Claude Code源码解析学习
前端时间,claude code源码泄漏。不过需要注意的是,泄漏的是 Claude Code 客户端的源码,并不是 Claude Opus 大模型的源码。那既然是客户端而不是大模型的源码,我们学它有什么用呢?主要在于,claude code源码模型简直就是这段时间AI圈爆火的Harness Engineering的最佳教科书。即给大模型套上缰绳Harness。用系统去约束它的行为,让大模型不至于肆意洒脱,而是稳稳当当的完成任务。
一.agent的实现及四大隐患
Claude Code 的本质就是一个 AI Agent。那什么是Agent呢?Agent 的核心是一个「感知-决策-行动」的自主循环。你给它一个目标(比如「帮我修复这个 bug」),它会自己决定先读哪个文件、再跑什么命令、然后改哪行代码,整个过程可能循环几十轮,直到任务完成。关键:大模型自己决定下一步做什么。
首先在接下来我们用的简化版代码来自开源项目learn-claude-code(shareAI Lab出品,MIT 许可,GitHub46.8K星),它把Claude Code的核心架构用Python拆解成了12个渐进式阶段。后续我们统一称之为"简化版代码"。今天先看最基础的第一阶段-------s01_agent_loop.py
那么首先来看一眼完整文件的结构。s01_agent_1oop.py总共120行,但去掉注释、导入和辅助代码后,真正的Agent逻辑只有大约30行有效代码,分成三个部分:
第一部分:工具定义(9行)
Agent需要"手"来操作世界。s01只给了它一只手一一一个bash工具:
TOOLS = [{
"name": "bash",
"description": "Run a shell command.",
"input_schema": {
"type": "object",
"properties": {"command": {"type": "string"}},
"required": ["command"],
},
}]我们知道当代agent在运行的时候,其实他的这个整体的运行逻辑或者核心骨架其实非常非常简单啊,就是能调用工具的大模型加上CMD命令行工具,基本上就构成了所有我们现在能看到的。
这个工具的作用在于它告诉 AI:“嘿,你现在拥有了一个执行 Bash 命令的能力。如果你在解决问题时需要运行代码或操作系统,你可以调用这个工具。”Claude code生产版有40多个工具---文件读写,搜索,Git操作等都是基于上述这个结构的扩展。
第二部分:核心循环agent_loop(21行)
这是整个Agent的灵魂,也是我们今天最重要的代码。仔细看这21行:
# -- The core pattern: a while loop that calls tools until the model stops --
def agent_loop(messages: list):
while True:
response = client.messages.create(
model=MODEL, system=SYSTEM, messages=messages,
tools=TOOLS, max_tokens=8000,
)
# Append assistant turn
messages.append({"role": "assistant", "content": response.content})
# If the model didn't call a tool, we're done
if response.stop_reason != "tool_use":
return
# Execute each tool call, collect results
results = []
for block in response.content:
if block.type == "tool_use":
print(f"\033[33m$ {block.input['command']}\033[0m")
output = run_bash(block.input["command"])
print(output[:200])
results.append({"type": "tool_result", "tool_use_id": block.id,
"content": output})
messages.append({"role": "user", "content": results}) 这段代码实现了一个 基于 ReAct 模式的智能体循环(Agent Loop):它通过一个 while 循环让 AI 处于“思考—行动—观察”的迭代状态,当 AI 发现无法直接解决问题时,会主动调用工具来执行系统命令,并将命令的返回结果作为新的上下文反馈给 AI,直到任务完成且 AI 停止调用工具为止。
这就是Agent的全部秘密。整个模式可以用一句话总结:
Agent=while循环+工具调用+ stop_reason 检查
LLM说”我需要执行一个命令",Agent就执行;执行完把结果喂回去,LLM看了结果决定是继续调工具还是回复用户。这个循环一直转,直到LLM说”"我说完了"(response.stop_reason != "tool_use":)
注:Claude Code的51.2万行TypeScript中,与LLM API直接交互的代码只有约8,000行(1.6%),核心循环与这21行Python的逻辑完全一致。剩下的98.4%一一后面会揭晓它们在干什么。
真实Claude Code源码中的核心循环
在Claude Code 的51.2万行 TypeScript 中,这个核心循环藏在 src/query.ts 里1,729行的文件,核心结构是一个AsyncGenerator驱动的状态机。听起来复杂?其实核心逻辑和我们简化版代码的while循环完全对应:

但是我们应该知道,就这个命令行和loop组成的大模型会有各种各样的问题,那么claude code是如何解决他的呢?
