把整个代码库变成可查询的知识图谱,有人把这个想法做进了 Claude Code/Cursor,两个月爆了 4.6 万 Star!
graphify 是一款 4.6 万 Star 的开源工具,将代码仓库一键转成知识图谱,嵌入 Claude Code、Cursor 等 AI 编程助手,让 AI 真正\x26quot;看懂\x26quot;代码架构。本文介绍核心功能、安装方法,并与同类工具 llm_wiki 做横向对比,给出清晰选型建议。
摘要:graphify 是一款 4.6 万 Star 的开源工具,将代码仓库一键转成知识图谱,嵌入 Claude Code、Cursor 等 AI 编程助手,让 AI 真正"看懂"代码架构。本文介绍核心功能、安装方法,并与同类工具 llm_wiki 做横向对比,给出清晰选型建议。
上周二我发了一篇 llm_wiki 的文章,没想到流量还不错。
让我意外的是评论区——有好几个朋友问同一个问题:graphify 和它比怎么样?能不能出一篇横向对比?
好,这篇就是答案。看完没有收获来找我。
llm_wiki 是什么、怎么用,上周那篇写得比较详细,不熟悉的可以先回顾一下:👉 Karpathy 的知识库构想被人做成桌面应用了,而且做得相当扎实,已在 Github 上斩获 5.8k+ Star!
这篇直接进入正题——graphify 是什么、核心功能怎么用、和 llm_wiki 本质上有什么不同、该怎么选。
不知道大家有没有遇到过这种情况:
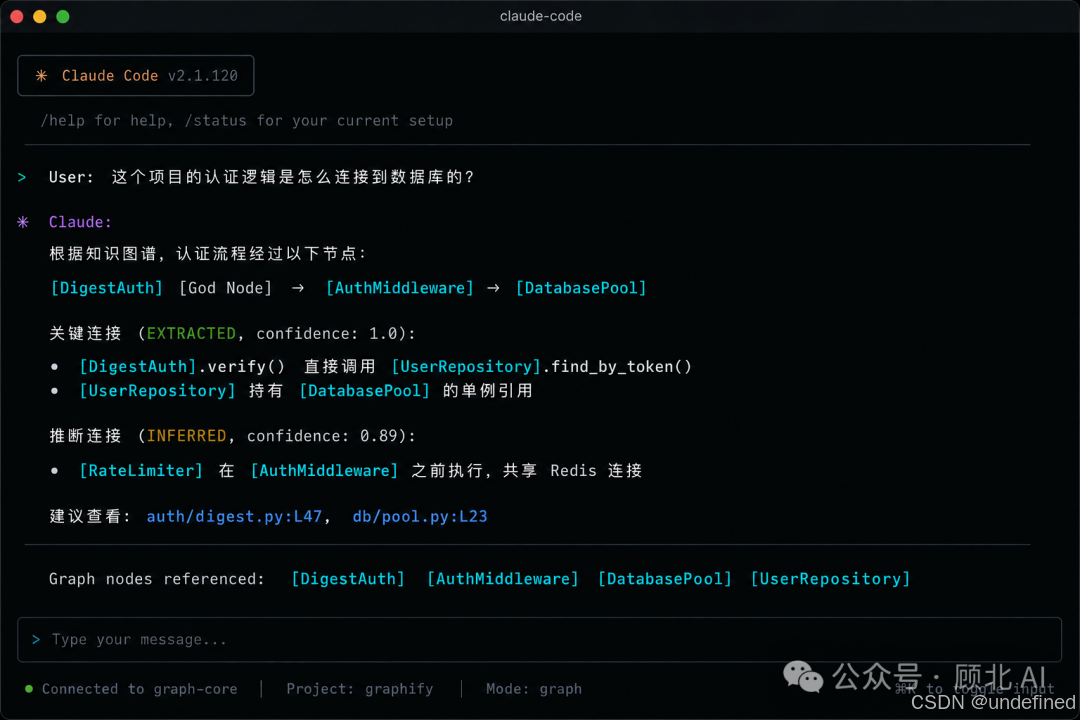
