从“Task列表”到“特性地图”:特性驱动开发如何重塑AI Coding工作流?
但随着任务复杂度提升,一个更深层的问题也逐渐暴露出来:现有方法虽然能够通过智能体的多轮迭代实现“从需求到代码”的完整生成过程,但在方法论上依然延续传统的瀑布模型过程(即先分析需求,再拆解任务形成to-do列表,然后按顺序完成任务)。而这,也正是 EvoDev 想要探索的方向。但在比对了相同底座模型在单Coding智能体和EvoDev场景下的表现后,我们发现Claude系列模型虽然具备更强的单智能体
随着大模型能力持续提升,AI Coding的主流模式正在从“代码生成”转向“端到端应用开发”。从MetaGPT等多智能体工作流,到Claude Code这样的工程化开发框架,再到近期流行的Harness Engineering,整个领域正在逐步迈向真正意义上的端到端软件生成式开发。但随着任务复杂度提升,一个更深层的问题也逐渐暴露出来:现有方法虽然能够通过智能体的多轮迭代实现“从需求到代码”的完整生成过程,但在方法论上依然延续传统的瀑布模型过程(即先分析需求,再拆解任务形成to-do列表,然后按顺序完成任务)。这种方式对于简单应用开发比较有效,但一旦用于复杂应用开发就会出现一系列问题:
1)任务粒度不稳定:缺少基于软件设计思想的任务拆解原则和粒度控制,导致to-do列表中的任务形态和粒度高度不确定,例如既有创建数据层、UI界面之类很技术导向的模糊任务,又有增加某个特定功能之类的很业务导向的具体任务;
2)任务之间缺乏依赖建模:线性to-do列表默认任务之间顺序推进且彼此独立,无法显式表达复杂开发过程中不同迭代任务之间的依赖关系;
3)上下文难以持续传递:复杂软件开发过程中形成的架构选择、接口约定、数据模型以及中间状态等关键信息,难以在多轮迭代之间被系统且有序地继承与复用;
4)整体一致性丢失:传统任务列表只能描述“下一步做什么”,却无法记录“为什么这样做”以及“系统已经演化到什么阶段”,因此难以维护长期演化中的设计逻辑与开发约束,随着开发轮次不断增加,已有设计决策和上下文逐渐被遗忘或覆盖,最终导致系统架构、模块实现与功能行为之间的一致性不断下降。
更糟糕的是,瀑布式任务流天然缺乏对“演化过程”的支持,它也许可以一次性生成应用,但却很难支撑接下来的持续迭代和演化。即便是近期流行的Harness Engineering,其本质上也仍然是在执行层进行优化:通过前馈提示、后处理与自动修复机制提升生成可靠性,但并没有真正解决软件的设计规划与结构化的任务组织的问题。因此,一个关键问题逐渐浮现出来:对于基于智能体的生成式软件开发而言,我们不仅需要关注开发任务执行,而且还需要从软件开发的内在规律出发优化开发任务的组织。
