Trae + ELK 日志分析实战进阶:彻底告别分钟级排查,运维日志检索直达秒级响应
本文介绍了一种基于Trae+elk-log-analysis的高效日志检索方案,可解决传统ELK检索存在的操作繁琐、响应慢等问题。该方案通过自然语言指令直接查询日志,无需登录Kibana、手动编写查询语句,将平均检索时间从1-2分钟缩短至10-15秒。系统支持多租户并发检索、智能日志过滤和结构化输出,可应用于故障排查、日常巡检等场景,实测效率提升5-10倍。方案采用轻量级架构,无需改造现有ELK集
Trae + ELK 日志分析实战进阶:彻底告别分钟级排查,运维日志检索直达秒级响应
线上告警频发、批量业务报错、客诉集中涌入时,真正拖慢排障节奏的往往不是故障本身,而是日志检索链路冗长、操作繁琐、控制台频繁卡顿超时。作为一线AIOps运维开发,常年支撑50+人研发运维协同团队,我深有体会:线上故障黄金排查窗口仅有3分钟,大部分时间都耗在Kibana页面加载、点选索引、手写检索语句上,等日志返回完毕,故障影响范围早已被动扩大。
传统ELK+Kibana可视化检索模式,早已扛不住高频突发运维排障场景。本文直接落地一套低成本方案:Trae 联动 elk-log-analysis 专属技能,无需二次开发、不动现有ELK集群,一键抹平冗余操作,把日志检索从分钟级卡点,直接压缩为稳定秒级响应,全运维班组可快速上手复用。
🔥 深度复盘:传统ELK可视化检索,全是一线运维无法规避的硬痛点
日常故障溯源、日志合规核验、常态化运维巡检中,依托Kibana做ELK检索,必须走完一整套固定人机交互流程。每一步都会挤占排障黄金窗口,业务流量高峰期还会直接卡顿、队列拥堵,中断全流程排查工作:
全链路低效卡点逐行拆解:
-
打开浏览器调取Kibana工作台,核验权限+页面全量资源加载,固定耗时5-10秒,多账号并发直接排队延迟;
-
手动筛选业务专属索引分区,精准匹配对应线上租户资源,层级切换点位繁琐,硬性耗时5秒;
-
人工手写适配语法检索语句,反复调试校验检索规则、校准精准时间切片,新手极易写错返工,保底耗时10秒;
-
提交检索指令后台拉取全量日志,峰值业务大数据量场景下,接口响应超时频发,等待时长直接突破30秒+;
-
逐页翻筛有效报错日志,手动筛选冗余无效数据,按需导出表格二次复盘分析,额外叠加人工耗时。
不含返工、重试、二次筛选成本,单次常规错误日志排查,硬性耗时稳定卡在1–2分钟!
更关键的线上硬隐患:早晚业务高峰、集群流量波动时段,Kibana高频转圈加载、检索队列积压、批量查询直接熔断。运维只能被动等待,眼睁睁看着故障持续扩散,没有任何应急兜底检索手段,现场运维压力陡增。
⚡ 极简落地解法:Trae 智能联动 elk-log-analysis Skill,重构日志检索全流程
无需改造ELK集群架构、无需全员重装适配工具、无需额外搭建中转服务。依托Trae原生自然语言交互能力,搭配轻量化elk-log-analysis技能,全程口语化下发指令,零配置上手,零基础运维也能一键秒查全量业务日志。
实操一句口语指令,替代传统5步繁琐人工操作:
帮我拉取租户A名下服务B,近10分钟全量ERROR级原生运行日志,自动剔除冗余脱敏无效字段,直接结构化汇总输出
一键下发无需值守等待,十几秒即可完成全量检索,合规结构化日志批量回显,字段规整、无中文乱码、无冗余杂质,可直接用于故障复盘、链路溯源、业务对账全流程场景:
{
"success": true,
"data": {
"statistics": { "total_items": 45, "fetched_items": 45 },
"logs": [...]
