基于 Harness 约束与 SDD 范式的全栈 AI 开发实践
在 Cursor 等成熟 IDE 中,开启多个 Agent 窗口(Tab),分别挂载前端与后端的 tasks.md,即可实现物理级别的并行开发。模型虽然具备通识编程能力,但在缺乏边界时,极易产出风格迥异、复用率极低的“外星代码”,反而成倍增加了 Code Review 与重构的成本。然而,在真实的企业级全栈开发中,如何确保 AI 产出的代码符合既有架构规范、具备高可维护性,成为了核心挑战。在严谨的
大家好,我是玄姐。
PS:
Harness 工程干货直播,欢迎点击预约,直播见。
在当今的 AI 辅助研发浪潮中,大模型展现出了惊人的代码生成能力。然而,在真实的企业级全栈开发中,如何确保 AI 产出的代码符合既有架构规范、具备高可维护性,成为了核心挑战。本文将围绕 Harness 思维、多仓管理与 SDD(规范驱动开发),完整拆解一套高采纳率的全栈 AI 研发流水线。
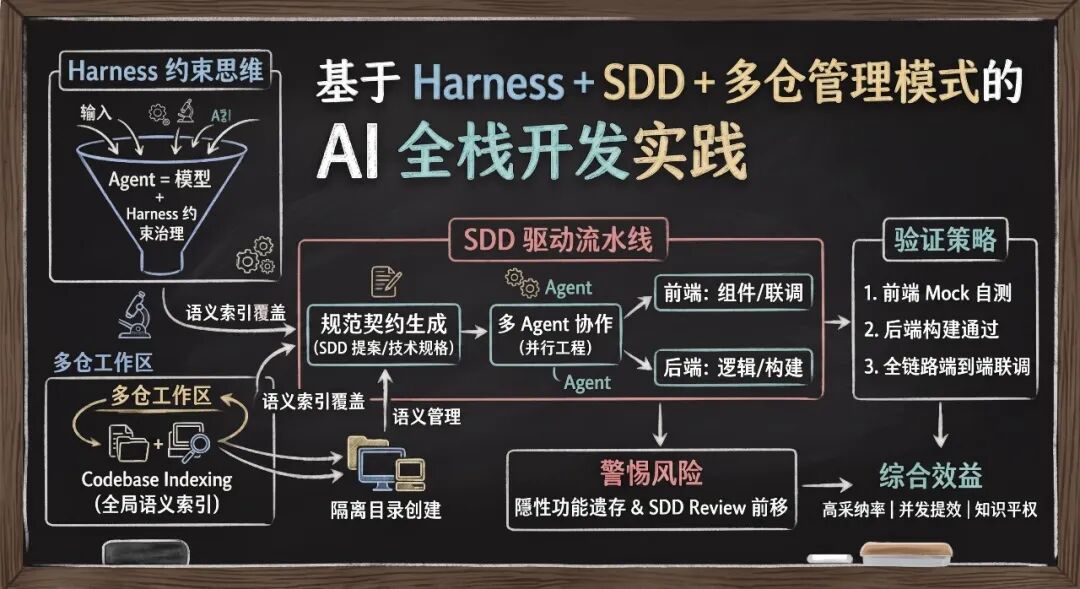
一、核心架构理念:Harness 约束思维
全栈 AI 开发最致命的陷阱,是让 AI 处于“零约束”状态下凭空创造。模型虽然具备通识编程能力,但在缺乏边界时,极易产出风格迥异、复用率极低的“外星代码”,反而成倍增加了 Code Review 与重构的成本。
Harness 思维的本质在于:Agent = 模型 + Harness 治理层。必须为 AI 提供明确的“模仿标的”与执行沙盒,让其在既有规范的约束下复刻逻辑,而非自由发挥。
| 原则 | 核心执行点 | 落地示例 |
|---|---|---|
| 找相似实现 | 在代码库中锚定功能最相似的现有模块作为全局参照物。 | 明确要求“结束语”功能参照“场景化欢迎语”的全栈链路。 |
| 复用优先 | 强制复用现存的组件、接口封装与底层数据结构。 | 沿用 greetingExtendInfo 数据结构,衍化出 closingExtendInfo。 |
| 模仿替换 | 鼓励“依葫芦画瓢”,维持 Controller/Service 分层原貌。 | 严格模仿已有 Service 层的事务处理与异常抛出机制。 |
| 锁定生成域 | 在提示词中精确框定需要参考的具体文件路径与代码行号。 | 指定前端入口:@FeatureTable/index.tsx:53-58。 |
提示词优化对比:❌ 不推荐(零约束): “请实现一个结束语管理的 CRUD 接口及前端页面。”
✅ 推荐(Harness 驱动): “请参照现有的'场景欢迎语'功能(后端接口
/api/v1/feature/list,前端入口@FeatureTable/index.tsx:53-58),实现'结束语'功能。数据结构、分层逻辑、命名规范必须保持一致。本次新增场景 code 为:categoryCode = "SCENARIO_CLOSING"。”
二、全栈工作区搭建与跨仓语义索引
