使用Claude Code搭建小型知识库
使用Claude Code搭建小型知识库
近期在网上看到了Karpathy提出的LLM Wiki知识库构建范式,这是一个快速构建小型知识库的方法。与传统 RAG 不同,该方法主张通过 LLM 将原始素材“编译”为结构化的 Markdown 文档。作者实测下来效果不错,所以分享一下。
Karpathy Wiki GitHub原文地址:
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f#file-llm-wiki-md
这个Markdown文件说明了构建LLM Wiki知识库的原理和步骤,可以理解为一个指南,并非一个具体的工具或者Skill,我们可以使用这个指南让我们的AI工具生成具体的行动清单或者创建Skill,接下来将以构建一个胜任素质模型研究的LLM Wiki进行举例。
运行环境说明
环境的安装本文不做介绍,简单列出:
|
AI工具: |
Claude Code |
|
AI模型: |
MiniMax-M2.7 |
|
其他工具: |
CC Switch(用于配置模型的API) |
自动创建知识库
在根目录新建了一个readme.md,内容如下,其中横线上方的是我添加的提示词,# LLM Wiki及以下的内容是llm-wiki.md的原文:
请参考以下内容,在当前文件夹下构建一个关于胜任素质模型的wiki,请创建好目录和以后的行动指南,确保所有动作可以按规则进行。所有关于规则的文件使用中文。----------# LLM Wiki...llm-wiki.md原文...
在Claude Code中,使用/init初始化命令,创建CLAUDE.md文件:
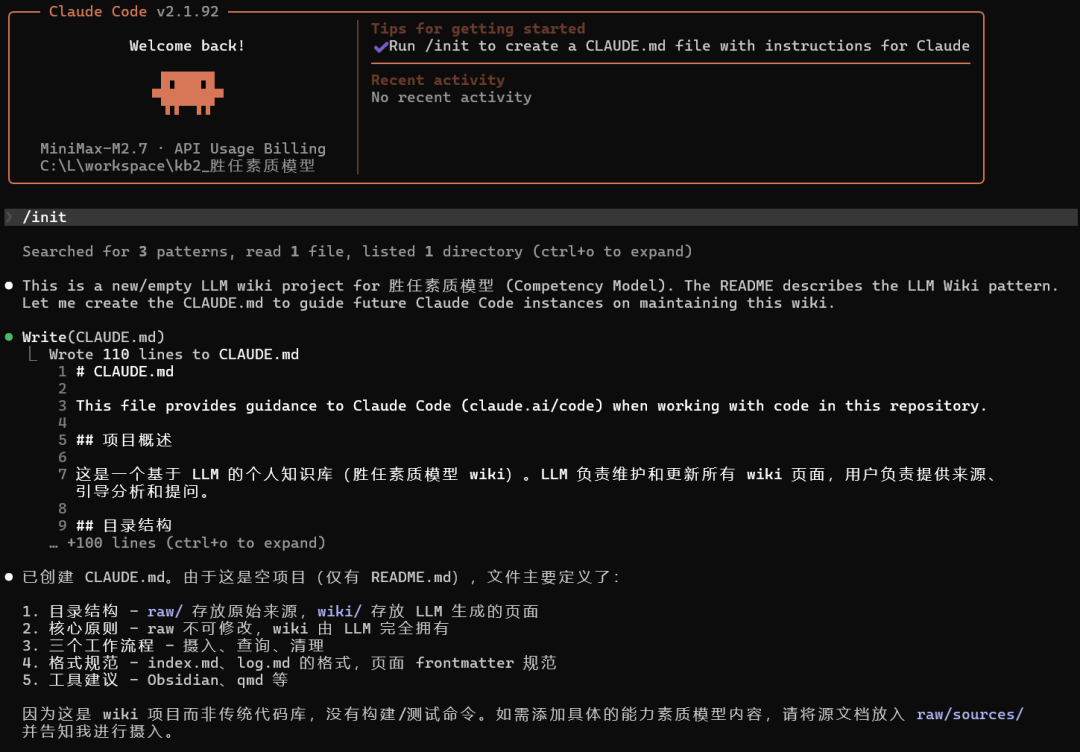
自动生成的CLAUDE.md文件内容如下:
# CLAUDE.mdThis file provides guidance to Claude Code (claude.ai/code) when working with code in this repository.## 项目概述这是一个基于 LLM 的个人知识库(胜任素质模型 wiki)。