大学生如何用Claude Code实现弯道超车?从宿舍写代码到科研论文,我的完整踩坑实录
一个认真的提醒:Claude Code是工具,不是拐杖最后说一件我必须说的事。我见过两种用Claude Code的大学生:第一种:让Claude Code做所有事情,自己什么都不懂,三个月后跟没用一样,因为啥也没学会。第二种:用Claude Code做所有"可以自动化"的事,把节省下来的时间用来深入理解"为什么",三个月后能力提升肉眼可见。
开篇:那个让我沉默三秒钟的瞬间
2026年4月,我在帮一个朋友面试一名大三学生。
简历上写着"Python基础、机器学习了解",我们给了他一道真实的数据分析题——清洗一个有脏数据的CSV、跑个线性回归、输出报告。
预期解题时间:45分钟。
他用了12分钟。
代码是在Claude Code里生成的,但他全程在看代码、改参数、解释为什么要用这个方法。当我问"这里为什么不用StandardScaler而是MinMaxScaler",他回答得头头是道。
我当时只说了一句:"明天来上班吧。"
这不是在吹Claude Code多厉害,而是在说一件2026年正在发生的事:懂得用AI工具的大学生,和不懂用的,已经不在同一个起跑线上了。
先说一下国内订阅claude code确实有些困难,想尝试的朋友可以去找一个靠谱的网站,这里推荐一个:claudemax.shop

先说清楚:Claude Code是什么,跟Claude聊天版有什么不一样
很多人把Claude Code和Claude.ai的网页聊天混为一谈。这是两个完全不同的东西。
Claude.ai 是对话界面,你输入问题,它输出文字,就跟打字聊天一样。
Claude Code 是一个跑在你电脑终端里的AI编程Agent。它不住在任何编辑器里,直接在终端运行。你描述一个需求,它自己规划步骤、读文件、写代码、执行命令、验证结果。
更关键的区别:
- Claude.ai:告诉你"怎么做"
- Claude Code:帮你把事情做完
比如你说"帮我分析一下这100篇论文的摘要,找共同主题"——Claude.ai会给你一套方法论;Claude Code会直接去读那100个PDF,写Python脚本,跑NLP,输出聚类结果,把图画好放在你面前。
Claude Code在2025年2月公开发布研究预览版,5月正式GA。GA后仅6个月,达到10亿美元年化收入。
好,现在说大学生最关心的问题:要花多少钱?
钱的问题先说清楚:有免费方案,也有聪明的省钱方式
Claude Code本身是免费的,你真正花钱的是它调用的AI模型。如果能找到免费的模型API,CC就等于白嫖。
具体来说,大学生有四种方案:
方案一:零成本白嫖(适合入门期)
把Claude Code的后端换成国内免费模型API——火山方舟(字节旗下)、硅基流动都有免费额度。代价是模型能力弱一些,但做课程作业绰绰有余。
# 接入国内替代模型
export ANTHROPIC_BASE_URL=“your url“
export ANTHROPIC_API_KEY=“你的火山API_KEY"
claude # 正常启动,后端已换
方案二:Claude Pro订阅(推荐的主力方案)
约150元/月(2026年5月汇率),使用claude-sonnet-4-6,足够应付大多数学习和科研场景。这大概是两天的饭钱,性价比极高。
方案三:API按量付费(适合项目冲刺期)
不订阅,直接充值API额度,用多少花多少。一般月耗150-300元,视任务强度而定。比订阅更灵活,期末冲刺时特别合适。
方案四:Claude Max(毕业论文/大创冲刺)