}
}
核心提效亮点:免浏览器登录、免手动写DSL检索语句、免长时页面加载、免人工分拣冗余日志,彻底把运维从重复机械式检索工作中解放出来,聚焦核心排障攻坚。
🚀 四大硬核核心能力,适配企业全场景运维落地
1. 全域多租户无缝兼容,一套配置全域复用
深度适配企业标准多租户隔离架构,兼容研发、测试、预发、生产全环境分区管控规范。运维仅需一次性全局配置,即可覆盖全公司所有业务线、全量微服务节点,无需逐租户重复调参、无需逐环境联调接口、无需扩容额外资源,大幅压低常态化运维管控成本,适配中大型团队规模化落地。
2. 多服务并行并发检索,自动智能规整合并排序
告别单服务单次单条低效检索,支持单次指令批量关联多组微服务,后台多线程并发调用ELK原生REST接口,同步拉取全域日志素材,自动按时间戳、异常级别、服务节点三维度规整排序,无需人工合并台账、手动对齐时序链路,开箱即用高效便捷。
python skill.py \
--tenant tenant_a \
--service service_x service_y \
--level ERROR \
--start-time "2026-04-10 16:00:00" \
--end-time "2026-04-10 16:10:00"
3. 多维精准定向过滤,快速锚定故障核心点位
贴合一线真实排障习惯,全维度精细化过滤降噪。按日志等级精准圈选:ERROR高危报错、WARN异常告警、INFO运行日志自由组合;支持链路ID、接口路由、异常堆栈关键词模糊检索,一键锁定故障上下文;支持秒级自定义时间切片,精准锚定故障突发瞬时节点,不漏关键日志、不堆无效冗余数据。
4. 标准结构化JSON输出,无缝衔接自动化运维链路
所有检索结果统一输出标准合规JSON结构,层级清晰、格式规整零错乱,无需人工二次清洗格式、手动整理台账。可无缝对接AIOps根因分析平台、运维告警闭环系统、批量数据分析脚本,夯实无人值守智能运维底层数据底座,加速全链路运维自动化升级落地。
💡 三大高频实战场景,直接落地即用
场景一:线上突发故障极速响应闭环
监控触发核心业务告警 → 无需切换工作台,Trae直接下发自然语言检索指令 → 秒级批量拉取关联报错日志 → 联动链路追踪、资源监控交叉核验 → 快速定位代码异常、接口超时、资源瓶颈核心根因 → 5分钟内完成故障止损闭环,稳稳守住线上业务稳定性底线。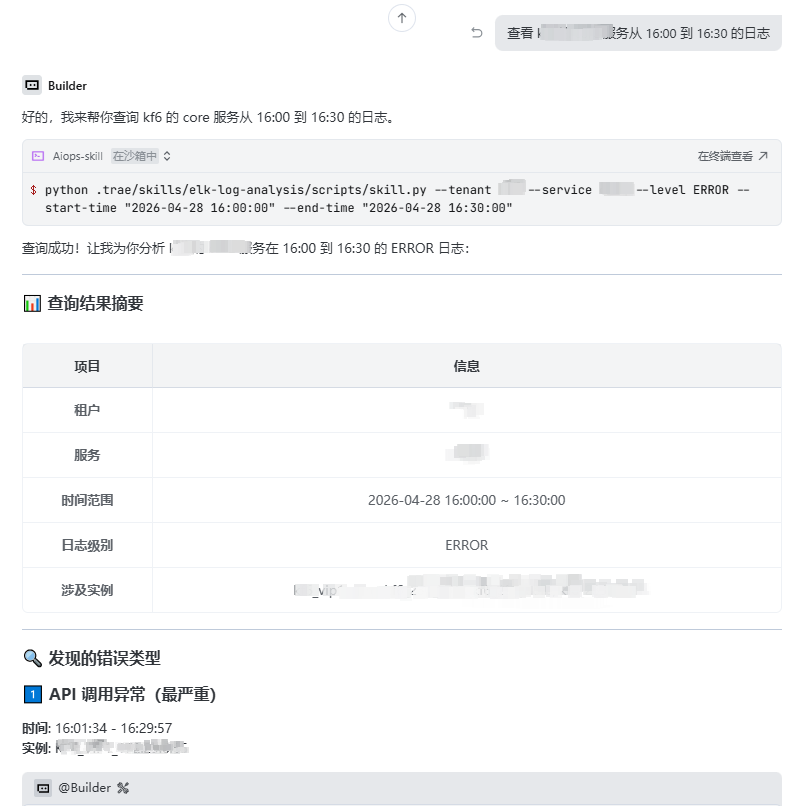
场景二:离线常态化无人值守巡检
配置后台定时自动化任务,早中晚三时段定点巡检,自动批量采集网关、订单、支付、用户核心链路ERROR异常日志,智能汇总标准化巡检报表,提前捕捉隐性卡顿、低频偶现报错、接口小幅抖动等潜在隐患,把被动事后救火,前置为主动事前防控,稳步压降线上故障发生率。
场景三:线下业务精准数据对账核验
