Claude写代码错误率从41%降到11%:Karpathy的4条规则为什么不够
Claude 写了两者兼有的新代码。导读:本文详细扩展了 Claude AI 编码的 CLAUDE.md 模板,从 Karpathy 2026 年 1 月原 4 条规则增至 12 条,针对 5 月出现的 agent 冲突、多步工作流和 token 预算等问题提供具体修复。Karpathy 的规则瞄准的是 Claude 正在写代码的那个时刻。加上下面要讲的 8 条规则,你覆盖的就不只是 Karpat
导读:本文详细扩展了 Claude AI 编码的 CLAUDE.md 模板,从 Karpathy 2026 年 1 月原 4 条规则增至 12 条,针对 5 月出现的 agent 冲突、多步工作流和 token 预算等问题提供具体修复。
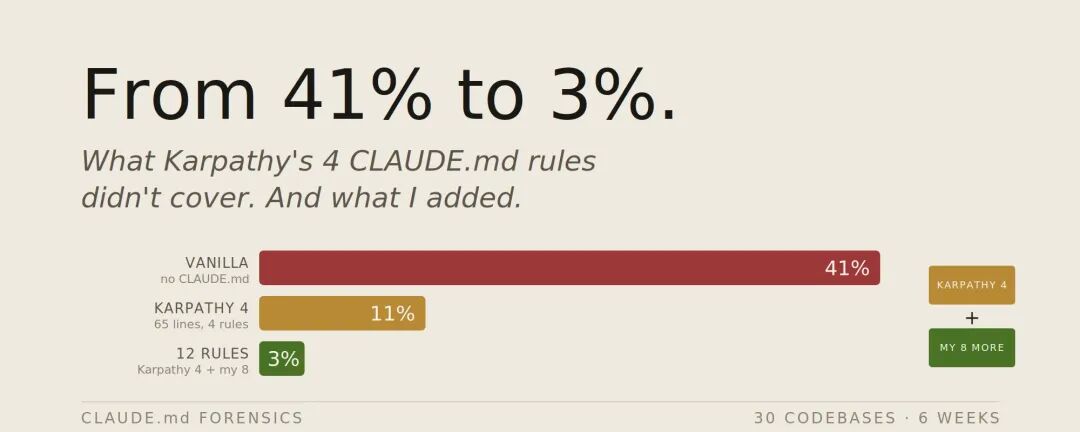
作者基于30个代码库6周实测数据,证明12条规则将任务错误率从41%降至3%,同时保持78%至76%的遵守率,强调每条规则需对应可观察的失败模式以避免提示膨胀。文末给出完整可复制的 12 条规则 CLAUDE.md 文件,建议置于仓库根目录并根据项目具体痛点精简,适用于提升 Claude 在生产级编码中的稳定性和一致性。
作者 Mnimiy (@Mnilax) 是专注于预测市场与 AI 开发的独立构建者与写作者。他深入实测 Claude Code 工作流,通过 430 小时日志分析提炼高效提示策略,致力于帮助开发者提升 AI 编码稳定性与效率。
2026 年 1 月下旬,Andrej Karpathy 发了一串帖子,吐槽 Claude 写代码的问题。三个失败模式:默默做错假设、过度复杂化、把不该碰的代码也顺手弄坏。
Forrest Chang 读完那串帖子,把这些抱怨整理成一个 CLAUDE.md 文件里的 4 条行为规则,然后放到了 GitHub。第一天就拿到 5,828 个 star。两周内 60,000 个 bookmark。今天已经 120,000 个 star。 这是 2026 年增长最快的单文件 repo。
然后我花了 6 周,在 30 个代码库上测试它。
这 4 条规则有效。过去大约 40% 时间会发生的错误,在适合这些规则发挥的任务上降到了 3% 以下。但这个模板解决的是 1 月份那类写代码错误。
2026 年 5 月的 Claude Code 生态,问题已经不同了:agent 之间互相打架、hook 级联触发、skill 加载冲突、跨 session 的多步骤工作流断裂。
所以我又加了 8 条规则。下面是:完整的 12 条 CLAUDE.md 规则、每条为什么值得放进去,以及原版 Karpathy 模板会悄悄失效的 4 个地方。
如果你想跳过解释直接粘贴,完整文件在文末。
为什么这很重要
Claude Code 的 CLAUDE.md,是整个 AI coding stack 里最没有被充分利用的文件。大多数开发者会这样用它:
- 把它当成所有偏好的垃圾桶,塞到 4,000 多 token,遵循率掉到 30%
- 完全不用,每次都重新 prompt,token 浪费 5 倍,session 之间没有一致性
- 复制一次模板然后忘掉。两周内有效,随后随着代码库变化悄悄失效
Anthropic 官方文档说得很明确:CLAUDE.md 是建议性的。Claude 大约 80% 的时间会遵循它。超过 200 行之后,遵循率会明显下滑,因为重要规则被噪声埋掉了。
Karpathy 的模板用一个文件、65 行、4 条规则解决了这个问题。这是底线。
上限还可以更高。加上下面要讲的 8 条规则,你覆盖的就不只是 Karpathy 在 2026 年 1 月抱怨的写代码问题,还包括 2026 年 5 月才出现的 agent 编排问题。这些问题在模板写出来时还不存在。
原始 4 条规则