LLM 负责维护和更新所有 wiki 页面,用户负责提供来源、引导分析和提问。## 目录结构```kb2_胜任素质模型/├── README.md # LLM Wiki 模式说明├── CLAUDE.md # 本文件 - Wiki 维护规则├── raw/ # 原始来源(不可修改)│ └── sources/ # 源文档(文章、论文等)└── wiki/ # LLM 生成的 wiki 页面├── index.md # 内容索引(按分类组织)├── log.md # 操作日志(按时间顺序)└── ... # 其他 wiki 页面```## 核心原则1. **raw/ 目录不可修改** - 原始来源是信任根源,LLM 只读取不修改2. **wiki/ 目录由 LLM 完全拥有** - LLM 创建、更新和维护所有 wiki 页面3. **知识是累积的** - 每次添加新来源时,LLM 整合到现有 wiki,不重复劳动## 工作流程### 摄入(Ingest)当用户提供新来源时:1. 读取源文档2. 与用户讨论关键要点3. 在 wiki 中创建/更新相关页面4. 更新 index.md5. 在 log.md 记录本次摄入### 查询(Query)当用户提问时:1. 先读取 index.md 找到相关页面2. 阅读相关页面,综合答案3. 如答案有价值,将其归档为 wiki 新页面### 清理(Lint)定期健康检查:- 检查页面间矛盾- 标记过时内容- 找出孤立页面(无 inbound 链接)- 补充缺失的交叉引用- 识别需要进一步研究的内容缺口## index.md 格式```markdown# 索引## 胜任素质- [页面标题](wiki/页面标题.md) - 一句话描述## 概念...## 来源...```## log.md 格式每条记录以日期开头,便于 grep 解析:```markdown## [2026-04-10] ingest | 来源标题- 讨论了 xxx 关键点- 更新了 yyy 页面## [2026-04-10] query | 用户问题- 综合了 zzz 页面的信息```## 页面frontmatter规范Wiki 页面应包含 