GitHub 飙升 21k Stars,最强免费 Claude Code 平替方案来了!
👉 这是一个或许对你有用的社群
🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料:
-
《项目实战(视频)》:从书中学,往事中“练”
-
《互联网高频面试题》:面朝简历学习,春暖花开
-
《架构 x 系统设计》:摧枯拉朽,掌控面试高频场景题
-
《精进 Java 学习指南》:系统学习,互联网主流技术栈
-
《必读 Java 源码专栏》:知其然,知其所以然
👉这是一个或许对你有用的开源项目
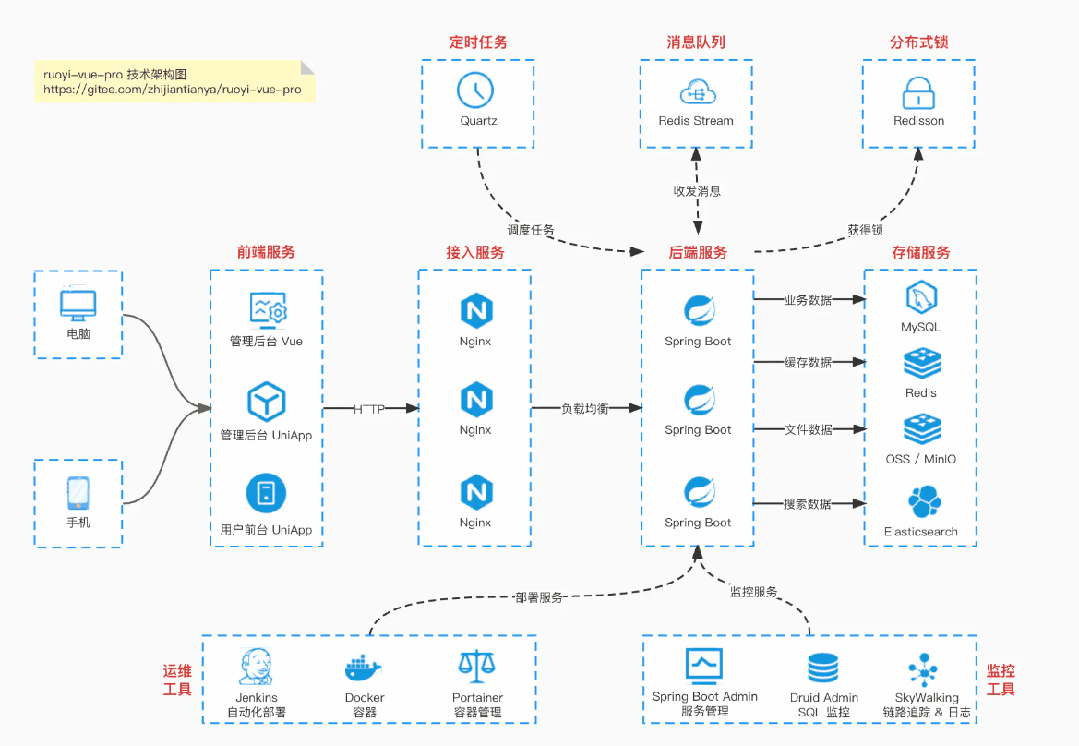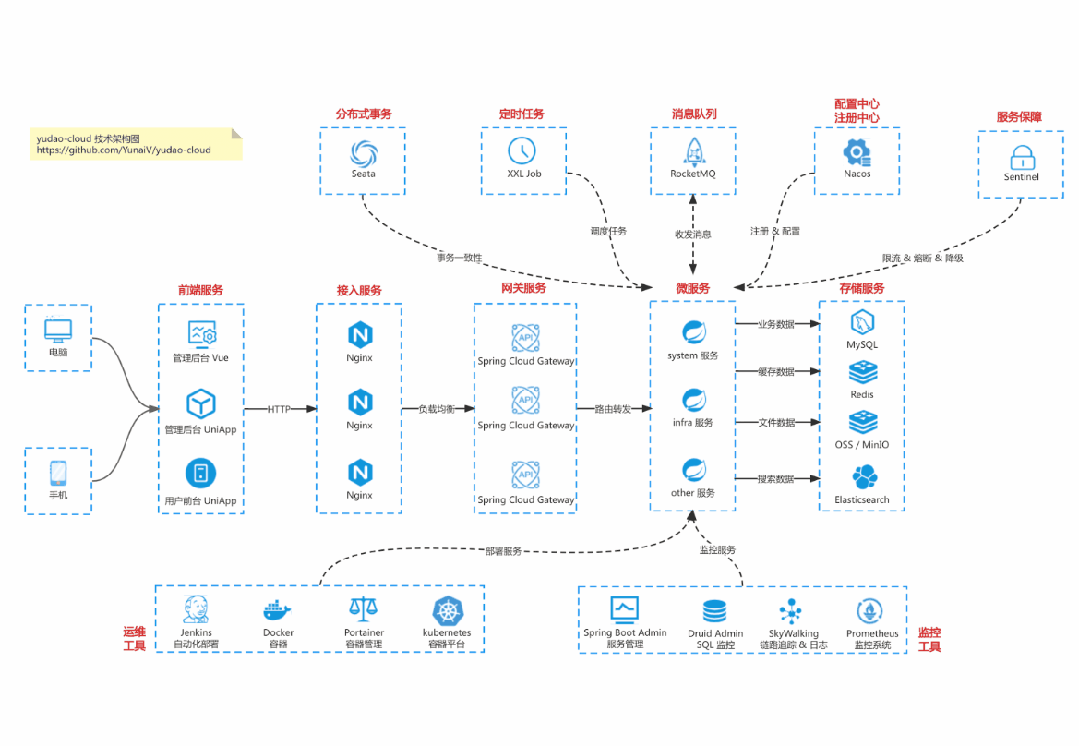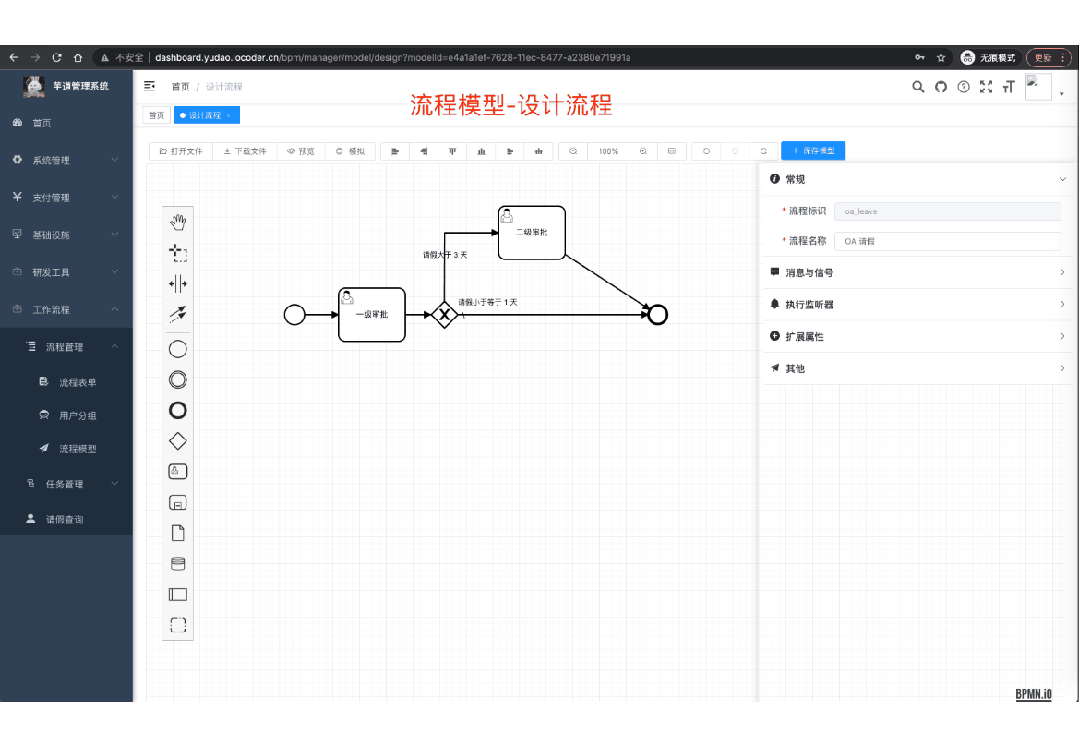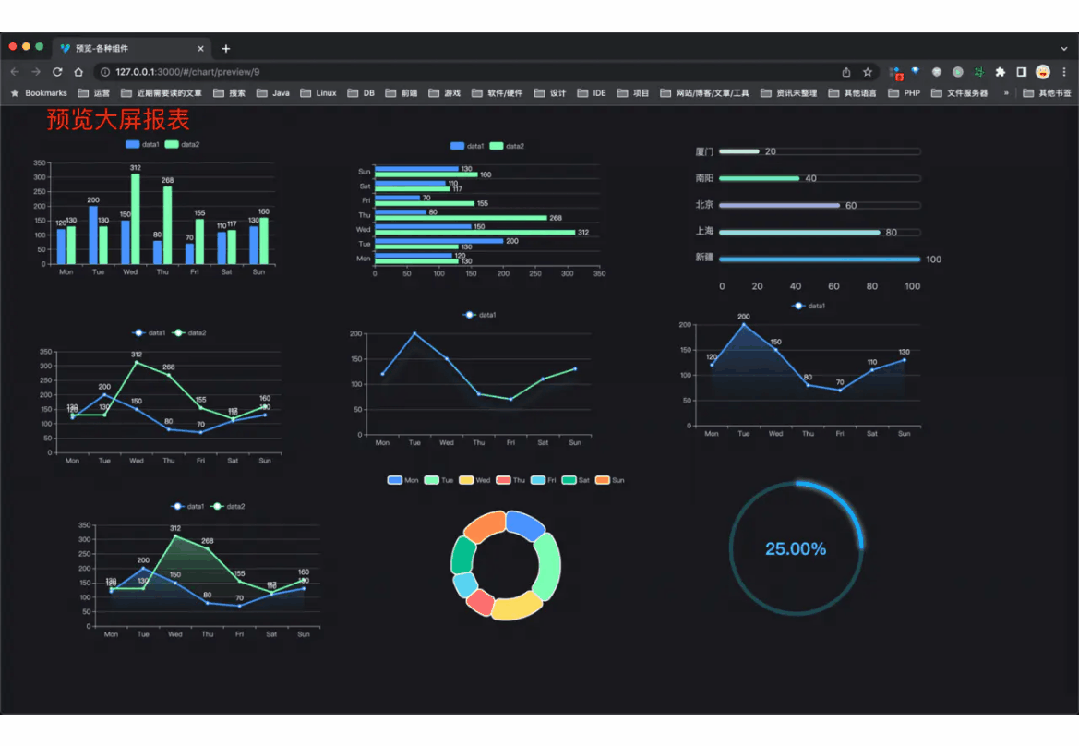
国产Star破10w的开源项目,前端包括管理后台、微信小程序,后端支持单体、微服务架构
RBAC权限、数据权限、SaaS多租户、商城、支付、工作流、大屏报表、ERP、CRM、AI大模型、IoT物联网等功能:
多模块:https://gitee.com/zhijiantianya/ruoyi-vue-pro
微服务:https://gitee.com/zhijiantianya/yudao-cloud
视频教程:https://doc.iocoder.cn
【国内首批】支持 JDK17/21+SpringBoot3、JDK8/11+Spring Boot2双版本

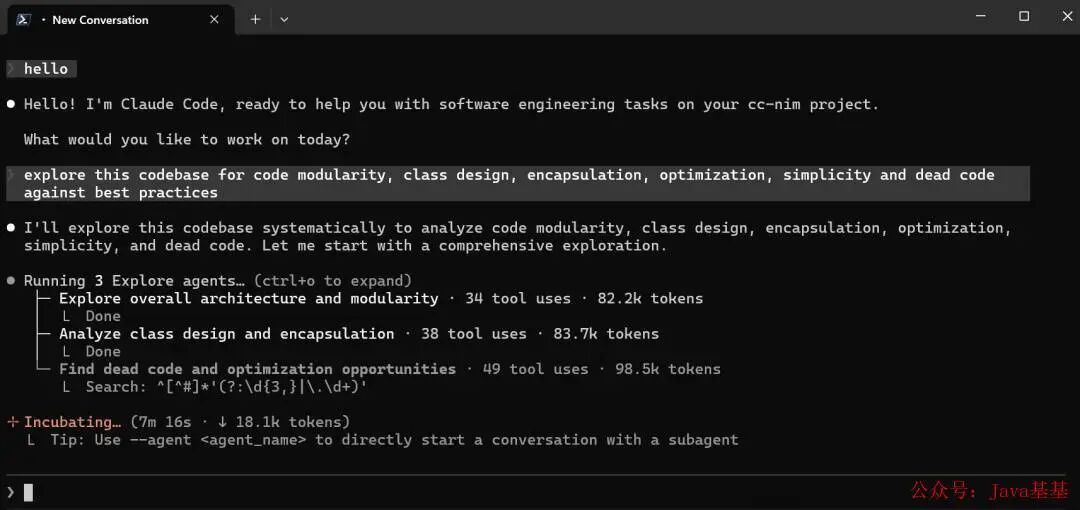
Coding Plan 抢不到 / 下午就卡——这才是研发的真痛点
国内研发用 Claude Code 的同学最近多半都在被同一件事折磨——Coding Plan 越来越难抢、下午一用就卡 。
-
抢 Plan :早 8 点 / 晚 8 点放出来——眼睛眨一下就被秒光,只能等下一波;
-
下午就卡 :Plan 抢到了也开心不了多久——下午 3-5 点高峰期一查询响应延迟动辄 30 秒+ ——本来想用 AI 提效,结果反倒拖慢工作;
-
额度用得心慌 :Pro 套餐 $20/月已经是最低档——稍微大一点的模块改 token 就刷刷地烧没了。
