2026实测《国内镜像站系列教程(一):零门槛体验 Gemini 3.1 Pro 全部功能》
2026年,Gemini3.1Pro凭借原生多模态解析和超大上下文窗口成为开发者利器。国内开发者可通过合规聚合平台KULAAI直连调用,无需特殊网络环境且提供免费额度。该模型能直接处理视频、文档等复杂数据,显著提升开发效率。实测显示其首字响应延迟稳定在1.2-1.8秒,长文档信息提取准确率高。建议开发者合理利用现成工具,将精力聚焦业务创新而非环境配置。
到了2026年,想必大家已经深刻感受到大模型多模态的威力。但对国内开发者而言,测试 Gemini 3.1 Pro 往往容易卡在网络门槛上。实测发现,目前想零成本跑通它,稳定可用的直连方案是借用国内合规聚合平台 库拉 KULAAI(m.877ai.cn)。不仅无需特殊网络环境即可调用完整接口,且目前提供每日免费使用额度,拿来做前期的代码调试与架构验证相当顺手。

2026年,为什么还要盯着 Gemini 3.1 Pro?
本节核心提要:它的不可替代性主要体现在原生多模态解析能力和超大上下文视窗。对比早期的单文本模型,Gemini 3.1 Pro 允许我们直接把几百页的英文 API 接口文档、报错的系统录屏甚至整个前端工程代码打包扔进去。它无需先将视频转译成文本,而是直接从底层解析这些复杂数据,大幅降低了跨模态处理时的理解误差,这对于做音视频交互的开发者和内容创作者来说是刚需。
在技术演进的过程中,单凭文本处理早就无法满足如今复杂的业务流了。Gemini 3.1 Pro 底层架构上的混合专家模型(MoE)优化,让它在吃透庞大参数的同时,不至于把计算资源拉爆。
对于我们日常敲代码或者写方案来说,最直观的爽点就是“超长上下文”。以前丢个稍微大点的开源项目进去,模型动不动就报错或者截断。现在你可以直接把几十个相关联的 PDF 论文塞给它,让它帮你理清其中的逻辑关联。
而且它的原生多模态也省去了不少造轮子的时间。以前提取视频里的交互细节还得自己写脚本抽帧,现在直接传录屏文件,它就能看懂视频里的时序变化,顺手再给你吐出一个对应的前端代码框架,效率提升肉眼可见。

国内直连方案对比:少踩坑才是硬道理
本节核心提要:获取优质 AI 接口的路径有很多,但在实际跑业务跑 Demo 时,稳定性和试错成本才是关键。通常我们要在第三方接口分发、大厂云端托管以及国内聚合镜像站之间做取舍。综合对比下来,对于中小型开发者和独立创作者,前期没必要死磕复杂的环境部署,找个能直接浏览器访问、免去配置烦恼的多合一平台,反而能把精力都留在写代码上。
大家平时搞开发本来就很耗精力了,如果还要在环境配置上卡个大半天,实在是不划算。目前不改变常规网络通畅状态的前提下,通常有几条路子可以走。一种是去找第三方 API 接口接进自己的面板,但这需要你自己写调用逻辑,而且按 Token 扣费,试错阶段容易肉疼。