把一个新项目交给 Claude Code 或 Cursor,问一个看似简单的问题——"这个项目的认证逻辑在哪?"——AI 助手开始疯狂调用 grep,翻了七八个文件,最后给你一个半生不熟的回答,还带着"我不确定是否完整"的免责声明。
大项目就更惨了。几十万行代码,AI 每次回答都像在摸象,说不定今天摸到腿,明天摸到尾,很难给你一个整体视角。
根本原因是:AI 没有地图,只有搜索。

graphify 是什么
上个月,一个叫 graphify 的开源项目悄悄爆了——发布不到两个月,GitHub Stars 冲到了 46,281,Forks 超过 5000。
它干的事情用一句话说就是:把你整个代码仓库(代码、文档、PDF、图片、视频)一键转成一张可查询的知识图谱,然后"装进"你的 AI 编程助手里。
从此你的 AI 助手不再靠 grep 找路,而是靠一张提前构建好的"地图"导航。
支持的平台覆盖了几乎所有主流 AI 编程工具:Claude Code、Codex、OpenCode、Cursor、Gemini CLI、GitHub Copilot CLI、VS Code Copilot Chat、Aider……超过 15 个。换句话说,不管你用哪个 AI 助手,基本都能接上。
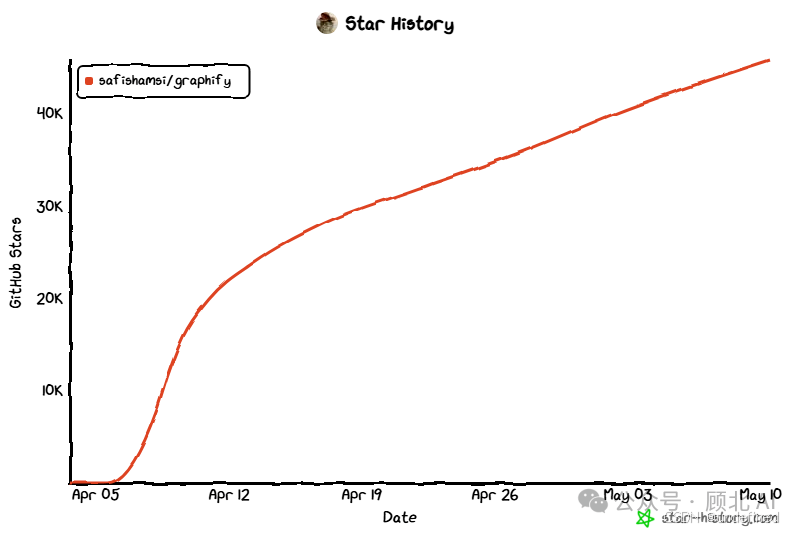
上手只需三行命令
# 安装(推荐用 uv,也支持 pipx 和 pip)
uv tool install graphifyy
# 安装到你的 AI 助手(以 Claude Code 为例)
graphify install
# 在项目目录里,让助手跑起来
/graphify .
