一家叫 DeepSeek 的中国公司,是怎么用三年时间改写全球开源大模型版图的
我记得当时 SemiAnalysis 出了一篇长报告,把 V3 的训练成本、推理成本、技术取舍拆得很细,结论大致是:"这是迄今为止最好的开源模型,没有之一。今天我想聊的这一家,相对年轻很多,但我个人认为,它在过去三年里所完成的爬坡,是中国科技产业里非常值得认真记一笔的事情。但在这十一个月里, DeepSeek 把 R1 的推理能力、 V3.1 的 Think/Non-Think 双模式、 V3.2
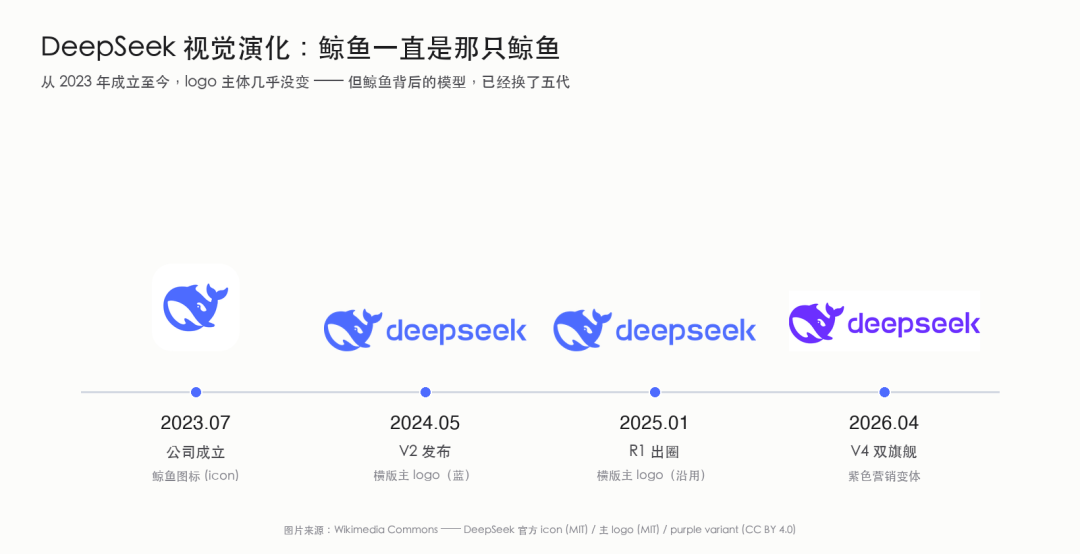
一、先把话说在前面
最近这几年,我陆陆续续写过不少关于中国科技公司的文章。华为、中芯国际、比亚迪、宁德时代、大疆,每一家都有自己的故事。今天我想聊的这一家,相对年轻很多,但我个人认为,它在过去三年里所完成的爬坡,是中国科技产业里非常值得认真记一笔的事情。
这家公司就是 DeepSeek。
可能很多人对 DeepSeek 的印象,还停留在 2025 年 1 月那一波 "DeepSeek 出圈"。当时 DeepSeek-R1 在 1 月 20 日发布,紧接着 App Store 登顶、海外社交媒体刷屏,到 1 月 27 日整个西方资本市场连锁反应,纳斯达克和英伟达单日大跌。整个西方 AI 行业才突然意识到:原来一家中国公司,也可以做出能跟 OpenAI o1 直接对标的推理模型,而且权重和论文全部开源, MIT 协议,允许蒸馏,允许商用。
但如果你只看那一个时刻,其实是严重低估了这家公司的份量。
为了写这篇文章,我前后花了几天时间,把 DeepSeek 从 2023 年 11 月第一次公开发布到 2026 年 4 月最新发布的所有主要版本——DeepSeek LLM 、 V2 、 V2.5 、 V3 、 R1 、 V3.1 、 V3.2-Exp 、 V3.2 、 V4-Pro 、 V4-Flash——对应的官方公告、 GitHub 仓库、 HuggingFace 模型卡、 arXiv 论文一一翻了一遍。
翻完之后,我有一个非常直接的感受:
DeepSeek 不是某一次"爆冷出圈"的偶然,而是一家中国公司用三年时间,一步一个脚印爬出来的。
接下来这篇文章,我就尽可能用第一手数据,把这条路给你讲清楚。文章会长一点,请你耐心。
二、先看一组让我个人很惊讶的数字
老规矩,我们先把数字摆出来。
DeepSeek 最早公开发布的模型,是 2023 年 11 月 29 日 的 DeepSeek LLM 7B / 67B 系列。当时它的规格是这样的:
总参数:7B 和 67B( dense )
上下文长度:4K
训练数据:2T tokens
架构:标准 dense Transformer
放在 2023 年底的开源大模型圈子里,这是一个完全合格、但并不出众的水平。同期的 LLaMA-2 70B 、 Mistral 7B 、 Qwen 7B/14B 大家都在这个区间里你追我赶。
我们再看一下 2026 年 4 月 24 日 上线的 DeepSeek-V4-Pro :
总参数:1.6T(也就是 1 万 6 千亿)
激活参数:49B
上下文长度:1M
训练 tokens :>32T
架构: MoE + MLA + DSA + Hybrid Attention ( CSA + HCA ) + mHC + Muon 优化器
我们做一个简单的对比:
|
指标 |
DeepSeek LLM 67B |
DeepSeek-V4-Pro |
增长倍数 |
|---|---|---|---|
|
总参数 |
67B |
1.6T |
约 24 倍 |
|
激活参数(用户实际承担) |
67B ( dense 全激活) |
49B |
0.73 倍(更小!) |
|
上下文长度 |
4K |
1M |
256 倍 |
|
训练 tokens |
2T |
>32T |
超过 16 倍 |