事实上,对于这个问题我们可以从经典软件工程中的特性驱动开发(Feature-Driven Development,FDD)方法中获得灵感,即首先通过短周期迭代将用户需求拆解为可独立交付的“特性”,再以一种敏捷迭代的方式持续交付价值。基于以上思考,我们提出了一种特性驱动的迭代式端到端生成式软件开发框架EvoDev。该框架定义并实现了一套面向大模型智能体的结构化开发工作流:它不再将开发过程组织为线性的to-do列表,而是引入特性地图(Feature Map)作为演化式开发的核心组织结构,并在此基础上利用特性依赖关系统筹开发任务规划以及上下文管理与传播,从而实现持续的演化式应用开发能力。
基于该研究工作的研究论文《EvoDev: An Iterative Feature-Driven Framework for End-to-End Software Development with LLM-based Agents》已被软件工程领域顶级国际会议 ISSTA 2026 接收。

-
论文标题:EvoDev: An Iterative Feature-Driven Framework for End-to-End Software Development with LLM-based Agents
-
论文作者:Junwei Liu, Chen Xu, Chong Wang, Tong Bai, Weitong Chen, Kaseng Wong, Yiling Lou, Xin Peng
-
作者单位:复旦大学
-
论文地址:https://arxiv.org/pdf/2511.02399
1. 瀑布流开发 vs 特性驱动开发
在揭示EvoDev方法的具体设计之前,先来看看我们的实验对比:

EvoDev 相较其他端到端开发智能体的效果提升
(基于Claude-Sonnet-4)
我们的实验结果揭示了当前端到端软件开发智能体的核心瓶颈。针对Android应用开发,开源的端到端开发框架(MetaGPT、GPT-Engineer)均无法稳定生成可运行应用,这说明智能体工作流的设计会高度影响底层模型能力的有效释放。Claude Code 虽然能够完成完整开发流程,并达到 73.3% 的构建成功率,但其功能完成度仅为 2.27 / 4。这意味着,大量功能虽然“存在”,但在逻辑正确性、交互一致性与细节实现上仍存在明显问题。相比之下,EvoDev 借助特性驱动的开发工作流,将构建成功率提升至 100%,功能完成度达到 3.57 / 4,相较 Claude Code 提升 57.3%。
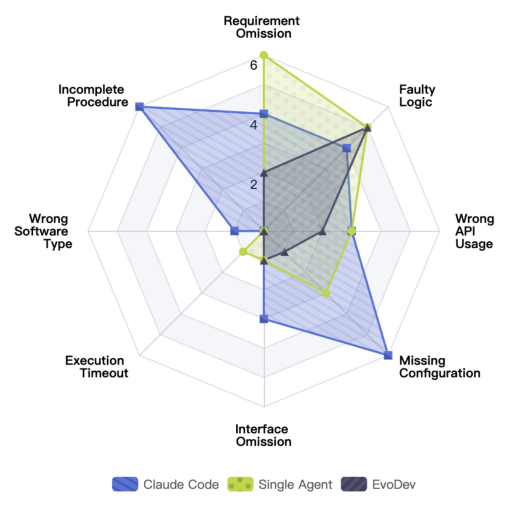
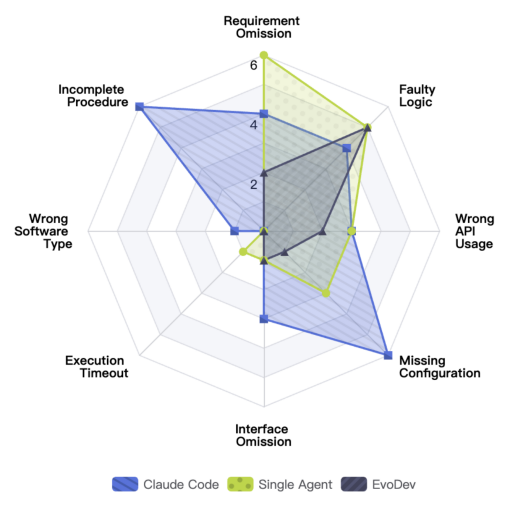
EvoDev、Claude Code 与 Single Agent 的失败模式分析
