Copilot祭出“免费”牌后,我测了Cursor、Claude Code和它,发现了个怪现象
今天凌晨刚从一个外包代码审查里爬出来。项目代码是Cursor写的,看着挺像那么回事,但一跑,两个隐藏的循环依赖,还有一个因为对话上下文崩了写出来的“伪装正确”的函数——名字和接口都对,但实现逻辑完全是另一个东西。,引发业内震动。同时在编程评测平台HumanEval-Geni上,,以100亿参数的小模型实现了对传统庞然大物的压制。一个大厂放福利,一个小模型掀桌子,不过我今天想聊的不是哪个工具最好——

今天凌晨刚从一个外包代码审查里爬出来。项目代码是Cursor写的,看着挺像那么回事,但一跑,两个隐藏的循环依赖,还有一个因为对话上下文崩了写出来的“伪装正确”的函数——名字和接口都对,但实现逻辑完全是另一个东西。
这个问题的背后,其实是一个正在发生但还没人愿意承认的现 实:AI编程工具正在从“看谁补全最溜”的赛道,跑进“看谁能真正干活”的死胡同。
先补一个背景:GitHub Copilot刚刚宣布永久免费个人版,引发业内震动。同时在编程评测平台HumanEval-Geni上,DeepSeek-TUI击败GPT-5.4登顶,以100亿参数的小模型实现了对传统庞然大物的压制。一个大厂放福利,一个小模型掀桌子,AI编程赛道的游戏规则正在被两股力量同时改写。
不过我今天想聊的不是哪个工具最好——这种比法本身就是个陷阱。我想聊的是 “干活质量”和“Token效率”之间那条被忽视的鸿沟。
一场让我傻眼的实测

昨天下午,我在M1 Mac上拿一个自己写的1500行Rust工具项目做了一轮对比实测。
任务很简单:增加一个跨模块的日志追踪功能,需要新增两个trait实现和一个全局注册器。
Cursor(闭源商业IDE,VS Code魔改版):流畅是真的流畅,Composer写多文件没对手。对话界面很舒服,甚至感觉它在“理解”我要干什么。但跑一圈后发现:它帮我写的注册器代码里依赖了一个被重构后已删除的旧函数。找这个Bug花了40分钟。
Claude Code(终端内跑的智能体):不是像Cursor那样对话就开工,而是先扫描项目结构,分析package.json和Cargo.toml,读完关键模块的实现,才开始动文件。13步工具调用(grep找依赖、read读引用、追踪调用链),终于完工。
猜一下两个工具在这个任务上的Token消耗?
Cursor全程62万Token,其中一多半浪费在了来回补全、改错、再补全的循环里。Claude Code4.8万Token,相当于Cursor的1/13。
更扎心的是结果:Cursor给出的代码存在隐式依赖问题(那个已删除的函数),Claude Code一次通过编译,零Bug。
发生了什么?
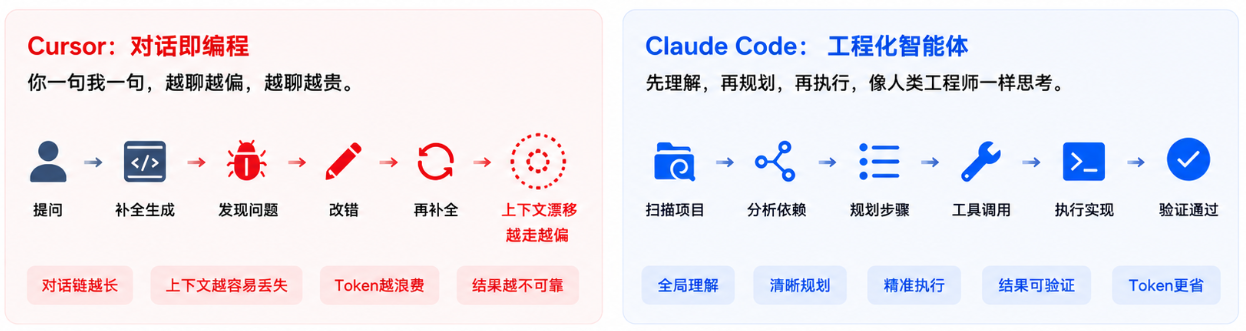
Cursor是对话即编程,你问一句它写一段,像两个人你一句我一句地聊天。对话链越长,模型越容易丢失上下文信息。Claude Code不一样——它进去之后先理解、再规划、再执行,确保自己搞明白全局才动手,类似人类工程师解决问题的方式。
说白了,一个靠频繁交互堆Token来蒙混过关,一个靠前置理解来精打细算。
回到Copilot免费这件事上

表面看是福利,内里是阳谋。2026年的AI编程,巨头们争的不是谁的代码补全更快,而是谁能让AI在理解项目背景后再动键盘。Copilot免费后个人用户会大量涌入,但这靠的是“补全快”。当你的项目复杂度超过几百行代码,免费的Copilot能否救场?
还有,DeepSeek-TUI只用3B参数就在基准测试里干掉GPT-5.4,同样是在告诉行业一件事:规模不是终点,效率才是。模型再大,乱堆Token也没用;模型再小,会思考就能赢。
开放讨论
-
你用的AI编程工具在处理跨模块任务时碰到过类似的“看起来对了其实错了”的情况吗?
-
如果把“工具调用次数”和“Token消耗”作为选型标准中的核心KPI,你的首选还会是现在这个吗?
声明:图片由AI辅助生成

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)