我自己也在这堆痛点里挣扎了很久——直到刷 GitHub 的时候撞到 free-claude-code 这个项目(作者 Alishahryar1,MIT 开源协议 )。
它做的事说起来很直白——在你本机跑一个代理服务器,把 Claude Code 发给 Anthropic 的请求拦下来、翻译成别的格式、发给你配置的后端 ——可以是 NVIDIA 的免费额度、也可以是国产模型、还可以是本机离线模型。Claude Code 那头完全感知不到变化 ——还是同一个 CLI、同一个 IDE 扩展、同一个交互方式——但你不用再抢 Plan、不用看下午的限速脸色 。
仓库地址:https://github.com/Alishahryar1/free-claude-code
截至本文发稿,GitHub Star 已经 21.7k+ ——比刚发那阵涨了快 50%。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
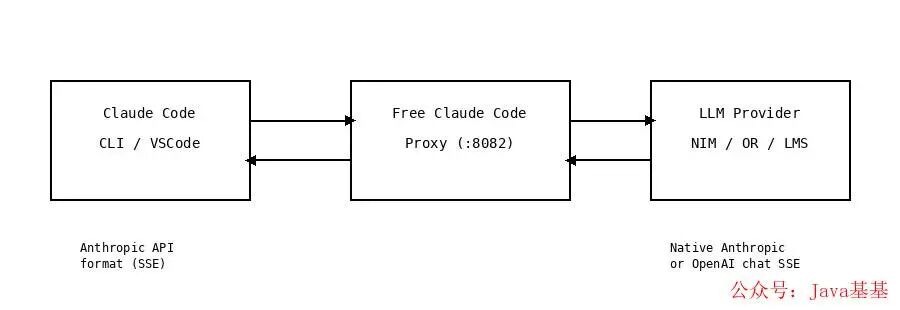
它在中间干了什么:协议互译代理一行图说清
Claude Code 工作时会不断往 Anthropic API 发请求 。这个代理就架在中间,把请求拦下来、翻译成别的协议、发给你指定的后端 ——回包再翻译回 Anthropic 的格式。
按官方 README 描述——代理实现了 Anthropic Messages API 的关键路由 :/v1/messages、/v1/count_tokens、/v1/models——**thinking 块、tool_use 调用、token usage、provider error 全部归一化成 Anthropic 协议形态** ——所以从 Claude Code 看就是 100% 兼容。
启动方式很简洁——开启代理后两个环境变量都得设 (**ANTHROPIC_AUTH_TOKEN 客户端值必须和代理 .env 里配的一致** ——代理是按等值校验的,不是只看存在):
ANTHROPIC_BASE_URL="http://localhost:8082" \
ANTHROPIC_AUTH_TOKEN="freecc" \
claude整个过程不改 Claude Code 的代码、不改 VS Code 插件 ——就改两个环境变量。这就是为什么这个项目能 60 天爆 21k Star——它根本不动 Claude Code,只动它和 Anthropic 之间那根管子 。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
