Deepseek MLA和MLA absorb
主要方法是将Q K V用一个相对低秩的矩阵来存储,可以降低显存空间,以及一部分计算量, 为解决位置相关的信息丢失问题,将压缩后的QK又单独concat。MLA和MHA的区别是QKV计算的过程不同,其后的Attention计算以及linear流程基本是一致的。图中可以看到tokens输入的d维度是7168,q_down压缩之后的维度是1536+576,q_up解压后的维度是32*(128+64)=6
1. MLA原理
多头潜在注意力(Multi-Head Latent Attention, MLA)是由深度求索(DeepSeek)公司在2024年5月发布的DeepSeek V2模型中提出的一种创新注意力机制, 可以理解为一种升级版的MHA(Multi-Head Latent Attention)。 主要方法是将Q K V用一个相对低秩的矩阵来存储,可以降低显存空间,以及一部分计算量, 为解决位置相关的信息丢失问题,将压缩后的QK又单独concat。MLA和MHA的区别是QKV计算的过程不同,其后的Attention计算以及linear流程基本是一致的。
其中
2. MLA 模型架构图
图中可以看到tokens输入的d维度是7168,q_down压缩之后的维度是1536+576,q_up解压后的维度是32*(128+64)=6144,整体维度都是压缩了。
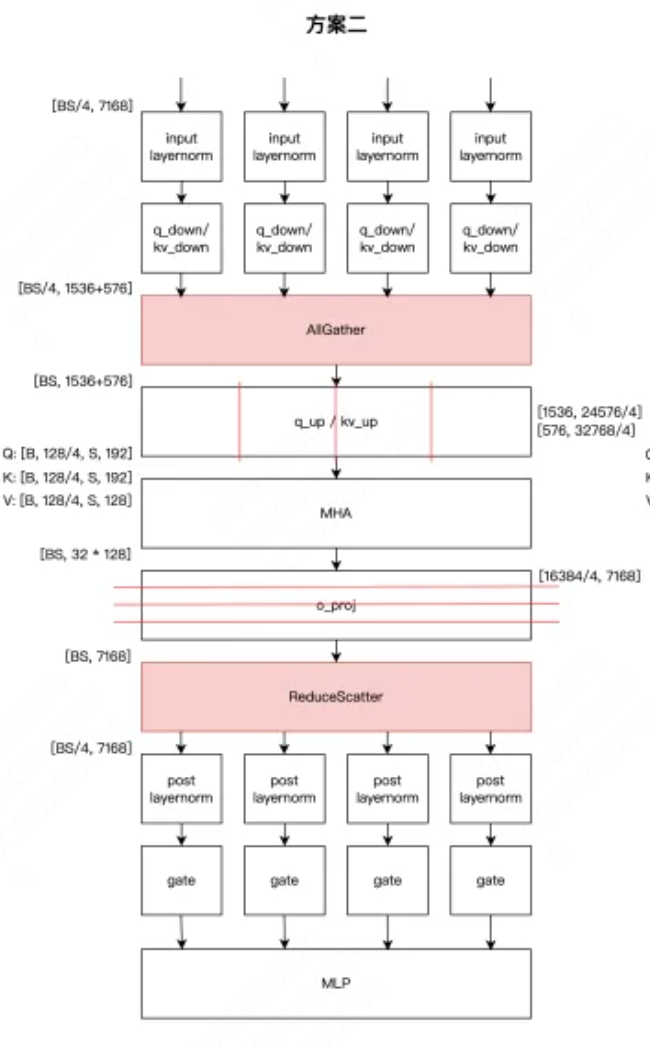
3.MLA absorb原理
MLA absorb 解决性能问题的方法和Linear attention有点像。本质是矩阵三连乘问题,应该是先左乘还是右乘,显存占用以及计算量越少。
变化在 , 优先做左乘,而不是原生的
。其中
,
,
这部分原生MLA的复杂度, 主要复杂度是
, MLA absorb的复杂度
, 主要复杂度是
, 算子显存优化比是d:dc, 以上图中d=7168, dc=1538。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)