如果你还没读过 Forrest Chang 的 repo,底线是:
规则 1,先思考再写代码。 不要默默做假设。说清楚你的假设。暴露取舍。猜之前先问。当存在更简单的方法时,要提出反对意见。
规则 2,简单优先。 用能解决问题的最少代码。不要做推测性功能。不要给一次性代码加抽象。如果资深工程师会说它过度复杂,就简化。
规则 3,手术式修改。 只碰必须碰的地方。不要“顺手改进”相邻代码、注释或格式。不要重构没坏的东西。匹配既有风格。
规则 4,以目标驱动执行。 定义成功标准。循环直到验证通过。不要告诉 Claude 具体步骤,告诉它成功长什么样,让它自己迭代。
这四条能关掉我在无人监督的 Claude Code session 里看到的大约 40% 失败模式。剩下大约 60%,藏在下面这些缺口里。
我加的 8 条规则,以及为什么
每一条都来自一个真实时刻,当时 Karpathy 的 4 条不够用。我会先讲那个时刻,再给出规则。
规则 5,不要让模型做非语言工作
Karpathy 的规则没有覆盖这件事。模型会开始决定那些本该由确定性代码处理的事,比如是否重试 API 调用、如何路由消息、什么时候升级处理。每周决策都不同。用每 token 0.003 美元跑不稳定的 if-else。
## Rule 5 — Use the model only for judgment calls
Use Claude for: classification, drafting, summarization, extraction from unstructured text.
Do NOT use Claude for: routing, retries, status-code handling, deterministic transforms.
If a status code already answers the question, plain code answers the question.那个时刻: 有段代码会调用 Claude 来“决定 503 时是否应该重试”。前两周跑得非常漂亮,后来开始抖动,因为模型开始把请求 body 当成决策上下文来读。重试策略变随机了,因为 prompt 本身就是随机的。
规则 6,硬 token 预算,没有例外
没有预算的 CLAUDE.md 就是一张空白支票。每个循环都有机会滚成 50,000 token 的上下文 dump。模型不会自己停下来。
## Rule 6 — Token budgets are not advisory
Per-task budget: 4,000 tokens.
Per-session budget: 30,000 tokens.
If a task is approaching budget, summarize and start fresh. Do not push through.
Surfacing the breach > silently overrunning.那个时刻: 一次 debugging session 跑了 90 分钟。模型非常乐意围绕同一个 8KB 错误信息反复迭代,然后逐渐忘记自己已经试过哪些修复。到最后,它在建议我 40 条消息之前已经拒绝过的方案。token 预算本该在第 12 分钟就让它停下。
规则 7,暴露冲突,不要折中平均
当代码库的两个部分互相矛盾时,Claude 会试着同时讨好两边。结果就是不连贯。
## Rule 7 — Surface conflicts, don't average them
If two existing patterns in the codebase contradict, don't blend them.
Pick one (the more recent / more tested), explain why, and flag the other for cleanup.