错误分析进一步说明,Claude Code 与单Coding智能体系统的大部分失败,并非来自代码生成错误,而是由于开发过程缺乏结构性建模导致的流程性问题与上下文问题,例如:
1)需求遗漏(Requirement Omission):模型自主拆分的任务粒度和质量不稳定,导致一部分需求信息在拆分的过程中丢失;
2)流程中断(Incomplete Procedure):模型自行决定任务进度,有时会出现任务列表未全部完成就提前终止的情况;
3)接口遗忘(Interface Omission):模型在后续任务的执行过程中,未能探查到之前任务为当前任务预留的接口,导致实现断层,功能无法串接;
4)配置缺失(Missing Configuration):to-do列表的任务描述往往十分简短,主要聚焦于功能描述,忽视了必要的辅助配置,导致模型在实现时遗漏了配置检查。
这些问题本质上都指向同一个根源,当前工作流无法有效管理“开发过程”本身。当开发被简单拆解为线性to-do列表时,模型需要在任务描述高度简化和缺乏结构约束的情况下进行局部决策,这会导致依赖关系无法显式表达,上下文在长链路开发中逐渐丢失,最终影响整体质量。而 EvoDev 的核心改进,正是针对这一结构性问题展开。
2. EvoDev: 特性驱动的迭代开发框架
EvoDev的核心思想是将软件开发流程本身设计为一个结构化、可演化的系统。它不再以任务(Task)为开发单位,而是以特性(Feature)作为整个开发流程的核心组织结构,通过特性依赖连接软件不同层次的开发视图,并基于特性依赖关系实现上下文的持续传播。
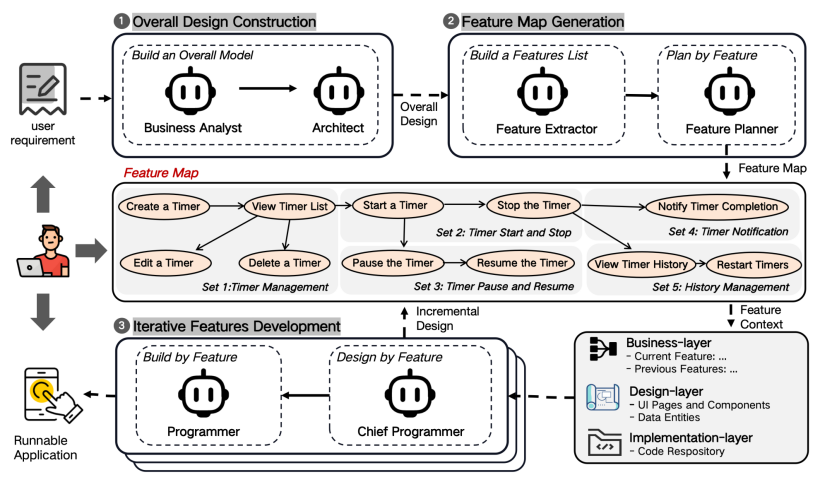
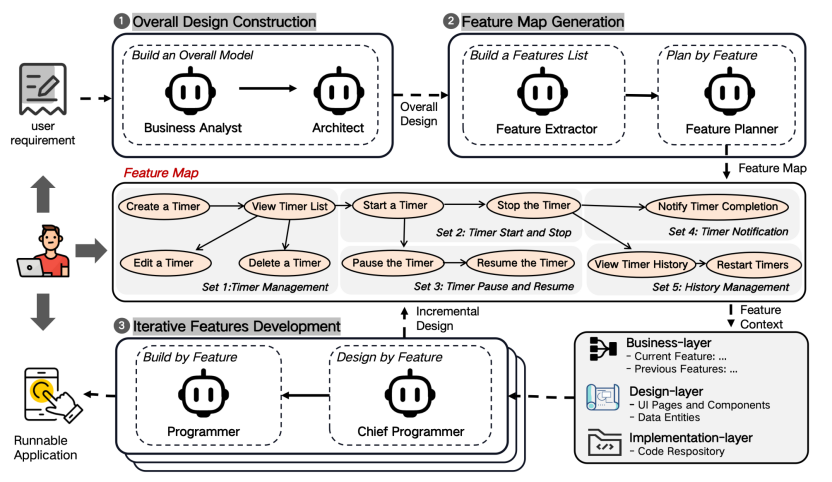
EvoDev方法框架
EvoDev主要包含整体设计构建、特性地图生成和特性迭代开发三个阶段。
在整体设计阶段,系统首先对需求进行分析与建模,生成用统一术语描述的整体架构设计,例如为每个UI组件赋予全局性的id。这一步不仅为后续开发提供了设计蓝图,而且为迭代开发建立一致的全局语义空间基础,避免不同阶段之间产生理解偏差,导致一致性的下降。
在特性地图生成阶段,EvoDev将应用需求和设计拆解为一组具有明确依赖关系的特性节点,从而形成特性地图(Feature Map)。特性地图是 EvoDev 最核心的设计之一。它的每一个节点都同时包含三个层次的上下文:
1)业务层:当前特性的用户目标与业务语义;
2)设计层:实现该目标所需的交互与架构设计;
3)实现层:当前特性对应的代码修改与实现状态。
这意味着,一个特性并不仅仅是一个待执行任务,而是一个完整的软件语义单元。不同特性之间则通过依赖关系形成拓扑结构,使上下文能够沿着特性依赖自然传播。特性的连接,实际上使得不同抽象层次之间的上下文也得以连接,从而显著降低模型在复杂项目中定位相关上下文的难度。
