Claude Code 架构与设计理念解析
参考资料
Dive-into-Claude-Code
deep-dive-claude-code
cc-haha
一、Claude Code 架构解析
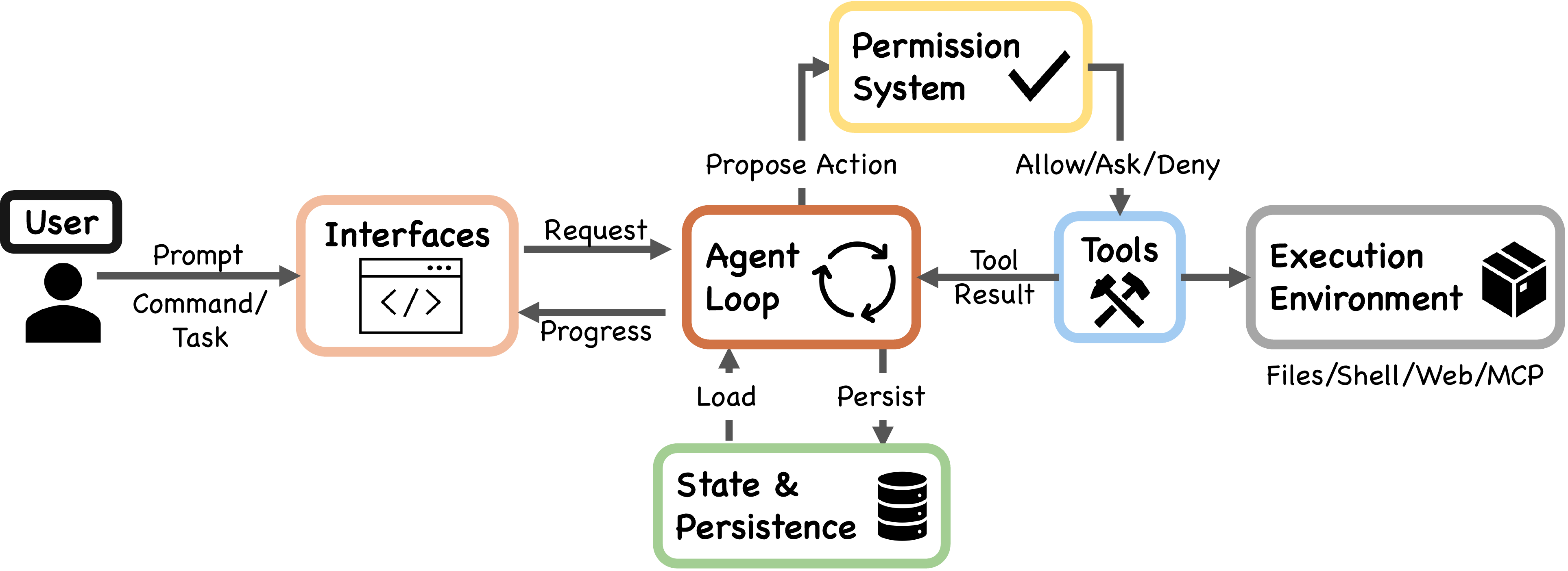
Claude Code 不是“一个聊天 UI + 一个大模型”,而是一个终端原生 AI Agent 运行时。模型负责推理和决定下一步,宿主程序负责上下文组装、工具执行、权限判断、状态持久化、错误恢复和 UI 渲染。Dive-into-Claude-Code 的核心结论也很明确:Agent loop 本身很简单,复杂度主要在 loop 周围的确定性基础设施;该资料称约 1.6% 是 AI 决策逻辑,98.4% 是权限、上下文、工具路由、恢复逻辑等基础设施。
Claude Code 的 Agent 行为,本质上是一个 ReAct 风格 while-loop:
while true:
1. 组装上下文
2. 调用模型
3. 模型输出文本或 tool_use
4. 如果有 tool_use:
权限检查
执行工具
把 tool_result 加回消息
继续下一轮模型调用
5. 如果没有 tool_use:
结束
二、Claude Code 的核心设计理念
把几篇资料的观点汇总起来,Claude Code 的设计哲学可以浓缩成下面几条。
1. Harness vs. Model 的严格分离——“模型负责推理,框架负责执行”
这是整个系统最核心的一条哲学。Claude Code 有 960+ 个文件、380K+ 行代码,但真正属于"AI 决策逻辑"的代码只占约 1.6%,剩下 98.4% 都是围绕模型的确定性基础设施:权限系统、上下文压缩、工具路由、恢复逻辑、会话持久化。Anthropic 的赌注是:当基础模型的推理能力趋于收敛时,生产级 Agent 的可靠性差异将来自外围工程,而不是模型本身。
2. 一个极简的 Agent Loop,外面套一层厚重的工程防护
核心循环其实就是"send message → 模型响应 → 执行工具 → 回传结果 → 重复"的 while 循环,实现在 QueryEngine.ts 和 query.ts 里。一个教学版 Agent 30 行就能写完,Claude Code 在同一个骨架上堆了多层基础设施。这种"小内核 + 大外设"的结构,让系统可以在不改动主循环的前提下,通过加工具、加权限模式、加 MCP server 不断扩展。
3. Tool 作为统一抽象——类似 Unix 的"Everything is a Tool"
每一个能力——读文件、跑 Bash、grep、调用 MCP 远端服务——都实现同一个 Tool 接口(schema、permission、execute)。内置 50+ 工具和外部 MCP 工具在主循环眼里完全一样。这和 Unix 把一切抽象为"文件"是同一种哲学:用一个最小共通接口,换来巨大的正交扩展空间。
4. Deny-first 的多层权限系统
安全是 Code Agent 的生死线。Claude Code 用七种权限模式 + ML 分类器 + 级联规则(规则 → 工具逻辑 → 模式 → 分类器 → 用户),每一次工具调用都要过闸。拒绝优先于询问、询问优先于允许,最严格的规则赢。Anthropic 发现当用户批准率达到 93% 时会出现"批准疲劳",解决方案不是加更多警告,而是重构边界——这本身就是一条很有分量的工程哲学。