首先第一个问题就是上下文会不断地增加。首先第一点就是上下文窗口的问题,只能保留一部分记忆;第二点就是上下文越长,重要性会被稀释。第二个问题就是关掉就失忆,重开全不知。第三个就是安全方面的问题。s01对其的安全措施是怎么样的,可以看一下run_bash函数:
def run_bash(command: str) -> str:
dangerous = ["rm -rf /", "sudo", "shutdown", "reboot", "> /dev/"]
if any(d in command for d in dangerous):
return "Error: Dangerous command blocked"
try:
r = subprocess.run(command, shell=True, cwd=os.getcwd(),
capture_output=True, text=True, timeout=120)
out = (r.stdout + r.stderr).strip()
return out[:50000] if out else "(no output)"
except subprocess.TimeoutExpired:
return "Error: Timeout (120s)"
except (FileNotFoundError, OSError) as e:
return f"Error: {e}"安全检查的全部代码就这两行,一个硬编码的字符串列表,非常鸡肋:
if any(d in command for d in dangerous):
return "Error: Dangerous command blocked"第四个问题就在于每轮都要发全量历史,导致线性成本增长,那么我们回头来看agent_loop函数的第83行:
while True:
response = client.messages.create(
model=MODEL, system=SYSTEM, messages=messages,
tools=TOOLS, max_tokens=8000,
)注意 messages=messages代表我每次调用API都会把完整的history发过去。这意味着:
- 第1轮API调用发送100 token
- 第2轮发送200token(第1轮+第2轮)
- 第3轮发送300token(第1、2、3轮全部)
- 第N轮发送N*平均单轮token
API按token计费,这意味着你为早期的对话内容反复付费。第1轮的内容在第10轮还在付费在第100轮还在付费。而且如果你同时跑多个任务一一比如让一个Agent改前端、另一个改后端它们各自独立积累history,没有任何共享。
更糟糕的是,这种成本增长和前面的"上下文膨胀"问题是同一枚硬币的两面:上下文越大,既消耗注意力(质量下降),又消耗token(成本上升)
| 致命问题 | 根本原因(代码层面) | 对应的约束 |
|---|---|---|
