我终于把 Codex 的用量扒出来了,原来最贵的不是输出。
大家知道,output 才是最贵的,所以 codex-usage 算下来 Pro 20x 拉满换算成 $ 大概是 2000 - 2200 $ ,所以 plus 一周拉满的情况下是 100$ - 110 $ ,当然这都属于极端情况下,因为 LLM 不可能一直在 output。很多时候我们对用量的感觉一直不准,我以前容易下意识觉得输出很长一定很贵,实际跑出来才发现最吓人的往往是 input,是一大坨上
最近我用 Codex 用得越来越多,脑子里一直有个很头疼的问题:我今天到底用了多少?
大家都知道,Codex 改为 token 计费之后,用得很快,于是这个头疼的问题变得更头疼了。
而且网上几乎没有相关的工具可以开箱即用,那怎么办呢?还能咋办,自己撸一个。
我的主要诉求就是通过 Codex 的订阅用量,统计出来换算成 Token ,大概的用量是多少,继而明白 Plus 的 Token 数量和 Pro 20x 的用量大概是多少。
于是我就写了个小工具:Codex Usage Estimator。
项目地址: https://github.com/crisxuan/codex-usage
这个项目就干了一件事情,把 Codex 的用量情况拉出来给你看,并且生成本地的 SVG 图表。
用法很简单。项目拉下来之后,在macOS、Linux 或 WSL 下直接跑:
./run.sh
Windows PowerShell 跑:
.\run.ps1
脚本会创建 Python 虚拟环境,安装 codex-usage 命令,然后跑一遍 doctor、demo 和测试。
或者这些命令都懒得用,那就拉下来直接让 AI 统计用量就完事儿了。
比如我统计了一下当天的 Codex 用量情况:

primary 表示的是 5h 的额度,secondary 表示的是周额度。
从日志可以看出来,我大概昨天一天用了 2 亿的 token ,而且 90% 以上都在用 cached input,为什么这么多?
因为我昨天有个任务用了 goal 命令,不间断跑了将近 20 个小时,现在还在跑,所以 cached input 这么多可以理解。

codex-usage 还会直接生成本地 SVG 图表。
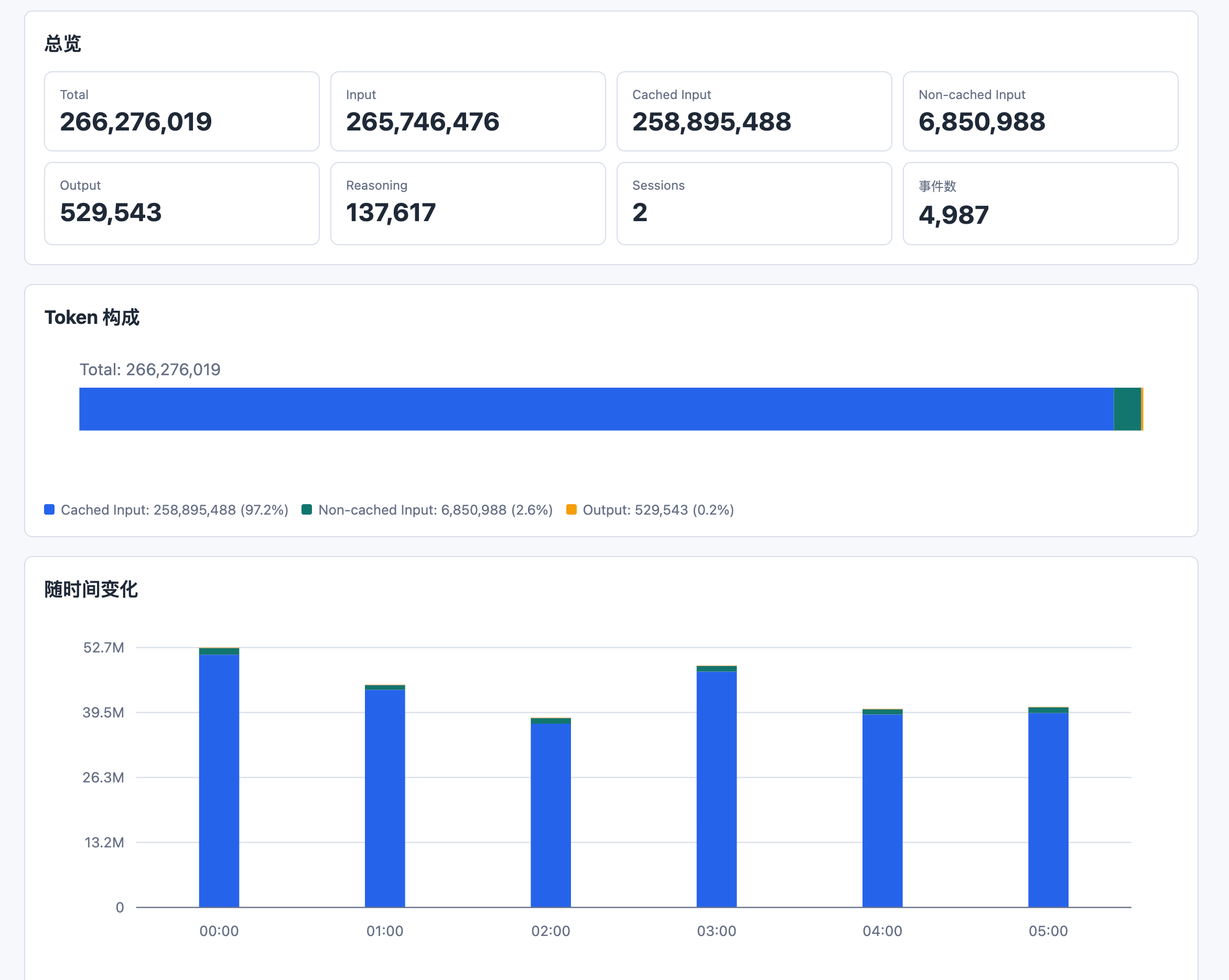
很多时候我们对用量的感觉一直不准,我以前容易下意识觉得输出很长一定很贵,实际跑出来才发现最吓人的往往是 input,是一大坨上下文,所以如果只看 total,很容易误以为每次都在全量烧,实际上可能大部分是 cache 命中。
大家知道,output 才是最贵的,所以 codex-usage 算下来 Pro 20x 拉满换算成 $ 大概是 2000 - 2200 $ ,所以 plus 一周拉满的情况下是 100$ - 110 $ ,当然这都属于极端情况下,因为 LLM 不可能一直在 output 。
再说一下技术实现。
项目技术栈也比较简单,没有传统的 “AI 偏好语言”,没有 Next.js,没有数据库,没有后端服务,没有登录系统,没有花里胡哨的 dashboard。
就是一个 Python CLI。
主要依赖也就一个:
tiktoken>=0.7.0
整个项目大概分成几块:
codex_logs.py:读取 Codex 本地 session 日志里的token_count。reporting.py:把记录汇总成终端里的表格。charts.py:生成本地 HTML + 内联 SVG 图表。transcript.py:解析手动导入的 Markdown 对话记录。storage.py:用 JSONL 存任务组、快照和 turn。tokens.py:用 tiktoken 做 token 估算。cli.py:把这些能力包成命令行。
本地记录直接存在:
.codex-usage/
groups.jsonl
snapshots.jsonl
turns.jsonl
config.json
JSONL 的好处就是简单。
这里重点说一下 tiktoken ,也就是 OpenAI 的官方分词器 https://github.com/openai/tiktoken。