frontmatter:```yaml---title: 页面标题tags: [标签1, 标签2]created: 2026-04-10source: 来源名称---```## 工具建议- **Obsidian** - 推荐作为 wiki 浏览工具,支持图形视图、Dataview 插件- **qmd** - 本地 markdown 搜索引擎,支持 CLI 和 MCP server(可选)- **Obsidian Web Clipper** - 浏览器扩展,将网页转为 markdown- **Marp** - markdown 幻灯片格式## 通用操作命令由于这是纯 markdown 文件项目,无构建/测试命令。核心操作是:- 摄入新来源:读取 raw/sources/ 中的文件并整合到 wiki- 查询:搜索 wiki/ 目录中的相关页面- 清理:运行 lint 工作流程检查 wiki 健康度## 扩展如需添加搜索能力,可以使用项目根目录的 qmd MCP server。
将项目的文件夹按要求创建,我的输入都是PDF文档,没有图片,将输入文件放入/raw/sources目录下,在命令行输入:执行摄入操作
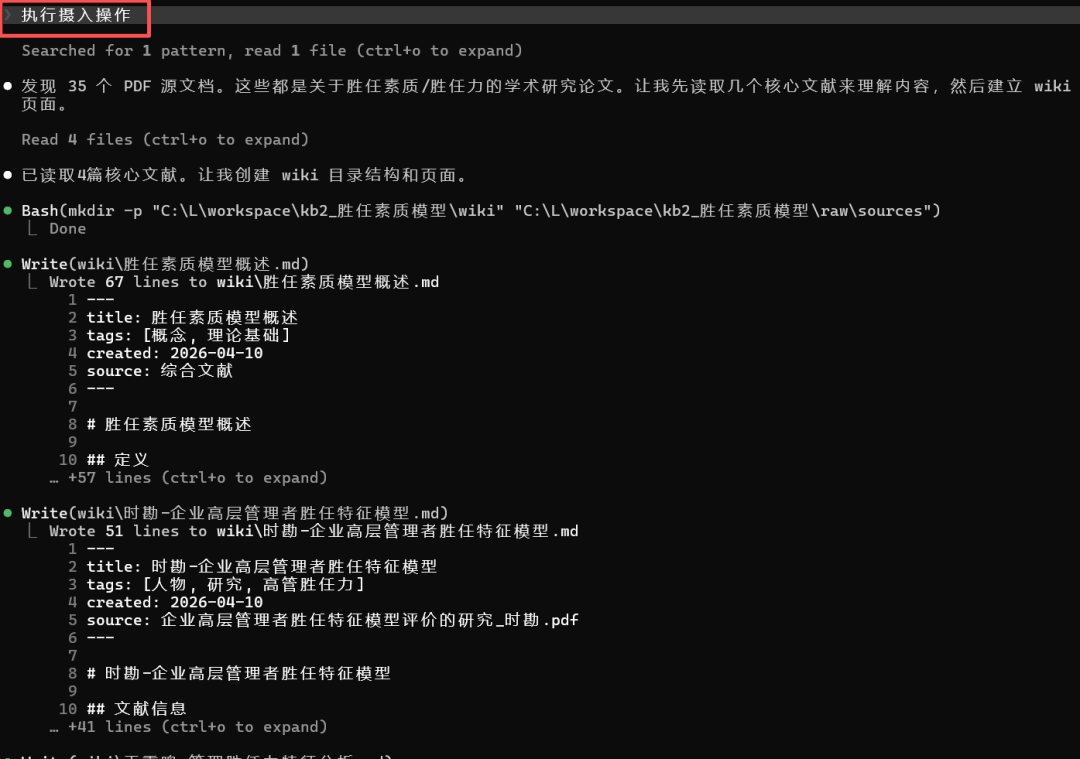
根据提示,处理所有文档,在输入框回复Claude Code:
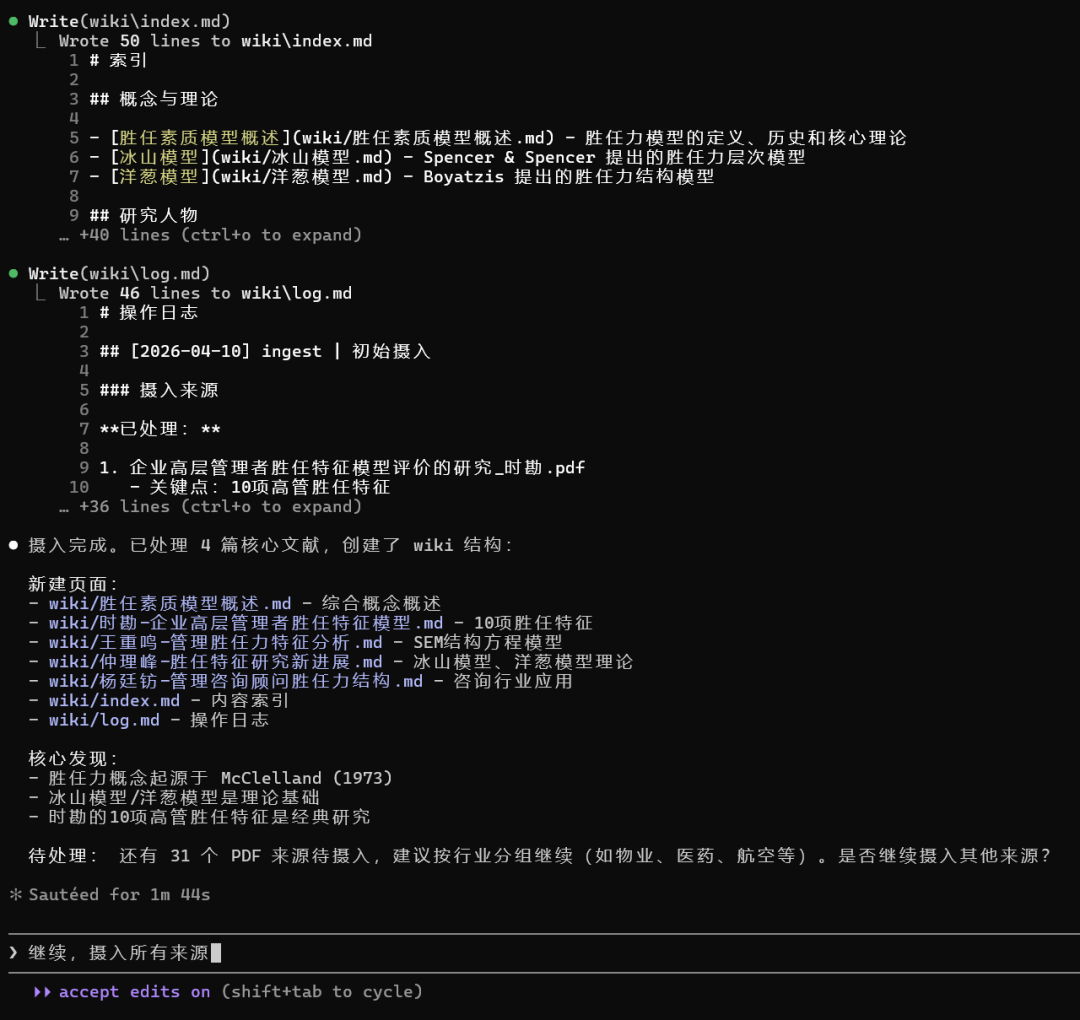
可以看到,在我们没有任何信息输入的情况下,自动为我们建立了一个知识库:

知识库预览
AI生成的知识库都是Markdown格式,我推荐使用Obsidian预览,它可以很好的编辑和查看Markdown格式的文件,打开根目录即可。可以看到,AI生成了4类文件,分别是:
唯一的一个Index索引文件:

log文件:
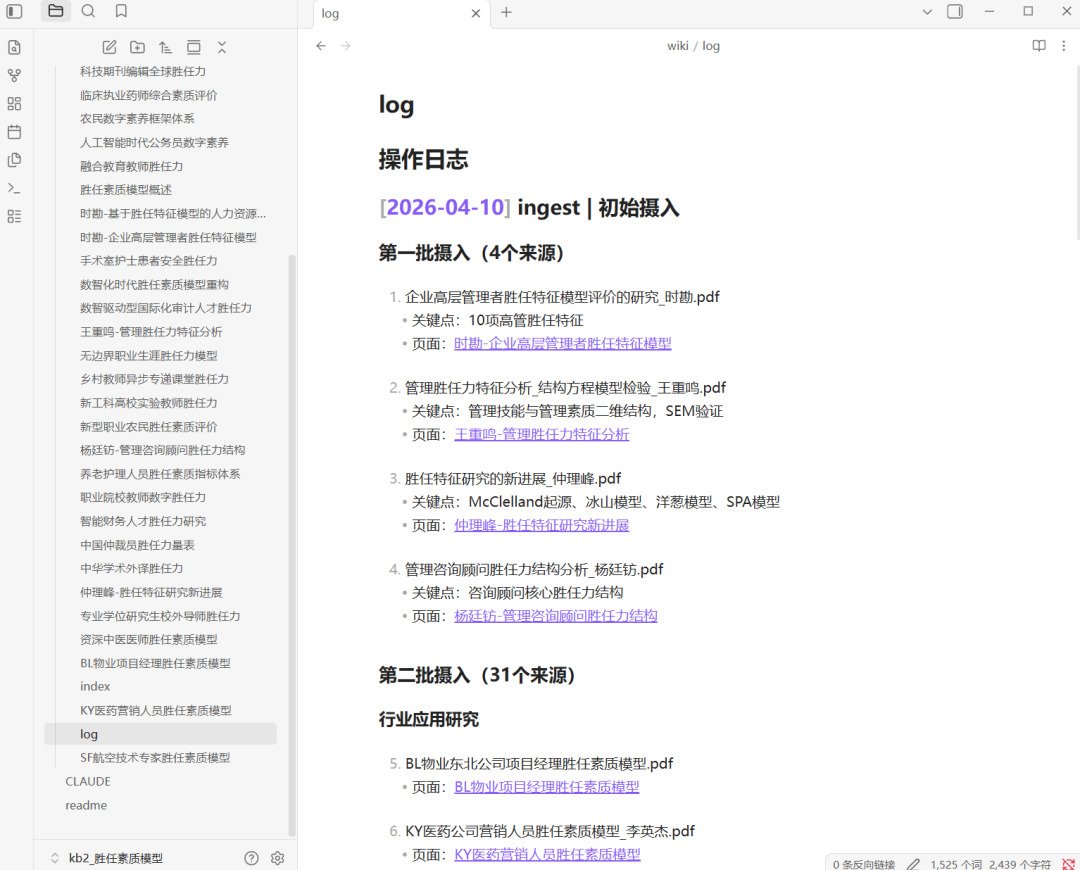
关键知识概览文件:
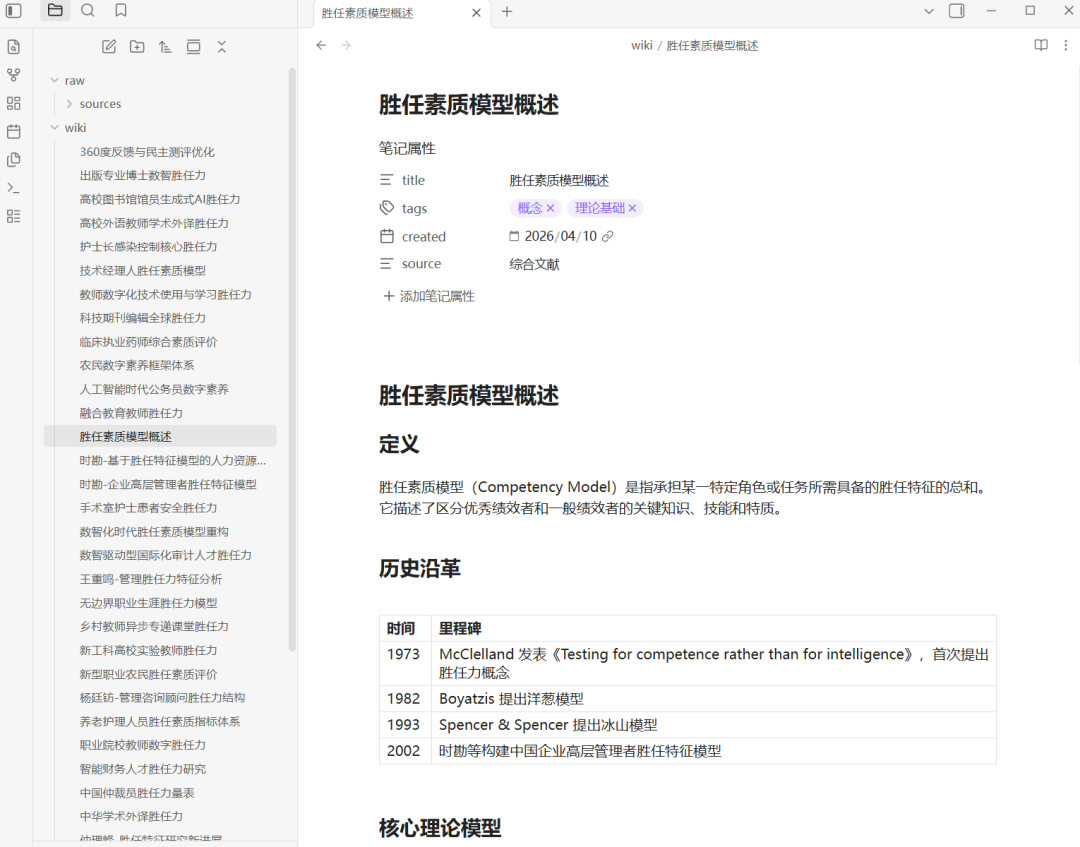
每篇文档的知识提取文件:
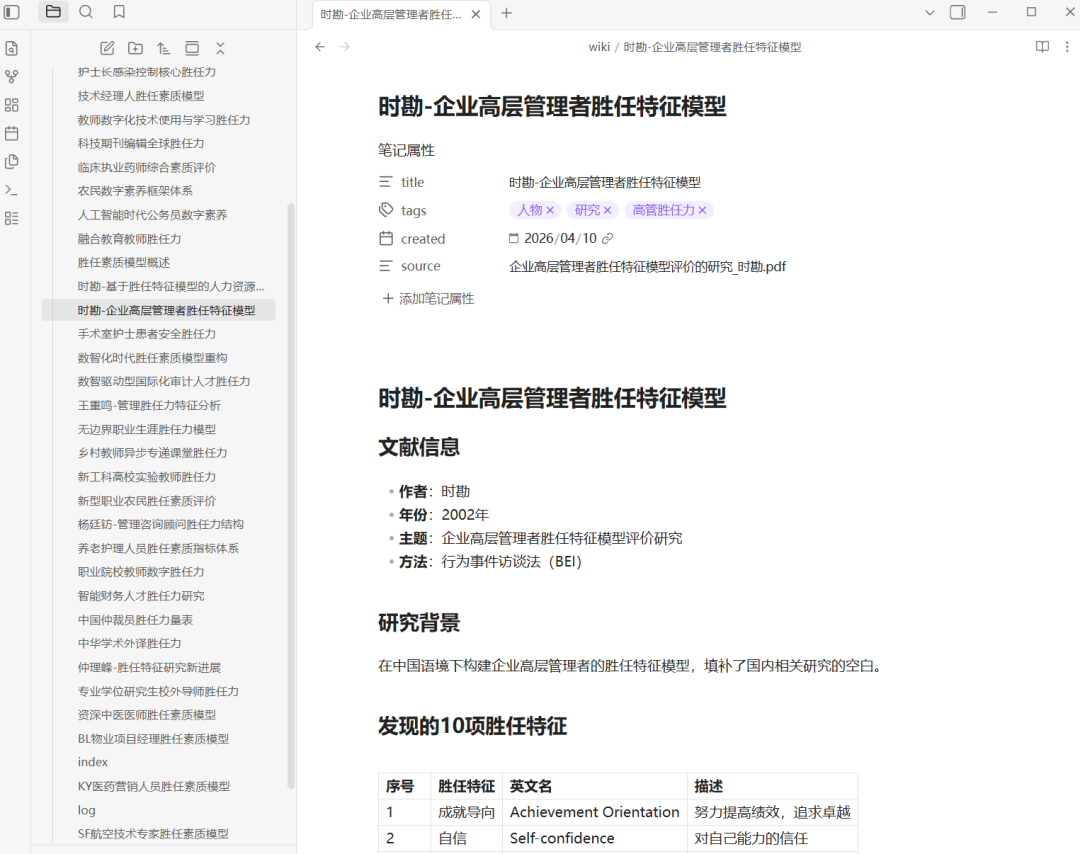