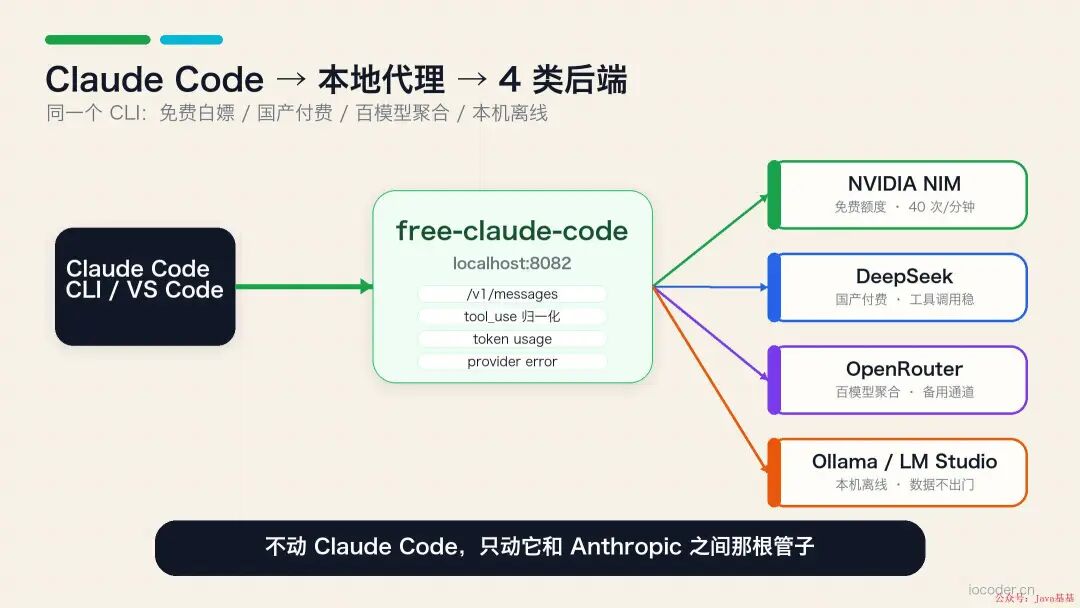
6 个后端按白嫖 / 付费 / 离线 / 语音 4 类拆解
按 <https://github.com/Alishahryar1/free-claude-code> 的 README,整个项目支持 6 个后端 + 1 个语音转录扩展 。按定位拆 4 类:
|
类别 |
后端 |
费用 |
速率 |
适合谁 |
|---|---|---|---|---|
| 🟢 白嫖党 | NVIDIA NIM | 完全免费 |
40 次/分钟 |
国内不能抢 Plan 的同学日常主用 |
|
🟡 付费便宜党 |
DeepSeek |
按量付费(极便宜) |
高 |
国产模型,工具调用稳 |
|
🟡 SaaS 聚合党 |
OpenRouter |
部分免费 |
不定 |
模型种类多,备用 |
|
🔵 离线党 |
LM Studio / llama.cpp / Ollama |
免费 |
无限制 |
数据敏感、显卡好 |
下面把最值得讲的 3 个 展开聊聊:
NVIDIA NIM——白嫖党天选
NVIDIA 给开发者提供完全免费 的额度——每分钟 40 次请求 ——去 https://build.nvidia.com/ 注册一个,不需要绑信用卡 。
上面可用的模型很猛——Kimi、GLM、Qwen3-Coder 系列 都在最新版本,全部免费跑(具体版本号请以 https://build.nvidia.com/ 实时上线为准——模型迭代很快、本文给的版本号大概率会过时)。这就是这个项目最大的卖点 ——它本质上是把 Claude Code 接到了 NVIDIA 的免费白嫖通道上——Coding Plan 卡你的时候,这条路依然丝滑 。
DeepSeek——国产付费但极便宜
DeepSeek 是付费的——但价格比 Anthropic 便宜一个量级 。原生支持 Anthropic 的消息格式——接起来非常顺 。工具调用稳定性也好 ——比 OpenRouter 上的免费模型靠谱得多——适合"白嫖额度不够 + 不想充 Plan"的中间档同学。
Ollama——离线党天选
本机跑模型——只要你显卡扛得住 :完全离线、没有速率限制、数据不出本机。显存 16GB+ 起步 ——能流畅跑 GLM-4.7-Flash 这一档。
安装:4 步装好 + 5 个新人最容易撞的坑