请你重点看激活参数那一行。
什么意思呢?意思是用户每次跑这个模型,实际"喂进 GPU"参与计算的参数量,只有 49B。
而第一代 DeepSeek LLM 是 dense 67B ,每跑一次推理,那 67B 都得整个激活一次。
把这两个数字放在一起,我得出一个很直接的结论:
三年里, DeepSeek 模型容量扩张了 24 倍,但用户每次推理实际承担的计算成本,反而比第一代还要略小一点。
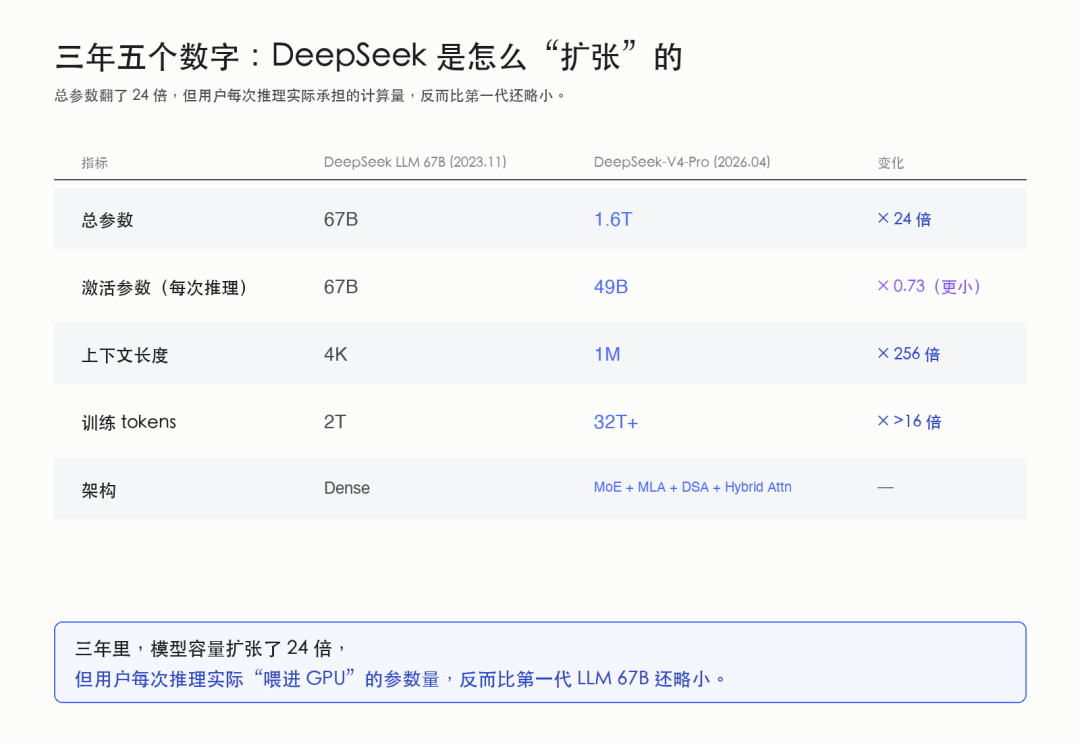
这件事,我必须说,是非常了不起的工程成就。我个人认为,它比"参数做到了 1.6T"这件事本身,重要十倍。
为什么呢?因为它直接说明了一个东西:
DeepSeek 走的从来不是"暴力堆参数、暴力烧算力"的路线。它走的是一条"在不让用户多花钱的前提下,把模型能力一点一点往上推"的路线。
而这件事,对中国 AI 产业、对全球开源大模型生态、对所有正在被算力卡脖子的国家,都有非常实际的意义。
下面我们一段一段往下讲。
三、第一阶段( 2023.11 → 2024.05 ):从 dense 67B 到 V2 , DeepSeek 找到了自己的方法论
2023 年 11 月 29 日, DeepSeek LLM 67B 系列在 GitHub 上开源。模型卡上写得很朴素:
7B 和 67B 两个规格
base 和 chat 两种版本
2T tokens 训练
4K 上下文
商业可用
当时这家公司还叫不上名字。论文挂上 arXiv 之后,业内的反应大致是:"还行,性能能打 LLaMA-2 70B ,做得挺扎实,但不算开创性。"
事实上,这一代模型在后来 V2 的官方材料里,被回溯式地标注为 "DeepSeek-V1 ( Dense-67B )"。也就是说, DeepSeek 自己也认为,那一代是它的 V0/V1 阶段——是"我能做模型"的证明,不是"我有方法论"的证明。
真正让 DeepSeek 从"一家做得不错的开源公司"变成"值得重点观察的中国新势力"的,是 2024 年 5 月 6 日发布的 DeepSeek-V2。
V2 的官方规格是这样的:
总参数 236B ,激活参数 21B
上下文 128K
训练数据 8.1T tokens
架构 DeepSeekMoE + MLA ( Multi-head Latent Attention )
我们做几个对比:
总参数: 67B → 236B ,约 3.5 倍
激活参数: 67B → 21B,反而下降到原来的 1/3
上下文: 4K → 128K ,32 倍
训练 tokens : 2T → 8.1T ,约 4 倍
注意,这里出现了一个非常关键的转折:
总参数翻了 3.5 倍,但激活参数从 67B 降到了 21B 。也就是说,模型容量大了,但用户实际承担的计算成本反而小了。
这一点,是 DeepSeek 第一次表现出和主流 dense 路线完全不同的取舍。
更重要的是, V2 的官方论文里给出了几个非常硬的数字:
相比 DeepSeek 67B ,训练成本节省 42.5%
KV 缓存减少 93.3%
最大生成吞吐提升到 5.76 倍
这些数字背后,是一整套以 MLA (多头潜在注意力)+ DeepSeekMoE 为核心的架构选择。
我多说一句,因为我觉得这一点国内媒体讲得不够清楚:
MLA 这个东西,是 DeepSeek 第一次在国际开源大模型架构层做出的真正原创性贡献。 它不是在 LLaMA 上改改、在 Mistral 上调调,而是 DeepSeek 自己提出来的注意力机制改造方案,目的是把 KV 缓存的成本压下去。后来你能看到,整个开源圈陆陆续续都在借鉴 MLA 思路,包括很多做长上下文方向的中外团队。
也就是说,从 V2 这一代开始, DeepSeek 已经不只是"用别人的方法做开源模型",而是开始"提出自己的方法、被别人引用"。
这是中国 AI 公司在大模型时代第一次真正进入"被引用方"的阵营。
