一键jar包批量反编译jar,可联动idea,trae等
摘要: Fuck Jar是一款批量反编译Java JAR文件的图形化工具,解决了传统工具效率低下的问题。支持递归处理多层目录,保留原始文件结构,自动反编译class文件为Java源码。v2.0.0版本新增多级并行处理、智能缓存系统、内部类识别等功能,通过批量传参和线程池技术大幅提升速度。工具内置CFR反编译器,提供拖拽操作和日志实时反馈,输出结果可直接用IDE搜索分析。需预装Java环境,适合代码
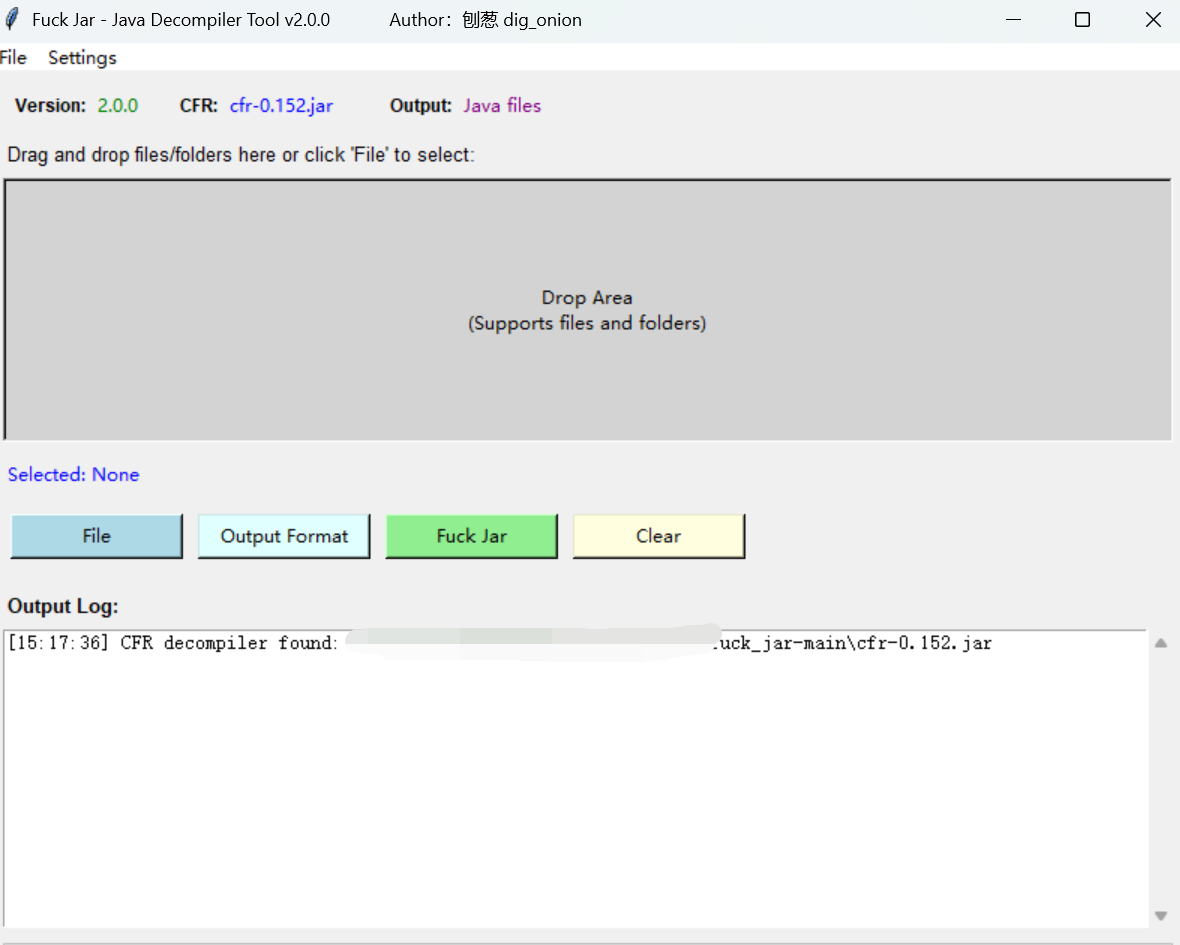
批量反编译jar批量反编译 (已升级)
当我们需要对java项目进行逆向,代码审计等操作的时候,jar包真的很烦人,ij idea 虽然可以自动打开jar,但是对里面的class文件无法进行索引,连个public关键词都搜不到,id-gui 工具虽然可以很好的将jar反编译为java文件,但是每次只能处理一个jar包,效率真的低啊,于是一怒之下,写了个图形化的jar批量反编译,可以对整个项目进行逆向,不管有几层目录,都可以妥善处理,上G的文件也轻松处理,原模原样的保留其他类型文件,反编译结果会保存在工具的同级目录,这时候用ij idea 再打开就可以轻松搜索自己要找的内容了
使用fuck jar 批量反编译项目,再使用Intellij IDEA 打开 轻松搜索关键字,进行代码审计,逆向分
https://gitcode.com/2201_75640626/fuck_jar(已更新到v2)
https://github.com/Dig-Onion/fuck_jar-Java-Decompiler-Tool-
Fuck Jar - 批量反编译jar(Java Decompiler Tool)
作者信息
- 刨葱 dig_onion
- 版本 2.0.0
依赖项
推荐:
- Python 3.11.9
- Java运行环境(JRE/JDK)java 23.0.1 - 用于运行CFR反编译器
Python包:
- tkinter(通常随Python安装)
- tkinterdnd2(用于拖拽功能)
方法1:一键启动(推荐)
双击 run.bat 即可启动程序
- 自动检查 Python 和 Java 环境
- 自动安装缺失的 Python 依赖
- 自动提示下载 CFR 反编译器(首次运行时)
方法2:手动启动
-
安装依赖:
pip install -r requirements.txt -
运行程序:
python fuck_jar_gui.py
使用步骤
-
选择文件/文件夹:
- 点击 “File” 菜单独立选择文件和文件夹(会连续出现两次选择框,一次为选文件,另一次为文件夹,可取消/直接关闭)
- 或直接将文件/文件夹拖入灰色拖放区域
-
设置线程数(可选):
- 点击"Settings"菜单
- 选择"Set Thread Count"
- 设置并发线程数(根据CPU调整)
-
选择输出格式(可选):