这块需要注意 ——这个项目用 uv 管理依赖、不是传统的 pip。**uv 速度快很多但需要单独装** 。
第 1 步:装 uv 和 Python 3.14
# macOS / Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
uv python install 3.14
# Windows PowerShell
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
uv python install 3.14第 2 步:装 free-claude-code(推荐用包安装)
方式一:克隆仓库运行
git clone https://github.com/Alishahryar1/free-claude-code.git
cd free-claude-code
cp .env.example .env然后编辑 .env——以 NVIDIA NIM 为例(model 名称去 https://build.nvidia.com/ 选当前最新最强的,下面的占位仅为示例格式 ):
NVIDIA_NIM_API_KEY="nvapi-你的key"
# 把 <provider/model-name> 换成 build.nvidia.com 上当前可选的最新模型 id
MODEL="nvidia_nim/<provider/model-name>"
ENABLE_MODEL_THINKING=true方式二:当包来装(推荐,不用克隆)
uv tool install git+https://github.com/Alishahryar1/free-claude-code.git
fcc-init # 自动生成 ~/.config/free-claude-code/.env
free-claude-code # 启动服务器以后更新也很简单:uv tool upgrade free-claude-code。
第 3 步:启动代理 + 启动 Claude Code(开两个终端)
# 终端 1:启代理
uv run uvicorn server:app --host 0.0.0.0 --port 8082
# 终端 2:跑 Claude Code(AUTH_TOKEN 必须和代理 .env 里的值一致)
ANTHROPIC_BASE_URL="http://localhost:8082" \
ANTHROPIC_AUTH_TOKEN="freecc" \
