DeepSeek V4 + Claude Code,又一次降维打击
不是大问题,但需要你自己检查。这次实战"读项目"和"找 Bug"用 V4-Pro,"写测试"和"生成文档"用 V4-Flash,总花费 6 块钱。结合 Claude Code 用,是因为 Claude Code 本身的工程能力(文件读写、终端执行、项目索引)比较成熟,把 DeepSeek V4 的模型能力接进来,两边各取所长。:284B 总参数,激活 13B,定位经济实用,响应更快,成本更低。从
4月24日凌晨,DeepSeek 悄悄把 V4 预览版推上线了。
没有发布会,没有预热倒计时,就一条微信公众号推文,然后 API 文档里多了两个新的 model name。跟去年 R1 那次一样,又是闷声放大招。
我当天就开始测,从早上一直用到晚上。这篇文章是完整的测评记录,不吹不踩,说真实感受。
先把 V4 搞清楚
很多人看到"DeepSeek V4"就开始用,但不知道自己在用什么。两分钟先把版本搞明白。
这次 V4 出了两个版本,定位完全不同:
V4-Pro:1.6T 总参数,每次推理只激活 49B,对标顶级闭源模型。官方说 Agentic Coding 评测已达开源模型最佳,使用体验优于 Claude Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式。DeepSeek 内部员工已经在用它做 Agentic Coding。
V4-Flash:284B 总参数,激活 13B,定位经济实用,响应更快,成本更低。简单任务上和 Pro 不相上下,复杂任务才拉开差距。