我个人认为, 2024 年 5 月 6 日,是 DeepSeek 整个发展史上最重要的一天,没有之一。
四、第二阶段( 2024.09 → 2024.12 ): V2.5 和 V3 , DeepSeek 站上世界前沿
很多人对 DeepSeek 真正的关注,是从 V3 开始的。但实际上中间还有一个非常关键的过渡版本——V2.5。
2024 年 9 月 5 日, DeepSeek 发布 V2.5 。这个版本看起来像是常规升级,但意义其实很大。它是把:
DeepSeek-V2-0628 (通用对话版)
DeepSeek-Coder-V2-0724 (编码版)
这两个原本独立的产品线,合并成了一个统一的主力模型。这意味着 DeepSeek 在 2024 年下半年,就已经看明白了一件事:
未来用户需要的不是"一个聊天强、一个写代码强"两个模型,而是一个能同时承担对话、编码、 function calling 、 JSON 输出、结构化任务的统一模型。
这一点判断,我现在回头看,跟 OpenAI 后来 GPT-4o → GPT-5 把全部能力收敛到一个统一模型的方向,是高度一致的。
也就是说,DeepSeek 在 2024 年 9 月就开始做统一主力模型的产品判断,比 OpenAI 公开走这条路要早差不多一年。
到了 2024 年 12 月 26 日, DeepSeek 发布 V3。这一代直接把规格拉到了一个新台阶:
总参数 671B
激活参数 37B
训练 tokens 14.8T
上下文 128K
架构延续 MLA + DeepSeekMoE ,新增 auxiliary-loss-free load balancing 和 multi-token prediction
我们再做一个对比:
总参数: 236B → 671B ,约 2.85 倍
激活参数: 21B → 37B ,约 1.76 倍
训练 tokens : 8.1T → 14.8T ,约 1.83 倍
请注意这三个比例:总参数大概翻了三倍,但激活参数和训练 tokens 都只翻了不到两倍。
这说明什么?说明 DeepSeek 在 V2 → V3 这一步,仍然在坚持"模型容量可以涨,但用户感知的成本要慢慢涨"的取舍。
V3 的官方公告里写了一个数字,我特别想拿出来讲一下:"3 倍快于 V2"。
为什么我特别想强调这个数字?因为它说明了一个反直觉的事情:
V3 的总参数是 V2 的 2.85 倍,但单 token 推理速度反而比 V2 快了 3 倍。
这在当时整个开源大模型圈里,是几乎没有先例的。同期 LLaMA 、 Mistral 这些模型,都是参数越大、推理越慢、部署越难。 DeepSeek 偏偏走出了一条 "模型更大,反而推理更快" 的路线。
到这一步, DeepSeek 才算真正站上了世界开源前沿。后来美国知名 AI 评测机构、风投圈、 SemiAnalysis 这种深度技术媒体,开始大量讨论 DeepSeek-V3 。我记得当时 SemiAnalysis 出了一篇长报告,把 V3 的训练成本、推理成本、技术取舍拆得很细,结论大致是:"这是迄今为止最好的开源模型,没有之一。"
注意,这是西方 AI 行业第一次给一家中国公司这种评价。
五、第三阶段( 2025.01 ): R1 出圈, DeepSeek 让全世界第一次正眼看中国 AI
2025 年 1 月 20 日, DeepSeek 发布 R1。
我相信很多读者对 DeepSeek 的认识,就是从这一天开始的。
R1 这件事,我必须用比较长的篇幅来讲,因为它的意义远远超出了一个模型发布本身。
先说技术。 R1 的官方信息是这样的:
基于 DeepSeek-V3-Base 构建
通过 大规模强化学习( RL )后训练
性能对标 OpenAI-o1
模型权重和代码以 MIT License 开源
明确允许蒸馏,明确允许商业使用
那个时候 OpenAI 的 o1 是什么状态呢?