- 点击"Output Format"按钮
- 选择"Java 文件 (反编译,默认)“或"Class 文件 (原样复制)”
- 点击"保存"按钮应用
-
开始处理:
- 点击 “Fuck Jar” 按钮
- 日志区实时显示提取、反编译、复制等步骤进度
- 进度条反映 JAR 级别完成百分比
-
查看结果:
- 输出目录:工作目录下的
decompiled_YYYYMMDD_HHMMSS/ - 每个 JAR 对应一个同名子目录(去掉
.jar后缀) - 目录结构与 JAR 内部完全一致,
.java文件可直接用 IDE 打开
- 输出目录:工作目录下的
功能说明
在对 Java 项目逆向分析的时候,IntelliJ IDEA 无法对 class 文件进行索引,十分恶心,而 JD-GUI 每次只能处理一个 jar 包,相当难受。于是,该项目应运而生——
这是一个基于 Python 的跨平台图形化工具,用于批量反编译 JAR 文件,使用 CFR 反编译器生成真正的 Java 源代码。
🚀 v2.0.0 新版本优化(相比原版 1.0.0 的改进)
| 优化项 | 原版 (1.0.0) | 新版 (2.0.0) |
|---|---|---|
| JAR 级别并行 | 逐个串行处理 | ThreadPoolExecutor 最多 8 个 JAR 同时处理 |
| 文件复制 | 逐文件串行复制 | 线程池 16 路并行复制 |
| 批量 CFR 传参 | 有但含致命 Bug(--forcecondy 等无效参数导致全部失败) |
修复参数,同目录 class 一批传给 CFR |
| 缓存系统 | MD5 仅写入、从不读取(死代码) | 完整读写闭环,重复运行秒级完成 |
| $ 内部类识别 | 无特殊处理 | 智能关联父类 .java,缓存有效 |
| 嵌套 JAR 递归 | 无限递归风险 | 最大深度 5 层限制,超限自动串行 |
| CFR 自动下载 | 仅日志提示 | 弹窗询问用户是否下载 |
| 线程安全 | 日志可能丢失、缓存无锁 | 队列日志 + 缓存线程锁 |
| ZipFile 解压 | 并行解压导致随机丢文件 | extractall() 可靠解压 |
| outputdir 路径 | 子目录会导致路径翻倍 | 指向 JAR 根目录,CFR 自行处理子目录 |
| 文件选择 UX | 必须先选文件才能选文件夹 | 两步均可取消跳过 |
核心特性
- 批量反编译:递归扫描目录下所有 JAR,一键全部处理
- 多级并行:JAR 级别 + 目录级别 + IO 级别,三层并行
- 批量传参:同目录 class 一批评传递给 CFR,大幅减少 JVM 启动次数(JVM 启动约 1-2 秒/次,批量传参将 N 次启动降为 1 次)
- MD5 + LRU 缓存:基于文件完整 MD5 哈希的缓存系统(容量 10000),重复运行几乎零开销
- $ 内部类智能识别:CFR 将内部类(如