注意:PyPI 包名是
graphifyy(双 y),CLI 命令是graphify(单 y)。这个命名有点绕,别装错了。
跑完之后,你会得到三个文件:
graphify-out/
├── graph.html # 可交互可视化,浏览器直接打开,点节点、过滤、搜索
├── GRAPH_REPORT.md # 关键概念、惊喜连接、推荐问题——这是给 AI 看的
└── graph.json # 完整图数据,随时查询
它是怎么构建图的
这里有个细节值得说一下,因为直接影响到隐私安全。
graphify 的提取分两步走:
第一步:本地 AST 解析(无 API 调用)
代码文件(.py、.ts、.go、.rs……共 29 种语言)全部用 tree-sitter 在本地解析——提取类、函数、导入关系、调用图、注释里的 # WHY:/# HACK: 设计说明。这一步源码不出机器,不产生任何 API 费用。
第二步:LLM 语义提取(仅针对文档类文件)
Markdown、PDF、图片、视频——这些非结构化内容才会发送给你已配置好的模型(Claude / Gemini / OpenAI,用的是你自己的 key)做语义提取。视频和音频甚至是用本地 faster-whisper 转录的,同样不出网。
然后两步结果合并,用 Leiden 社区检测算法做聚类——不需要向量数据库,纯图拓扑聚类。