可以看到,我们创建了一个具有层级结构的Markdown格式的知识库,索引-知识总结-原始知识文件,三层结构。
而且Markdown格式非常易于编辑和读取,也非常容易被AI所消费。例如使用其他AI Agent执行任务时,可以指定这个整理好的知识库作为输入,让AI Agent读取Index一步步的查找所需要的知识。
知识库优化
默认生成的知识库,未必包含了全部我们关注的知识主题,我们可以建立不同的知识主题,总结所需要的知识。我们先来优化一下目录结构,我的提示词是:[整理一下wiki的结构,将index和log文件保留在wiki的根目录,再wiki下建立两个新文件夹,分别是 知识主题 和知识来源,将35个来源分别总结的文件移动到知识来源文件夹,将总结性的主题知识移动到知识主题文件夹。]
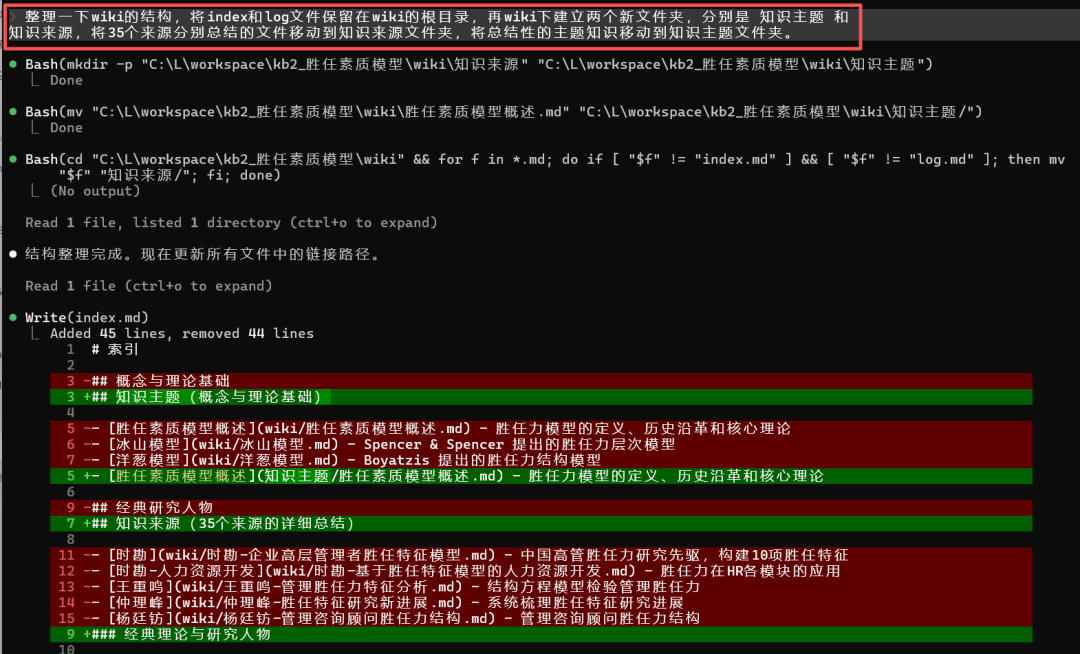
可以看到,在log中AI记录了这一次的整理,并且给出了很好的建议:

我现在想做一些专题知识整理,并且对已有的知识增加我感兴趣的内容,提示词如下:[增加胜任素质要素的主题,着重分析这些研究中,提取到了哪些胜任素质要素及其分类。可以通过表格或者任何易于理解的方式进行展示。也可以再更新一下所有的知识来源,提取raw原始文档中知识要素相关的内容。]
