我用一个工具将Claude代码探索时间和成本降低了 90%
它支持 TypeScript、JavaScript、Python、Go、Rust、Java、C#、PHP、Ruby、C、C++、Swift、Kotlin、Dart、Svelte、Pascal/Delphi 和 Liquid,也就是 Shopify themes 常用的语言。于是,Claude 拿到的不是模糊摘要,而是它真正需要的东西:入口点、相关符号、代码片段、调用者和被调用者关系。Claude
每个 Claude Code 用户,大概都熟悉这种崩溃感。
你打开一个全新的会话,输入一个看起来很简单的问题,然后眼睁睁看着它开始“考古”:
⏺ Explore(“How does the extension host communicate with the main process?”)
⎿ Done (52 tool uses · 89.4k tokens · 1m 37s)每一次,都是这样。
Claude 并不真正记得你的代码库。于是,它只能派出 Explore agents,在项目里用 grep、glob 和 Read 一层层爬文件。每一次工具调用都在烧 token,每一次扫描文件都在吃上下文窗口。
我在自己的一个项目上测过一次:60 次工具调用,157,800 个 token。Claude 花了将近 2 分钟探索代码,才终于开始处理我真正想让它做的事情。
最烦的是,这些昂贵探索换来的知识,一旦你关掉会话,就没了。
下次再开?
从零开始。
再交一次“探索税”。
那些临时补丁
我不是第一个发现这个问题的人。
社区里早就有各种绕路方案。
一种是 memory markdown 文件。很多人会把 CLAUDE.md 塞满代码库摘要、架构说明、文件列表。它确实有一点帮助,但 Claude 仍然不真正理解代码之间的关系。它只是在读一篇说明文档。
另一种是带独立 markdown 文件的 subagents。有人会搭建一套复杂系统,让探索 agent 更新共享记忆文件。这个方法比单纯写 CLAUDE.md 更进一步,但本质上还是有点“土法炼钢”:仍然是文本,仍然缺少真实结构,仍然无法直接表达代码之间的连接方式。
还有一种是手动塞上下文。每次提问前,把相关代码复制到 prompt 里。它能工作,但太麻烦,也根本不适合大项目。
这些办法都没有真正给 Claude 它最需要的东西:
不是一段总结,而是一张代码关系图。
如果 Explore Agent 有地图呢?
这就是 CodeGraph 的核心想法。
不要让 Explore agents 像蒙着眼睛一样到处扫文件,而是让它们查询一张提前构建好的代码图谱。
这张图知道:
哪些函数调用了哪些函数; 哪些类继承自哪些类; 接口在哪里被实现; import 是怎样把文件连接起来的; 当你修改某个符号时,影响范围会扩散到哪里。
这不是一份需要 Claude 自己解读的文字摘要,而是一个结构化数据库。Claude 可以直接向它提问。
Explore agents 仍然会运行。
但它们不再低效地满项目翻文件,而是直接查图。图查询几乎立刻返回结果,也就不需要一份文件一份文件地扫描。
于是,同样的问题会变成这样:
⏺ Explore(“How does the extension host communicate with the main process?”)
