈、画思维导图,一个中等项目光需求阶段就能磨两三周。

为什么不直接让 AI 读公司资料?因为公司战略文档、KPI 考核表、过去三年的业务汇报,这些东西扔给在线 API 就等于泄密。法务过不去、合规过不去、老板更过不去。
DeepSeek V4 把这道墙拆了。开源本地部署意味着模型跑在自己服务器上,数据连公司防火墙都不出。完整业务语料一股脑扔进去,DeepSeek V4 在完整语境下理解你的业务。
CC 在上面做了一层壳。你用自然语言和它对话,它以"业务分析师"的角色把模糊的"我想看销售"逐层拆成指标体系、分析框架和优先级,甚至主动反问,"你说的销售是成交金额还是回款金额?退货要不要扣掉?赠品怎么算?"

业务思路这层窗户纸,AI 替你捅破了,而且是在你公司内网里捅破的。
数据清洗智能化
数据清洗是 BI 项目里最脏的活。
日期字段里一半 2024/3/5 一半 2024-03-05;客户名称"ABC 公司""ABC 有限公司""ABC 公司(北京)"全是同一家;金额列里混着文本格式;空值、0 值、异常值各自有不同含义……
过去这活给 AI 做有个成本问题。清洗从来不是一次过,加一个规则、跑一遍、发现问题、再改、再跑。一个中等复杂度的清洗任务,业务人反复调试几十轮是常态。用闭源旗舰模型,一轮下来几十万 token,一周下来 API 费用比雇个数据工程师还贵。
DeepSeek V4 把这道墙也拆了。输入 1元/百万、输出 2元/百万、缓存命中 0.2元/百万,这个价格下,业务人可以放开手让 AI 反复试错,成本不再是顾虑。真要省到底,自部署版本的 DeepSeek V4 连 API 费都不用交。
CC 里的流程是:Excel 直接拖进去,说一句"帮我清洗这份销售数据,日期统一、客户去重、金额转数值"。DeepSeek V4 读完所有字段,生成 Power Query 的 M 代码,CC 通过 MCP 协议把代码注入 Power BI,一次跑通。跑完不对?把错误贴回去,它自己改。

业务人看到的只是"我说了一句话,然后干净的数据就出现了"。
数据建模智能化
维度建模这件事,曾经是 BI 工程师的护城河。
事实表要不要拆?维度表到什么粒度?退化维度怎么处理?缓慢变化维度用哪一类型?星型还是雪花?这些答案不在书里,在经验里。
过去 AI 建模卡在哪?和第一节一样,卡在合规。企业数据模型是核心资产,表结构、字段命名、业务规则、历史口径全是商业机密,发给闭源 API 合规部门第一个不同意。所以过去的"AI 建模"演示都是用公开数据集在玩,真落到企业内部就推不动。
V4 开源本地部署这条路,才让这件事从"演示"变成"生产"。
把 ERP 导出的 20 张表结构丢给 CC,说一句"这是一家连锁零售企业的销售数据,我要做一个分析经营情况的看板"。V4 在本地跑,告诉你哪些是事实表、哪些是维度表、关系怎么建、粒度定在单据行级还是商品级、需要补哪些派生字段。接下来更离谱的是,它直接把 DAX 度量值写好:销售额、同比、环比、占比、同店同比、滚动 12 个月销售额,一套打包注入你的 Power BI 模型。

这些 DAX 过去是 Power BI 工程师收费的核心,现在边际成本接近零,而且整个过程数据没出过公司内网。
数据分析智能化
BI 做完了,业务方看了一眼问:"为什么 3 月华北区销售下滑?"
过去这个问题要走一套流程:业务分析师提需求,数据分析师拉数据,做归因分析,写报告。快则两天,慢则一周。
问题不是 AI 做不了归因,是高频归因烧不起钱。一个一百人规模的公司,业务部门每天几十上百个归因问题。用闭源旗舰模型,一个月 API 账单十几万起。大多数企业试了两个月就放弃了。
DeepSeek V4 把这道墙也拆了。2元/百万 tokens 输出 的定价 + 缓存命中 90% 折扣,意味着同样的调用量成本压到原来的 5%~10%。自部署版本更是把 API 成本直接归零,你买的是算力,不是 token。
某电商平台的运营负责人用 CC 之后分享说:以前做促销数据分析要外包,5000 元一次,等 3 天才有结果;现在自己就能做,随时掌握销售数据。
CC 里的流程是:把 3 月数据切片丢进去,一句话让它归因。自上而下拆:总量下滑多少 → 哪几个子区域跌得最多 → 哪些品类贡献了下滑 → 客单价问题还是订单量问题 → 和去年同期、环比、预算分别什么情况 → 给出三到五个最可能的业务假设。