| 上下文越来越大,质量下降 | history.append() 只增不减 |
约束工作台(上下文管理) |
| 关掉就失忆,无法跨会话延续 | history=[] 每次从零开始 |
约束记忆(三层记忆+AutoDream) |
| 安全裸奔,5行字符串匹配 | dangerous = [...] 硬编码黑名单 |
约束行为(四层安全纵深) |
| 成本线性增长,多任务无法共享 | messages=messages 全量发送 |
约束成本(Fork缓存+编排者模式) |
这30行代码就是一个Agent一一能工作,但有四个致命缺陷。而Claude Code的51.2万行代码,就是为了约束这个不完美的AI。
二.Harness Engineering架构
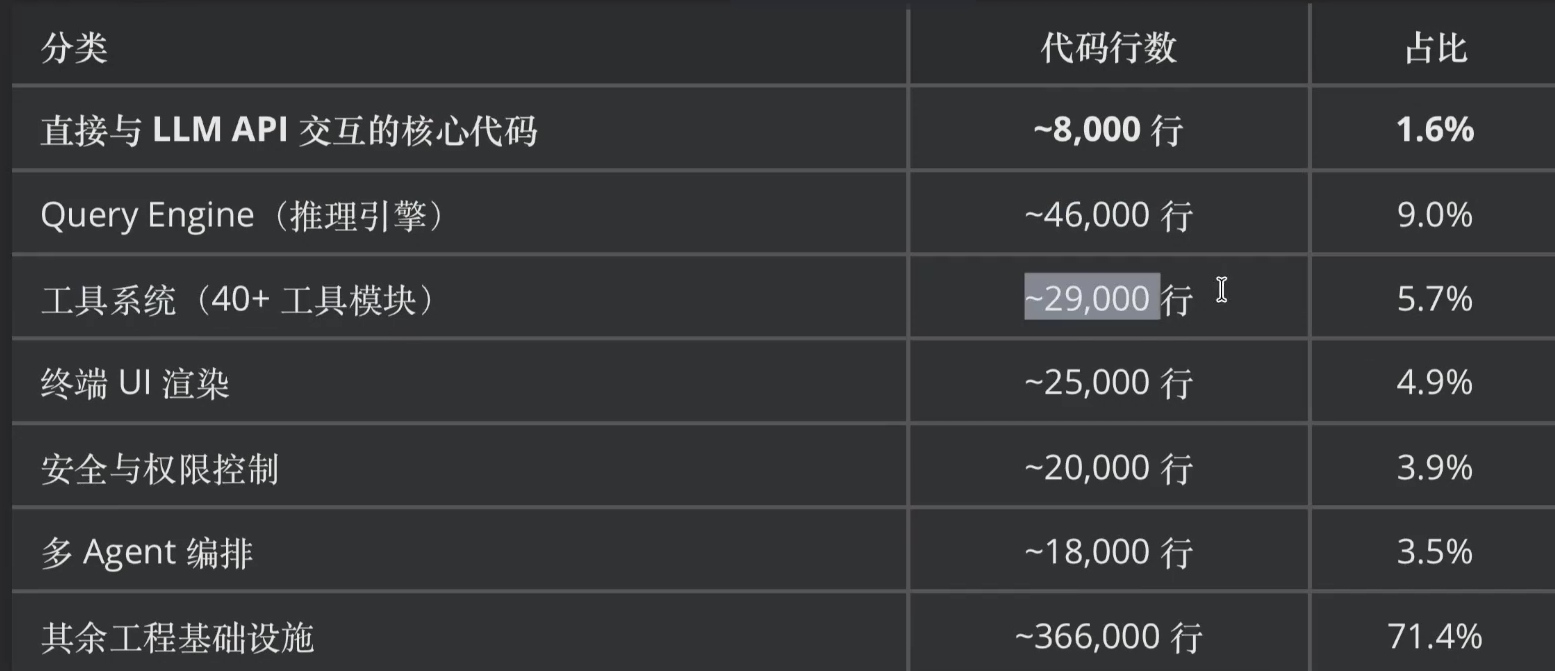
98.4%的代码是Harness一一这个词不是我们发明的。
2025年12 月,Anthropic 发表了 "Building Effective Agents" 系列文档利后续的 Harness Engineering 理论框架,正式定义了AI Agent系统中 "模型之外那部分" 的工程方法论。Claude Code的51.2万行代码,就是这个理论蓝图的工业级实现。
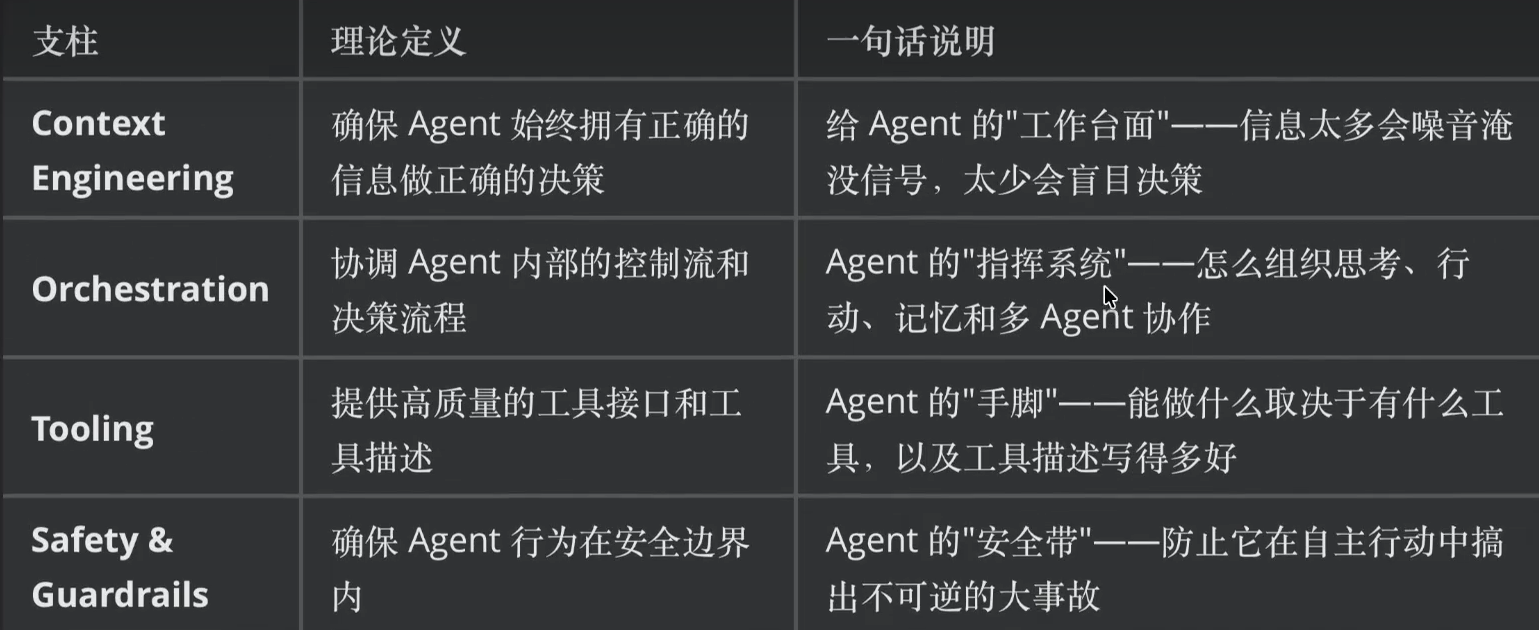
理论四支柱
Harness Engineering 将Agent 系统中围绕模型构建的工程基础设施划分为四大支柱:
可以先看一下claude code的五层架构:

- 约束工作台(上下文管理)一一主要在L3引擎层,QueryEngine的上下文协调器和Compact模块
- 约束记忆(三层记忆+Auto Dream)一一跨L3和L4,Skill加载在L4,记忆索引管理在L3
- 约束行为(安全纵深防御)一一主要在L4工具层,每个工具的执行前后都有安全检查管线
- 约束成本(Prompt Cache经济学)一主要在L3引擎层,Fork模式和缓存编排
L1入口层和L5基础设施层今天不深入一一它们重要,但不是Agent架构差异化的核心。
上下文管理
在聊claude code上下文管理之前,我们需要知道什么是上下文管理。
我们大模型其实有点像金鱼,它没有真正的“记忆”。每次你提问,它都得把自己“重置”一下,然后重新读一遍小抄。这个小抄里装着什么呢?包括系统预设的指令(system prompt)、你俩之前聊过的所有历史、还有你刚问的这个问题。它把这些统统塞进脑子里,然后才生成回答。
问题是,这小抄不能无限长,总有塞不下的时候。这个容纳的极限,就叫“上下文窗口”。窗口大小用 token 来衡量——你可以把 token 想象成文本的“积木块”。
大模型有上下文窗口限制。即使是 200K Token 的窗口,一次复杂的编程任务(读了几十个文件、执行了几十条命令)很容易就塞满了。
那既然上下文管理有窗口限制,加大窗口不就可以解决了吗?其实不然;加大窗口会带来以下三个致命问题:
- 上下文越长,单次推理的 token 消耗就越大,金钱开销越大
- 上下文越长,模型生成第一个 token 的延迟就越高
-
第三个硬伤最致命,叫 Lost in the Middle(中间迷失)。这是个挺有名的现象:
当上下文非常长时,大模型对开头和结尾的信息记得比较清楚,但对中间那一大段,记忆就很模糊了。
你以为你把历史全塞进窗口里,它就能全看到?不一定。中间那一大段,模型可能只是“瞟一眼”就过去了。这是注意力机制的固有特性,跟窗口开多大没关系。
面对上述问题,业界常见的上下文管理做法无非也就那几类;现在来介绍一下业界常见的上下文管理方案
- 滑动窗口。 这是最简单的做法,设个阈值,超过就从最老的消息开始砍,只保留最新的。问题在于 agent 的关键信息往往在最开始——比如用户开局说「禁止做 B」,你砍掉了,后面 agent 就开始疯狂干 B。而且工具调用有依赖,砍掉前面的
tool_result,后面引用它的地方就成了无头苍蝇,模型一脸懵。 - 每 N 轮做摘要。 每过 10 轮或 50k token 就触发一次摘要,把小模型总结的一段话替换掉原始对话。这比滑动窗口好,至少信息没全丢,但问题也不少:触发时机太死板,10 轮可能是关键节点,一刀切下去细节就丢了;摘要粒度也粗,细微的状态变化、错误修复过程、中途改的需求,全压成几句话就没了。本质是一种机械主义方案,按节奏粗暴破坏对话连贯性。
-
向量召回历史。 把历史消息切片存向量库,每次用新问题召回 top-k 相关片段。这招在 RAG 里很好用,但放到 agent 场景直接翻车:向量召回不管时序,可能把 B 召回来、A 丢了,执行顺序全乱;所以它相比于agent上下文,更适合rag检索文档。
那 Claude Code 怎么干?
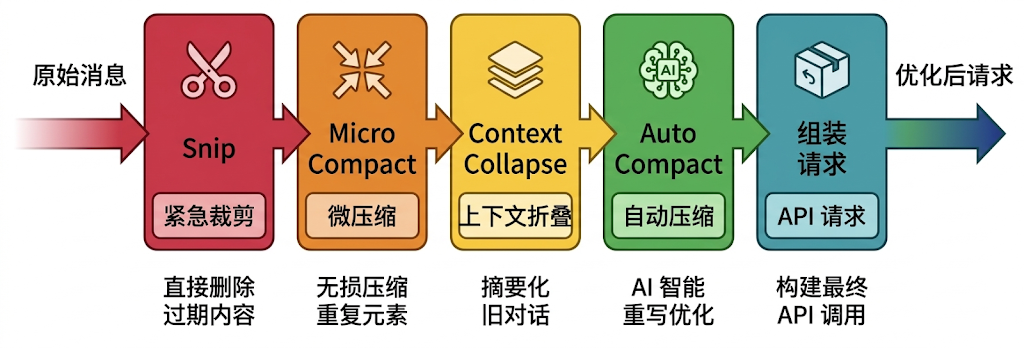
-
Snip 是最「粗暴」但也最高效的一层,直接把对话开头的一批老消息移除掉,然后插入一个边界标记告诉模型「这之前的内容已经被清理了」。它不做任何摘要,不总结「前面聊了什么」,直接砍掉。听起来很暴力,但对于那些确实已经完全过时的消息来说,这是代价最低的做法,因为它不需要额外调用大模型来生成摘要,零 API 开销。
-
Micro-Compact:经过前面的截断,上下文里剩下的都是「不太老但也不太新」的消息。这些消息不能直接砍掉(可能还有用),但里面大量的工具输出其实已经过时了,于是采用的核心思想是时间衰减:越老的工具结果越不重要,可以被裁剪。但是,不是所有工具的结果都能裁剪。可以被裁剪的,都是「可重新获取」的工具,Read 的结果可以再读一次,Bash 的输出可以再执行一次,搜索结果可以再搜一次。但 AgentTool(子 Agent 的输出)、TaskTool(任务状态)这类工具的结果永远不会被裁剪,因为子 Agent 的推理过程是不可重复的,砍掉就真的丢了。
-