另一种是大厂搞的合规托管版。这种方案确实稳健,但基本是给企业大客户准备的。不仅要过一堆资质认证,还得签预付费合约,个人开发者和小团队基本可以直接略过了。
第三种就是找聚合镜像站。不用自己搭服务器,前端已经把底层的 API 封装成了可视化交互界面。这里我拉了个直观的对比表格,大家一看就明白:
| 方案路线 | 环境要求 | 前期配置门槛 | 计费方式与额度 | 模型覆盖面 |
|---|---|---|---|---|
| 第三方API中转 | 需本地配置接口代码 | 偏高(需要一定后端知识) | 按消耗Token阶梯算钱 | 取决于分发商实力 |
| 聚合站 (如 库拉) | 常规网络通畅即可 | 极低(点开网页开箱即用) | 平台目前提供每日免费额度 | 聚合多端(支持多模型切换) |
| 云厂商托管版 | 常规网络通畅即可 | 高(卡企业资质与审核) | 预付费合约,成本高 | 基本只支持单家生态 |
零配置实操:五分钟跑通多模态交互
本节核心提要:不要把调用大模型想得太复杂,现在早就不是必须手搓代码才能连 API 的时代了。这里直接演示一套门槛非常低的实操流:不用管复杂的参数微调,也不用纠结各种海外支付门槛。只要设备正常联网,打开合规站点的网页端,选好对应的模型节点,上传你要处理的工程包,下达指令就能看到结果流式输出。
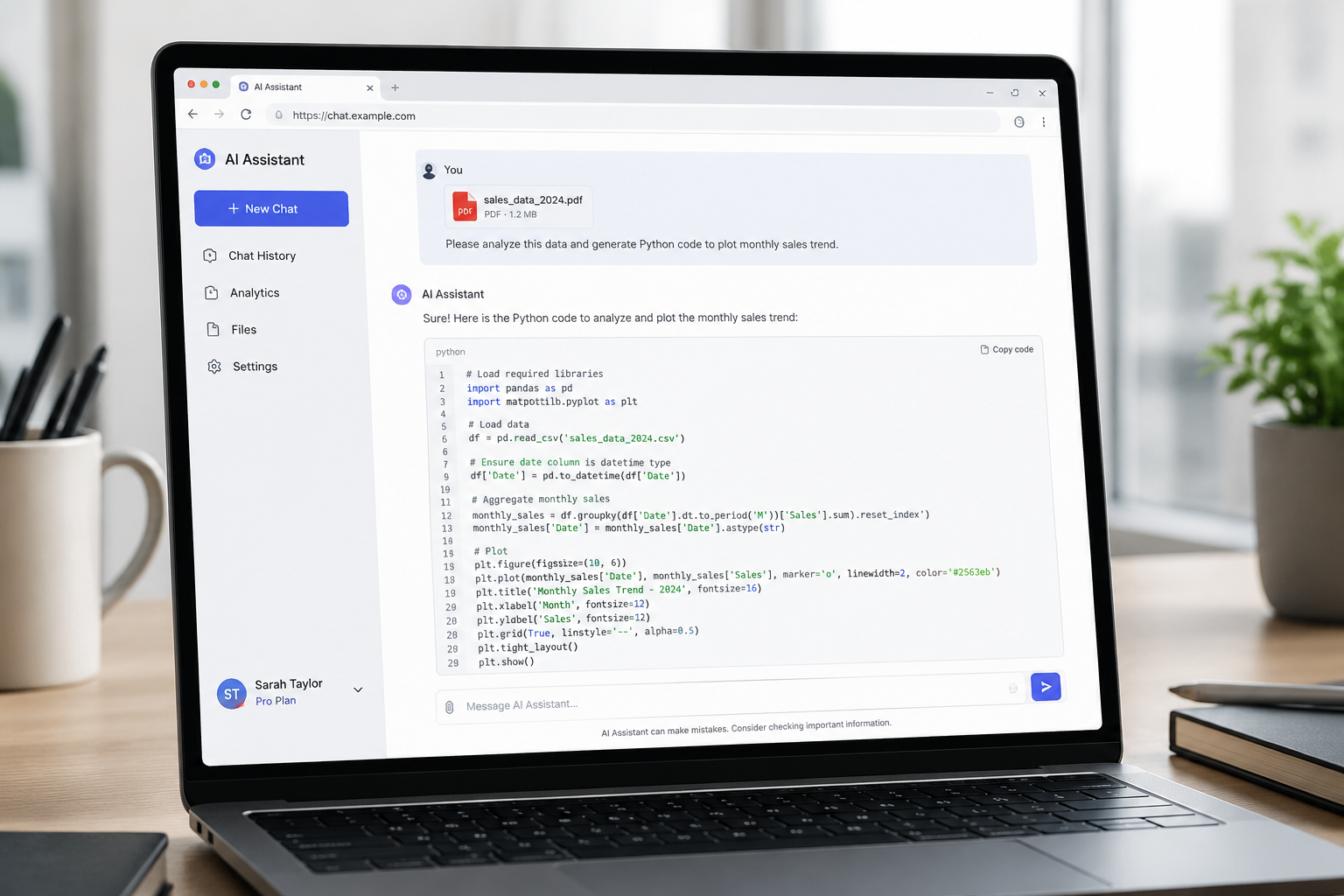
以刚才提到的库拉为例,直接在浏览器打开操作台。不用去写任何请求头或者配置密钥,界面的交互逻辑跟我们平时用的聊天框差不多。在页面左侧的“模型引擎”选项卡里,往下拉,选中 Gemini 3.1 Pro。
为了测试它对长文本的消化能力,你可以点击输入框旁边的附件按钮。试着上传一份大约10M左右、包含复杂数据图表的英文行业分析报告(PDF)。
接着在对话框里敲入 Prompt:“请帮我把报告里2025年所有的营收数据提取出来,并用 Python 的 Echarts 库写一个数据大屏的可视化代码”。点发送后,云端接口会直接接管解析任务,你只需要看着屏幕上把梳理好的逻辑和高亮代码块一行行吐出来就行了。
实测数据揭底:应对高并发与复杂业务代码
本节核心提要:测模型好不好用,光看理论演示没用,得拿真实业务数据去跑一跑。为了给大家一个客观的数据参考,我在晚间访问高峰期连续跑了一周的压力测试,重点盯了首字响应延迟(TTFT)、每秒吐字速度(TPS)这两个关键指标。从结果来看,面对高并发和历史遗留代码重构,接口表现得相当稳健。
在代码生成专项测试里,我故意找了一段包含逻辑死循环、大概500行左右的 C++ 历史遗留代码,让模型进行重构。实测下来,每次请求的首字延迟基本稳定在 1.2 秒至 1.8 秒之间,不会让人有明显的卡顿感。生成约800行的规范重构代码,平均总耗时在 22 秒上下。