很多人可能一看到 token 统计,就会以为所有 token 都是 tiktoken 算出来的。
并不尽然。
这里面有两个主线任务,
第一个是 Codex 本地日志。
codex-usage codex report --today --lang zh
这里读的是 Codex 本地 session 日志里的 token_count 事件。
这个 token 数本身已经在日志里了,工具做的是扫描、按时间窗口取 delta、汇总、展示。
所以这里不是拿 tiktoken 重新算一遍。
它更像是在本地日志里把账本翻出来。
第二个是手动导入 transcript。
比如你把一段对话或者一段运行日志保存成 Markdown,然后用:
codex-usage turn add --group repo-refactor --file transcript.md
这时候工具不知道 Codex 内部真实请求是什么,只能基于你导入的可见文本估算 token。
这个时候才会用到 tiktoken。
如果你指定模型,并且 tiktoken 能识别,它就按模型对应的 encoding 来算。
所以 tiktoken 在这里的作用不是“破解 Codex 内部用量”,而是:
把你本地可见的文本,换成一个相对靠谱的 token 估算值。
比如 transcript 里可以这样标记:
<!-- codex-usage:user -->
用户输入
<!-- codex-usage:assistant -->
助手输出
<!-- codex-usage:tool -->
工具输出
<!-- codex-usage:file-context -->
文件上下文
这样导入之后,它就能分别估算用户输入、助手输出、工具输出、文件上下文。
这比一股脑把整篇 transcript 当成一坨文本要好一点。
这里还做了一个任务组的逻辑,为什么要做任务组?
因为我觉得得知道不同任务类型的消耗大概有多少:因为简单聊天、基本代码修改和大项目重构、长时间 agent run 完全不是一个东西。
所以这些类型不能混在一起。
比如你今天用了 5%。
那到底是因为问了几个问题?
还是因为让它跑了 8 小时?
还是因为你把半个仓库都塞给它了?
不分组的话,根本看不出来。
所以工具里有一个 task group 的概念。
比如我可以建一个:
codex-usage group create "repo-refactor" --label code
然后任务开始之前记录一下当前用量:
codex-usage snapshot --group repo-refactor --usage 42
任务结束之后再记一次:
codex-usage snapshot --group repo-refactor --usage 47
中间再把 transcript 或者运行日志导进去。
最后它会告诉你这个任务组里:
- 有多少 turn。
- 估算请求数是多少。
- 工具调用多少次。
- 可见 token 估算是多少。
- 有效 token 估算是多少。
- 用量变化是多少。
- 每 1% 大概对应多少可见 token。
这个功能看起来有点手工。
但这就是我想要的。
因为订阅用量这东西,本来就没法百分百反推。
能建立一个自己的经验表,已经很有价值了。
不过要注意的是,这并不是 Codex 官方的用量统计,所以具体的数据只能是估算。
我这里必须强调一下,免得大家误会。
这个工具不能做的事情有很多,不过也可以作为 TODO 后续来慢慢迭代了。
- 它不能读取隐藏 system prompt。
- 它不能读取 Codex 内部完整请求。
- 它不能知道每次请求到底带了多少不可见工具 schema。
- 它不能知道模型内部到底怎么压缩历史。
- 它不能把订阅百分比直接换算成官方账单。
- 它不能告诉你 OpenAI 后台到底怎么扣额度。
这些目前还做不到,但没准后续会优化,你可以提 PR,也可以提 issue,更重要的是点个 star。
最后,这个 github 开放了微信交流群,这里不再放出来了,真正想提反馈的同学,可以从项目地址里面扫码来进。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)