Context Collapse: 前面都是「写时压缩」,直接修改消息列表,把内容替换掉或删掉。但 Context Collapse 不修改原始消息,它只在调用 API 的那一刻,动态计算一个「压缩视图」给模型看。90% 上下文窗口时主动开始分段压缩旧消息。这个设计最精妙的地方是它和第4层的配合:Context Collapse 运行在 Auto-Compact 之前。如果 Context Collapse 已经通过「读时投影」把上下文压到了阈值以下,Auto-Compact 就完全不需要触发了。这样模型保留了更多的细节上下文,而不是被一段粗糙的全量摘要替代。
-
Auto-Compact:最重的兜底。此时先会生成摘要,然后替换掉旧的消息,接着是整个流程中最关键的一步,压缩完不是就完了,还要主动恢复最重要的上下文:系统会从文件状态缓存中找出最近访问过的文件,按最后访问时间排序,挑选最多 5 个、总共不超过 50K Token 的文件内容重新注入。同时恢复活跃的 Skill,如果有进行中的 Plan 也会恢复 Plan 文件。
接下来,我们聚焦最顶上的第 5 层 Auto-Compact,因为它是面试官最爱拷打的、设计最精妙的、也是最有面试加分价值的。
首先就是,auto compact到底在干啥?核心就三点:
- 别数轮次,看缓存余量。 很多人喜欢按对话轮数或者时间间隔来触发压缩,这其实不科学。正确姿势是盯着 token 计数器,等上下文窗口只剩下最后一点缓冲空间了(比如 10k token),再动手。这样既不会过早压缩浪费计算,也不会在关键时刻突然断档——说白了,压力到位了再干预。
- 推倒重写,而不是删旧留新。 绝大多数人会本能地选择“砍掉最早的消息”,但更聪明的方式是:把整段对话从头到尾塞进一个压缩模型,让它重新写一份精简版的完整记录。原始的三万行变成五百行,但关键节点一个不丢。这招反直觉的地方在于——你不是在丢弃信息,而是在改写信息。
- 关键信息走专线,别混进压缩池。 像文件内容、CLAUDE.md 这种长期记忆,以及那些还在后台跑着的异步子任务(比如主 agent 派了两个小弟,一个查文档一个跑测试),这些东西太重要了,不能靠摘要算法“随缘保留”。单独开一条恢复通道,每次压缩完后重新注入回去。这样就算对话被压成干,核心状态也还在。
知道了cc压缩到底在压缩什么之后,我们需要知道第二点:什么时候触发压缩?
对于claude code,它的工程化思路是:距离上限的固定缓冲触发压缩。它的触发线是这么算的:拿到模型的有效上下文窗口(比如某个模型是 200k),减去一个固定值 13k,得到的就是触发阈值。token 数一旦超过这条线,就开始压。
那对于autocompact来讲,我们还有一个/compact命令也可以来压缩上下文;那这两个有什么区别吗?如果了解过cc的源码,你会发现,这里面其实藏着两套“入口”,但底层并不是两套系统。
一种是 Claude Code 在上下文快超限时自动触发的压缩;另一种,则是用户可以主动执行的 /compact 命令。表面上看,一个是系统行为,一个是手动操作,但继续往下挖会发现:两者最终调用的是同一个压缩核心,只是喂进去的参数不同。