2024 年 9 月 12 日: OpenAI 推出 o1-preview / o1-mini ,正式把推理模型作为一条独立产品线
2024 年 12 月 17 日: o1 走向 API 生产化部署
完全闭源
完全不开放思维链
价格非常贵( input $15 / output $60 per million tokens )
也就是说, OpenAI 把推理模型这条路线立起来才四个月, DeepSeek 就拿出了一个性能对标、完全开源、允许蒸馏、允许商用的版本。
这件事在西方 AI 圈引发的反应有多大,我们做几个客观陈述:
1.
2025 年 1 月 27 日:纳斯达克因为 DeepSeek-R1 的冲击单日大跌,英伟达单日市值蒸发约 5890 亿美元,是当时美股历史上单日最大市值损失。
2.
2025 年 1 月底: DeepSeek-R1 在 OpenRouter 、 Together AI 、 Fireworks 等推理服务平台上的调用量暴增。 Hugging Face 上 R1 系列模型在一周内被下载超过百万次。
3.
2025 年 1 月 31 日: Sam Altman 在 Reddit AMA 上公开承认 "OpenAI 在开源这件事上站在了错误的一边"(原话:"I personally think we have been on the wrong side of history here and need to figure out a different open source strategy")。 Anthropic CEO Dario Amodei 专门发表长文《 On DeepSeek and Export Controls 》回应。 R1 也成为美国新一轮对华 AI 政策辩论中被反复提及的标志性事件。
4.
西方主流媒体(《纽约时报》《华尔街日报》《经济学人》《彭博》)头版连续几天讨论 DeepSeek 。
我个人观察,这是中国 AI 公司第一次在西方主流舆论场里成为"被参照对象",而不是"追赶对象"。
但是!请注意一个非常重要的点。
R1 的真正意义,不在于它"打败了"o1 (事实上严格意义上 R1 在某些 benchmark 上略弱于 o1 ,在另一些上略强于 o1 ,整体大致平手)。
R1 的真正意义在于:
它把"前沿推理能力 + 完全开源 + 允许蒸馏"这三件事,第一次在同一个模型上同时做到了。
这等于直接告诉全世界:闭源公司能做到的事情,开源也能做到;美国公司能做到的事情,中国公司也能做到;而且我做完之后还把权重免费给所有人用。
我个人认为,2025 年 1 月 20 日,是过去十年里中国 AI 行业最重要的一天。 它的意义大于阿尔法狗赢李世石,大于 GPT-3.5 出圈,大于任何一次单独的"中国 AI 进展"新闻。
因为它第一次让全世界意识到:在 AI 这条赛道上,中国不是"会不会赶上"的问题,而是"已经平起平坐"的问题。
六、第四阶段( 2025.08 → 2025.12 ): V3.1 和 V3.2 , DeepSeek 默默进入了 Agent 时代
R1 之后, DeepSeek 进入了一个外界看起来"安静下来"的阶段。
但事实是,从 2025 年 8 月 到 2025 年 12 月 这四个月里, DeepSeek 完成了三件非常硬的工作:
第一件事: V3.1 ( 2025 年 8 月 21 日)
把 Think 模式 和 Non-Think 模式 直接整合进同一个模型。
也就是说,用户不再需要在"快速回答的聊天模型"和"深度思考的推理模型"之间切来切去,同一个模型可以根据任务自动选择是否进入深度思考状态。
这一点, OpenAI 是在 2025 年 8 月 7 日 的 GPT-5 上才公开实现的。 DeepSeek 仅仅 14 天后就拿出了开源版本。
第二件事: V3.2-Exp ( 2025 年 9 月 29 日)
引入 DeepSeek Sparse Attention ( DSA )。
这个技术的意义是:长上下文的推理成本进一步下降。官方公告里写得很直白——"性能与 V3.1-Terminus 持平,但 API 价格直接下降 50% 以上"。
我必须强调一下:在西方大公司还在不断涨价的 2025 年下半年, DeepSeek 做了一次直接打 5 折的开源版本。
这种节奏,是中国制造业出海最熟悉的打法——性能不输你,价格只有你一半,权重还免费给你。
第三件事: V3.2 正式版( 2025 年 12 月 1 日)
官方公告里有一句话,我看到的时候停顿了很久:
"This is the first DeepSeek model that integrates thinking directly into tool-use."