最贵但最强,800元+/月,Opus 4.7基本无限用。真正做毕业论文数据分析的时候,花两个月Max订阅换来的生产力提升,远比这钱值。
安装:比你想象的简单
# 第一步:确保有Node.js(去官网下载)
node --version # 确认版本 >= 18
# 第二步:安装Claude Code
npm install -g @anthropic-ai/claude-code
# 第三步:配置API Key
export ANTHROPIC_API_KEY=你的Key # 临时设置
# 或者写入 ~/.bashrc / ~/.zshrc 永久生效
# 第四步:启动!
claude # 就这样,进入交互界面了
整个过程5分钟以内。遇到权限问题用sudo,遇到网络问题配代理,这两个坑覆盖了95%的安装问题。
配置CLAUDE.md(很重要,大多数人不知道):
在你的项目文件夹里创建一个CLAUDE.md文件,告诉Claude Code关于这个项目的一切:
# 我的毕业论文项目
## 研究背景
这是一篇关于A股市场散户行为的量化研究论文,导师是XX教授。
## 数据说明
- data/raw/:原始交易数据,CSV格式,包含2020-2025年数据
- data/processed/:清洗后的数据
- 主要变量:日收益率、换手率、市值分组
## 代码规范
- 全部用Python,风格遵循PEP8
- 统计分析用statsmodels,机器学习用scikit-learn
- 图表统一用matplotlib + seaborn,学术风格
## 注意事项
- 不要修改raw目录下的原始数据
- 每个脚本开头必须有注释说明用途
这个文件让Claude Code"记住"你的项目背景,不用每次都重新解释。
场景一:课程学习——从"看不懂报错"到"能改代码"
这是大学生用Claude Code最高频的场景,也是最容易上手的起点。
传统的痛苦:敲了半天代码,报错了,看不懂,百度了半小时,找到一个Stack Overflow答案,看不太懂,复制粘贴,又报错了……
用Claude Code之后:
# 直接在终端问
claude "解释一下这个报错是什么意思,怎么修复"
# 或者把整个代码文件扔给它
claude "帮我读这个文件,找出为什么跑不通" @homework.py
# 最有效的学习方式:让它一边解释一边改
claude "修复这个bug,但要逐行注释解释你在做什么,我要学会这个方法"
一个让我印象深刻的真实对话(根据我观察到的使用案例还原):
一个学数据结构的大二学生,对着一道二叉树遍历的题想了一个小时没头绪。他用Claude Code这样问的:
我理解了前序、中序、后序的定义,但我写不出来代码。
不要直接给我答案,帮我一步步思考:
1. 前序遍历的"根-左-右"对应到代码里是什么逻辑?
2. 为什么要用递归?
3. 递归的基本情况(base case)是什么?
Claude Code没有直接给代码,而是引导他思考,20分钟后他自己写出来了。
这才是正确的用法——让AI成为你的苏格拉底,而不是你的代笔机器。
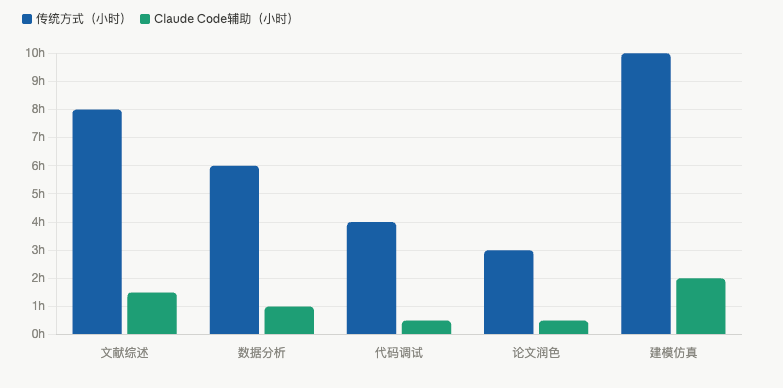
场景二:数据分析——大学生科研的刚需
不管你是理工科做实验数据、文社科做问卷数据,还是经济学做面板数据,数据分析都是大学生科研绕不过去的坎。
这也是Claude Code最能帮上忙的地方。
完整的工作流长这样:
# 第一步:告诉CC你有什么数据和目标
claude "我有一个问卷调查数据集,共300个样本,
变量包括:年龄、性别、收入水平、消费意愿(1-5分)。
我想做:1.描述性统计 2.不同收入组的消费意愿差异检验 3.回归分析
帮我规划分析步骤,先不要写代码"
# 第二步:CC生成分析方案,你确认后再执行
claude "方案看起来没问题,现在帮我写代码,
每一步都要输出结果并解释统计意义"
# 第三步:出图
claude "把回归结果做成学术期刊风格的图表,
要包含置信区间,颜色用黑白灰,导出为PDF"
一个具体的Python分析示例(Claude Code会帮你生成类似这样的代码):
import pandas as pd
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据
df = pd.read_csv('survey_data.csv')
# 描述性统计
print("=== 描述性统计 ===")
print(df.describe())
# 不同收入组的消费意愿差异
low_income = df[df['income'] == '低']['consumption_willingness']
high_income = df[df['income'] == '高']['consumption_willingness']
# 独立样本t检验
t_stat, p_value = stats.ttest_ind(low_income, high_income)
print(f"\n=== t检验结果 ===")