Xxx$Inner.class)合入父类.java,缓存自动关联父类文件,避免重复处理 - 嵌套 JAR 递归:自动检测并处理 JAR 内部嵌套的 JAR,最大深度 5 层
- 双输出模式:Java 源码(CFR 反编译)或 Class 字节码(原样复制)
- 资源文件保留:非 class 文件(.properties / .xml / .gif / .png 等)全部原样复制
- CFR 自动下载:首次运行时弹窗询问是否自动下载 CFR 反编译器
- 线程安全:多线程环境下日志不丢失、缓存读写互斥
速度优化原理
为什么快?
| 优化点 | 策略 | 效果 |
|---|---|---|
| 批量传 class | 同目录 class 一批传给 CFR(cmd.extend(uncached)) |
JVM 启动从 N 次降到 1 次,单 JAR 提速数十倍 |
| JAR 并行 | ThreadPoolExecutor 同时处理多个 JAR(上限 8) |
N 个 JAR 分成 ⌈N/8⌉ 轮处理 |
| 文件复制 | 线程池 16 路并行 + 先批量创建目录 | IO 密集型操作大幅加速 |
| 缓存复用 | MD5 标识 + LRU 淘汰(容量 10000) | 重复运行几乎零开销,内部类智能关联父类 |
缓存机制详解
每个 class 文件 → 计算完整文件 MD5 → 查缓存字典(线程安全)
├─ 命中 & .java 存在 → 跳过(不调 CFR)
├─ 命中 & 是 $ 内部类 & 父类 .java 存在 → 跳过(CFR 批量模式将内部类合入父类)
└─ 未命中 → 调用 CFR → 成功后写缓存(线程安全)
缓存容量 10000 条,超出则 LRU 淘汰最旧记录。
_hash 计算使用 64KB 分块读取完整文件 MD5,与命令行 md5sum 结果一致。
文件结构
fuck_jar/
├── fuck_jar_gui.py # 主程序(当前推荐版本 v2.0.0)
├── cfr-0.152.jar # CFR 反编译器(已内置)
├── requirements.txt # Python 依赖
├── run.bat # Windows 一键启动脚本
├── run.sh # Linux/macOS 一键启动脚本(暂未调试)
└── README.md # 本文件
注意事项
- Java 环境:必须先安装 Java JRE/JDK,否则 CFR 无法运行
- 磁盘空间:反编译产物通常为原始 JAR 的 3-5 倍,请预留足够空间
- 内存消耗:batch 反编译的 JVM 堆内存根据 batch 大小动态调整(512MB - 1GB),建议不低于 8GB 物理内存
- 并发上限:默认并发数基于 CPU 核心数自动计算,直接使用推荐值即可
- CFR 参数:本工具调用 CFR 0.152,部分版本参数可能不兼容
许可证
本工具仅供学习和研究使用。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)