在特性迭代开发阶段,系统按照特性地图的拓扑排序进行迭代实现。每个迭代都会接收到其依赖的历史特性上下文,以及当前特性的业务目标和整体设计。首席程序员智能体借助这些信息进一步明确当前迭代在整个开发流程中的定位和目标(业务层拓展),并通过详细设计完善全局设计未曾覆盖的设计细节(设计层拓展),之后程序员智能体通过编码、构建与调试形成闭环,完成当前迭代的开发目标(实现层拓展)。
由于每个特性都对应一个可执行的用户目标,因此整个开发过程中的中间状态始终是“可运行、可体验”的。这使 EvoDev 不仅将传统瀑布式开发转变为持续演化过程,也让原本黑盒的端到端开发流程变得更具可观测性与可干预性。
3. 特性驱动开发的设计哲学
FDD:更适配智能体的开发过程模型
EvoDev的灵感来自软件工程经典的特性驱动开发(FDD)方法,全局包含“开发整体模型”、“构建特性列表”、“按特性规划”三个阶段,每轮迭代则包含“按特性设计”和“按特性构建”两个阶段。与传统瀑布式开发相比,它天然更强调增量式演化、结构化规划以及以用户价值为核心的迭代组织方式。而这些特性,恰恰与当前大模型智能体的能力边界形成了高度契合。
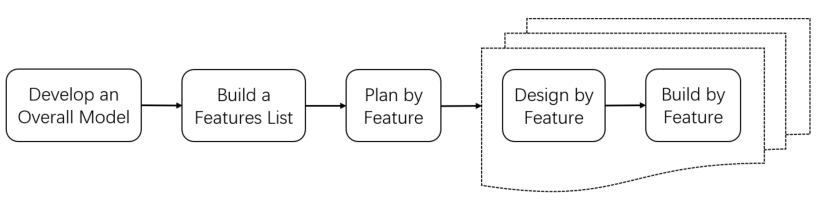
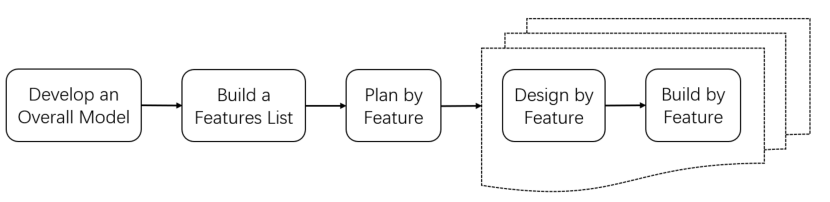
经典特性驱动开发工作流
首先,FDD 是一种相对“重文档”的敏捷方法。它将开发过程中的核心信息沉淀为结构化产物,使需求、设计、实现与迭代状态都能够稳定地转化为模型输入与输出。这一点对于大模型尤为重要,因为当前智能体最稳定、最可靠的信息媒介仍然是自然语言文本。相比之下,像 Scrum 这样的敏捷方法更依赖高频的面对面沟通(例如Daily Scrum),而多智能体之间的协同讨论目前仍然存在明显问题,例如观点趋同、循环讨论、迎合型反馈等。这意味着,许多强调即时沟通的传统敏捷机制,在智能体场景下并不能被自然继承。
其次,FDD在需求拆分的基础上进一步引入了“依赖关系建模”。传统工具使用的to-do任务列表本质上是线性的,它只能表达“接下来做什么”,却无法表达“为什么现在做”“它依赖什么”“它会影响什么”。而在 EvoDev 中,特性地图不仅描述待实现特性,更描述不同特性之间的依赖关系。于是,整个开发过程不再是一个线性的任务队列,而是一个显式建模的演化图结构。这种结构带来了两个重要结果:
1)一方面,它使开发流程更加平滑。模型不再需要在缺乏上下文的情况下进行“跳跃式开发”,而是能够沿着依赖关系逐步推进系统演化;
2)另一方面,它也使上下文传播第一次具备了结构基础。上下文不再只依赖长对话历史或全局代码检索,而是能够沿着特性依赖进行按需传递。
