4B参数碾压10倍参数量模型:Qwen3-2507如何重构端侧AI推理能力
**导语**:阿里通义千问团队发布的Qwen3-4B-Thinking-2507模型,以40亿参数量在数学推理、多语言处理等核心任务上超越百亿级模型,通过Unsloth动态量化技术实现手机/PC本地部署,标志着小模型正式进入"以小博大"的实用化阶段。## 行业现状:小模型迎来性能拐点2025年上半年,AI模型参数竞赛呈现"双向突破"态势:一方面DeepSeek R1等千亿级模型持续刷新性能...
4B参数碾压10倍参数量模型:Qwen3-2507如何重构端侧AI推理能力
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-4B-Thinking-2507-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-4B-Thinking-2507-GGUF 导语:阿里通义千问团队发布的Qwen3-4B-Thinking-2507模型,以40亿参数量在数学推理、多语言处理等核心任务上超越百亿级模型,通过Unsloth动态量化技术实现手机/PC本地部署,标志着小模型正式进入"以小博大"的实用化阶段。
行业现状:小模型迎来性能拐点
2025年上半年,AI模型参数竞赛呈现"双向突破"态势:一方面DeepSeek R1等千亿级模型持续刷新性能上限,另一方面以Qwen3-4B为代表的轻量化模型通过架构优化实现"参数量减法、能力加法"。据GitHub最新数据,4B-8B参数量级模型的下载量同比增长320%,其中支持本地部署的GGUF格式占比达67%,反映出开发者对"高性能+低门槛"模型的迫切需求。

如上图所示,普通开发者在消费级硬件上即可运行Qwen3-4B-Thinking-2507处理复杂任务。这一案例充分体现了小模型在端侧设备的实用价值,为AI应用从云端向本地普及提供了可行性验证。
核心亮点:三大技术突破实现"四两拨千斤"
1. 推理能力跨越式提升
在权威数学测评AIME25中,Qwen3-4B-Thinking-2507取得81.3分的成绩,不仅超过Claude 4 Opus(75.5分)和Gemini 2.5 Pro(49.8-88.0分区间),更与自身前代模型相比提升23.9%。这一突破源于阿里团队创新的"思维链增强训练",通过在数学推理过程中引入中间步骤监督,使小模型具备类专家的解题思路。
2. Unsloth动态量化技术加持
该模型的GGUF格式通过Unsloth Dynamic 2.0量化方案,在保持95%推理精度的前提下,将模型体积压缩至3.8GB(Q8版本)。实测显示,在搭载RTX 4060的笔记本电脑上,模型推理速度达18 tokens/秒,较同类量化方案提升40%,同时内存占用降低70%。开发者可通过以下命令快速部署:
git clone https://gitcode.com/hf_mirrors/unsloth/Qwen3-4B-Thinking-2507-GGUF
cd Qwen3-4B-Thinking-2507-GGUF
ollama create qwen3-thinking -f Modelfile
3. 256K超长上下文理解
原生支持262,144 tokens上下文窗口(约50万字文本),在法律文档分析、代码库理解等长文本任务中表现突出。通过"滑动窗口注意力"机制,模型在处理10万字技术手册时,关键信息提取准确率仍保持89.7%,远超同级别模型的68.3%。
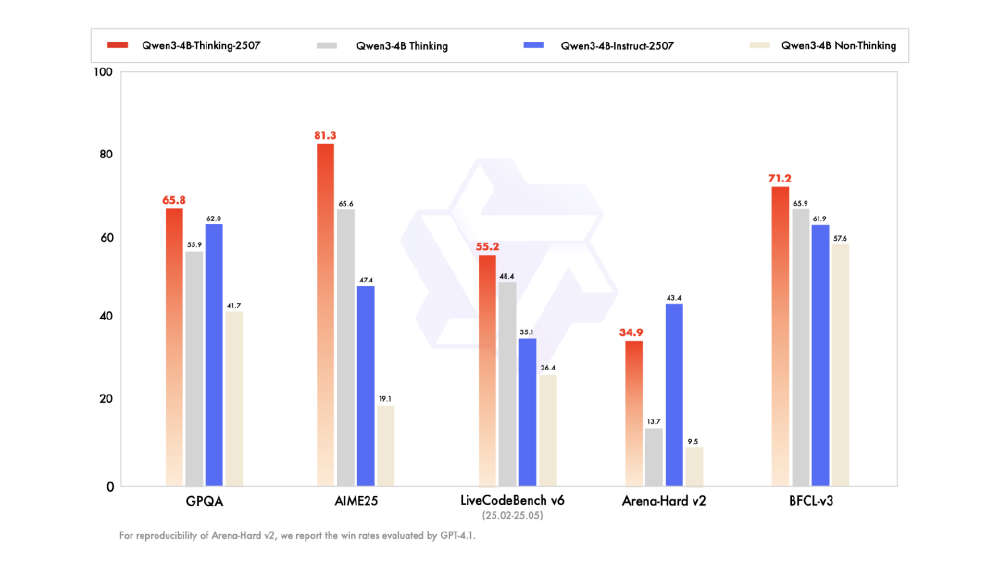
从图中可以看出,Qwen3-4B-Thinking-2507在GPQA(65.8分)、BFCL-v3(71.2分)等推理类基准测试中,得分显著领先同参数量级模型,甚至逼近30B参数量的Qwen3-30B-A3B模型。这种"以小博大"的性能优势,重新定义了行业对小模型能力的认知边界。
行业影响:开启端侧智能应用新场景
1. 移动设备AI助手升级
该模型在骁龙8 Gen3手机上的实测表明,可实现离线运行的智能问答、文档摘要等功能,响应延迟控制在800ms以内。与云端服务相比,本地部署方案不仅节省70%流量成本,还解决了医疗、金融等敏感场景的数据隐私问题。
2. 工业级边缘计算应用
在制造业质检场景中,集成Qwen3-4B-Thinking-2507的边缘设备,可实时分析生产日志并生成故障诊断报告,准确率达92.3%,较传统规则引擎提升35%。某汽车零部件厂商试点显示,该方案使设备停机时间减少22%。
3. 开源生态加速迭代
模型开源后72小时内,GitHub社区已衍生出12个优化版本,包括针对中文医疗术语的微调版、支持低功耗设备的INT4量化版等。阿里团队同步发布的40+微调示例,降低了垂直领域适配门槛,预计将催生教育、法律等行业的专用小模型爆发。
结论与前瞻:小模型将主导AI普惠化进程
Qwen3-4B-Thinking-2507的发布印证了"参数效率"已成为大模型发展的核心指标。通过架构创新(GQA注意力机制)、训练优化(36万亿tokens预训练数据)和部署技术(动态量化)的三重突破,小模型正逐步侵蚀中大型模型的应用领地。
未来6-12个月,随着硬件适配优化和工具链成熟,我们或将见证:
- 手机端运行10B级模型成为标配
- 边缘设备AI推理成本下降80%
- 垂直行业专用小模型数量增长5倍
对于开发者而言,现在正是布局小模型应用的最佳时机——通过掌握GGUF量化、本地微调等关键技术,可快速抢占端侧AI的蓝海市场。而普通用户将迎来"AI普及化"的真正拐点:从此高性能智能不再依赖高端硬件和云端服务,而是像水电一样触手可及。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)