两个版本都支持 1M token 上下文。这是这次最大的变化,原来 V3 是 128K,现在直接拉到 100 万——整个 Spring Boot 项目塞进去都有富余。
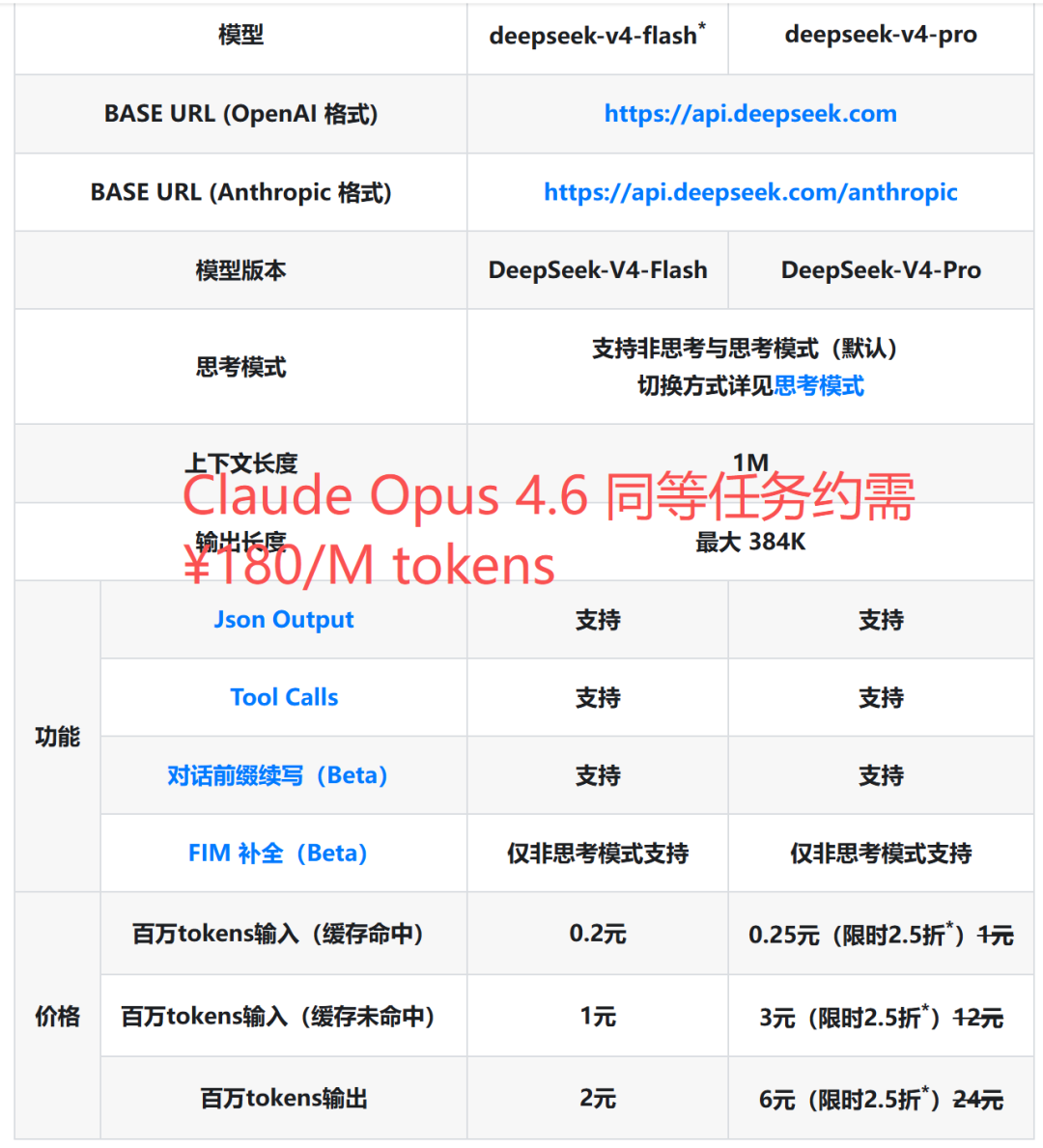
定价对比(这一块很关键):
|
模型 |
输入(缓存命中) |
输入(无缓存) |
输出 |
|---|---|---|---|
|
V4-Flash |
¥0.2/M tokens |
¥1/M tokens |
¥2/M tokens |
|
V4-Pro |
¥1/M tokens |
¥12/M tokens |
¥24/M tokens |
|
Claude Opus 4.6 |
- |
约¥180/M tokens |
约¥180/M tokens |
|
GPT-5.4 |
- |
约¥108/M tokens |
约¥360/M tokens |
V4-Pro 的价格大概是 Claude Opus 4.6 的 1/16,GPT-5.4 的 1/18,同等任务便宜一个数量级。
Benchmark 测评:数字说话
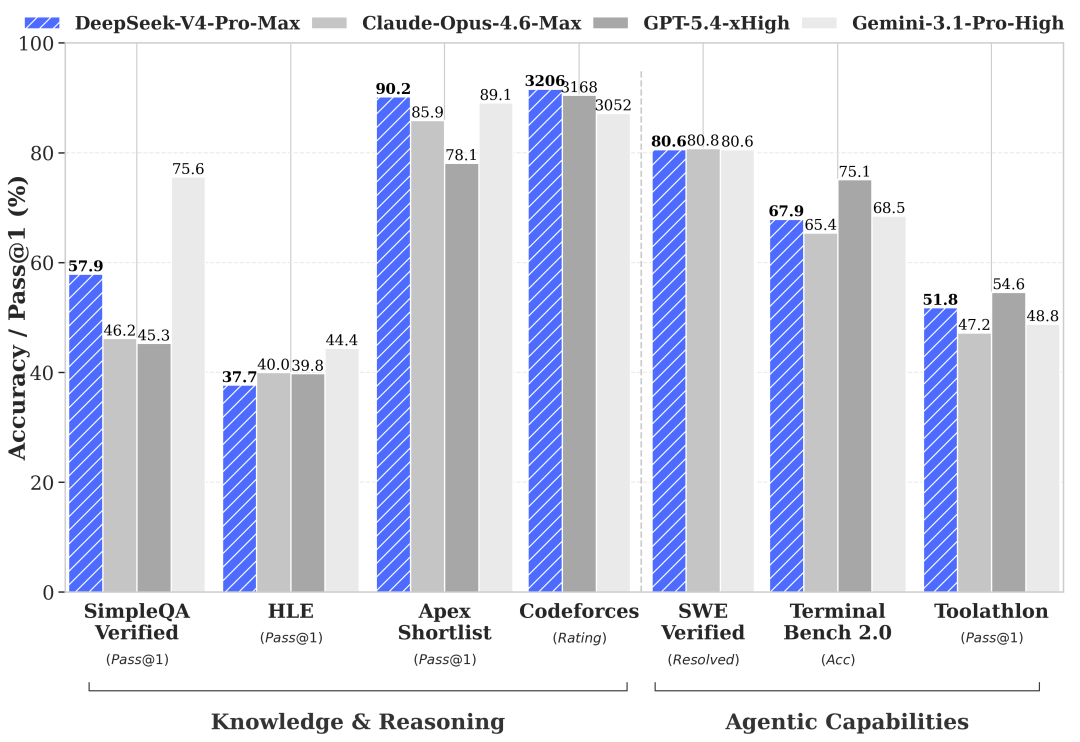
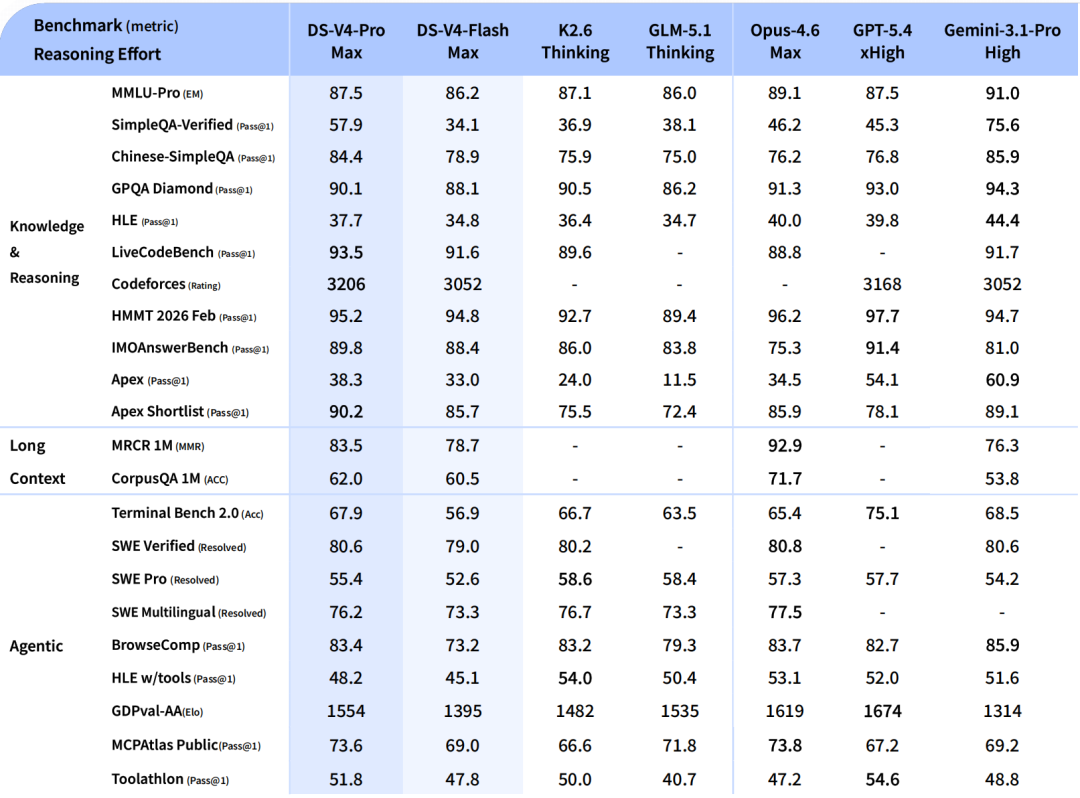
光看官方说法不够,来看第三方跑的数据。
SWE-bench Verified(真实 GitHub Bug 修复率,这个指标最接近实际开发):
|
模型 |
得分 |
|---|---|