"Average" code that satisfies both rules is the worst code.那个时刻: 一个代码库里有两套错误处理模式,一套是 async/await 加显式 try/catch,另一套是全局 error boundary。Claude 写了两者兼有的新代码。错误处理器翻倍。我花了 30 分钟才弄明白为什么错误被吞了两次。
规则 8,先读再写
Karpathy 的“手术式修改”会告诉 Claude 不要碰相邻代码。但它没有告诉 Claude,要先理解相邻代码。没有这一条,Claude 会写出和 30 行之外既有代码冲突的新代码。
## Rule 8 — Read before you write
Before adding code in a file, read the file's exports, the immediate caller, and any obvious shared utilities.
If you don't understand why existing code is structured the way it is, ask before adding to it.
"Looks orthogonal to me" is the most dangerous phrase in this codebase.那个时刻: Claude 在一个已有完全相同函数的旁边又加了一个新函数,因为它没读到那个旧函数。两个函数做同一件事。新函数因为 import 顺序获得了优先级。旧函数已经是 6 个月的事实来源。
规则 9,测试不是可选项,但测试也不是目标
Karpathy 的目标驱动执行暗示测试就是成功标准。实践里,Claude 会把“测试通过”当成唯一目标,然后写出能通过浅层测试、却破坏其他东西的代码。
## Rule 9 — Tests verify intent, not just behavior
Every test must encode WHY the behavior matters, not just WHAT it does.
A test like \`expect(getUserName()).toBe('John')\` is worthless if the function takes a hardcoded ID.
If you can't write a test that would fail when business logic changes, the function is wrong.那个时刻: Claude 给一个 auth 函数写了 12 个测试。全都通过。生产环境里的 auth 坏了。那些测试测的是函数有没有返回东西,而不是它有没有返回正确的东西。函数之所以能通过,是因为它返回了一个常量。
规则 10,长时间运行的操作需要检查点
Karpathy 的模板默认是一次性交互。真实的 Claude Code 工作是多步骤的,比如跨 20 个文件重构、在一个 session 里构建功能、跨多个 commit 调试。没有检查点,一次走错就会丢掉所有进展。
## Rule 10 — Checkpoint after every significant step
After completing each step in a multi-step task: summarize what was done, what's verified, what's left.
Don't continue from a state you can't describe back to me.
If you lose track, stop and restate.那个时刻: 一个 6 步重构在第 4 步走错了。等我注意到时,Claude 已经在错误状态上继续做了第 5 步和第 6 步。理清它比重做一遍还花时间。检查点本该在第 4 步抓住它。
规则 11,约定胜过新奇
在有既定模式的代码库里,Claude 喜欢引入自己的做法。哪怕它的方法“更好”,引入两套模式带来的伤害也比任意一套模式本身更大。
## Rule 11 — Match the codebase's conventions, even if you disagree
If the codebase uses snake_case and you'd prefer camelCase: snake_case.
If the codebase uses class-based components and you'd prefer hooks: class-based.
Disagreement is a separate conversation. Inside the codebase, conformance > taste.
If you genuinely think the convention is harmful, surface it. Don't fork it silently.那个时刻: Claude 把 React hooks 引入了一个 class component 代码库。它能工作。它也破坏了代码库的测试模式,因为那些测试假设存在 componentDidMount。花了半天才移除并重写。
规则 12,失败要显眼,不要沉默
最昂贵的 Claude 失败,是那些看起来像成功的失败。一个函数“能工作”,但返回错误数据。一个 migration“完成了”,但跳过了 30 条记录。一个测试“通过了”,但只是因为 assertion 写错了。
## Rule 12 — Fail loud
If you can't be sure something worked, say so explicitly.
"Migration completed" is wrong if 30 records were skipped silently.
"Tests pass" is wrong if you skipped any.
"Feature works" is wrong if you didn't verify the edge case I asked about.