分析师的价值从"执行分析"转向"判断结论是否靠谱、制定下一步行动",这才是人该做的事。
数据看板智能化
一个好看又好用的 Power BI 看板,过去得懂视觉设计、懂信息层级、懂色彩心理学。
DeepSeek V4 在这一节有一个具体的工程优势,原生 Agent 适配。发布公告里明确提到,DeepSeek V4 对 Claude Code、OpenClaw、OpenCode、CodeBuddy 这些主流 Agent 框架做了原生适配,不是靠外挂硬接。
意味着什么?意味着 DeepSeek V4 可以直接操纵 Power BI Desktop 的脚本接口、读写 PBIX 文件、调用 Power BI REST API。不是"给你生成一段配置你自己复制进去",是"它自己把这件事做完"。
CC 架在这层能力上。你说"帮我做一个 2024 年全年销售看板,突出华北区和华南区的对比",CC 调度 DeepSeek V4 生成看板配置、选图表、定布局、配色方案、下钻逻辑,十分钟出初稿。

某制造企业财务总监的反馈:"月报是最痛苦的事,整个团队要忙 3 天。现在上传文件,2 小时出报告,准确率还更高。"
3 天变 2 小时,不是文案,是「BI佐罗AI智能体」学员用下来的真数。
AI 问数智能化
最后是最关键的那一环,AI 问数。
先澄清一个误区。市面上大部分所谓"AI 问数",其实是 AI 问答,你问一句,AI 给你一个回答或建议,然后告诉你"具体你去做"。本质还是你在干活。
CC 不是 AI 问答,是 AI 智能体。区别是什么?
|
场景 |
传统方式 |
AI 问答 |
CC(AI 智能体) |
|---|---|---|---|
|
数据报表 |
手动整理 Excel |
AI 出主意,你来做 |
上传文件,自动生成 |
|
市场分析 |
找 IT 帮忙等几天 |
AI 出主意,你来做 |
直接问,立即出结果 |
|
日常汇报 |
熬夜做 PPT |
AI 出主意,你来做 |
描述需求,自动生成 |
|
上手难度 |
学软件、找教程 |
要反复追问 |
说话就行 |
|
处理速度 |
慢 |
中 |
快 10 倍 |
AI 问数的真正难点不是单次查询,是企业敢开、业务人敢高频用。
Gemini Flash、GPT-4.1 nano 这些模型其实也快、也便宜、也支持长上下文。但问数的数据来源是企业内部数据库,销售明细、客户信息、供应链合同,走公网 API 这一步,合规部门不会放行。过去两年,多少"AI 问数"项目卡死在这里,卡在 PoC 过不了上线。
DeepSeek V4 把最后这一公里打通,开源 + 本地部署 + 企业内高频调用零公网暴露。
业务老板打开 CC 问:"过去 30 天 Top 10 客户的复购率趋势怎么样?哪几家最近有异常?"V4 在内网跑,理解问题、生成 DAX 查询、CC 调用 Power BI 语义模型,十秒内返回一张趋势图、一段文字解读、标红三家异常客户。
追问:"这三家之前有什么共同特征吗?"
CC 继续挖。这是过去 AI 问数做不到的,不是单次查询,是连续的、带记忆的业务对话,而且整场对话里公司数据一个字节都没离开过内网。

为什么是今天
回过头看这六件事。
过去做 BI,业务人、BI 工程师、数据分析师三方协作,周期长、成本高、需求一变全盘推倒。业务人最苦,提需求提不明白,等看板等到花都谢了,看到成品发现不是自己想要的,改动一次又得排三周队。
为什么 AI + BI 喊了两年,企业里真正跑起来的屈指可数?
三道墙:
-
数据合规墙,闭源 API 不能喂公司机密
-
成本墙,高频调用一个月烧掉一个部门预算
-
算力墙,国产化合规企业买不到英伟达
这三道墙同时拆掉,今天是第一次。DeepSeek V4 开源 + 地板价 + 昇腾适配,三把钥匙一把不缺。
CC 站在这三把钥匙上,把"模型能力"翻译成"业务人用得上的生产力"。Power BI 作为最成熟的企业 BI 平台承接落地。
三者缺一不可:
-
只有 DeepSeek V4 没有 CC,业务人对着 API 发呆
-
只有 CC 没有 DeepSeek V4,回到之前"上云合规过不去、API 调用烧钱、国产算力没支持"的死循环
-
只有 DeepSeek V4 + CC 没有 Power BI,报表展示、权限管控、企业级分发都得从零做
三位一体,才是今天这件事的全貌。

「BI佐罗AI智能体」学员身上测出来的一组数:
-
每月节省 66 小时(平均每天 3 小时 × 22 天)
-
相当于多请 1 个助理
-
数据错误减少 90%
-
决策速度从"等明天"变成"现在就要"
500+ 企业已经在这条路上了。
业务人第一次有机会端到端自己把 BI 这件事做完。他们最懂业务,最知道想看什么、为什么看。过去卡在工具门槛、IT 排期、预算上的想法,现在可以直接变成看板、变成分析、变成决策。
这就是"业务人价值潜能的高度释放",不是说业务人要变成技术人,而是说技术这件事的权重大幅下降,业务判断力的权重大幅上升。

一个懂业务的人,配一个 DeepSeek V4,加一个 CC,加一个 Power BI,能干过去一个五人 BI 团队的活。
游戏结束,从今天开始。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 0
0 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)