/compact 属于手动模式,它允许额外传入一段 customInstructions。这个参数可以理解成“摘要偏好”——你可以提前告诉压缩器,这次保留哪些上下文最重要。比如正在排查某个 bug,就能明确要求它重点保留与该问题相关的调用链、日志或者推理过程。而自动压缩就完全是另一种思路了。它不会接收用户额外指令,但会默认开启一个内部选项:suppressFollowUpQuestions。
这个开关名字有点长,不过作用很直接:禁止摘要过程中生成“后续待确认问题”。原因也不难理解——自动压缩通常发生在 Agent 已经进入连续工作状态的时候,如果压缩完突然冒出一句“请确认一下 XXX”,整个执行流就会被打断。
所以本质上,两种模式的区别并不在“怎么压缩”,而在“压缩时优先考虑什么”。手动模式强调“按用户意图保留重点”,自动模式则更关注“不中断任务流程”。
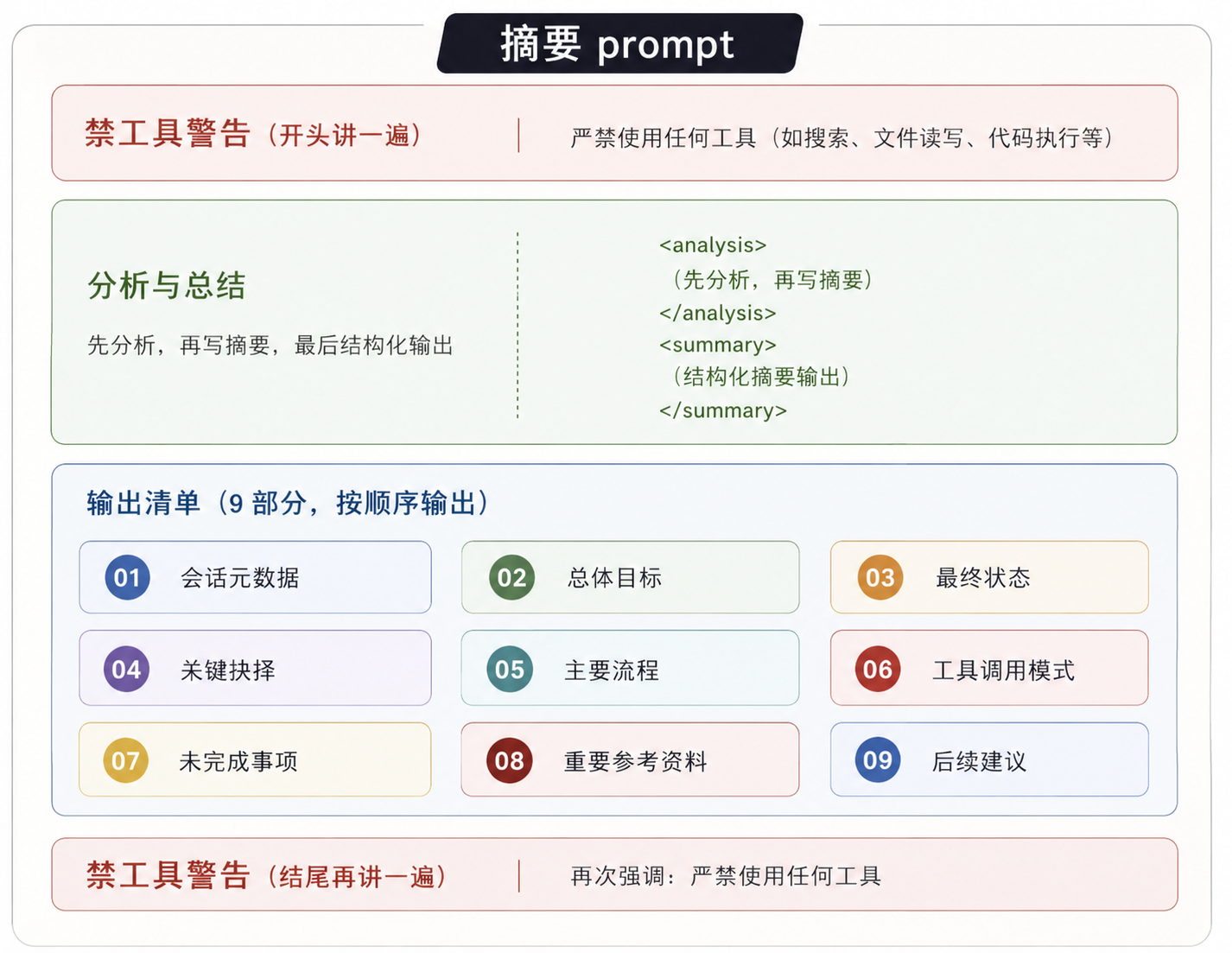
接下来就是第三点:claude code压缩的摘要prompt长什么样呢?
-
Primary Request and Intent(主要请求和意图)
-
Key Technical Concepts(关键技术概念)
-
Files and Code Sections(涉及的文件和代码段)
-
Errors and fixes(碰到的错误和修复方式)
-
Problem Solving(解决的问题)
-
All user messages(所有用户消息)
-
Pending Tasks(待办任务)
-
Current Work(当前正在做的事)
-
Optional Next Step(下一步建议)
第 6 项其实非常关键,它要求的不是“总结用户说了什么”,而是完整保留所有用户输入。很多人第一反应会觉得,这不就是把聊天记录再抄一遍吗?其实不是。这里真正强调的是:所有非 tool result 的用户消息,都必须进入摘要。
原因很简单。Agent 的任务方向并不是固定不变的,而是在长对话里不断被用户修正。用户可能在几十轮之后新增限制条件,也可能突然推翻之前的方案,甚至直接改变目标。如果摘要遗漏了其中某一句,后续 Agent 就可能沿着错误方向继续执行。
所以这一项本质上是在保证“任务演化历史”不丢失。它宁可让摘要变长,也要确保用户意图链条是完整的。因为对于 Agent 来说,遗漏一句用户输入,可能就意味着整个任务上下文发生偏移。
第 8 项则解决的是另一个问题:压缩之后,Agent 如何无缝继续工作。
这里要求摘要必须用“最细粒度”描述当前进度。不是简单一句“正在调试登录问题”,而是要精确到:
正在排查 token 刷新逻辑;已经定位到 cookie 过期判断异常;下一步准备修改
auth.ts中的refreshToken()。
为什么要这么细?因为压缩完成后,Agent 接下来首先面对的问题其实是:
“我刚刚做到哪里了?”
