昇腾Atlas 800I A3部署deepseek-v4流程
本文介绍了在Ascend NPU环境下部署DeepSeek-V4-Flash-w8a8-mtp大语言模型的完整流程。首先通过docker_run.sh脚本创建容器,挂载必要的设备驱动和目录;然后下载模型文件并安装依赖;接着配置环境变量并启动vllm服务,设置并行参数和量化选项;最后通过curl命令调用API接口进行模型推理。整个过程详细说明了容器配置、模型部署和服务调用的关键步骤,适用于Ascen
1、创建docker容器
创建vim docker_run.sh内容如下
镜像:vllm-ascend:v0.13.0rc3-a3
export IMAGE=quay.io/ascend/vllm-ascend:v0.13.0rc3-a3
export NAME=deepseekV4-sj
docker run --rm \
--name $NAME \
--net=host \
--shm-size=1g \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci8 \
--device /dev/davinci9 \
--device /dev/davinci10 \
--device /dev/davinci11 \
--device /dev/davinci12 \
--device /dev/davinci13 \
--device /dev/davinci14 \
--device /dev/davinci15 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /etc/hccn.conf:/etc/hccn.conf \
-v /mnt/sfs_turbo/.cache:/root/.cache \
-v /data:/data \
-d $IMAGE tail -f /dev/null
~
给文件赋权限
chmod +x docker_run.sh
执行脚本
./docker_run.sh
使用docker ps查看创建的docker容器

使用以下命令进入容器
docker exec -it e9c600eff989 bash
2、下载模型
下载以下模型
https://www.modelscope.cn/models/Eco-Tech/DeepSeek-V4-Flash-w8a8-mtp
安装以下插件
pip install modelscope
下载到当前目录的dir文件夹中
modelscope download --model Eco-Tech/DeepSeek-V4-Flash-w8a8-mtp --local_dir ./dir

注:作者下载路径为:/data/share/models中(路径根据实际情况修改)
3、运行模型
创建运行脚本start.sh
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=10
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export ACL_OP_INIT_MODE=1
export ASCEND_A3_ENABLE=1
export USE_MULTI_BLOCK_POOL=1
export HCCL_BUFFSIZE=1024
export VLLM_ASCEND_ENABLE_FUSED_MC2=1
export VLLM_ASCEND_ENABLE_FLASHCOMM1=1
vllm serve /data/share/models/DeepSeek-V4-Flash-w8a8-mtp \
--host 0.0.0.0 \
--max_model_len 152000 \
--max-num-batched-tokens 8192 \
--served-model-name deepseek_v4 \
--gpu-memory-utilization 0.9 \
--max-num-seqs 64 \
--data-parallel-size 2 \
--tensor-parallel-size 8 \
--enable-expert-parallel \
--quantization ascend \
--chat-template /data/share/models/DeepSeek-V4-Flash-w8a8-mtp/chat_template.jinja \
--port 8005 \
--block-size 128 \
--async-scheduling \
--safetensors-load-strategy eager \
--compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY"}'\
--speculative-config '{"num_speculative_tokens": 1,"method": "deepseek_mtp"}' \
--additional-config '{"enable_cpu_binding": "true","multistream_overlap_shared_expert": false}'
4、调用
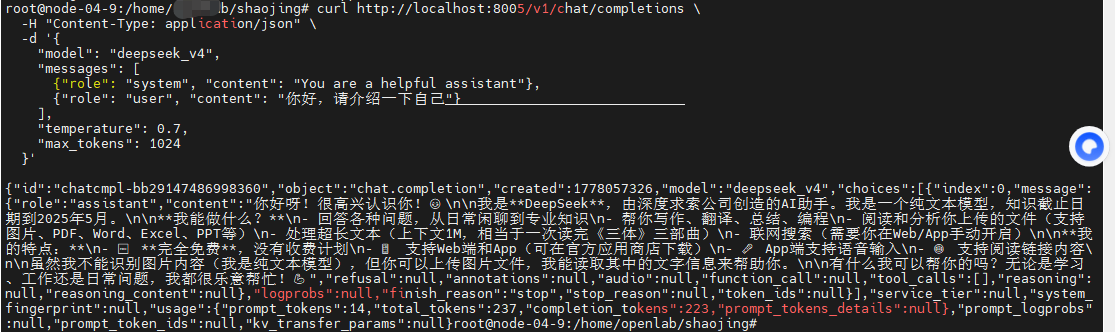
使用以下命令调用(ip可根据实际情况修改)
curl http://localhost:8005/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek_v4",
"messages": [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "你好,请介绍一下自己"}
],
"temperature": 0.7,
"max_tokens": 1024
}'

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)