更进一步,这种结构还天然支持后续功能扩展。新增功能不再作为一个完全独立的任务进行规划,而是可以作为新的特性节点接入已有特性图,与历史功能建立依赖关系,从而融入整个系统演化过程。
最后,FDD在“全局规划”与“局部迭代”之间提供了一种非常适合大模型的平衡。它既通过整体设计保证系统一致性,又允许在每轮迭代中逐步细化设计与实现。这种“强结构 + 弱执行”的组织方式,能够有效降低模型在复杂开发中的失控概率。
因此,FDD 的价值,在于它天然提供了一种适合大模型进行长期协作的结构化开发方式。EvoDev 也并不是简单地“把FDD搬到 AI 上”。它更像是在重新回答一个问题:当开发者从人类变成智能体后,什么样的软件工程方法才真正适用?
4. 从Task到Feature:从执行单元到语义单元
以 Claude Code 为代表的 AI Coding 系统,通常以to-do列表中的任务(Task)作为开发流程的基本单位。这种方式继承自Chain-of-thought,强调执行步骤,将复杂需求拆解为一系列待完成任务,再逐步推进开发过程。这样的设计在短链路代码生成中是有效的,但一旦进入复杂应用开发,就会逐渐暴露出问题。核心原因在于:任务本质上是“执行导向”的,而不是“语义导向”的。
一个任务往往只描述“做什么”,却缺少“为什么做”“它在系统中的位置”“它与其他功能的关系”等信息。因此,模型很容易陷入局部执行视角,过度关注代码层面的物理实现,而忽略业务目标、交互逻辑以及系统整体一致性。这也是为什么许多智能体虽然“完成了任务”,却仍然会出现功能遗漏、流程错误与交互不一致等问题。
相比之下,EvoDev 将开发单位从“任务”转向了“特性”。这一变化看似只是需求拆分方式的调整,但本质上改变的是整个开发过程的信息组织方式。任务更接近“步骤”,而特性更接近“功能语义模块”。一个特性不只是一个待完成事项,它同时包含:用户价值、业务目标、设计约束、实现状态、与其他特性的依赖关系。因此,对于模型而言,一个特性实际上构成了一个完整的上下文闭环。
这意味着,模型在开发过程中不仅知道“当前要写什么代码”,更知道当前功能属于系统的哪个部分?为什么需要它?它会影响哪些已有功能?它未来会被哪些功能依赖?这种信息完整性,会显著降低模型在复杂开发中的“上下文漂移”。
与此同时,由于每个特性都对应一个用户可感知的功能目标,因此 EvoDev 的每轮迭代都能够交付一个可运行、可体验的中间结果。这意味着开发过程第一次从“黑盒生成”变成了“持续演化”。开发者不再只能等待最终结果,而是能够持续观察系统如何生长,并在过程中进行反馈与干预。而这,恰恰是传统软件工程中“迭代开发”的核心价值之一。
5. 从空间上下文到时间上下文:
从代码快照到演化历史