如果当前状态描述太粗,Agent 很容易进入一种“知道自己在干什么,但不知道具体做到哪一步”的状态,然后重新扫描上下文、重新验证推理、重新排查问题。最终结果就是重复消耗 token 和时间。
所以这 9 个摘要项的设计,并不是单纯为了“信息完整”,而是在尽可能保留 Agent 的工作记忆:
- 用户意图不能丢;
- 技术决策不能丢;
- 已踩过的坑不能丢;
- 文件修改状态不能丢;
- 当前执行位置更不能丢。
Claude 的摘要机制,本质上并不是在“缩短聊天记录”,而是在尽量压缩 token 的同时,维持 Agent 的连续工作状态。
那么如果压缩失败,cc会一直压缩吗?我先讲明答案:claude code专门设置了一套机制,不会一直尝试压缩,具体的内容在下述的安全检查会介绍。
安全检查
Agent 安全的本质是什么? 当我们给一个 AI 系统"执行 Bash 命令"的能力时,我们实际上把系统级权限交给了它——删文件、改配置、发网络请求、安装软件、甚至横向移动到其他机器。这不是"能不能跑通"的问题,而是风险管理的问题。
s01 用 5 个字符串做安全检查,任何一个有经验的开发者看到都会说"这不够"。但"不够"之后该怎么做?直觉是"加更多规则"——但加多少规则才算够?规则之间会不会冲突?规则覆盖不到的地方怎么办?那么claude内部有五层相关设计:

安全系统还有一个容易被忽视的设计——断路器(Circuit Breaker)。当出现 3 次连续拒绝或 20 次累计拒绝时,系统自动降级,不再继续尝试。这个设计借鉴了微服务架构中的断路器模式:与其让一个不断被拒绝的 Agent 反复撞墙(每次拒绝都消耗一次 API 调用),不如果断停下来。这是安全性和成本控制的双重务实——既防止了 Agent 的"执念式重试",也避免了无意义的 token 消耗。
Claude Code 的安全架构中有一个出人意料的维度——它不只防用户的误操作,还防竞品的数据窃取。泄露的源码揭示了一种叫"假工具注入"的反蒸馏机制:Claude Code 会在 API 请求中夹带一些并不存在的虚假工具定义。如果竞品公司通过 API 请求来逆向工程 Claude Code 的行为——比如训练自己的模型来模仿 Claude Code 的工具调用模式——这些假工具就会成为训练数据中的"毒丸",导致竞品模型产生错误的工具调用行为。
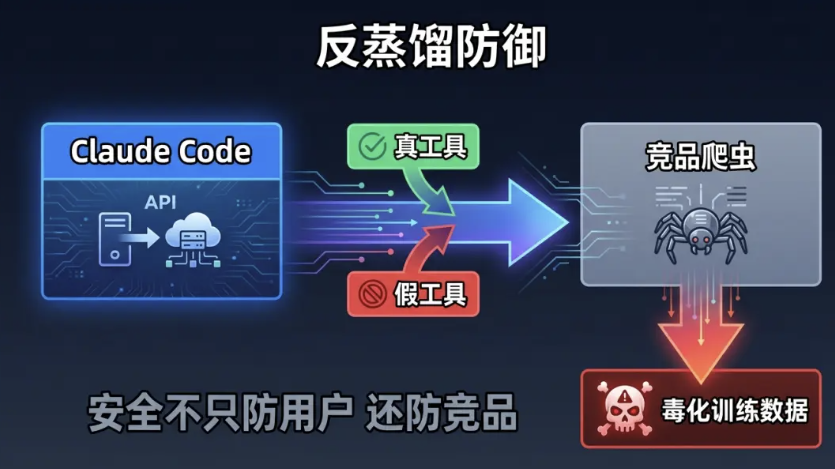
还有一个策略是双AI对抗, 用一个 AI 监督另一个 AI,两者上下文完全隔离。安全分类器是最直接的双 AI 对抗案例——一个 Claude(任务模型)负责干活,另一个 Claude Sonnet(分类器)负责判断干活的那个是否越界。两者的上下文完全隔离——分类器看不到任务模型的推理过程,任务模型也无法影响分类器的判断。
这个模式之所以有效,是因为它解决了 AI 系统中的一个根本性问题:如何信任一个不完全可靠的系统? 答案不是"让它变得完全可靠"(做不到),而是"用另一个独立系统来检查它"。两个系统同时犯同一个错误的概率,远低于单个系统犯错的概率。
对抗知识熵增
回到第四个致命问题。我们看到 s01 的 agent_loop 每轮 API 调用都把完整的 messages历史发送一遍——第 N 轮要发送前面所有 N-1 轮的内容。
这已经够贵了。但真正让成本爆炸的场景是多Agent 并行。多Agent 并行的成本挑战是什么
当一个任务足够复杂——比如"重构一个前后端分离的项目"——你可能想让一个Agent 改前端,另一个改后端,第三个写测试。每个子Agent都有自己的独立消息历史( messages=[] ),每个都在各自的上下文窗又里累积 token。三个 Agent 各跑 20 轮,成本就是单Agent 的三倍。
那么我们先看s04的实现:
# -- Parent tools: base tools + task dispatcher --
PARENT_TOOLS = CHILD_TOOLS + [
{"name": "task", "description": "Spawn a subagent with fresh context. It shares the filesystem but not conversation history.",
"input_schema": {"type": "object", "properties": {"prompt": {"type": "string"}, "description": {"type": "string", "description": "Short description of the task"}}, "required": ["prompt"]}},