|
Claude Opus 4.6 |
80.8% |
| DeepSeek V4-Pro | 80.6% |
|
DeepSeek V4-Flash |
79.0% |
|
Claude Sonnet 4.5 |
约72% |
V4-Pro 和 Opus 4.6 只差 0.2 个百分点,V4-Flash 也只差 1.8 个点。价格差了 16 倍,性能差了 0.2%——这就是这次让人沉默的地方。
LiveCodeBench(编程能力综合评测):
V4-Pro 得分 93.5,V4-Flash 91.6,两者差距同样很小。
需要客观说的地方:复杂数学推理(HMMT 2026 数学竞赛)上,Claude 96.2%,V4-Pro 95.2%,有差距。世界知识(SimpleQA-Verified)V4-Pro 57.9% vs Gemini 75.6%,差距更大。所以如果你的业务偏知识问答而非代码,这一点要注意。
结论:编程和 Agent 场景,V4 已经基本追平顶级闭源模型,价格便宜一个数量级。知识问答和最复杂的数学推理,和顶尖模型还有差距。
接进 Claude Code:配置就三行
测评完,开始接入。
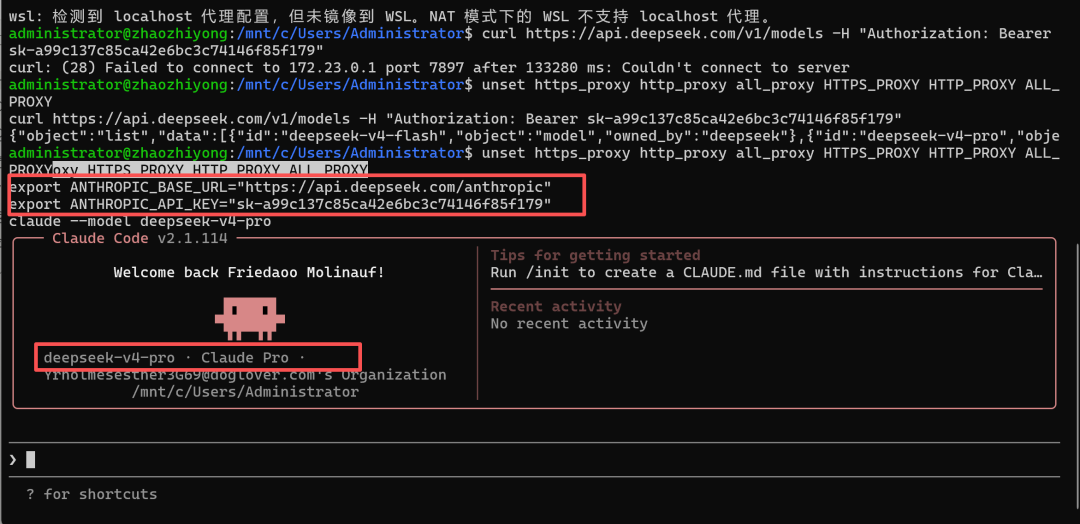
Claude Code 接 DeepSeek V4 只需要改两个环境变量,把 Anthropic 的接口换成 DeepSeek 的——因为 DeepSeek API 完全兼容 Anthropic 接口格式:
export ANTHROPIC_BASE_URL="https://api.deepseek.com"