claudeVS Code 插件用户——打开 Settings 搜 claude-code.environmentVariables,在 settings.json 里加两行:
"claudeCode.environmentVariables": [
{ "name": "ANTHROPIC_BASE_URL", "value": "http://localhost:8082" },
{ "name": "ANTHROPIC_AUTH_TOKEN", "value": "freecc" }
]第 4 步:5 个新人最容易撞的坑(官方 README 里全部点名)
按官方 README 的"Common Issues"段,按踩坑频率从高到低:
-
坑 1( 最常见):
ANTHROPIC_BASE_URL后面千万别加/v1—— 这是新人第一周必撞——加了 Claude Code 直接连不上代理,显示 404 一脸懵; -
坑 2:必须用 Python 3.14 final ——3.13 / 3.14 RC 版都不行,会有依赖兼容问题 ;
-
坑 3:llama.cpp / LM Studio 这俩本地后端要给足
--ctx-size——太小直接报 HTTP 400; -
坑 4:本地后端 base URL 必须带
/v1——和 NVIDIA NIM 这种 SaaS 不一样——两套规则别搞混 ; -
坑 5:VS Code 第一次启动可能弹登录窗 ——直接关掉,代理依然在工作 ——这是 VS Code 的客户端层 UI 残留,不影响功能。
进阶玩法 1:Opus / Sonnet / Haiku 分档跑不同后端
Claude Code 内部会发不同档次的请求——Opus 对应最复杂的任务、Sonnet 是日常主力、Haiku 负责快速轻量操作 。
这个代理可以给每档分别配不同后端 ——下面这套配置思路 永远成立,具体模型 id 请去 https://build.nvidia.com/ 选当前最强 :
# Opus 档:跑最复杂的任务——选 NVIDIA Build 上当前最强的推理模型
# 写稿时(2026-05)的可选项:deepseek-v4 系列 / kimi-k2 系列 / qwen3-coder 系列
MODEL_OPUS="nvidia_nim/<最强推理模型>"
# Sonnet 档:日常主力——选和 Opus 错开厂商的次档强模型
# 故意和 Opus 错厂商,避免一家挂了全瘫
MODEL_SONNET="nvidia_nim/<次档强模型>"