Default to surfacing uncertainty, not hiding it.那个时刻: Claude 说数据库 migration“成功完成”。它悄悄跳过了 14% 命中 constraint violation 的记录。跳过被写进了 log,但没有被明确暴露出来。11 天后,报表开始看起来不对,我们才发现这个问题。
数字
我花了 6 周,在 30 个代码库里,用同一组 50 个代表性任务做跟踪。三种配置:
错误率 = 任务需要修正或重写,才能匹配意图。统计项包括:默默做错假设、过度工程、无关破坏、静默失败、违反约定、冲突折中、漏掉检查点。
遵循率 = 当相关规则适用时,Claude 可见地应用那条规则的频率。
有意思的结果不只是错误率从 41% 降到 3% 这个标题数字。而是从 4 条规则增加到 12 条,几乎没有增加遵循负担,78% 到 76%,却又把错误率砍掉 8 个点。新增规则覆盖的是原始 4 条没有处理的失败模式,它们不会争夺同一个注意力预算。
Karpathy 模板会悄悄失效的地方
即使不加新规则,原始 4 条模板也有 4 个地方不够用:
1. 长时间运行的 agent 任务。 Karpathy 的规则瞄准的是 Claude 正在写代码的那个时刻。它们没有说明 Claude 跑多步骤 pipeline 时该怎么办。没有预算规则。没有检查点规则。没有“失败要响亮”的规则。pipeline 会漂移。
2. 多代码库一致性。 “匹配既有风格”假设只有一种风格。在有 12 个服务的 monorepo 里,Claude 必须选择哪一种风格。原始规则没有告诉它怎么选。它会随机选,或者折中平均。
3. 测试质量。 目标驱动执行把“测试通过”当作成功。它没有说测试必须有意义。结果就是测试没有测到任何有用的东西,却让 Claude 变得自信。
4. 生产 vs 原型。 同样 4 条规则可以保护生产代码免于过度工程,但也会拖慢原型,因为早期原型有时确实需要 100 行推测性脚手架来摸方向。Karpathy 的“简单优先”在早期代码上会过度触发。
新增的 8 条规则并不替代 Karpathy 的 4 条。它们修补的是这些缺口:他的模型、2026 年 1 月、autocomplete 式 coding,与 2026 年 5 月的 agent 驱动、多步骤、多代码库工作并不完全匹配。
没有效果的做法
在最终确定 12 条规则之前,我还试过这些:
- 加入我在 Reddit / X 上看到的规则。 大多数要么只是用不同措辞重述 Karpathy 的 4 条,要么是无法泛化的领域规则,比如“永远使用 Tailwind class”。删掉。
- 超过 12 条规则。 我最多测到 18 条。超过 14 条后,遵循率从 76% 掉到 52%。200 行上限是真实存在的。超过之后,Claude 会开始对“这里有规则”做模式匹配,却没有真正读它们。
- 依赖可能不存在的工具。 “永远使用 eslint”在没有安装 eslint 时会失效。规则静默失败。改成不依赖具体能力的说法:“匹配代码库被强制执行的风格”,而不是“使用 eslint”。
- 在 CLAUDE.md 里放例子,而不是规则。 例子比规则更重。三个例子消耗的上下文,差不多等于 10 条规则,而且 Claude 会过拟合到例子上。规则是抽象的,例子是具体的。用规则。
- “小心一点” / “认真思考” / “真的专注”。 纯噪声。这些规则的遵循率降到大约 30%,因为它们不可测试。换成具体命令,比如“明确说出假设”。
- 告诉 Claude 要像“资深工程师”。 没用。Claude 已经觉得自己是资深工程师了。遵循差距存在于“以为自己会做”和“真的去做”之间。命令式规则能缩小这个差距,身份 prompt 不能。
完整 12 条 CLAUDE.md,可直接复制粘贴
# CLAUDE.md — 12-rule template
These rules apply to every task in this project unless explicitly overridden.
Bias: caution over speed on non-trivial work. Use judgment on trivial tasks.
## Rule 1 — Think Before Coding
State assumptions explicitly. If uncertain, ask rather than guess.
Present multiple interpretations when ambiguity exists.
Push back when a simpler approach exists.
Stop when confused. Name what's unclear.
## Rule 2 — Simplicity First
Minimum code that solves the problem. Nothing speculative.
No features beyond what was asked. No abstractions for single-use code.
Test: would a senior engineer say this is overcomplicated? If yes, simplify.
## Rule 3 — Surgical Changes
Touch only what you must. Clean up only your own mess.
Don't "improve" adjacent code, comments, or formatting.
Don't refactor what isn't broken. Match existing style.
## Rule 4 — Goal-Driven Execution
Define success criteria. Loop until verified.