5. 在有限上下文里做无限工作——五层压缩流水线
从 Budget reduction → Snip → Microcompact → Context collapse → Auto-compact,五层 lazy degradation,每一层都比上一层代价更高,只在必要时触发。目标是保住 prompt cache 经济性的同时,让 session 可以跑很长很长。
6. 可扩展性分层——MCP / Plugin / Skill / Hook
四种扩展机制各司其职:MCP 对接外部服务、Plugin 扩展 CLI、Skill 封装可复用工作流、Hook 在动作前后强制执行规则。这是对"不同扩展需求要有不同的扩展口子"的承认,而不是把什么都塞到一个插件体系里。
7. 为人而设计——人保留最终控制权
Anthropic 的 Agent 安全框架里有一条中心张力:“Agent 必须能自主工作,这正是它的价值所在;但人类必须保留对目标如何实现的控制权。” principal hierarchy、skill 系统、CLAUDE.md 的配置面,全都是在给人保留干预点,而不是追求端到端的全自动。
8. 工程务实主义
书的第九部分专门讲这些看似不起眼但关键的决策:Bun 的 feature() 内建做编译时 DCE,让一个二进制里藏着 108+ 个内部模块但对外发布时被剥掉;React + Ink 自定义渲染器;append-only 的会话存储;Zod 全程校验类型边界。这些选择单个看都不惊艳,组合起来就是"生产级"。
三、Claude Code 与 CUDA编程系统 的区别
先简单介绍一个 CUDA 编程系统:KernelBlaster 。它是 2026 年 2 月 arxiv 上的工作(Kris Shengjun Dong 等人),一个 Memory-Augmented In-context Reinforcement Learning (MAIC-RL) 框架,用来让 LLM Agent 跨任务、跨 GPU 代际地优化 CUDA kernel。核心机制是一个可检索的 Persistent CUDA Knowledge Base + profile-guided、textual-gradient 风格的 agentic flow。在 KernelBench 上相对 PyTorch baseline 取得了 1.43× / 2.50× / 1.50× 的几何平均加速。
两个系统虽然都叫"Agent",但有很大差异。下面从几个关键维度对比:
1. 目标不同
Claude Code 的目标是通用的、有人参与的软件工程协作——理解代码库、多步推理、改动正确性、不破坏用户环境。它的"成功"是模糊的、上下文相关的、需要人来判定的。
KernelBlaster 的目标是狭窄的、可度量的性能搜索——给定 PyTorch 参考代码,在特定 GPU 上生成功能等价且更快的 CUDA kernel。成功函数是硬指标:正确性(数值 tolerance)+ runtime 加速比。这是一个有明确奖励信号的优化问题。
2. Loop 的性质不同:对话循环 vs. 搜索循环
Claude Code 是对话 / 工具循环:一次 turn 里模型决定做什么,执行结果回到上下文,人可以随时介入。循环的目的是推进任务,而不是搜索最优解。
KernelBlaster 是优化搜索循环:类似进化算法——生成候选 kernel、profile、根据 profile 的"文本梯度"生成下一代、把好的策略写进知识库。它跑的是一个 cross-task 的强化学习 / 搜索过程,没有人在回路里。