(这是 DeepSeek 第一个将思维直接整合进工具调用的模型。)
这句话翻译成产业语言就是:DeepSeek 第一次正式做出了一个"会一边思考、一边主动调工具去完成任务"的模型。
这就是过去一年大家一直在讨论的 Agent (智能体)。
到这一步, DeepSeek 的产品形态已经不再是"一个聊天机器人",而是 "一个会自己安排步骤、调用工具、解决问题的数字工作者"。
这一点,恰好和 Anthropic Claude Sonnet 4.5 、 OpenAI GPT-5 的方向高度一致。也就是说:
从 2025 年 12 月开始, DeepSeek 已经和 OpenAI 、 Anthropic 站在了同一条主战场上——agentic AI 。
而且全部开源。
七、第五阶段( 2026.04 ): V4 双旗舰, DeepSeek 完成体系化
2026 年 4 月 24 日, DeepSeek 上线了 V4 Preview,分成两个版本:
|
版本 |
总参数 |
激活参数 |
上下文 |
定位 |
|---|---|---|---|---|
|
DeepSeek-V4-Pro |
1.6T | 49B | 1M |
上限旗舰 |
|
DeepSeek-V4-Flash |
284B | 13B | 1M |
高效主力 |
这一代有三个非常关键的变化,我必须分开讲。
变化一: DeepSeek 从"单一旗舰"走向"分层旗舰"
这一点非常重要。过去 DeepSeek 都是一次发布一个最强版本,大家用就是了。但 V4 这一代, DeepSeek 第一次同时发布了两个旗舰:
V4-Pro:把上限往上推,对标西方最贵闭源模型
V4-Flash:把成本往下压,对应高频、低预算、大规模部署场景
这个分层逻辑,跟 Anthropic 的 Opus + Sonnet 、 OpenAI 的 GPT-5 + GPT-5 mini 是一个思路。
也就是说,DeepSeek 已经具备了一个成熟旗舰公司的产品体系结构。
变化二: 1M 上下文,从"卖点"变成"标配"
V4 这一代官方原话是:"1M context is now the default."
请你品一下这句话。
过去几年, 1M 上下文几乎是 GPT-4.1 、 Gemini 1.5/2.0/3.0 、 Claude 这些闭源顶级模型的特权。开源模型最多做到 128K 、 256K ,能跑到 1M 的少之又少。
DeepSeek 这一句话的潜台词是:长上下文不再是顶级闭源模型的特权,而是开源旗舰的标准配置。
这件事的意义,远远不止"长一点"那么简单。它意味着任何一家中国公司、任何一家发展中国家的公司、任何一所大学的实验室,都可以以接近零成本拿到一个 1M 上下文的旗舰模型。
这对全球 AI 产业的"准入门槛",是一次实打实的拉低。
变化三:扩张方式仍然非常克制
我们再看一下 V4 相对 V3 的扩张比例:
总参数: 671B → 1.6T ,约 2.4 倍
激活参数: 37B → 49B ,约 1.32 倍
训练 tokens : 14.8T → 32T+,约 2.16 倍
请注意中间那一行:激活参数只涨了 1.32 倍。
也就是说, DeepSeek 在 V4 这一代,总参数翻了 2.4 倍,但用户实际推理时承担的计算量只多了 1.32 倍。
这种"克制",从 V2 一直延续到 V4 ,没有一代例外。
这就是我在文章一开始说的那个核心判断:
DeepSeek 走的从来不是"暴力堆参数"的路线,而是一条"模型容量可以涨,但用户感知成本不能涨太快"的路线。
把前面讲的所有版本拉到同一条时间线上看,会非常直观:
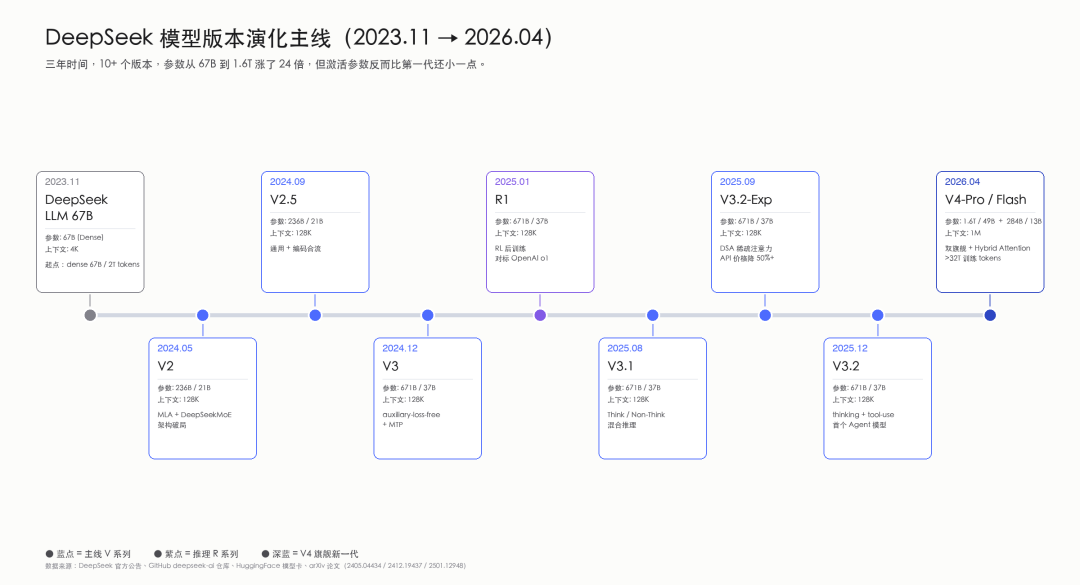
这张图我特别想强调的是:从 V3 到 V3.2 ,整整十一个月, 671B / 37B 的规模没有再变。但在这十一个月里, DeepSeek 把 R1 的推理能力、 V3.1 的 Think/Non-Think 双模式、 V3.2-Exp 的 DSA 稀疏注意力、 V3.2 的 thinking + tool-use 全部上了线。
这种"参数不动、能力一直长"的节奏,是中国制造业最熟悉的味道——不靠一次性的大动作惊艳全场,而是靠每两三个月一次的扎实迭代,把对手慢慢拉开。
八、把 DeepSeek 放到全球大模型版图里看
写到这里,我想做一组对比,把 DeepSeek 同时期的全球主要玩家放在一起看。
第一组对比: OpenAI
OpenAI 这两年的产品演化路径大致是:
2024.05.13: GPT-4o (多模态旗舰)
2024.07.18: GPT-4o mini
2024.09.12: o1-preview / o1-mini (推理模型独立成线)
2024.12.17: o1 API 生产化
2025.02.27: GPT-4.5
2025.04.14: GPT-4.1 (强调 coding + tool use + 1M context )
