DeepSeek-V4全栈适配实测:企业级部署的算力基础设施方案
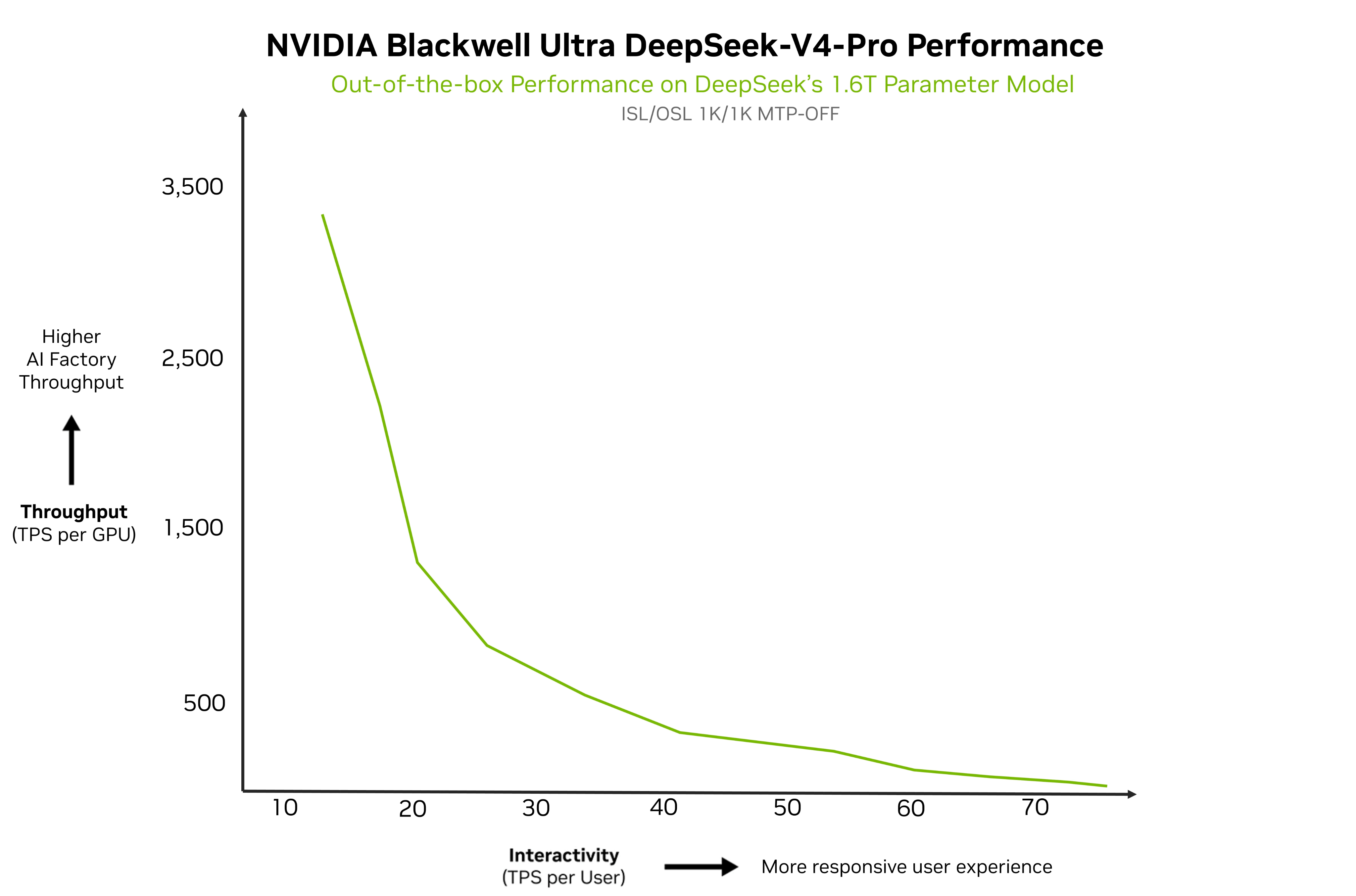
DeepSeek-V4正式发布72小时内,算力层完成首轮适配闭环: NVIDIA于发布当日即宣布Day-0支持,基于Blackwell Ultra架构在1.6T参数模型上测得约3500 tokens/s的峰值推理吞吐(per GPU,初步数据),并明确随着co-design stack持续优化,该性能基准仍有上浮空间。
一、模型架构与技术特征
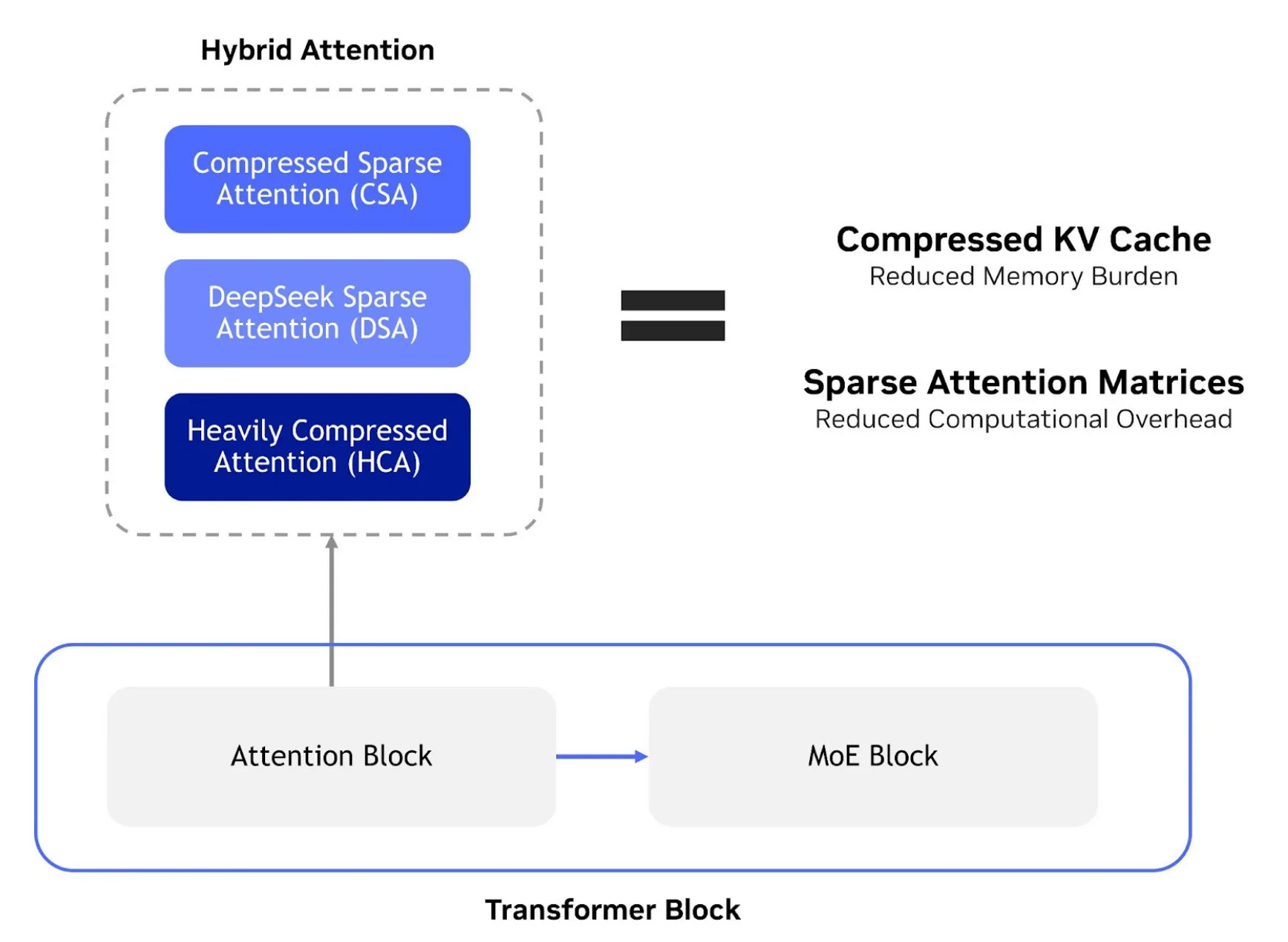
DeepSeek-V4采用混合注意力架构(CSA+HCA+DSA)与MXFP4混合精度训练,核心参数如下:
关键技术点:
●MXFP4精度: 较FP8进一步降低显存占用,单Token推理FLOPs降至V3.2的27%,KV Cache占用降至10%
●混合注意力: CSA(Compressed Sparse Attention)处理长序列,HCA(Heavily Compressed Attention)处理极长上下文,DSA(DeepSeek Sparse Attention)处理标准场景