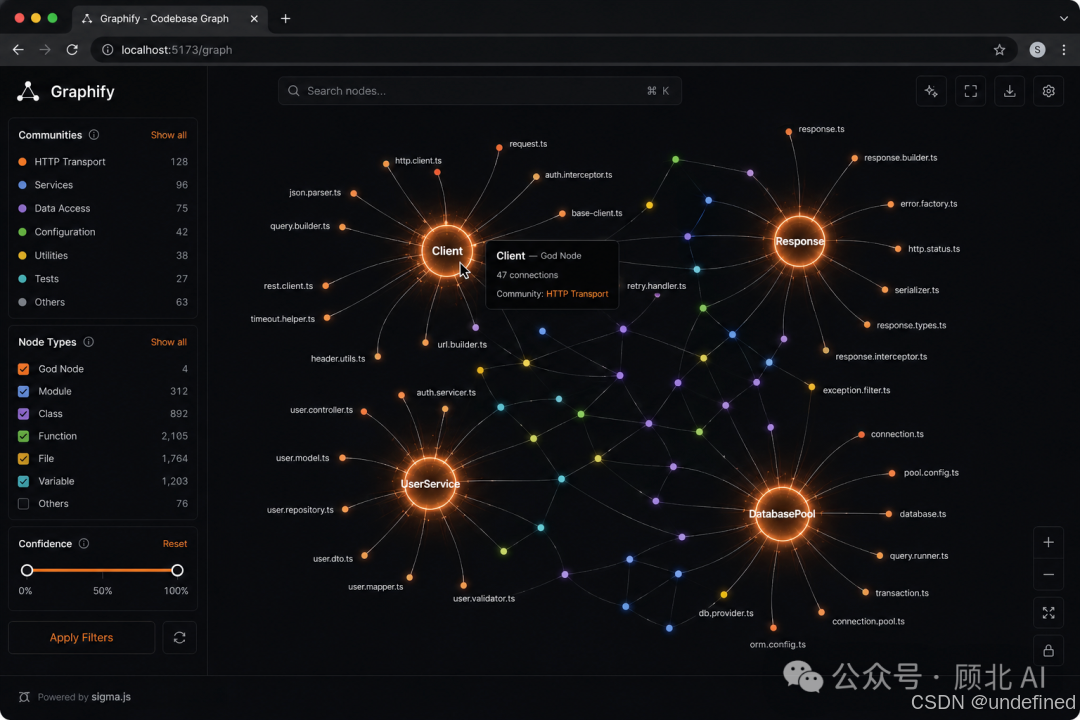
图里有什么好东西
生成的 GRAPH_REPORT.md 里,我觉得最有价值的几个部分:
God Nodes(上帝节点)
连接度最高的核心概念。比如跑了一个 500k 词的代码库,可能发现 Client、Response、Request 是 God Nodes——意味着整个系统都在绕着这几个类转。新人上手一个陌生项目,先看 God Nodes,比读文档快多了。
Surprising Connections(惊喜连接)
这个功能我个人觉得很惊艳。它会找出那些"住在不同文件/模块里,但实际上有强关联"的概念对。比如官方文档里的一个例子:DigestAuth → Response——两个看起来八竿子打不着的东西,实际上存在隐式依赖。这种连接靠 grep 基本找不到。
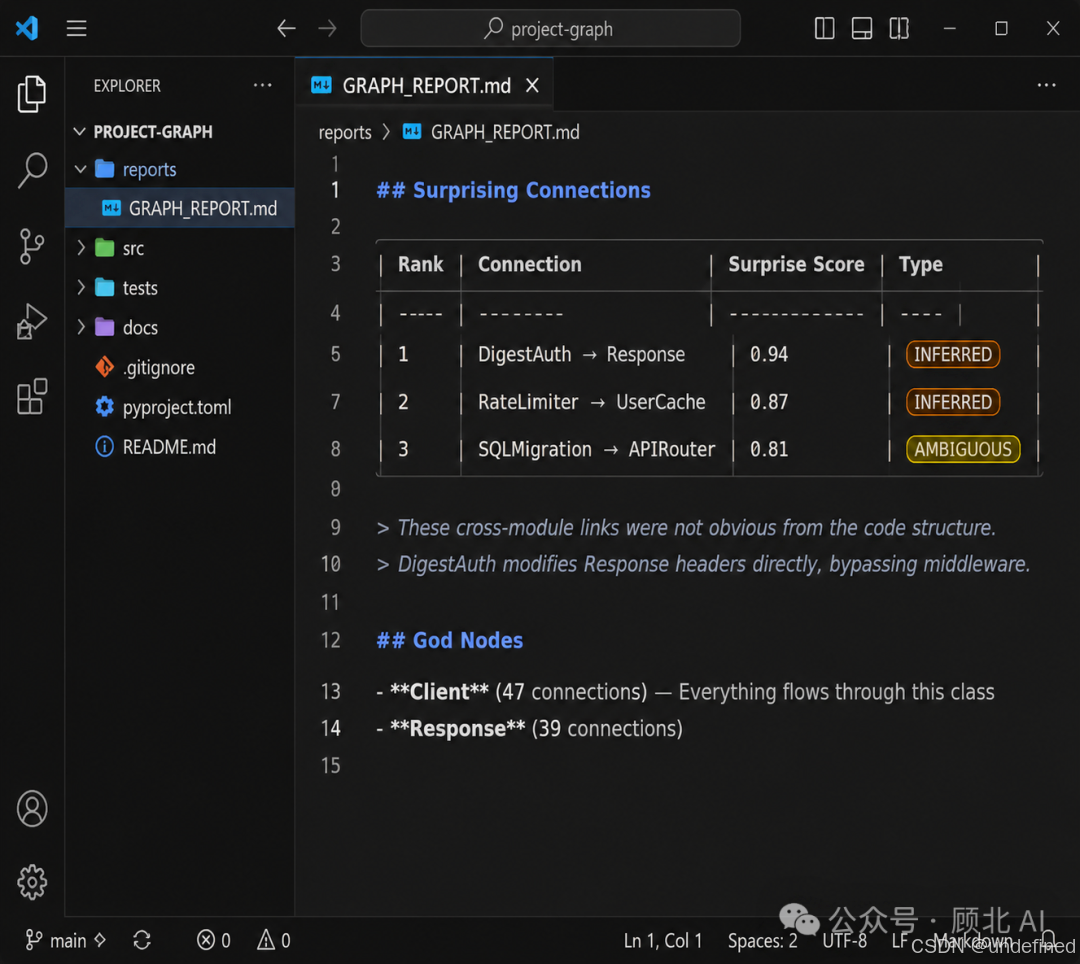
置信度标签
每一条关系边都标了来源:
-
EXTRACTED:直接从源码找到的(置信度 1.0) -
INFERRED:合理推断,带confidence_score(0.0–1.0) -
AMBIGUOUS:不确定,需要人工确认
这个设计很诚实,你知道哪些是"实锤",哪些是"猜的"。
查询命令
建好图之后,可以直接在终端里查:
/graphify query "什么连接了认证模块和数据库?"