2025.08.07: GPT-5 (统一路由系统)
2026.04.23: GPT-5.5 (强调真实工作场景的稳定执行)
这是一条非常典型的闭源旗舰路线:每一代都更强、更贵、更封闭、更产品化。
第二组对比: Anthropic
Anthropic 走的是另一条路——把 Sonnet 这个中档模型做成大多数人的默认主力:
2024.10.22: Claude 3.5 Sonnet 升级 + computer use
2025.05.22: Claude Sonnet 4 发布
2025.08.12: Sonnet 4 开放 1M context
2025.09.29: Claude Sonnet 4.5 (最强 coding/agent/computer use )
2026.02.05: Claude Opus 4.6
2026.02.16: Claude Sonnet 4.6 成为 Free / Pro 默认模型
Anthropic 的核心打法是:"旗舰能力,中档价格,默认主力。"
第三组对比: Meta Llama
Meta 在这场竞赛里其实并没有掉队,相反节奏很密集:
2024.04.18: Llama 3
2024.07.23: Llama 3.1
2024.09.25: Llama 3.2
2024.12.06: Llama 3.3 70B
2025.04.05: Llama 4 (原生多模态 + MoE , Scout 17B/109B/10M context , Maverick 17B/400B/1M context )
但是说实话, Meta 这两年最大的问题不是技术,而是叙事中心地位的丢失。
过去开源大模型圈言必称 Llama ,现在言必称 DeepSeek 。这种叙事中心的迁移,本身就是中国 AI 产业崛起的一个非常重要的信号。
把这几条线放一起看
如果你把 OpenAI 、 Anthropic 、 Meta 、 DeepSeek 这四条线放一张时间轴上,会发现一个非常有意思的现象:
2024 年的开源大模型叙事中心还是 Meta Llama , 2025 年逐渐转向了 DeepSeek , 2026 年已经基本完全在 DeepSeek 这边。
这是一次发生在三年之内的"开源大模型话语权转移"。
而这一次转移,第一次让中国公司站在了开源叙事的中心位置。
这件事,我个人认为是过去十年中国科技产业最重要的几个事件之一。值得用很长的篇幅来记一笔。
九、为什么我说 DeepSeek 的故事,是一个非常"中国"的故事
写到这里,我想讲一下我个人对 DeepSeek 这条路线的几个判断。
第一, DeepSeek 是被"算力受限"逼出来的工程美学
这一点必须讲清楚。
过去几年,美国对中国半导体行业的管制是越来越严的:
2022 年 10 月:禁止向中国出口 A100 、 H100
2023 年 10 月:堵住 A800 、 H800 这些"特供版"
2024 年:进一步限制 HBM 、先进封装、 EDA 工具
2025 年:把 H20 也纳入限制范围
也就是说, DeepSeek 从成立第一天起,就是在一个"算力被持续卡脖子"的环境里做大模型。
OpenAI 可以用十万张 H100 集群训 GPT-5 , DeepSeek 就用不了。
那怎么办?
DeepSeek 给出的答案是:既然我没法跟你比"暴力规模",那我就在架构、在算法、在训练效率、在推理效率上把每一分算力都榨干。
这就是 V2 的 MLA 、 V3 的 MTP + 无辅助损失负载均衡、 V3.2 的 DSA 、 V4 的 Hybrid Attention 这些技术决策的真正背景。
我们再看一下数字:
DeepSeek-V3 的训练成本:约 557.6 万美元(按 H800 GPU 小时计算, 2048 张 H800 , 278.8 万 GPU 小时,每小时约 2 美元,这是官方论文里直接写的数字)
据 SemiAnalysis 等机构估算, OpenAI GPT-4 当年训练成本约 6300 万美元 量级
也就是说,DeepSeek-V3 用了 GPT-4 大约 1/10 的训练成本,做出了一个性能基本对标甚至部分超越 GPT-4 的开源模型。
这里我必须补一句很重要的话:557.6 万美元只是"最后一次成功训练"的成本,不包含前期研究、架构试错、数据清洗、人员工资这些"隐形大头"。如果把所有研发成本都摊进来, DeepSeek 真实的累计投入肯定是这个数字的几十倍以上。但即便如此,相对于 OpenAI 、 Anthropic 那种"一年烧几十亿美元"的研发节奏, DeepSeek 的成本控制还是非常惊人的。
这就是中国制造业最熟悉的逻辑:性能不输你,成本只有你的零头。
第二, DeepSeek 的开源策略是有战略层面思考的
这一点也很重要。
DeepSeek 几乎所有主力模型都是 MIT License 开源,明确允许蒸馏、允许商用、允许二次微调。这在西方主要大模型公司里是非常少见的。
为什么 DeepSeek 要这么开放?