前后端代码通常物理隔离在两个仓库中。在 AI 研发模式下,如果割裂上下文,接口字段对不上、类型错配将成为常态。将前后端合并至单一工作区,是实现高阶 Agentic 流水线的基础。
建立全局工作区的核心价值在于触发工具的 Codebase Indexing(代码库索引)功能。以 Cursor 为例,它会对工作区进行全局向量化嵌入。当 AI 接受指令时,它不仅能看到当前的单个文件,还能跨越仓库边界,顺藤摸瓜检索到“前端组件 -> 接口调用 -> 后端 Controller -> 数据库映射”的完整语义链路。
AI 辅助研发工具能力对比:
| 评估维度 | Cursor | Claude Code (CLI) |
|---|---|---|
| 语义索引机制 | 混合检索 (Grep + 向量化嵌入),理解深度高 | 依赖传统 Grep,准确度与模型基础推理强绑定 |
| 代码生成时效 | 极速响应(Tab 级或即时流式输出) | 中低速(复杂任务常需 3-5 分钟以上) |
| 上下文引用 | 极简(快捷键、拖拽、@ 文件或特定代码段) |
需手动输入绝对路径,无法精确定位代码段 |
| 多 Agent 协同 | 默认支持,多 Tab 并行互不干扰 | 需通过 JSON 手动配置注册 Subagent 子代理 |
| 适用场景建议 | 敏捷全栈迭代首选(推荐 Composer 模式) | 底层逻辑重构、重度依赖长上下文的深水区任务 |
三、SDD 驱动的全栈代码生成流
规范驱动开发(Specification-Driven Development, SDD)要求先有契约,后有代码。在全栈语境下,必须强制输出两套独立的 SDD 文档(前端与后端),并在生成代码前完成接口契约的双向对齐。
1. 全栈 SDD 提示词范式
以下是经过大量验证的 SDD 引导提示词,其核心逻辑在于隔离目录、对齐契约、防止 AI 擅自决策:
这是一个前后端全栈开发工作区,你需要设计技术接口方案,并为后续的前后端 Agent 编写开发依据。
规则:
请分别
cd到前后端应用目录中创建 SDD 文件,产出两份独立文档。后续将有两台 Agent 并行执行,因此接口契约、VO 字段必须在文档中严格映射。
遇到未决的设计细节,请务必先向我提问确认,确认无误后再生成文档。
前端环境:
service-frontend执行:/sdd-propose feature/your-feature-name参考锚点:@FeatureTable/index.tsx:53-58后端环境:
service-backend执行:/sdd-propose feature/your-feature-name参考锚点:/api/v1/feature/list【需求详情见附件 PRD】
2. 需求拆解与架构确认清单
在 AI 生成正式 SDD 之前,必须引导其完成高风险架构决策。例如针对“结束语管理”功能,AI 需提前确认以下核心问题:
-
主键设计机制:读写操作时的唯一标识符如何流转?