]父Agent通过一个叫 task 的工具来启动子Agent。
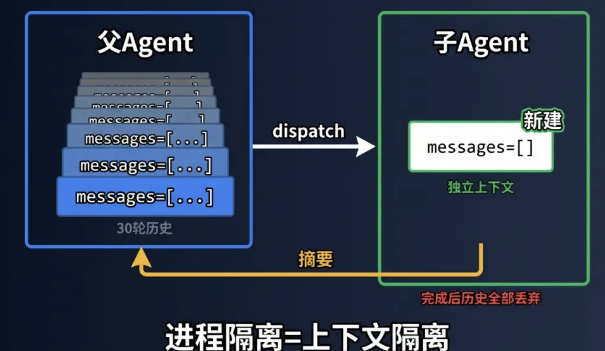
注意工具描述中的那句话:"It shares the filesystem but not conversation history"——共享文件系统,不共享对话历史。这一行代码注释精准地定义了子 Agent 的隔离边界:文件系统层面互通(子 Agent 可以读写父 Agent 创建的文件),上下文层面完全隔离。
父Agent调用task工具后,子 Agent在自己的上下文中独立工作——可能调用了多次 bash、read_file 等工具。完成后只返回一段精简的文本摘要,父 Agent 收到摘要继续工作。
s04 的子Agent创建方式是sub_messages = [] ——一个全新的空上下文。Claude Code 的做法完全不同:子Agent字节级继承父Agent的完整上下文。
"字节级继承"是什么意思?当Claude Code通过AgentTool启动一个子Agent时,它不是创建一个空白的新会话,而是复制一份父Agent当前的完整消息历史——包括系统提示词、工具定义、项目上下文、之前的对话记录。子Agent从父Agent停下的地方继续,就像Unix的fork() 系统调用一样。
这意味着子Agent天然拥有父Agent积累的所有上下文信息,不需要重新"介绍"项目背景、编码规范、当前任务状态。
Fork 的字节级继承不只是功能上的便利,它还带来了一个巨大的成本红利——Prompt Cache 复用。
Anthropic API 的 Prompt Cache 机制是这样工作的:当两个 API 请求的前缀部分(系统提示词 + 工具定义 + 前面的消息历史)字节级完全相同时,第二个请求的前缀不需要重新处理,直接从缓存读取——输入 token 的计费降低到标准价格的 10%。
Claude Code 的系统提示词被精心分割为两个区域:
- 稳定区(前半部分):基础行为指令、工具定义、全局规则——这些在同一个会话中不会变化,可以被所有子Agent共享缓存
- 动态区(后半部分):会话特定上下文、环境状态、用户指令——这些在每次调用时可能不同
Fork 的子 Agent 继承了父Agent的完整上下文,意味着它们的请求前缀天然与父Agent相同——自动命中Prompt Cache。

三.总结
Agent 的核心骨架(如 s01_agent_loop.py 所示)极其简单,可以概括为一个公式: Agent = while 循环 + 工具调用 + stop_reason 状态检查,虽然这 30 行代码能完成任务,但存在四个“致命伤”:
-
上下文膨胀: 历史记录只增不减,导致模型注意力稀释,质量下降。
-
记忆缺失: 会话结束即失忆,无法跨任务或跨时间延续。
-
安全裸奔: 仅靠简单的字符串黑名单(如
rm -rf)拦截风险,极易被绕过。 -
成本爆炸: 每一轮都发送全量历史,Token 消耗呈线性甚至指数级增长
为了解决上述问题,Claude Code 引入了 Harness Engineering(装甲工程) 体系,将 98.4% 的代码用于约束和优化模型行为,主要分为四大支柱,那么我们主要来看以下几点:
A. 约束工作台(上下文管理)
通过四层压缩防御机制,确保上下文窗口始终高效
B. 约束行为(五层安全纵深)
安全不再是简单的黑名单,而是一套防御体系:
-
双 AI 对抗: 使用独立的分类器模型(如 Sonnet)监控任务模型的行为。
-
断路器模式: 连续失败或拒绝后自动停机,防止 Agent 陷入“无效重试”浪费 Token。
-
假工具注入: 针对竞品窃取数据的“毒丸”防御。
C. 约束成本(Fork 模式与缓存经济学)
Claude Code 通过模仿 Unix 的 fork() 机制,解决了多 Agent 协同的成本问题:
-
字节级继承: 子 Agent 直接复制父 Agent 的上下文,无需重复发送背景信息。
-
Prompt Cache 复用: 利用 Anthropic API 的缓存机制,使重复前缀的费用降低 90%。
-
任务编排: 通过父子 Agent 模式,将复杂任务拆解,完成后仅回传摘要,保持父上下文清爽

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)