# Haiku 档:轻量快速操作——选轻量 / Flash 变体,或本地小模型
# NVIDIA Build 的 Flash 系列、或本地 Ollama / LM Studio 跑的小模型都行
MODEL_HAIKU="nvidia_nim/<轻量 / Flash 模型>"为什么这么搭 :① Opus 配最强 —— 跨多文件重构、深度推理这种活靠它;② Sonnet 故意错开厂商 —— 避免一家挂了全瘫、不同厂商的工具调用风格也各有所长;③ Haiku 用轻量 / Flash —— 文件路径检测 / 对话标题这种轻量任务,Flash 比 Pro 快 3 倍 ——省额度也省延迟。
⚠️ 模型迭代极快 ——本文不写具体 model id 是有意的,写了过几个月就过期 。每次新建
.env前去 https://build.nvidia.com/ 看一眼当前可选的最强模型即可——配置思路(Opus 最强 / Sonnet 错厂商 / Haiku 轻量)才是不会过时的部分。
进阶玩法 2:原生 Model Picker + Discord 远程派活
按 README 还有几个别的文章很少讲 的细节:
原生 Model Picker——直接在 Claude Code 里切模型
Claude Code 2.1.126+ 加了一个 CLAUDE_CODE_ENABLE_GATEWAY_MODEL_DISCOVERY=1 环境变量——开启后会自动从代理的 /v1/models 端点发现可用模型 。
CLAUDE_CODE_ENABLE_GATEWAY_MODEL_DISCOVERY=1 \
ANTHROPIC_BASE_URL="http://localhost:8082" \
ANTHROPIC_AUTH_TOKEN="freecc" \
claude代理会自动列出所有配置的 provider 上的可用模型 ——每个还带一个 "(no thinking)" 变体(给不支持 adaptive-thinking 的模型用)——你直接在 Claude Code 的 UI 里切模型,不用改 .env 。这是这个工具体验最丝滑的一个特性。
Discord / Telegram bot——远程派活给 Claude Code
按 README——可以用 Discord / Telegram bot 远程让 Claude Code 干活 :
# .env 配置示例
DISCORD_BOT_TOKEN="..."