⎿ Done (3 tool uses · 56.6k tokens · 17s)关键在于 codegraph_explore。
这是一个工具调用,却能为所有相关符号返回完整的源码片段。以前 Explore agent 可能需要 52 次 grep、glob、Read 调用,现在只需要一次图查询,就能拿到它真正需要的内容。
真实 benchmark 数据
我在完整的 VSCode 代码库上,用同一个 prompt 分别测试了启用和未启用 CodeGraph 的效果。
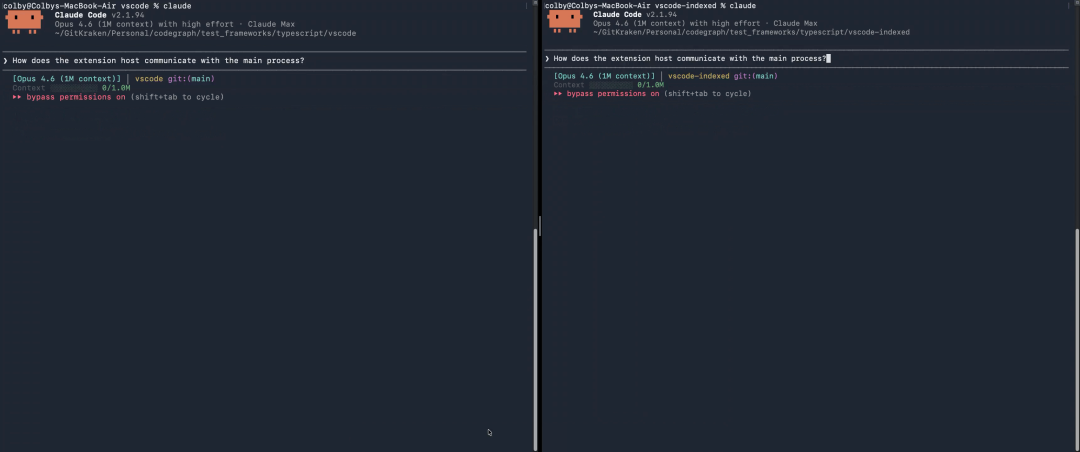
左边是不使用 CodeGraph,右边是使用 CodeGraph。
结果很直接:Explore agents 的工具调用减少了大约 94%,速度提升了大约 82%。原因也不玄学,图查询本来就比文件扫描更高效。
这省下的不只是时间。
它省的是每一次复杂任务里的 token、成本和等待。
五分钟装好
需要的东西很少:
Node.js 18+; Claude Code。
然后只需要运行一个命令:
npx @colbymchenry/codegraph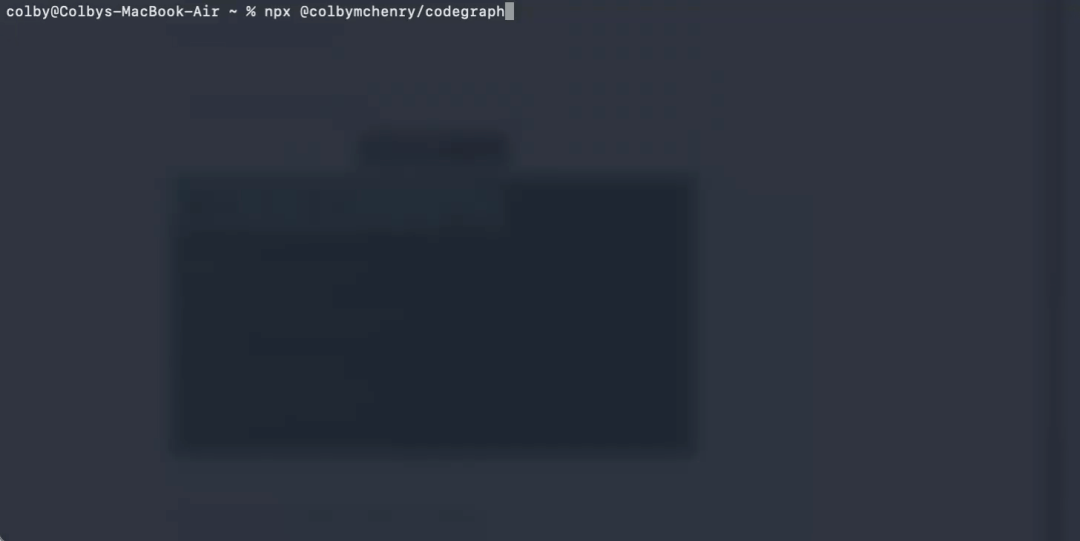
交互式安装器会把事情都处理好:
-
在
~/.claude.json里配置 MCP server; -
为 CodeGraph 工具设置自动允许权限;
-
询问是否初始化当前项目;
-
根据你选择的项目级或全局配置,写入
CLAUDE.md指令。
重启 Claude Code 之后,在任何你想使用的项目里执行初始化:
codegraph init -i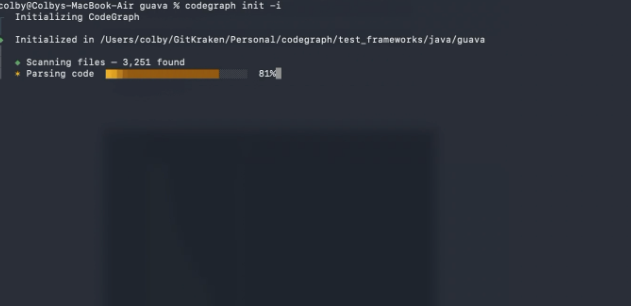
就这样。
以 VSCode 这个体量的代码库为例,3,251 个文件、119,675 个节点、116,424 条边,以及关系边映射,大约 30 秒就能完成索引。
它到底怎么工作?