-
状态自增逻辑:“优先级”字段是由前端显式传递,还是后端依据当前量级隐式自增?
-
高并发更新:拖拽排序引发的批量权重更新,如何避免 N 次单条 Update 操作?
-
数据模型映射:复杂子对象(如时段规则)是拆分多表关联,还是降维序列化为 JSON 存入单一字段?
3. SDD 标准产出物
标准的 SDD 流程将会在前后端各自生成高度结构化的契约文件,供后续 Agent 读取:
-
前端文档组:proposal.md (交互与提案)、spec.md (组件设计与状态管理)、tasks.md (原子化代码变更任务)。
-
后端文档组:proposal.md (接口提案)、spec.md (分层设计与契约)、design.md (数据库 DDL 与核心类图)、tasks.md (任务指令)。
4. 极简执行流
尽管 SDD 工具链(如 OpenSpec)提供了丰富的指令,但日常研发可抽象为最简的三步走闭环:
-
想 (Propose):结合上下文与参考源,生成技术规格契约。
-
做 (Apply):Agent 严格按照 tasks.md 执行代码变更。
-
收 (Archive):验证无误后,归档本次 SDD 会话,保持环境纯净。
四、多 Agent 协作:全栈并行工程
当 SDD 契约锁定后,前后端开发即刻解耦。多 Agent 协作是突破“人月神话”的关键。
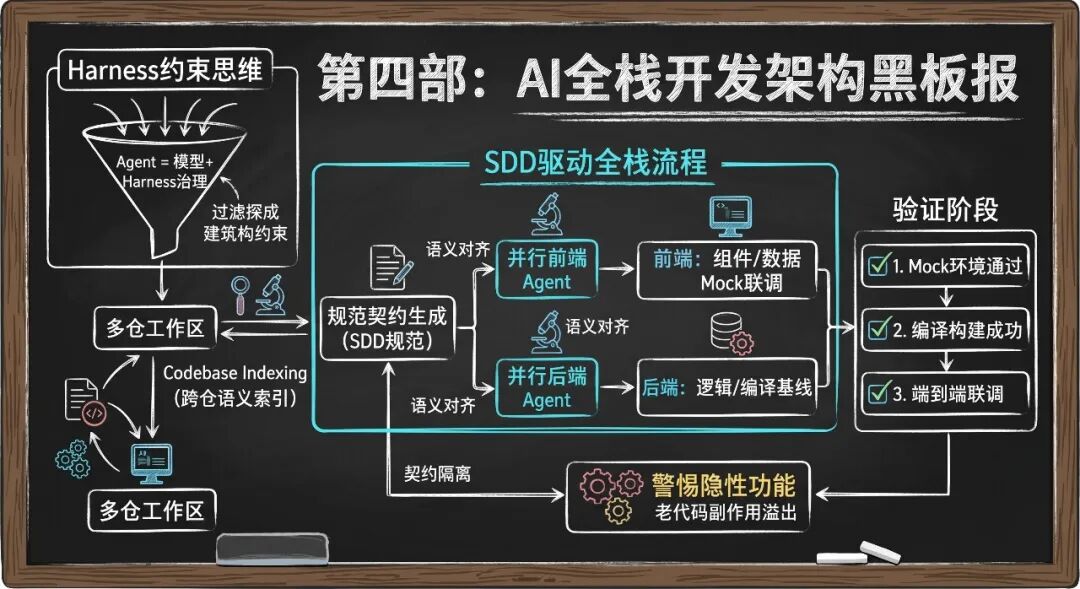
1. 并发执行策略
在 Cursor 等成熟 IDE 中,开启多个 Agent 窗口(Tab),分别挂载前端与后端的 tasks.md,即可实现物理级别的并行开发。前端 Agent 专注于 UI 还原与 Mock 联调,后端 Agent 专注于建表、接口逻辑与单元测试。两者唯一的交汇点就是 SDD 契约。
2. Subagent 模式配置示例
如果使用 CLI 工具(如 Claude Code),可以通过配置子智能体(Subagent)来实现职责隔离:
{ "description": "全栈前端 Agent", "tools": ["Read", "Edit", "Write", "Bash", "Grep"], "permissionMode": "bypass", "model": "sonnet", "skills": ["React", "TypeScript", "严格遵守 SDD 契约"]}多 Agent 协同建议:坚守“单一职责”,前端 Agent 仅依赖后端接口定义生成 Mock,后端 Agent 专心实现数据逻辑。双轨并行可最大化利用算力与等待时间。
五、三阶段验证与 Mock 联调机制
全栈 AI 生成的代码,严禁直接进入端到端联调。必须采用解耦的“三阶段验证法”:
-
前端孤岛验证 (Mock 验证):
-
-