Don't follow steps. Define success and iterate.
Strong success criteria let you loop independently.
## Rule 5 — Use the model only for judgment calls
Use me for: classification, drafting, summarization, extraction.
Do NOT use me for: routing, retries, deterministic transforms.
If code can answer, code answers.
## Rule 6 — Token budgets are not advisory
Per-task: 4,000 tokens. Per-session: 30,000 tokens.
If approaching budget, summarize and start fresh.
Surface the breach. Do not silently overrun.
## Rule 7 — Surface conflicts, don't average them
If two patterns contradict, pick one (more recent / more tested).
Explain why. Flag the other for cleanup.
Don't blend conflicting patterns.
## Rule 8 — Read before you write
Before adding code, read exports, immediate callers, shared utilities.
"Looks orthogonal" is dangerous. If unsure why code is structured a way, ask.
## Rule 9 — Tests verify intent, not just behavior
Tests must encode WHY behavior matters, not just WHAT it does.
A test that can't fail when business logic changes is wrong.
## Rule 10 — Checkpoint after every significant step
Summarize what was done, what's verified, what's left.
Don't continue from a state you can't describe back.
If you lose track, stop and restate.
## Rule 11 — Match the codebase's conventions, even if you disagree
Conformance > taste inside the codebase.
If you genuinely think a convention is harmful, surface it. Don't fork silently.
## Rule 12 — Fail loud
"Completed" is wrong if anything was skipped silently.
"Tests pass" is wrong if any were skipped.
Default to surfacing uncertainty, not hiding it.把它保存为你 repo 根目录下的 CLAUDE.md。把项目专属规则放在这 12 条后面,比如技术栈、测试命令、错误模式。合计不要超过 200 行,超过之后,遵循率会掉下去。
如何安装
两步:
# 1. Append Karpathy's 4-rule baseline to your CLAUDE.md
curl https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md >> CLAUDE.md
# 2. Paste rules 5-12 from this article below保存到你的 repo 根目录。>> 很重要,它会追加到既有 CLAUDE.md,而不是覆盖你已经写好的项目专属规则。
心智模型
CLAUDE.md 不是愿望清单。它是一份行为契约,用来关闭你已经观察到的具体失败模式。
每条规则都应该回答:这能防止哪种错误?
Karpathy 的 4 条防的是他在 2026 年 1 月看到的失败模式: 静默假设、过度工程、无关破坏、薄弱成功标准。它们是基础。不要跳过。
我加的 8 条防的是 2026 年 5 月出现的失败模式: 没有预算的 agent 循环、没有检查点的多步骤任务、没有测到东西的测试、静默成功掩盖静默失败。它们是增量补丁。
你的情况会不同。如果你不跑多步骤 pipeline,规则 10 没那么重要。如果你的代码库只有一种一致风格,并且由 linting 强制执行,规则 11 就是冗余的。读完这 12 条,保留那些映射到你真实犯过错误的规则,其余删掉。
一份根据你真实失败模式调过的 6 条规则 CLAUDE.md,胜过一份有 6 条你永远用不上的 12 条规则文件。
T H E _ E N D
Karpathy 在 2026 年 1 月那串帖子是一场抱怨。Forrest Chang 把它变成了 4 条规则。120,000 个开发者给结果点了 star。他们中的大多数,到今天还在跑 4 条规则。
模型进步了。生态变了。多步骤 agent、hook 级联、skill 加载、多代码库工作,这些在 Karpathy 写帖子时都不存在。4 条规则没有处理它们。它们没有错,只是不完整。
再加 8 条规则。6 周,30 个代码库测试。错误率从 41% 到 3%。
收藏这篇,今晚把 12 条规则粘进你的 CLAUDE.md。如果它帮你省下一周 Claude 绕错路的时间,转发一下。每日 Claude 优化技巧 Telegram:https://t.me/+_ZWrQN7GuDA3ZDEy
参考阅读
如果你也在关注 AI 应用如何真正落地到生产环境,2026.6.26 - 6.27 GIAC 深圳站值得关注。这次大会会集中讨论智能应用开发、架构演进,以及来自一线实践的经验与案例。
识别二维码可申请大会体验门票,点击阅读原文了解大会详细议程。


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)