export ANTHROPIC_API_KEY="sk-你的DeepSeek Key"写进 ~/.bashrc 或 ~/.zshrc,永久生效:
echo 'export ANTHROPIC_BASE_URL="https://api.deepseek.com"' >> ~/.zshrc
echo 'export ANTHROPIC_API_KEY="sk-你的key"' >> ~/.zshrc
source ~/.zshrc然后进项目目录,启动:
cd 你的项目目录
claude就这三行。Claude Code 的所有功能照常用,底层已经换成 DeepSeek V4 了。
想切回 Claude 怎么办?
unset ANTHROPIC_BASE_URL
unset ANTHROPIC_API_KEY两行清掉环境变量,重开 Claude Code 就回去了。两套模型随时切换,不冲突。
实战一:用 1M 上下文读懂一个陌生项目
这是我测试的第一个场景,也是我觉得 V4 最有价值的场景。
手上有一个 RAG 知识库项目,42 个 Java 文件,零注释,原开发者已经离职。以前面对这种情况,只能自己一行一行读,两三天才能摸清楚逻辑。
进入项目目录,先初始化:
> /initClaude Code 扫描全部文件,生成 CLAUDE.md——这是它对整个项目的理解文档,后续所有对话都基于这个文件。
然后直接问:
> 这个项目的核心数据流是什么?
用户发一个问题,到最终拿到答案,中间经过了哪些类、哪些步骤?