ALLOWED_DIR="/home/user/projects"
CLAUDE_WORKSPACE="/home/user/workspace"支持的命令也很完整:
-
/stop—— 取消当前任务或指定分支; -
/clear—— 重置 session; -
/stats—— 查看当前 session 状态; -
回复消息分支会话 —— 和 Discord 的 thread 模型对齐——同一根线索可以多轮跟进。
研发场景的实际用法:长耗时任务挂着跑,人不用守终端 ——你下班路上、开会的时候、Discord 里发条消息让 Claude Code 处理一个 PR / 跑一段单测 / 改一段文档——回家打开看结果——这种"远程触发 + 实时通知"研发体验非常上头 。
语音转录——直接在 Discord 发语音让 AI 干活
这是别的文章基本不提的特色——支持本地 Whisper 或 NVIDIA NIM 跑语音转录 :
# 本地 Whisper(CPU 或 GPU)
WHISPER_DEVICE="cpu" # 或 "cuda"
WHISPER_MODEL="base"
# 或者用 NVIDIA NIM 远程
WHISPER_DEVICE="nvidia_nim"
NVIDIA_NIM_API_KEY="nvapi-..."装的时候要加 uv sync --extra voice_local 或 --extra voice——前者本地跑,后者远程。
适用场景:地铁里 / 路上不方便打字的时候,直接 Discord 发条语音让 Claude Code 改代码 ——通勤 30 分钟下班路上能多干一个小时活。
本地拦截优化——省额度的关键设计
按 README——代理会在本地直接响应那些"trivial probes" :网络可达探测、对话标题生成、文件路径检测——这些请求根本不需要过 API ,代理直接给响应——省额度 + 省延迟 。
真实差距:白嫖版和原版到底差多少
按破坏力从高到低:
差距 1:模型能力(最常见)
NVIDIA NIM 上的 DeepSeek / Kimi 系列最新版跟原版 Claude 4.x 比——日常写代码、改 bug、生成模板都很顺 ;碰到 yudao-cloud 这种多模块 Spring Boot 项目跨模块重构 ——只要把上下文准备好(用 @filename 把相关文件主动喂给它)——白嫖版照样能搞定 ——只是需要你比用 Claude 4.x 时更主动地"递素材"。
实战体感 :跨 3-4 个模块的重构,Claude 4.x 一次能想清整条链路;NVIDIA NIM 上的国产最强模型多沟通 1-2 轮、明确告诉它"先看 dal 层 / 再看 service / 最后改 controller"——最终质量没差 。白嫖版不是不行,是要给它更清晰的指令 。