除了开发单位的变化之外,EvoDev 在上下文组织方式上,也与现有工作存在一个本质区别。当前大多数 AI Coding 系统,在上下文组织上都侧重于“空间型”,即,模型主要根据:当前目录结构、文件内容、局部代码关系、检索到的仓库片段来理解整个项目。Claude Code 中的 CLAUDE.md,其实就是这一思路的典型代表:它通过在不同目录下维护局部说明文档,帮助模型理解当前代码空间中的信息。这种方式当然有效,但它存在一个天然问题:它只能描述“当前系统长什么样”,却无法描述“系统是如何演化到这里的”。
而软件开发,除了当前的空间状态,还隐含着一个持续演化的时间状态。很多设计决策、接口结构与代码组织,并不能单纯从当前代码快照中推断出来,而必须结合开发历史与演化路径才能真正理解。EvoDev 的特性地图,本质上提供的正是一种“时间型上下文”。由于每个特性都与其前置特性存在显式依赖关系,因此系统能够天然保留:当前功能从哪里演化而来?为什么采用当前设计?哪些历史决策会影响当前实现?于是,模型不再只是“阅读代码”,而是在“理解演化过程”。因为随着项目规模扩大,仅靠代码检索定位上下文的方式,成本会越来越高,不确定性也会越来越强。而基于特性依赖传播上下文,则能够让模型始终在与当前开发目标最相关的历史语义范围内工作。
从某种意义上说:传统方式管理的是“代码空间”,而 EvoDev 更关注的是“系统演化”。
6. EvoDev带来的其他启发
EvoDev 的价值,并不仅仅在于提出了一套新的工作流,它还通过实验结果揭示了一个正在逐渐清晰的趋势:当大模型开始参与软件工程时,许多过去默认成立的AI Coding假设,可能都需要被重新讨论。
1)软件开发,不等同于代码生成
过去很长一段时间里,大家往往默认认为:模型的代码能力越强,软件开发能力就越强。但在比对了相同底座模型在单Coding智能体和EvoDev场景下的表现后,我们发现Claude系列模型虽然具备更强的单智能体代码实现能力,但在 EvoDev 的迭代开发场景中,GPT 系列模型反而获得了更大的性能提升(58.5%)。这意味着,端到端应用开发与代码生成需要的模型能力并不完全相同。
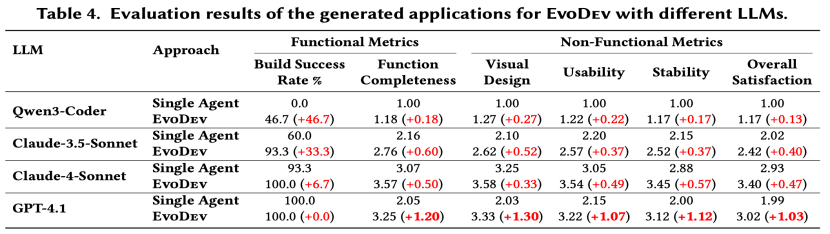
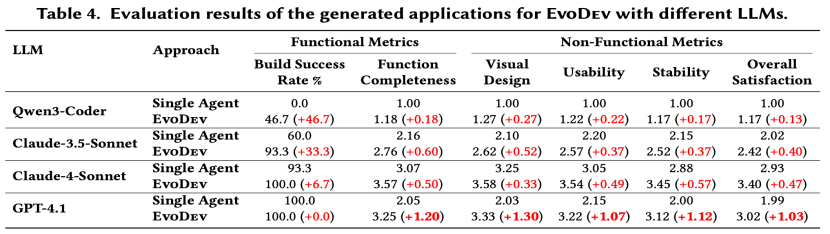
EvoDev 在不同 LLM 上相较于单智能体的效果提升
具体来说,代码生成更强调局部实现能力,例如语法正确性、API 使用、算法实现等;而端到端应用开发则更强调长程规划、多阶段一致性、指令遵循、上下文管理、系统级决策能力 ,换句话说,软件工程不仅要求模型会写代码,还要求模型能够持续组织系统并按照规划行事。这意味着,未来模型能力的发展方向,可能并不只是进一步强化Coding能力,而是需要更关注:长链路任务稳定性、结构化推理能力、持续上下文维护能力、以及更强的指令遵循能力。这也是为什么,越来越多研究开始从“代码生成模型”转向“软件工程智能体”。