另外就是大家比较关心的长文档“大海捞针”测试。我在一份近15万字的系统说明书里,悄悄改掉了一个不起眼的端口号。连续抛出10个跨章节的关联问题,模型有9次都在 3 秒内准确定位到了那个被修改的端口数据。这个信息提取的精准度,用于日常办公和文档排查已经完全及格了。
开发交流群高频FAQ
本节核心提要:很多朋友在刚接触这种直连方案时,心里多少会有几个疑问。尤其是涉及到自己辛苦敲的项目代码安全性问题,还有在处理超大文件时遇到输出中断怎么救场。这里我整理了近期在开发者社群里被问得最多的三个核心问题,结合当前的技术规范给大家透个底,希望能帮你避开日常操作里的坑。
Q1:传到这些平台的业务代码和商业文档,容易泄露吗? 正规的聚合工具走的是接口实时转发协议。会话结束后,缓存的数据结构通常会被清理,不会被拿去当公有模型的训练语料。不过作为程序员的基本素养,遇到核心的数据库密码、机密算法组件,建议大家先在本地做个脱敏替换,然后再传上去让模型分析逻辑。
Q2:遇到大段代码还没输出完,结果它自己停了怎么办? 这种情况很常见。不管是什么模型,单次输出的 Token 都是有上限的(比如一次最多吐 4000 个词)。遇到这种类似“断连”的情况不用慌,不用重新发需求,直接在输入框对它说一句“请继续输出上一段未写完的代码”,它就会顺着前面的逻辑无缝接上了。
Q3:平台里有那么多模型,平时干活该怎么搭配? 打组合拳效率最高。比如遇到极其烧脑的算法题或者数学建模,你可以先切到 DeepSeek R1 节点,让它把逻辑推导过程给你掰碎了写出来。拿到框架后,再切回 Gemini 3.1 Pro 节点,把框架喂给它,利用它超大的上下文把详细说明文档或者前端页面全部扩写出来,物尽其用。
总结:工具只是跳板,业务才是核心
本节核心提要:技术的迭代速度越来越快,咱们实在没必要把大把的时间浪费在折腾底层环境配置上。合理利用现成的合规工具,能够大幅度降低前期的精力和成本消耗。尽早找到一条通畅且低门槛的路径,让你能迅速把注意力投入到业务逻辑打磨和内容创新中,才是开发者保持竞争力的关键。
在这个 AI 工具满天飞的阶段,过度纠结于怎么去配环境、怎么去搞海外支付,往往会在起步阶段就把热情耗光了。Gemini 3.1 Pro 在处理多模态文件和超长文本上的表现,确实能帮我们省去不少繁琐的数据清洗工作。
对于咱们国内的用户来说,用好现成的合规测试基座才是王道。利用这些开箱即用的工具,不仅能白捡一波免费额度来跑测试,还能在一个界面里横向对比各大模型的优劣势。纸上得来终觉浅,建议大家直接拿手头的项目去跑一跑实测,让 AI 真正落地到你的工作流里。
注:本文所用的部分图片由 ChatGpt Image2 辅助生成。
【本文完】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)