yudao-cloud 仓库:https://github.com/YunaiV/yudao-cloud
差距 2:本地跑要显卡(常见)
LM Studio / Ollama 这类要在本机跑模型——显卡越好体验越好 。没独显或只有 4GB 显存的话 ——35B 以上的模型会卡到没法用——老 MacBook 党别想了 。
差距 3:速率限制(少见但破坏力大)
NVIDIA NIM 每分钟 40 次——听起来多,但 Claude Code 工作时请求频率挺高 ——密集写代码偶尔会撞限速。等几秒就好 ,但会打断思路。
项目代码质量值得一提
代码用 Python 3.14 + FastAPI 写的——目录结构清晰:server.py 是入口、providers/ 管各个后端、messaging/ 管 Discord / Telegram、tests/ 里有 pytest 测试用例。
如果你想自己加一个后端——继承 BaseProvider 或 OpenAIChatTransport、再在 provider registry 里注册一下就行 ——扩展成本很低。
作者在 README 里明确说了不接受 Docker 集成的 PR ——风格上偏向轻量。这个我很喜欢 ——一个工具能保持克制、不把所有人的需求都往里塞,本身就是一种健康的开源态度。
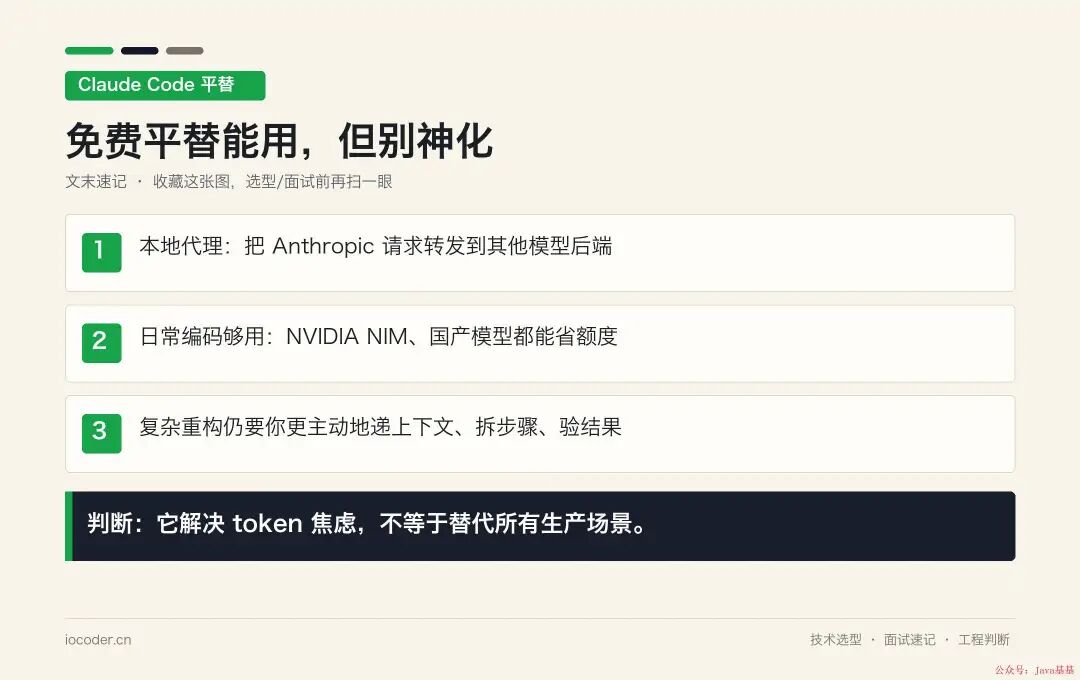
我的判断
坦率讲——这个项目不是让你完全替代付费版 Claude Code 的方案 。真要做严肃的生产项目,原版 Claude 4.x 的稳定性和模型能力还是更可靠 。
但它解决了国内研发的几个真痛点 :
-
抢不到 Coding Plan ——白嫖 NVIDIA Build 上的国产最强模型,日常写代码足够;
-
下午就卡 ——本地代理 + NVIDIA 走美国线路,比官方走本地代理稳得多 ;
-
不想公司数据走 Anthropic ——离线模型直接 Ollama 跑、数据不出本机;
-
想试试 Claude Code 是不是真好用 ——没必要先充 $20 一个月先;
-
学校 / 学生党不想掏钱 ——直接白嫖到饱。
NVIDIA NIM 免费 40 次/分钟——对付日常写代码完全够用 。装上之后第一感受会是「之前我焦虑的 token 焦虑突然不见了 」——这种心理变化值得专门感受一下。
仓库地址:https://github.com/Alishahryar1/free-claude-code
欢迎加入我的知识星球,全面提升技术能力。
👉 加入方式,“长按”或“扫描”下方二维码噢:

星球的内容包括:项目实战、面试招聘、源码解析、学习路线。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 11
11 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)