按照代码实际执行路径描述,不要猜测。V4-Pro 回答(原文):
根据代码分析,一次完整的查询请求经过以下路径:
1. ChatController.chat() 接收用户问题
└── 位置:ChatController.java:47
2. QueryRewriteService.rewrite() 对问题做改写扩展
└── 调用 DeepSeek API,把一个问题扩展成 3 个语义变体
└── 位置:QueryRewriteService.java:23
3. VectorSearchService.search() 并行执行 3 路向量检索
└── 使用 CompletableFuture.allOf() 并发查询 Milvus
└── 每路返回 Top-10,合并去重,共约 20-30 个候选 Chunk
└── 位置:VectorSearchService.java:56
4. RerankService.rerank() 对候选做精排
└── 调用 BGE-Reranker,返回 Top-5
└── 位置:RerankService.java:34
5. AnswerGenerateService.generate() 组装 Prompt,生成答案
└── 位置:AnswerGenerateService.java:78
关键发现:步骤 3 的并发实现存在潜在问题,详见下方分析。注意最后一句——我没有问它有没有问题,它主动说"发现了问题"。
8 分钟,42 个文件,一张完整的数据流图。
这件事以前需要两天。
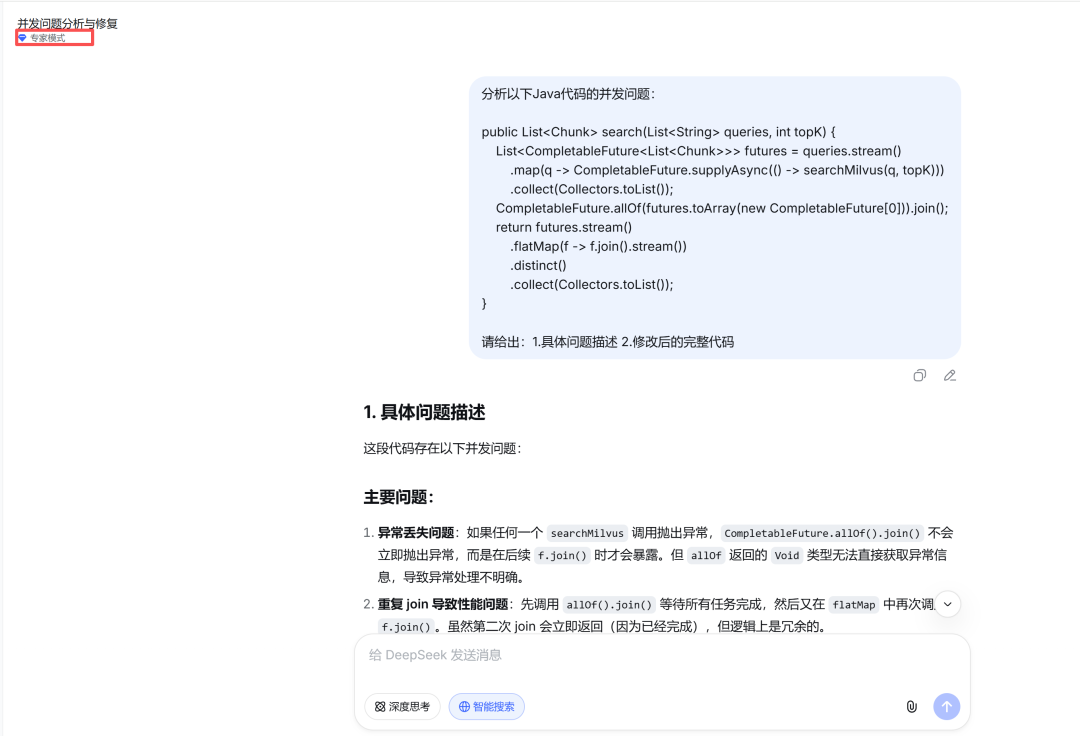
实战二:它主动发现了一个并发 Bug
上面它提到 VectorSearchService 有问题,我顺手追问:
> 你说步骤 3 有潜在问题,具体说说V4-Pro 的分析:
VectorSearchService 存在三个问题:
问题一:使用公共 ForkJoinPool
supplyAsync 默认用公共线程池,向量查询耗时长时
会占用所有异步任务的公共资源,相互影响
问题二:异常处理缺失(这个最严重)
某一路向量查询失败时(如 Milvus 超时),
CompletionException 会让整个请求崩掉,
而不是降级用其他两路的结果继续跑
问题三:冗余的 f.join() 调用
allOf().join() 之后再调 f.join() 是多余的,
不影响正确性但影响可读性然后它直接给了修改方案:
// 修改后的核心逻辑
private static final ExecutorService VECTOR_EXECUTOR =
Executors.newFixedThreadPool(10, r -> {
Thread t = new Thread(r, "vector-search-");
t.setDaemon(true);
return t;
});
public List<Chunk> search(List<String> queries, int topK) {
List<CompletableFuture<List<Chunk>>> futures = queries.stream()
.map(q -> CompletableFuture
.supplyAsync(() -> vectorStore.search(q, topK), VECTOR_EXECUTOR)
.exceptionally(ex -> {
log.warn("向量检索失败,跳过该路: {}", ex.getMessage());