CodeGraph 会先用 tree-sitter 对你的代码库进行一次索引。
每个函数、类、方法,以及它们之间的关系,都会被写入一个本地 SQLite 数据库。
Claude Code 则通过 MCP 连接它。当 Claude 需要理解你的代码时,它不再从头探索文件,而是直接查询这张图。
于是,Claude 拿到的不是模糊摘要,而是它真正需要的东西:入口点、相关符号、代码片段、调用者和被调用者关系。并且,这些信息通常只需要一次工具调用就能返回。
它还用 FileWatcher 保持新鲜度。MCP 会监听文件变化,并通过冷却机制避免频繁重建;当文件变化后,codegraph 通常会在不到一秒内重新同步相关增量。
这就是它和 markdown 记忆方案最大的区别。
Claude 不是在读一篇“关于代码库的文章”,然后努力猜测结构。
它是在查询一个已经知道代码如何连接的结构化数据库。
你能得到什么?
更聪明的上下文构建
Claude 原生的 Explorer subagents 可以借助 CodeGraph 更快定位文件,更早完成分析,并且用更少 token 找到正确答案。
它不是让 Claude 少思考,而是让 Claude 少走弯路。
影响范围分析
修改之前,先知道哪里可能会坏。
你可以追踪调用者、被调用者,以及某个符号的完整影响半径。对重构、修 bug、改公共接口来说,这一点非常实用。
支持 19+ 种语言
它支持 TypeScript、JavaScript、Python、Go、Rust、Java、C#、PHP、Ruby、C、C++、Swift、Kotlin、Dart、Svelte、Pascal/Delphi 和 Liquid,也就是 Shopify themes 常用的语言。
不同语言,使用同一套 API。
100% 本地运行
没有数据离开你的机器。
不需要 API key,也不依赖外部服务。它只是在你的项目里维护一个 SQLite 数据库。
对代码隐私敏感的团队来说,这一点很关键。
始终保持最新
MCP server 会使用原生系统文件事件监听项目变化,比如 macOS 的 FSEvents、Linux 的 inotify,以及 Windows 的 ReadDirectoryChangesW。
变化会被 debounce,然后增量同步。也就是说,随着你写代码,代码图也会跟着更新,而且几乎不需要额外配置。
受影响测试检测
它还能帮你只跑真正相关的测试。
codegraph affected 会追踪 import 依赖,找出你的改动影响了哪些测试文件。配合 git diff 使用,可以很快接入 CI。
这不是炫技,而是很现实的节省。
技术细节
CodeGraph 使用 tree-sitter 把源码解析成 AST,然后抽取两类核心信息。
第一类是节点:
函数; 类; 方法; 接口; 类型; 变量。
第二类是边:
调用; 导入; 继承; 实现; 类型引用。
这些信息会存进本地 SQLite 数据库,并支持:
基于 FTS5 的全文搜索; 用于影响分析的图遍历。
MCP server 会暴露一组 Claude 可以直接调用的工具:
codegraph_context,为任意任务构建完整上下文;codegraph_search,按名称快速搜索符号,只返回位置,不返回代码;codegraph_callers 和 codegraph_callees,追踪调用关系;codegraph_impact,计算代码修改的爆炸半径。
真正难的地方,在于引用解析:跨文件匹配调用和定义,解析 imports,连接继承关系,理解框架模式。
这些事情如果让 Claude 每次靠 grep 重新摸索,当然又慢又贵。
但如果提前整理成图,Claude 就能直接查答案。
最后
Claude Code 的成本高,很多时候不是因为它真的在写很多代码,而是因为它每次都要重新“认识”你的项目。
它没有地图,就只能走迷宫。
CodeGraph 的价值,就在于先替它把地图画好。
以前,一次复杂请求可能要几十次工具调用,十几万 token,等一两分钟才进入正题。现在,它可以通过一次结构化查询快速找到入口、关系和影响范围。
这不是简单的缓存,也不是往 CLAUDE.md 里多写几段说明。
它更像是给 Claude Code 装上了一套本地代码导航系统。
少扫描,少猜测,少浪费。
更多时间,直接干活。
最后:

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 11
11 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)