3. 记忆与学习方式不同
Claude Code 的记忆是会话级 + 工程化压缩:五层 compaction 保 context 活着,跨会话主要靠 CLAUDE.md、skill、append-only session storage。它不会在任务之间"学习"——模型权重是冻结的,知识只存在于人手工维护的文件里。
KernelBlaster 的核心创新恰恰是跨任务持久化学习:Persistent CUDA Knowledge Base 把先前任务中验证过的优化策略(比如"这个 tile size 在 H100 上对这类 GEMM 有效")沉淀下来,后续任务检索使用。这是一种 in-context RL——不改模型权重,但系统有经验积累。Claude Code 刻意不做这件事。
4. 基础设施重点完全不同
Claude Code 的 98.4% 基础设施在:权限、上下文、工具路由、UI、会话恢复——因为它面对的是不受控的真实代码库和真实用户。
KernelBlaster 的基础设施在:验证器(确保数值正确)、profiler(拿到 runtime/占用率/内存带宽数据)、reward signal、搜索策略、知识库检索——因为它面对的是一个封闭、可自动评判的优化问题。
5. 安全模型:人类授权 vs. 数值验证
Claude Code 的安全是拒绝优先 + 人类批准,因为 Bash/文件写入的后果不可逆且领域无关。
KernelBlaster 几乎不需要这种安全模型——它的"安全"就是正确性验证:跑单元测试,对比输出,tolerance 内即 OK。沙盒是自然的(kernel 只影响 GPU 内存),不需要七层权限。
6. 可扩展性哲学
Claude Code 是 Unix 哲学——用 Tool 接口 + MCP 让世界上所有东西都能接进来,领域无关。
KernelBlaster 是领域专家系统——它的扩展点(profiler、verifier、knowledge base schema)全部是为 CUDA 这一个领域设计的,换到 Triton / Metal 需要大动干戈。
总结
Claude Code 是一个为通用软件工程打造的、以人为中心的 Agent harness,它的价值在于把一个"还不够可靠"的通用模型包装成一个"足够可靠"的协作工具;它不关心模型在某一类任务上变得更好,只关心任何任务上都不出严重事故。
KernelBlaster 是一个为 CUDA 性能优化打造的、自主搜索式的 Agent,它的价值在于把"不能跨任务学习"的 LLM 变成一个"能积累 GPU 优化经验"的搜索系统;它不关心领域通用性,只关心在一个狭窄指标上逼近甚至超越专家。
用一个比喻:Claude Code 像一个配备了完整 IDE、版本控制、权限审计的资深工程师的工作台;KernelBlaster 像一个装了 profiler、知识库和进化算法的 CUDA 性能实验室里的自动化实验台。两者都是 Agent,但一个在解决"如何让 AI 在开放世界里安全地干活",另一个在解决"如何让 AI 在封闭优化问题里持续变强"。这两条路径未必互斥——未来的理想系统很可能是 Claude Code 这样的 harness 在特定子任务上调用 KernelBlaster 这样的领域专家——但它们代表的设计哲学现在是清晰分开的。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)