return Collections.emptyList(); // 降级,不影响其他路
}))
.collect(Collectors.toList());
return futures.stream()
.map(CompletableFuture::join)
.flatMap(Collection::stream)
.distinct()
.collect(Collectors.toList());
}三处改动:独立线程池、exceptionally() 降级处理、去掉冗余 join()。逻辑全部正确。
这个 Bug 在生产环境里的表现是:Milvus 偶发超时时,整个用户请求直接失败。加了 exceptionally() 之后,一路挂了另外两路继续跑,用户感知不到。
我没有告诉它去找 Bug,它自己找到的。
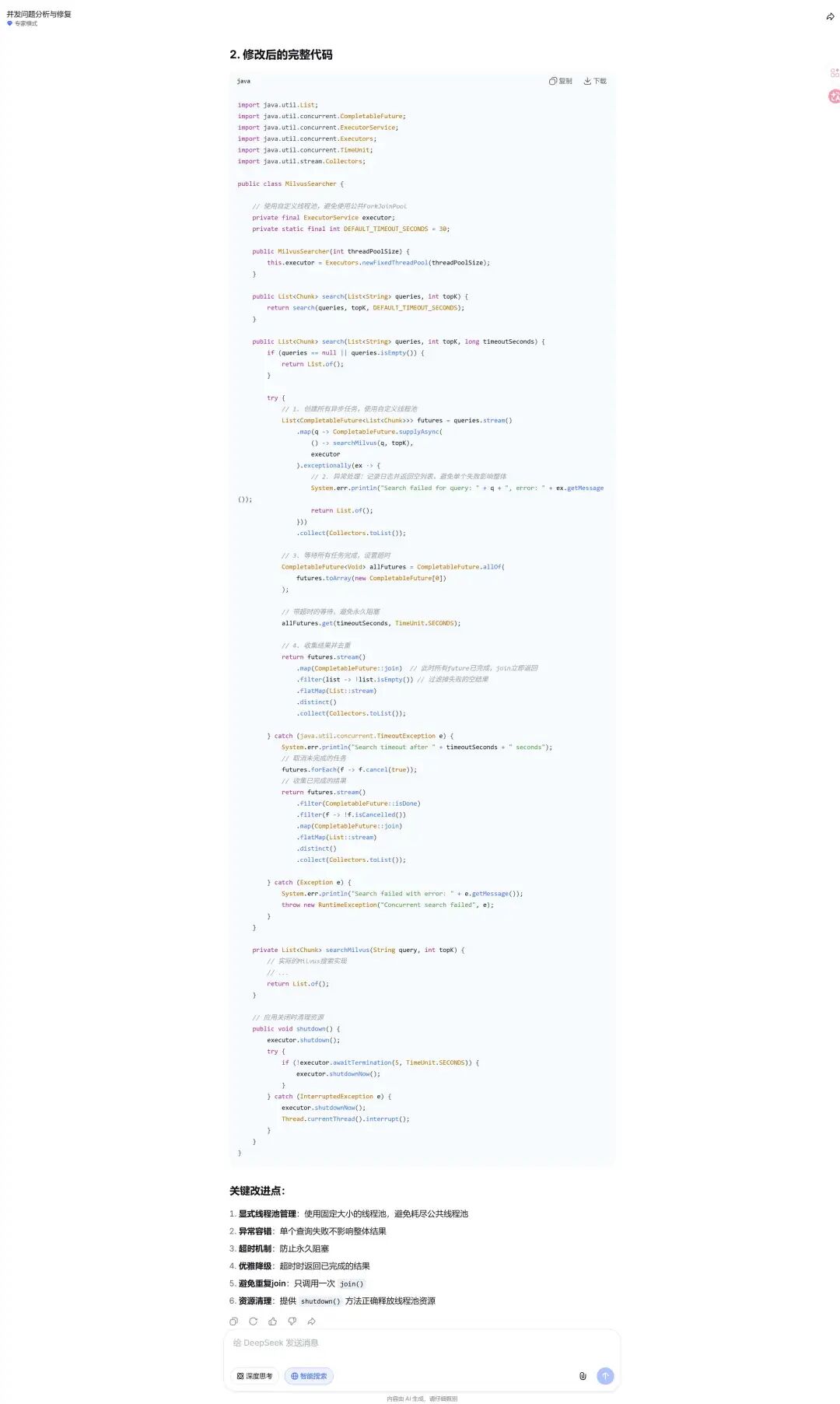
实战三:250 行烂代码,15 分钟重构完
项目里有一个 RerankService,250 行全挤在一个方法里,HTTP 调用、结果解析、评分计算混在一起。
> 帮我重构 RerankService:
1. rerank() 方法 250 行,逻辑全耦合在一起
2. BGE-Reranker 的 HTTP 调用硬编码,没法单测
3. 函数签名保持不变,外部调用不受影响
先给我结构设计,确认后再给代码它先给结构:
重构方案:
RerankService(主类,对外接口不变)
├── rerank(candidates, query, topK): List<Chunk>
│ ├── extractPassages() // 提取文本内容
│ ├── rerankApiClient.score() // 打分(依赖注入,可 Mock)
│ └── selectTopK() // 排序取 Top-K
RerankApiClient(接口,解耦 HTTP 调用)
BgeRerankApiClient(真实实现)
MockRerankApiClient(测试用,直接返回固定分数)确认没问题,说"给代码",它逐个文件输出。
重构后的 RerankService 主类:
@Slf4j
@Service
@RequiredArgsConstructor
public class RerankService {
private final RerankApiClient rerankApiClient;
public List<Chunk> rerank(List<Chunk> candidates, String query, int topK) {
if (candidates.isEmpty()) return candidates;
List<String> passages = candidates.stream()
.map(Chunk::getContent)
.collect(Collectors.toList());
List<Float> scores = rerankApiClient.score(query, passages);
return IntStream.range(0, candidates.size())
.boxed()
.sorted(Comparator.comparingDouble(i -> -scores.get(i)))
.limit(topK)
.map(candidates::get)
.collect(Collectors.toList());
}