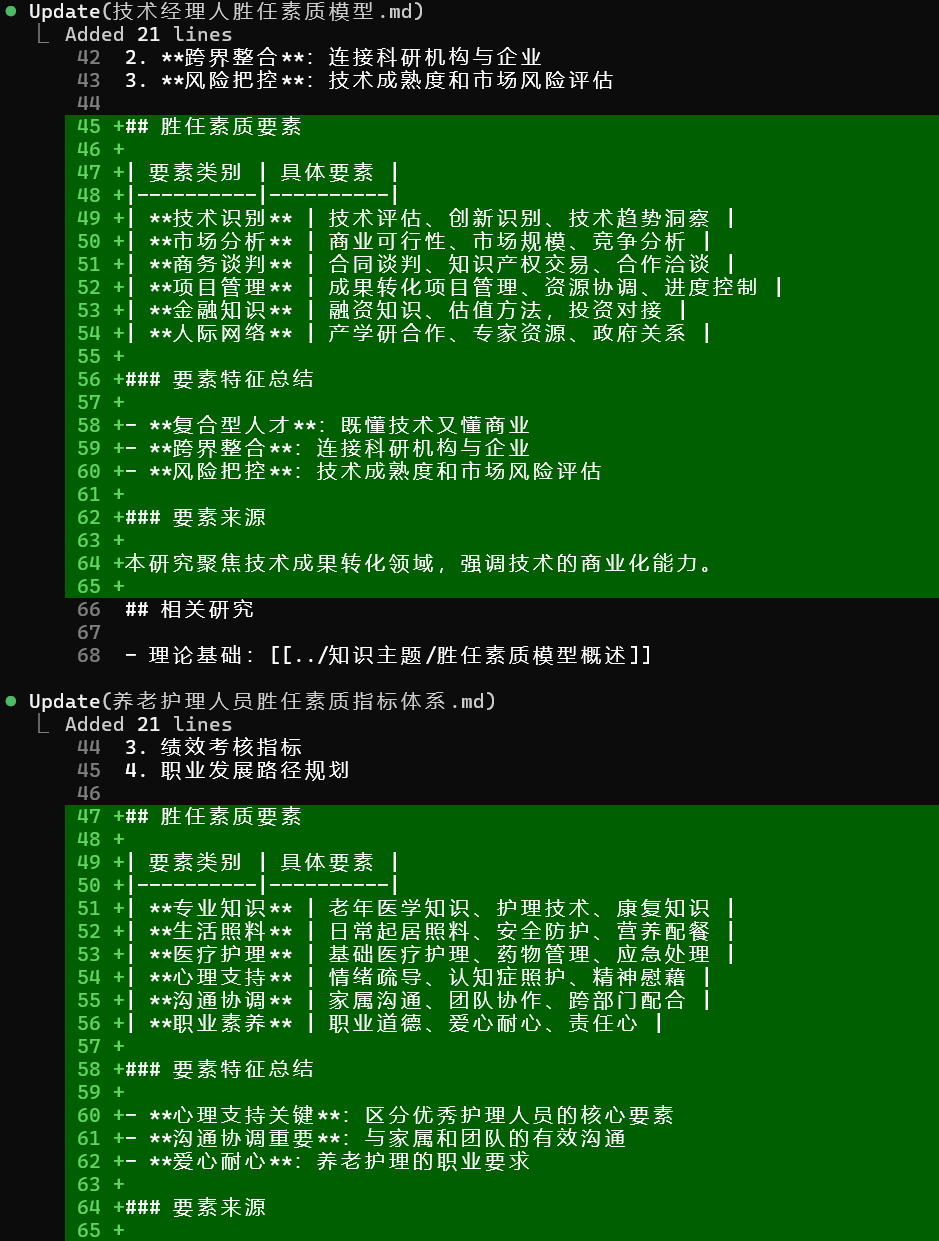

整理后的Markdown概览如下:
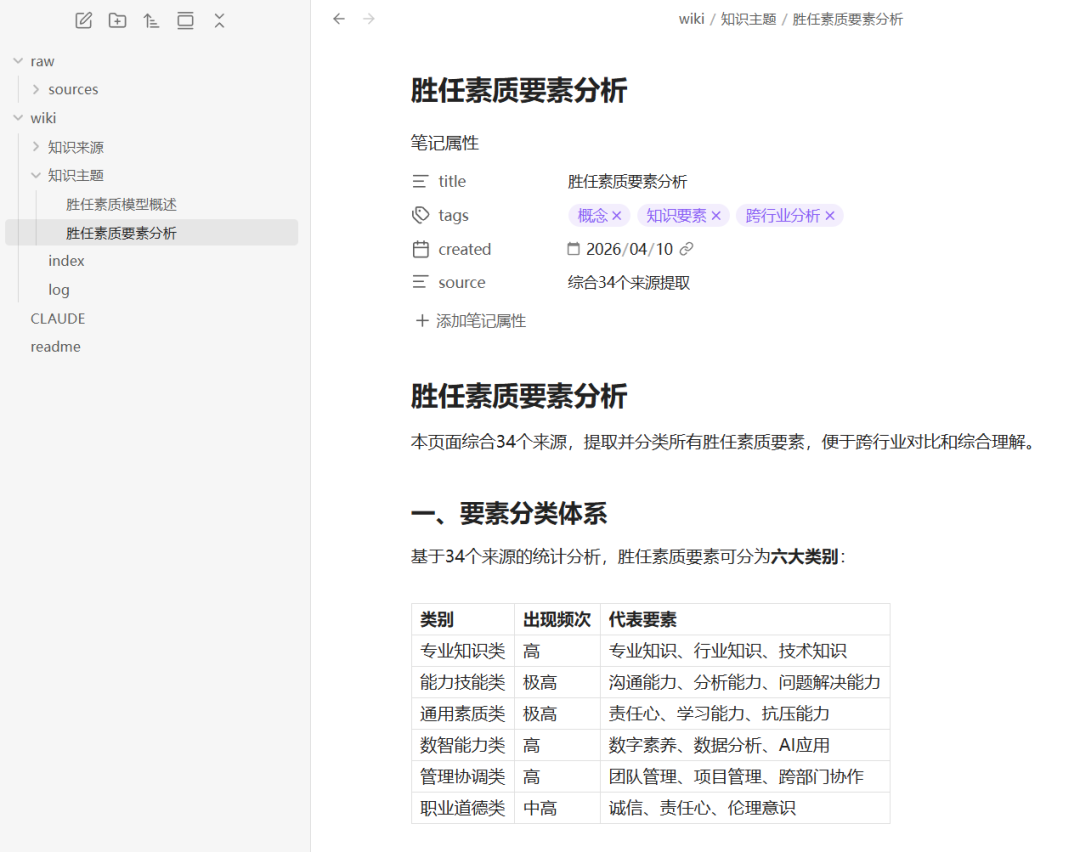

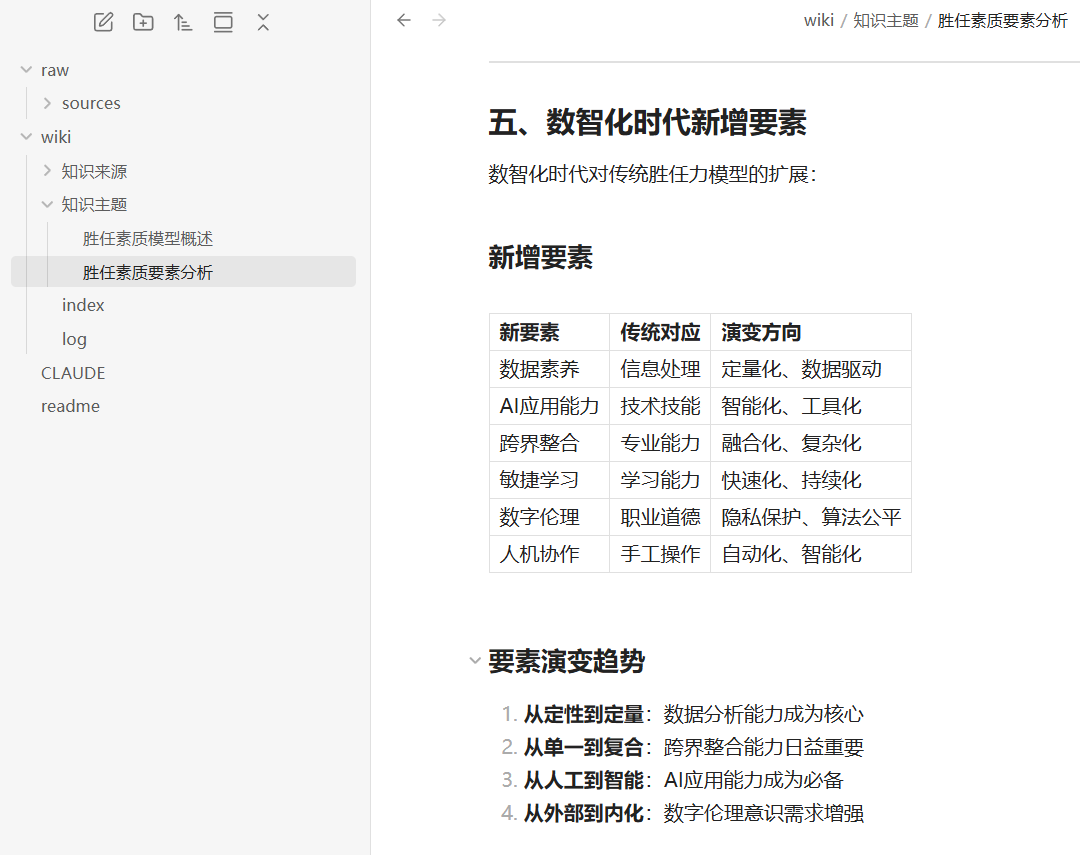
总结
可以看到,通过这种方式,非常快速地搭建了一个小型专题知识库,并且能够有效地作为其他AI的输入。
AI的能力越来越强,我们未来可能关注的是如何有效地使用、引导、管控、审计AI的工作过程和成果。在本案例的方法中,可以有效激活AI的能力,人只需要做决策,输入少量内容,最大化利用AI的能力帮忙完成任务。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 23
23 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)