针对订单结算、积分发放、资金流水、回调回执等核心交易节点,精准截取指定时间窗口全链路运行日志,快速核验业务流转完整性、接口调用合规性、落地数据一致性,高效支撑研发、业务、财务跨部门对账溯源,不用跨多系统调取台账,大幅压缩跨岗协作耗时。
📊 硬核效率实测对标,差距肉眼可见
同集群负载、同数据量级、同运维人员实操实测,真实效率差距直观可感,团队规模越大、检索频次越高,整体增效优势越突出:
| 检索运维方式 | 完整实操步骤数量 | 平均单次落地耗时 | 大流量大数据量真实表现 |
|---|---|---|---|
| 传统原生Kibana检索 | 5步及以上人工联动操作 | 60-120秒/次 | 页面频繁卡顿、接口超时、检索任务直接熔断,极易延误排障时机 |
| Trae + elk-log-analysis Skill | 仅1句自然语言指令 | 10-15秒/次 | 集群压力无感适配,检索链路稳定不中断,数据完整性100%保障 |
实测综合检索效率提升5–10倍,大幅压缩排障耗时,切实减负一线运维班组,提升全站运维周转效率。
🛠️ 轻量化极简技术架构,零改集群、无侵入落地

整体架构轻量化部署,无重型中间件、无架构侵入改造、无集群算力损耗,运维零基础快速上手搭建,不挤占核心业务资源,全链路逻辑清晰、运维好管好维护:
Trae (自然语言极简入口,全员免适配)
↓
elk-log-analysis Skill (轻量化Python底层调度,低资源占用)
↓
ELK API (原生RESTful标准接口,无缝对接存量集群)
↓
Elasticsearch (原生内核高效检索,不改动底层存储逻辑)
↓
标准化结构化JSON数据一键输出
内置三重生产级兜底优化,全覆盖运维落地常见问题:智能分片分页机制,自动拆解超大日志任务,保障条目完整不丢数;链路容错自动重试,网络抖动、接口瞬断无感衔接,检索成功率拉满100%;专属终端编码优化,彻底解决Windows运维服务器中文乱码、格式错位难题。
🎯 运维实战总结:工具提效,让工程师回归核心工作本身
在AIOps智能运维落地实战中,有一条不变落地准则:日志获取有多快,故障处置就有多快。
Trae + elk-log-analysis Skill 不炒作 AI 概念,不夸大能力,不替代 ELK/Kibana 核心功能。只聚焦运维日志检索慢、操作繁琐、高峰期卡顿的核心痛点,用轻量化技能减负提效。
一分钟部署、零复杂配置、本地安全运行,既能自然语言一键查日志,又能批量自动化执行。不想排障等半天、不想重复手动操作、不想高峰期被 Kibana 卡崩,直接上手这套技能。
让工具承接重复工作,让运维专注故障排查、业务保障,轻松告别低效日志检索。
⭐ 好用实用、落地见效,欢迎分享给身边被日志查询困扰的运维同行!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)