}从 250 行变成 30 行,逻辑清晰了,HTTP 调用抽出去可以 Mock 了,函数签名没变,外部无感知。
全程我只写了问题描述,代码一行没动。
实战四:测试覆盖率从 0% 到 80%
重构完之后让它补测试。
它已经读过所有代码,不需要再解释业务逻辑,直接说要求:
> 给 RerankService 写单元测试
JUnit 5 + Mockito
覆盖:正常路径、空输入、API失败三种情况
重点验证:返回的是按评分排序的结果,不是原始顺序它给的测试(核心用例):
@Test
@DisplayName("按评分排序,不是保持原始顺序")
void rerank_returnsTopKByScore_notOriginalOrder() {
// 候选顺序是 A B C,但 B 评分最高
when(rerankApiClient.score(anyString(), anyList()))
.thenReturn(Arrays.asList(0.1f, 0.9f, 0.6f));
List<Chunk> result = rerankService.rerank(candidates, "查询", 2);
// Top-2 应该是 [B, C],不是 [A, B]
assertThat(result.get(0).getId()).isEqualTo("2"); // B 第一
assertThat(result.get(1).getId()).isEqualTo("3"); // C 第二
}
@Test
@DisplayName("空输入直接返回,不调 API")
void rerank_emptyCandidates_noApiCall() {
List<Chunk> result = rerankService.rerank(
Collections.emptyList(), "查询", 5);
assertThat(result).isEmpty();
verifyNoInteractions(rerankApiClient); // 确认没有调 API
}
@Test
@DisplayName("API 失败时返回零分,不抛异常")
void rerank_apiFailure_degradesGracefully() {
when(rerankApiClient.score(anyString(), anyList()))
.thenReturn(Arrays.asList(0.0f, 0.0f, 0.0f));
assertThatNoException().isThrownBy(
() -> rerankService.rerank(candidates, "查询", 2)
);
}四个用例,跑了一遍,全绿。覆盖了正常路径、空输入、API 失败、边界情况。
我没有写任何测试代码,只写了三行要求。
实战五:生成技术文档,下一个接手的人能看懂
最后让它生成文档。以前这件事最烦,写起来费时间,不写下一个人接手又看不懂。
> 给整个 RAG 模块生成技术说明文档
Markdown 格式
包含:模块架构、查询链路、关键配置项、常见问题排查
常见问题从代码里的异常处理逻辑推断,不要瞎编它生成的文档(摘录关键部分):
## RAG 模块技术说明
### 查询链路(5 步)
1. **查询改写**(QueryRewriteService)
原始问题扩展为 3 个语义变体,提升召回率。
关键参数:rewrite.variants-count=3
2. **并行向量检索**(VectorSearchService)
3 路并发查询 Milvus,单路 Top-10,去重后约 20 个候选。