●细粒度EP: 在英伟达GPU和华为昇腾NPU双平台上验证通过,通用推理1.50-1.73倍加速,延迟敏感场景最高1.96倍
二、算力生态适配现状(截至4月27日)
NVIDIA Blackwell:
●Day-0支持,基于vLLM项目提供开箱即用方案
●GB300/Blackwell Ultra实测:1.6T模型约3500 TPS/GPU(ISL/OSL 1K/1K,MTP-OFF,初步数据)
●技术栈:NVFP4 + Dynamo + 优化CUDA内核 + 高级并行化
国产芯片:
●华为昇腾950PR:单卡算力较H20提升2.87倍,原生支持MXFP4
●寒武纪、摩尔线程S5000、燧原L600、天数智芯:发布当日同步宣布适配
●关键优势:MXFP4指令集与V4训练精度直接对齐,无需精度转换开销
三、企业部署的工程挑战
1. Agent场景的系统稳定性
V4 Agent任务执行时间从分钟级延伸至小时级,对基础设施要求:
●7×24持续运行能力
●任务断点续传机制
●多Agent并行时的资源隔离与优先级调度
2. 长上下文的系统瓶颈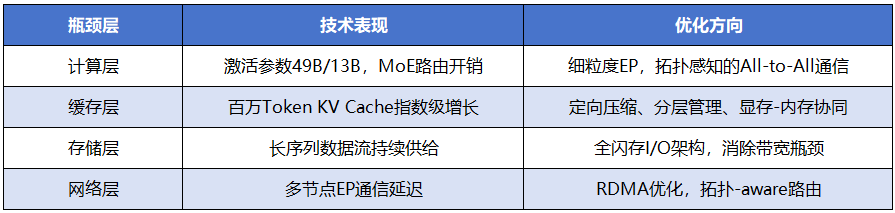
四、赋创从单机到集群:四阶段部署路径