我个人的判断有三层:
1.
拉低全球准入门槛。一旦顶级开源模型免费可用,西方闭源公司的"高价护城河"就会被持续侵蚀。
2.
建立全球开发者生态。今天全球有几十万开发者在 DeepSeek 模型上做微调、做蒸馏、做应用,这是一个庞大的、不需要支付招聘成本的"分布式研发网络"。
3.
绕开地缘政治封锁。模型权重一旦开源放上 HuggingFace ,美国政府想要"封禁"基本是不可能的。这是一种非常聪明的战略对冲。
第三, DeepSeek 的节奏感,是中国制造业最擅长的"持续迭代"
我最后再讲一点,是我从写制造业文章里学到的:
中国产业最大的护城河,从来不是某一次的"奇袭",而是"持续迭代"的能力。
华为是这样,比亚迪是这样,宁德时代是这样, DeepSeek 也是这样。
我们看一下 DeepSeek 三年里的发布节奏:
2023.11 : DeepSeek LLM
2024.05 : V2
2024.09 : V2.5
2024.12 : V2.5-1210 + V3
2025.01 : R1
2025.03 : V3-0324
2025.05 : R1-0528
2025.08 : V3.1
2025.09 : V3.1-Terminus + V3.2-Exp
2025.12 : V3.2 + V3.2-Speciale
2026.04 : V4-Pro + V4-Flash
平均下来,DeepSeek 大概每两到三个月就会发一次主要更新。这种密度,全球 AI 公司里只有 OpenAI 和 Anthropic 能比。
而且这些更新,没有任何一次是"为了发布而发布"的水货。每一次都对应着明确的能力突破或成本下降。
这就是中国制造业的味道——慢一点没关系,但每一步都要踩实,每一代都要有提升,没有水版本。
十、对中国 AI 产业意味着什么?
写到这里,我想把视角从 DeepSeek 这一家公司,扩大到整个中国 AI 产业。
DeepSeek 不是孤例。我们来看一下 2026 年这个时间点上,中国大模型行业的真实格局——这一点很多自媒体没有讲清楚,我尽量讲准确。
还在基座大模型主赛道上的,主要是这几家:
DeepSeek:本文主角,开源旗舰路线, V4-Pro / V4-Flash 双旗舰
阿里通义 Qwen 系列:覆盖从 0.5B 到几百 B 的全尺寸开源。在 HuggingFace 全时累计下载榜上,Qwen3-VL-2B-Instruct 是排名第 2 的开源模型,累计下载约 1.87 亿次(仅次于 sentence-transformers 这种基础工具类模型);最新的 Qwen3.6-35B-A3B 单月下载量超过 250 万次。整个 Qwen 系列在 HF Trending 榜上常年以多个尺寸版本同时在线
月之暗面 Kimi: K2 系列以 460 万美元训练成本创下行业新纪录, K2.5 已采用原生多模态架构, 2026 年正在筹备港股 IPO
智谱 GLM 系列:2026 年 1 月 8 日已在港交所上市,募资约 43 亿港元,成为国内首家上市的独立大模型公司
MiniMax:2026 年 1 月 9 日紧随其后登陆港交所主板,首日大涨 109%,市值一度突破 1000 亿港元
而曾经的"大模型六小龙"里,已经有几家主动收缩或转型:
百川智能:从通用大模型赛道收缩到 AI 医疗垂直领域,员工从 500 人砍到 200 人以下,新发布的 Baichuan-M3 医疗大模型在 HealthBench 全球评测里拿到第一
零一万物:李开复在 2025 年初公开承认"只有大厂能烧超大模型",把预训练团队整体并入阿里通义,自己转向小参数模型 + 应用层
这一点,我必须客观地说一下我的看法:
行业里曾经一度认为"大模型六小龙"是中国 AI 的希望。但事实证明,基座大模型这条路,比大家想象的要残酷得多。 它本质上是一个"算力 + 数据 + 工程团队 + 长期亏损"的资本游戏,绝大多数初创公司都跑不下去。
百川和零一的退出,不是失败,而是理性选择——他们意识到自己在大模型基座上拼不过 DeepSeek 、阿里、字节,于是要么转向垂直领域(百川转 AI 医疗),要么主动让出基座研发交给大厂(零一并入阿里)。
这反过来也说明了 DeepSeek 的不易——它是为数不多扛住了这种"基座大模型烧钱内卷"的中国民营公司。背后那家叫"幻方量化"的母公司,用量化交易赚来的钱在硬扛,这是 DeepSeek 能跑下去的一个关键背景。
也就是说, 2024-2026 这三年,中国并不是只有一家 DeepSeek 能打,而是已经形成了一个相对收敛、但依然非常有竞争力的"中国大模型梯队": DeepSeek + 阿里 + 字节豆包 + Kimi + 智谱 + MiniMax ,加上百度文心、腾讯混元、华为盘古等大厂自研模型。
这是非常关键的产业现象。它说明:
1.