2)离开上下文管理,迭代开发无从谈起
迭代开发并不是将原本单轮的开发改成多轮就可以,事实上,如果缺乏合理的上下文组织机制,迭代开发反而可能让问题进一步累积。这是因为,在复杂开发过程中,模型并不会天然记住:为什么之前这样设计?哪些功能已经完成?哪些接口会受到影响?当前修改会破坏什么?每一轮迭代,模型都要重新理解整个仓库并定位最相关的上下文,其中的信息损失率会受到模型能力和随机性的影响。于是,随着开发轮次增加,系统会逐渐出现上下文漂移、功能不一致、历史设计遗忘、新旧逻辑冲突等问题,这也是为什么许多端到端开发智能体在早期Demo阶段表现良好,但一旦进入稍长链路开发,就会迅速失控。


EvoDev消融实验,只进行迭代而开发而不进行上下文管理(第三行)反而会导致效果下降
EvoDev 的意义,恰恰在于它第一次通过特性地图将“上下文传播”结构化了。过去,上下文更多依赖长对话历史、RAG 检索、代码搜索、局部 Memory 文件,而 EvoDev 则尝试通过“开发结构”本身管理上下文。这其实是一个非常重要的思路转变,与其不断扩大模型上下文窗口,不如重新设计上下文的组织方式。
3)模型默认行为,可能会与工作流要求产生冲突
EvoDev 的实验还揭示了一个经常被忽视的问题:模型自身的默认行为,并不一定与智能体工作流兼容。例如,Coding能力越强的模型会越倾向于进行多轮自我修复(self-refinement),即不断尝试修改已有实现。在单次代码生成任务中,这种行为通常是有益的,因为它能够提高局部正确率。但在迭代开发场景中,这种倾向却可能带来问题,因为工作流本身已经规划好了:当前阶段做什么?当前特性的边界是什么?哪些问题应该留到后续阶段解决?而模型如果过度自我修复,就可能打乱既定开发节奏,修改不该修改的模块,或是引入额外上下文污染,增加不必要的 Token 消耗。这意味着:智能体系统设计,不能只考虑“模型能力”,还必须考虑“模型行为”。未来的软件工程 Agent,可能需要更深入地研究:如何对齐模型原生能力与工作流的约束?如何让模型理解开发阶段?如何避免局部优化破坏整体规划?等问题。
4)迭代开发也可以是高效的
EvoDev 的实验结果表明,虽然迭代开发通常会增加调用开销和时间,但由于其能够显著减少无效生成、大规模返工、功能遗漏以及后期修复成本,整体单位成本产出反而可能更高。这一点其实与传统软件工程非常类似。瀑布流开发看起来“步骤更少”,但一旦后期出现结构问题,返工成本往往会指数级增长。而迭代式开发虽然前期投入更高,却能够持续修正问题,从而降低整体系统失控风险。对于智能体软件工程而言,这可能意味着:“一次生成完成应用”并不一定是最优路径。真正可扩展的软件开发系统,或许更应该具备持续演化能力、可中断能力、可观测能力、可修正能力。而这,也正是 EvoDev 想要探索的方向。