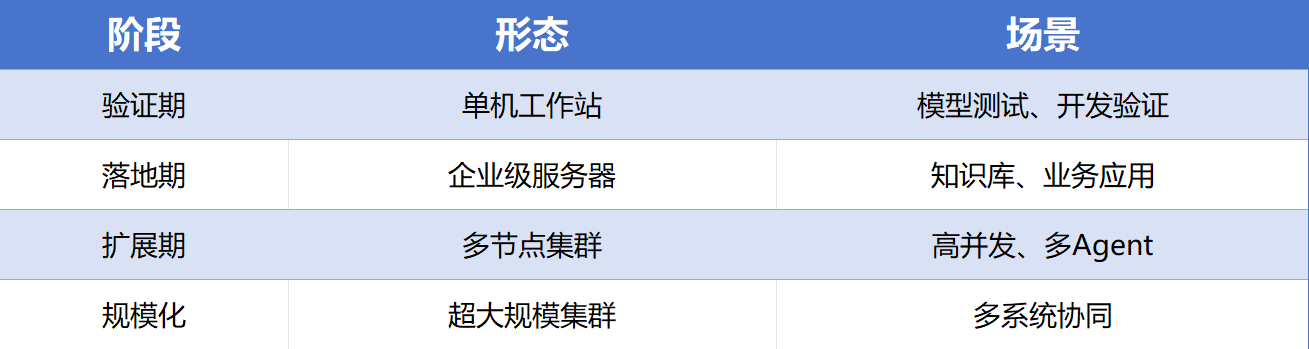
关键不在规模大小,而在架构一致性。实际部署中,常见陷阱是阶段一买的机器,阶段二用不上,资源白白浪费。更务实的做法是保持架构一致、节点按需扩展、模型灵活切换。
赋创已完成DeepSeek-V4全栈适配验证,具备面向企业级场景的算力基础设施交付能力。具体部署配置需结合业务负载、数据规模与合规要求进行针对性设计,欢迎与赋创技术团队沟通具体需求。
五、FAQ
Q1:部署门槛是否降低?
模型效率提升,但系统要求更高。MXFP4降低显存需求,但长上下文对I/O和稳定性提出硬性要求。
Q2:是否必须Blackwell?
不是。Hopper架构同样支持,但Blackwell在吞吐效率上有明显优势。国产昇腾950PR已验证等效能力。
Q3:国产算力是否可行?
已具备Day-0级适配能力。MXFP4指令集原生对齐,无需精度转换。
Q4:是否需要直接上集群?
建议先单机验证场景价值,确认后再按需扩展。
Q5:赋创支持哪些形态?
国产+国际双路线,单机到超大规模集群,架构一致,平滑扩展,可根据业务场景提供定制化架构设计与配置建议。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)