中国在大模型这条赛道上,已经形成了完整的人才梯队和技术积累。
2.
中国大模型公司已经不再依赖一两个明星科学家,而是有了体系化的工程能力。
3.
中国开源模型已经在全球 HuggingFace 榜单上占据了头部位置。这一条我专门去 HuggingFace 实际查了一遍,把数据贴出来给你看:
HF Trending 榜(实时热度)当前 Top 30 里,中国团队的模型大致情况:
DeepSeek-V4-Pro 高居 Trending 榜第 1 位( 862B ,单周下载 45.7 万次)
DeepSeek-V4-Flash 排在前 10 ( 158B ,单周下载约 41 万次)
Qwen3.6-27B 、 Qwen3.6-35B-A3B 等多个 Qwen 官方版本在榜(其中 35B-A3B 月下载 258 万次, 27B 月下载 120 万次)
由 unsloth 、 z-lab 、 HauhauCS 等社区团队基于 Qwen3.6 做的 GGUF/DFlash/Uncensored 衍生版本,在 Trending 榜上又占了好几个席位
Kimi-K2.6(月之暗面, 1.1T 参数,单周 75.6 万次下载)
小米 MiMo-V2.5-Pro 和 MiMo-V2.5( 1T 和 311B 两个版本同时在榜)
商汤 SenseNova-U1、蚂蚁百灵 Ling-2.6-flash 和 Ling-2.6-1T、腾讯 AngelSlim 等
合计算下来,Trending 前 30 里有大约 14-15 个席位是中国团队的开源模型,占比接近一半。剩下的位置主要被 Google Gemma-4 、 Mistral 、 NVIDIA Nemotron 、 IBM Granite 、 OpenAI (一个安全工具)等瓜分。
这个数据,三年前是完全不可想象的——那时候 Trending 榜几乎全是 Meta Llama 、 Mistral 、 Stability AI 、 Falcon 这些西方团队的模型。
这就是过去三年里,悄悄发生的一场全球 AI 力量再分配。
十一、写在最后
文章写到这里,已经接近 6000 字。我做一个简单的收尾。
我想说,DeepSeek 的故事,本质上不是一个"AI 公司逆袭"的故事,而是一个非常中国式的产业故事:
一开始没人看好( DeepSeek LLM 那一代基本无人问津)
在算力被卡脖子的环境里坚持做事( V2 → V3 → R1 全程都是 H800/H20 阶段)
用工程效率和成本控制弥补硬件劣势( MLA 、 MoE 、 DSA 、 Hybrid Attention 全是冲着省算力去的)
一步一个脚印,没有水版本(三年发了 10+ 个有意义的版本)
不计代价地开源,让全球开发者跟你站在一起( MIT License + 允许蒸馏)
直到某一天,全世界突然发现,原来你已经走到了第一阵营( R1 出圈那一刻)
这条路,是不是听起来很熟悉?
是的,这就是华为做 5G 的路,是比亚迪做电动车的路,是宁德时代做动力电池的路,是大疆做无人机的路。
这是中国制造业过去三十年走过的同一条路,只不过这次走在大模型赛道上。
我个人非常乐观地相信, DeepSeek 的故事,只是中国 AI 产业全面崛起的一个开始,而不是高潮。
接下来五年,我相信会看到:
1.
中国大模型公司在全球开源榜单上长期占据头部位置
2.
中国 AI 应用层全面爆发,覆盖编程、办公、教育、医疗、制造、政务、科研
3.
中国 AI 芯片(华为昇腾、寒武纪、壁仞、燧原、摩尔线程)逐步替代英伟达,形成完整的国产 AI 算力体系
4.
中国 AI 模型 + 中国 AI 芯片 + 中国 AI 应用形成完整闭环,构成一个不依赖美国、且对全球开发者开放的"第二套 AI 体系"
这就是我从 DeepSeek 这一家公司身上,看到的更大的图景。
我之前说过一句话,今天再说一遍:
中国科技产业的崛起,从来不是靠某一次出圈,而是靠一群在算力被卡、市场被压、舆论被唱衰的环境里,依然每天踏踏实实写代码、训模型、跑实验、迭代版本的中国人。
DeepSeek 只是其中一家。
后面还会有更多。 最后感谢 app.infinisynapse.com 的助力,没有它,就没有这篇文章。
参考资料
本文所有 DeepSeek 模型的参数、发布日期、训练数据、架构信息,全部基于以下一手官方信源:
DeepSeek 官方公告: https://api-docs.deepseek.com/news
DeepSeek GitHub 组织: https://github.com/deepseek-ai
DeepSeek HuggingFace 主页: https://huggingface.co/deepseek-ai
DeepSeek-V2 论文: https://arxiv.org/abs/2405.04434
DeepSeek-V3 论文: https://arxiv.org/abs/2412.19437
DeepSeek-R1 论文: https://arxiv.org/abs/2501.12948
DeepSeek-V4 Preview 公告: https://api-docs.deepseek.com/news/news260424
对照公司:
OpenAI 官方: https://openai.com/news
Anthropic 官方: https://www.anthropic.com/news
Meta Llama 模型卡: https://github.com/meta-llama
文中训练成本相关数字,参考自 SemiAnalysis 公开报告与各公司官方披露。如有出入,以官方为准。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)