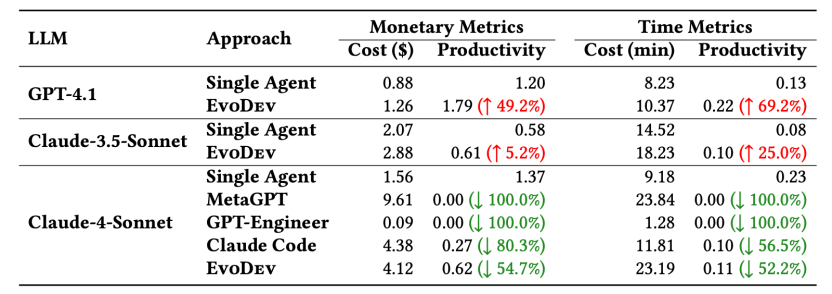
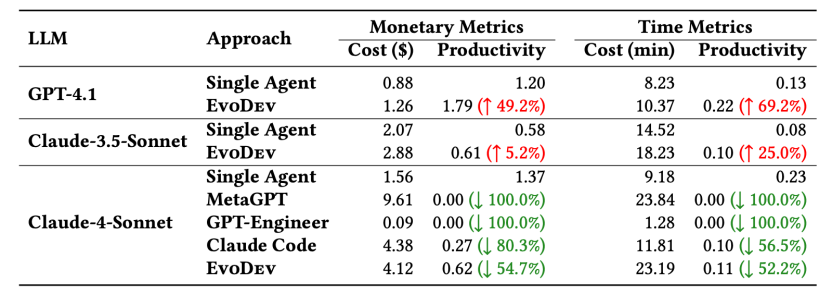
EvoDev与单智能体的开销比较,尽管开销有所提升,但是往往能换来更高的投入产出比(Productivity 定义为功能完整度和开销的比值)
总结:从“代码生成”走向“系统演化”
EvoDev 所展示的,并不仅仅是一种效果更好的开发框架。它真正重要的地方在于:它重新讨论了“智能体应该如何开发软件”。过去,大模型软件工程的核心目标,是让模型能够生成更多更正确的代码。而 EvoDev 所代表的方向,则开始重新关注:如何组织开发流程?如何管理上下文?如何建模系统演化?如何让智能体具备长期开发能力?从 Task 到 Feature,从线性流程到依赖结构,从空间上下文到时间上下文,EvoDev 所做的,本质上是在将软件开发从“任务执行过程”重新定义为“系统演化过程”。这或许也是未来 AI 软件工程真正值得关注的方向。
因为当模型能力逐渐趋近之后,真正决定系统上限的,很可能不再是模型本身,而是:我们究竟如何设计“软件工程”这件事。



作者简介
刘俊伟,复旦大学CodeWisdom团队博士生,导师为彭鑫教授。研究方向为基于大模型智能体的生成式软件开发与维护,相关研究成果发表在TOSEM、ISSTA、NIPS等高水平国际期刊与会议上。

审核修改
彭鑫,复旦大学计算与智能创新学院副院长、教授,国家级高层次人才计划入选者。中国计算机学会(CCF)杰出会员、软件工程专委会副主任、开源发展委员会常务委员,中国汽车工程学会汽车基础软件分会副主任,《Journal of Software: Evolution and Process》联合主编(Co-Editor),《ACM Transactions on Software Engineering and Methodology》、《Empirical Software Engineering》、《Automated Software Engineering》、《软件学报》等期刊编委。主要研究方向包括软件智能化开发、AI原生与云原生系统、泛在计算软件系统、智能汽车及工业软件等。研究工作多次获得IEEE Transactions on Software Engineering年度最佳论文奖、ICSM最佳论文奖、ACM SIGSOFT杰出论文奖、IEEE TCSE杰出论文奖等奖项。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)