print(f"t统计量: {t_stat:.4f}, p值: {p_value:.4f}")
print("结论:", "两组存在显著差异" if p_value < 0.05 else "两组无显著差异")
# 可视化
plt.style.use('seaborn-v0_8-white')
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 箱线图
df.boxplot(column='consumption_willingness', by='income', ax=axes[0])
axes[0].set_title('不同收入组消费意愿分布', fontsize=12)
# 回归散点图
sns.regplot(x='age', y='consumption_willingness', data=df, ax=axes[1])
axes[1].set_title('年龄与消费意愿关系', fontsize=12)
plt.tight_layout()
plt.savefig('analysis_result.pdf', dpi=300, bbox_inches='tight')
print("\n图表已保存为 analysis_result.pdf")
关键是:Claude Code会自动帮你处理缺失值、异常值、数据类型问题——这些让新手抓狂的前处理工作,CC基本能全自动搞定。
场景三:论文写作——真正帮你做"脏活累活"的部分
先说清楚边界:Claude Code不能替你写论文,但可以替你做所有论文写作中的"脏活"。
能做的(合理、高效):
- 批量阅读和整理文献
- 格式化参考文献
- LaTeX排版
- 检查逻辑漏洞
- 润色英文表达
- 数据图表制作
不能做的(学术不端,别想了):
- 替你生成观点和论证
- 捏造实验数据
- 伪造文献引用
文献管理的实战用法:
# 让CC批量处理PDF文献
claude "帮我读取literature/文件夹下所有PDF,
对每篇文章提取:
1. 核心研究问题
2. 研究方法
3. 主要发现
4. 与我的论文主题(消费者行为)的相关度评分(1-10)
整理成一个表格"
Claude Code可以运行Python、R等脚本进行数据分析,支持上传整本著作或大量文献进行分析,还可以通过脚本实现重复性任务的自动化。
LaTeX排版(理工科救星):
claude "把这份Word格式的论文草稿转换为LaTeX,
使用IEEE会议模板,参考文献格式用BibTeX,
把图片插入到对应的章节"
这个操作以前需要你自己学LaTeX,至少花两天时间。现在你只需要检查输出结果是否正确。
英文润色(毕业生必备):
claude "帮我润色这段英文abstract,
要求:学术风格,不要过度华丽,
保持我的原始意思,标注修改了哪些地方和修改原因"
场景四:大创和竞赛——比同学快半个身位的秘诀
大创和竞赛项目的核心竞争力是什么?
交付速度 + 可运行的Demo。
很多评委看的不是报告有多漂亮,而是你能不能现场演示一个真正跑通的系统。
Claude Code在这里的价值是:把原型开发时间从2周压缩到2-3天。
一个实际案例(我朋友团队的经历):
他们做的大创项目是"基于NLP的求职简历智能分析系统"。
- 传统做法:学HTML/CSS/Flask/NLP,每个人学2周,然后开始写……3个月后可能出来一个残缺版
- 用Claude Code:第一天搭好Flask后端,第二天前端界面,第三天NLP分析模块,第四天联调测试,第五天写报告
# 第一天,搭后端
claude "帮我创建一个Flask Web应用骨架,
功能是接收上传的简历PDF,返回JSON格式的分析结果。
包含:API路由设计、文件上传处理、错误处理"
# 第二天,前端
claude "帮我写一个简洁的前端页面,
包含文件上传按钮、分析结果展示区域,
用Bootstrap 5,移动端适配"
# 第三天,NLP模块
claude "帮我实现简历分析核心功能:
用spacy提取技能词汇、教育背景、工作经历,
与岗位JD做匹配度计算,输出结构化JSON"
五天出来一个能现场演示的系统,这在2023年以前几乎不可能。
学习路径:从入门到真正会用,三个月够了
我给大学生的建议是分阶段推进:
第一天:装好,跑一个最简单的任务
不要一上来就想做大项目。第一天只做一件事:让Claude Code帮你解释一个你看不懂的代码报错。成功了,你就完成了最重要的心理关卡——"原来这东西真的好用"。
第1-2周:用它学代码
每次遇到不懂的东西,不要先百度,先问Claude Code。让它解释,让它举例,让它出题考你。这阶段不要让它帮你写大段代码,重点是理解。
第3-4周:处理数据
找一个你课程相关的数据集(Kaggle有很多免费的),用Claude Code帮你做完整的探索性数据分析(EDA)。这一步会让你产生巨大的成就感。
第2个月:科研辅助
找一篇你最近在读的论文,用Claude Code帮你批量整理相关文献,复现论文里的实验,分析结论是否成立。这一步会让你的科研效率产生质的变化。