要求 AI 严格依照后端 SDD 的 JSON 结构生成 Mock 数据。
-
必须包含极端边界(空数组、超长字符串、Null 值)。
-
在本地纯前端环境下跑通完整交互链路。
-
-
后端基线构建 (编译级验证):
-
-
无需在本地启动沉重的完整微服务。
-
只需执行
mvn clean compile(以 Java 为例)。
-
只要编译通过,即可证明 AI 生成的依赖关系、接口签名与类型映射基本无误,具备部署测试环境的资格。
-
-
全链路端到端联调:
-
-
后端部署至测试环境。
-
前端通过代理配置指向测试服,并携带染色标识,精确打通前后端数据流。
-
六、QA 警示:警惕 AI 的“隐性功能”陷阱
SDD 不等于 PRD(产品需求文档)。在 Harness 约束下,AI 会极其努力地“模仿”参考代码。这意味着,参考代码中自带的隐蔽业务逻辑,会被 AI 照单全收,悄悄带入新功能中。
隐性风险示例:
-
-
前端状态残留:模仿旧弹窗时,AI 顺手抄来了 form.resetFields(),导致用户意外关闭弹窗时输入数据丢失。
-
后端自作主张的默认值:模仿旧业务时,AI 加入了特定的时间计算补齐(如永久有效时清空开始日期),但这在当前新业务中可能并不适用。
-
质量保障建议:测试工程师的介入点应大幅前移。将 SDD 视为测试用例的基座,在 Code Review 与联调阶段,带着“旧功能有什么隐藏行为被 AI 遗传下来了?”的怀疑态度进行边界探测,而非仅仅验证 Happy Path。
七、架构收益总结
基于 Harness + SDD + 多仓管理的方法论,能对现有研发流程产生实质性的降本增效:
-
规范收敛与采纳率跃升:剥夺了 AI 自由发挥的权利,利用全局索引与模板参照,代码产出即符合团队现存架构规范,Code Review 阻力降至最低。
-
异步并行提效:SDD 使得前后端解耦前置,依赖明确。原本传统的线性协作转变为双 Agent 并发执行。实测中,一个标准的全栈 CRUD 需求(含复杂交互与联动),整体交付人效可提升 50% 以上。
-
知识平权:在严谨的架构约束下,单领域开发者只需具备基础的全栈认知,即可借助 AI 驱动跨端需求,极大提高了业务线的吞吐率上限。
PS:
Harness 工程干货直播,欢迎点击预约,直播见。
好了,这就是我今天想分享的内容。如果你对构建企业级 AI 原生应用新架构设计和落地实践感兴趣,别忘了点赞、关注噢~
—1—
加我微信
扫码加我👇有很多不方便公开发公众号的我会直接分享在朋友圈,欢迎你扫码加我个人微信来看👇

加星标★,不错过每一次更新!
⬇戳”阅读原文“,立即预约!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 13
13 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)