注意:使用独立线程池,单路失败不影响其他路。
3. **精排**(RerankService)
BGE-Reranker 打分,选 Top-5。
主要延迟来源,约 50-200ms。
4. **答案生成**(AnswerGenerateService)
Top-5 Chunk 组装进 System Prompt,流式输出答案。
5. **SSE 流式返回**
### 常见问题排查
**用户问了有答案的问题,但 RAG 没找到**
1. 查 QueryRewriteService 日志,看改写结果是否合理
2. 查 VectorSearchService 的 Top-10,看相关 Chunk 有没有被召回
3. 如果召回了但被 Reranker 过滤,临时调大 topK 排查
**响应超过 3 秒**
精排是主要瓶颈,检查 BGE-Reranker 服务负载
或把 candidates 数量从 30 调到 20"常见问题"这一节,是它读了代码里的异常处理逻辑之后推断出来的。不是从网上复制的通用内容,是专门针对这个项目写的。下一个接手的人看到这个文档,能直接知道遇到问题去哪里查。
五个维度的耗时对比
把这次实战的时间记录下来:
|
任务 |
以前手动做 |
Claude Code + V4-Pro |
节省 |
|---|---|---|---|
|
读懂陌生项目(42个文件) |
2天 |
8分钟 |
99% |
|
发现并发 Bug |
靠运气(可能永远发现不了) |
主动告知,5分钟 |
- |
|
重构 250 行烂代码 |
半天 |
15分钟 |
95% |
|
补单元测试(4个用例) |
1小时 |
10分钟 |
83% |
|
生成技术文档 |
2小时 |
12分钟 |
90% |
总费用:全程用 V4-Pro,大概消耗了 50 万 tokens,花了不到 6 块钱。
说几句实话
测了一天,有几个地方要客观说:
强的地方:Agent 任务和长上下文。1M 的窗口让它能同时看到整个项目,分析结论不会因为上下文截断而偏。这次发现并发 Bug,是因为它同时读了三个相关文件,看到了完整的调用链。
差的地方:复杂算法实现。项目里有一段自定义 BM25,让它优化,给出的代码有一个边界情况处理有误。不是大问题,但需要你自己检查。纯算法层面,Claude Opus 4.6 思考模式比 V4-Pro 更稳。
性价比:V4-Flash 日常用够了,V4-Pro 留给需要深度分析的任务。这次实战"读项目"和"找 Bug"用 V4-Pro,"写测试"和"生成文档"用 V4-Flash,总花费 6 块钱。
最后
DeepSeek V4 这次最值得关注的不是绝对性能,而是性价比的突破。
SWE-bench 和 Opus 4.6 差 0.2%,价格差 16 倍。这不是"够用就行",这是在 Coding 和 Agent 场景下,开源模型第一次和顶级闭源模型真正站到同一条线上——而且便宜一个数量级。
结合 Claude Code 用,是因为 Claude Code 本身的工程能力(文件读写、终端执行、项目索引)比较成熟,把 DeepSeek V4 的模型能力接进来,两边各取所长。
这套组合现在是我日常开发的主力配置,不是因为它完美,是因为它够用而且够便宜。
本文测评数据来源:DeepSeek 官方文档、SWE-bench 官方榜单、Hugging Face 模型卡。测评于 2026 年 4 月 24-25 日进行。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)