第3个月:独立项目
用前两个月积累的能力,做一个你自己想做的小项目,或者投一个竞赛,或者用于毕业设计。这一步是检验你是否真的掌握了的时刻。
避坑指南:我见过大学生最常犯的五个错误
错误一:直接要答案,不要理解
"帮我写一道链表反转的代码"——Claude Code会写,但你啥都没学到。
正确姿势:先让它给提示,自己写,再让它审查。
错误二:用它生成论文内容
这是学术不端。而且Claude Code生成的学术内容往往有幻觉(hallucination),引用的文献可能根本不存在。
不要100%轻信AI的回答,它会胡说八道,记得多检查。
错误三:不写CLAUDE.md
没有上下文,Claude Code每次都要重新了解你的项目,大量时间浪费在重复解释上。花20分钟写一个好的CLAUDE.md,之后每次会话都受益。
错误四:用最贵的模型做所有事
很多人为了省钱或追求速度会用Haiku或Sonnet,但要根据任务复杂度选择:简单任务→Haiku;中等复杂度→Sonnet;高复杂度→Opus + Thinking。
课程作业用Haiku就够,真正的论文数据分析再换Opus。
错误五:不用Plan Mode
遇到复杂任务(比如"帮我重构整个项目结构"),先按Shift+Tab切换到Plan Mode,让Claude Code只读不写,先把方案给你看,确认没问题再执行。
Plan Mode的特点:Claude只执行读取操作,不会修改任何文件,适合安全地探索不熟悉的代码。
直接Auto-Accept风险极高,它可能删错文件。

我见过的真实案例:用Claude Code完成毕业论文数据部分
一个金融专业大四学生,毕业论文做的是A股市场的事件研究(Event Study),需要:
- 从Wind数据库导出5年的股价数据(5000+行CSV)
- 计算每个事件窗口的异常收益率(CAR)
- 统计显著性检验
- 画出3张学术风格图表
这部分工作如果全手动,对他来说估计要两周(他Python不太熟)。
他用Claude Code的过程:
# 第一步:数据理解
claude "帮我读取这个CSV,告诉我数据结构和质量,有没有缺失值异常值"
# 第二步:计算CAR
claude "帮我实现事件研究的CAR计算:
- 事件窗口 [-10, +10]
- 估计窗口 [-120, -11]
- 用市场模型估计正常收益率
- 输出每个公司每个事件的CAR值"
# 第三步:统计检验
claude "对CAR值做t检验和BMP检验,
告诉我在哪些时间窗口统计显著"
# 第四步:出图
claude "画三张图:CAR时间序列图、截面箱线图、显著性热力图,
学术黑白风格,可以投Journal of Finance那种"
实际用时:两天(其中大量时间花在理解结果和调整图表风格上)。
论文最终通过了,他说:"数据分析部分我完全理解,答辩时导师问了很多细节问题我都答上来了,因为我全程在看CC在做什么,不是无脑复制。"
这才是用Claude Code的正确姿势——理解每一步,掌控全程,让AI处理执行,人来做判断。
一个认真的提醒:Claude Code是工具,不是拐杖
最后说一件我必须说的事。
我见过两种用Claude Code的大学生:
第一种:让Claude Code做所有事情,自己什么都不懂,三个月后跟没用一样,因为啥也没学会。
第二种:用Claude Code做所有"可以自动化"的事,把节省下来的时间用来深入理解"为什么",三个月后能力提升肉眼可见。
区别在哪里?
区别在于你是否坚持在理解之后再让AI执行。
"Claude Code帮我写了这段代码"没用。 "Claude Code帮我理解了这段代码,然后我让它优化它"才有用。
用Claude Code的目标是什么?不是让你的代码更多,而是让你学得更快、做得更好、花的冤枉时间更少。
时间省下来,是用来思考的,不是用来打游戏的(打游戏当然也没问题,但那跟Claude Code无关了)。
劳动节快乐,开始行动吧。装好Claude Code,从第一个报错开始。
附录:大学生实用命令速查表
| 场景 | 命令 |
|---|---|
| 解释报错 | claude "解释这个报错并给出修复方案:[报错信息]" |
| 代码审查 | claude "审查这段代码的逻辑和效率" @file.py |
| 数据分析 | claude "分析这个CSV的数据质量和主要特征" @data.csv |
| 文献整理 | claude "阅读这篇PDF,提取研究问题、方法、结论" @paper.pdf |
| 英文润色 | claude "润色这段英文,保持学术风格" |
| 进入计划模式 | 按 Shift+Tab 切换 Plan Mode |
| 压缩上下文 | /compact "保留数据分析部分的关键信息" |
| 清空会话 | /clear |
| 导出对话 | /export 论文讨论-2026-05.json |

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)