能大米刻字的ChatGPT Images 2.0
同时,新技术也伴随着新挑战,Images 2.0的超逼真效果也引发了关于深度伪造和版权归属的严肃讨论,对AI生成内容的溯源和鉴伪技术提出了更高要求,这是个双刃剑,看我们怎么在合规的情况下充分应用了。模型,就是一个让我们能说出"哇塞"的产品,它是OpenAI最新发布的新一代AI图像生成与编辑模型,内部代号"Spud",是GPT-Image-1.5的全面升级版,同时承接DALL-E 3。模型生成图像的
点击标题下「蓝色微信名」可快速关注
国内外的各种大模型已经给我们工作和生活提供了太多新可能,通过自然语言,生成文字、图像、声音、视频等,已经逐渐被大众熟悉和依赖,各种产品也是层出不穷,有的相当惊艳。
ChatGPT Images 2.0,即GPT-Image-2模型,就是一个让我们能说出"哇塞"的产品,它是OpenAI最新发布的新一代AI图像生成与编辑模型,内部代号"Spud",是GPT-Image-1.5的全面升级版,同时承接DALL-E 3。
它将图像生成从"提示词到像素"的渲染过程,升级为"思考、验证再到生成"的战略设计系统,旨在成为实用的生产力工具。对很多的设计师来讲,这可能是个提升工作力的机会,但同时会对就业造成很大冲击。
大模型相关历史文章,
GPT-Image-2模型五大核心突破
-
🧠 原生“思考”能力:这是其最根本的升级。启用后,模型在生成图像前会先联网搜索信息、拆解复杂任务并生成多个方案,最后进行自我复核与修正,从而大幅提升输出的准确性和一致性,如同一位会规划的内置“设计师”。
-
✍️ 革命性的文字渲染:它能精准渲染包含中文、日文、韩文等在内的多语言文本,准确率高达99%。无论是菜单、海报还是UI界面上的小字,都能清晰准确。
-
🎨 精准构图与高度一致性:它能严格遵循复杂的详细指令,精准控制图像中每个元素的布局、颜色和位置关系。支持一次性生成最多8张保持角色、风格一致的连贯图像,对绘本故事、产品套图、分镜脚本等系列创作极为实用。
-
🔗 深度集成与调优:模型训练使用了截至2025年12月的最新数据,能生成贴合当下语境的内容。它无缝集成在ChatGPT和Codex中,开发者也可通过API调用,将其强大的生成和编辑功能嵌入自己的工作流。
-
🎞️ 画质与风格的飞跃:图像生成支持从1:3到3:1的灵活宽高比,最高输出2K分辨率,并彻底移除了常见的“AI味”(如塑料感或黄色滤镜)。

竞品速览
Images 2.0的发布给图像生成市场带来了不小的影响,它在权威模型测试平台LMSYS Image Arena的文生图、单图/多图编辑类别中均位列第一:
-
vs. Google Gemini系列 (Nano Banana):优势在于多图一致性及文字渲染;短板是Google深度整合搜索与服务生态。
-
vs. Midjourney:细节与UI元素生成更精准,作品可直接用于工作流;但在纯艺术创作的审美上仍有差距。
-
vs. DALL-E 3 (前代模型):升级幅度极大,尤其在指令遵循、文字渲染和多语言支持等核心短板上有质的飞跃。
🏗️ 技术架构揭秘
Images 2.0最关键的架构革新,是从传统的扩散模型切换到全新的自回归生成:
-
传统扩散模型 (如DALL-E):将文字“翻译”给一个独立的图像生成器,有损耗。
-
自回归生成 (如GPT-Image-2):图像与文本共享一张 “令牌”词汇表。模型生成图像的方式,就像在逐字“写作”而非“涂鸦”,因此能像输出文字一样精确地“写”出图像中的每个像素和文字。
ChatGPT Images 2.0 使用教程(详细步骤)
步骤一:登录ChatGPT官网
打开浏览器进入ChatGPT官网:https://chatgpt.com/,需要登录自己的账号(必须登录才可以用)。免费账号也能用ChatGPT Images 2.0,只是每天有生成次数限制。
步骤二:进入图像生成入口
在对话框点击「+号」,选择「创建图片」,这就是ChatGPT画图2.0的入口。输入想要生成图片的提示词,然后直接发送即可等待。
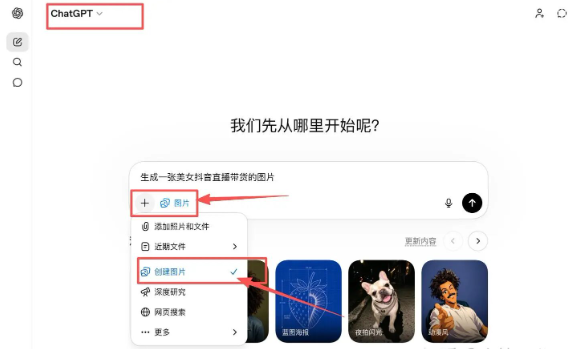
步骤三:输入提示词并生成
稍等片刻,图就做好了。
步骤四:调整宽高比与二次优化
点击生成出来的图片,可以进入编辑面板,改宽高比、做局部优化、重新出图都支持。
原生Thinking模式的生图逻辑:生图前先规划,生图后自检。
这是GPT-Image-2最核心的架构创新。它接入了OpenAI O系列推理模型,生成一张图要走完整的这几个流程:创建 → 打草稿 → 生成初稿 → 搭建场景 → 打磨细节 → 收尾 → 润色 → 微调。
以前这种图AI也能做,但大概率一眼假。位置像假的、文案像乱填的、结构混乱。这次GPT-image-2出来的东西,真的让人有些后背发凉,这是我做的中超联赛赛前海报,一些细节上做的都非常到位,让人很震撼,

这次GPT-image-2对设计行业的冲击,我觉得比以前任何一次都大。因为"画图"这件事本身开始不再稀缺,一个小白就能做出中高端的图。关键是它生成的东西符合真实产品的视觉规律。
但是换个角度,画图只是设计的执行层,真正稀缺的是你能不能看懂问题,你能不能理解用户,你能不能判断这张图为什么这么排,你能不能在一堆可能性里,找到那个最适合业务、最适合传播、最适合转化的解法。
这些东西,AI现在还没完全替代。就像程序员,判断、审美、思考、还有解决问题的能力才是最重要的。画图执行的时代确实在结束了,但设计师的时代未必结束,甚至某种程度上,可能才刚开始。
同时,新技术也伴随着新挑战,Images 2.0的超逼真效果也引发了关于深度伪造和版权归属的严肃讨论,对AI生成内容的溯源和鉴伪技术提出了更高要求,这是个双刃剑,看我们怎么在合规的情况下充分应用了。
如果您认为这篇文章有些帮助,还请不吝点下文章末尾的"点赞"和"在看",或者直接转发朋友圈,

可以到各大平台找我,
-
微信公众号:@bisal的个人杂货铺
-
腾讯云开发者社区:@bisal的个人杂货铺
-
头条号:@bisal的个人杂货铺
-
CSDN:@bisal
-
ITPub:@bisal
-
墨天轮:@bisal
-
51CTO:@bisal
-
小红书:@bisal
-
抖音:@bisal
近期更新的文章:
《英超第三十三轮》
近期Vlog:
《千岛湖》
《新疆之行(红山体育馆 - 国际大巴扎 - 红山公园 - 天山天池)》
《新疆之行(天马浴河 - 哈因塞 - 那拉提 - 依提根塞)》
热文鉴赏:
《推荐一篇Oracle RAC Cache Fusion的经典论文》
文章分类和索引:

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)