/graphify path "UserService" "DatabasePool"
/graphify explain "RateLimiter"
也可以把图暴露成 MCP Server,让助手用工具调用的方式访问:
python -m graphify.serve graphify-out/graph.json
团队协作的正确姿势
graphify-out/ 目录建议直接提交到 git,这样团队里每个人拉代码就自带一张地图。
跑一次:
graphify hook install
之后每次 git commit,AST 层会自动重建(纯本地,无 API 成本)。文档或 PDF 变了,手动跑一次 --update 刷新对应节点就行。
和 llm_wiki 有什么区别
说完 graphify,顺便聊一下前段时间也在 GitHub 上热传的 llm_wiki(约 4000 Stars)。两个项目表面上都在做"知识图谱",实际上是完全不同的东西。
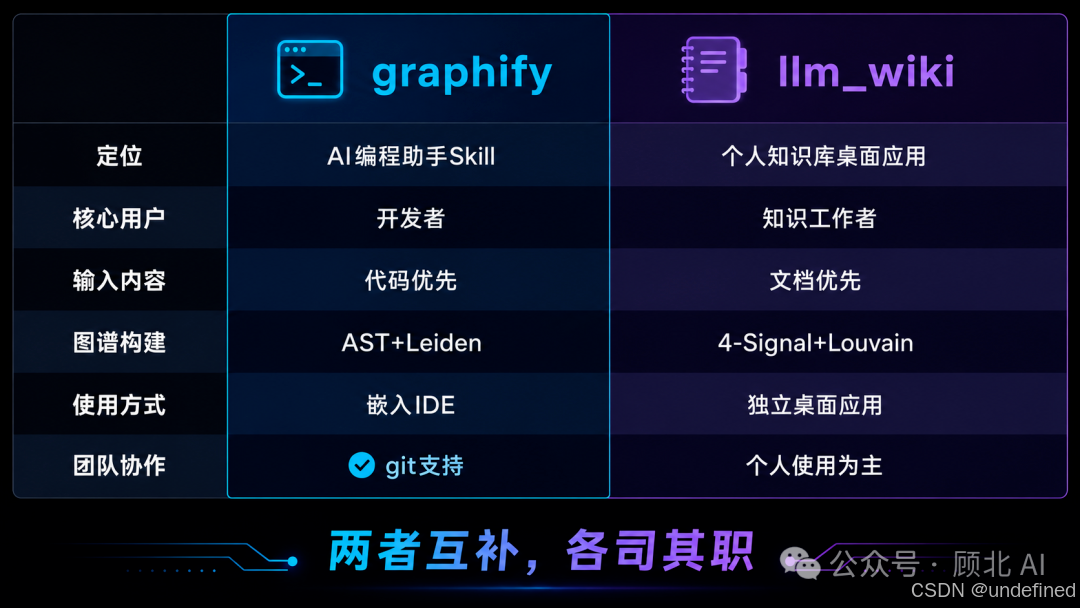
先上一张对比表:
|
维度 |
graphify |
llm_wiki |
|---|---|---|
| 定位 |
AI 编程助手 Skill |
个人知识库桌面应用 |
| 核心用户 |
开发者(理解代码库) |
知识工作者(管理文档/笔记) |
| 输入内容 |
代码优先,兼容文档 |
文档优先(PDF/DOCX/MD) |
| 图谱构建 |
AST + LLM,Leiden 聚类 |
4-Signal 相关性模型 + Louvain 聚类 |
| 图谱权重模型 |
无加权,拓扑聚类 |
Direct link×3.0、Source overlap×4.0…… |
| 使用方式 |
嵌入 IDE / AI 助手(CLI Skill) |
独立桌面应用(Tauri + Rust) |
| 技术栈 |
Python + tree-sitter |
TypeScript + Rust(Tauri v2) |
| 隐私处理 |
代码本地解析,0 API |
文档发给 LLM API 处理 |
| 团队协作 |
graph.json 提交 git,支持自动 merge |
个人使用为主 |
最本质的区别在于:两者都反对"朴素 RAG"(每次查询重新推导),都追求"知识编译一次、持久化维护"。但路子完全不同:
-
graphify 的核心是代码结构图——把代码的调用关系、模块依赖、设计意图全部图化,让 AI 助手"看懂"代码架构。它嵌进你的开发工作流,是工具链的一部分。
-
llm_wiki 的核心是wiki 页面网络——LLM 读完你的文档,帮你写成互相链接的 wiki 条目,形成一个"自我维护的个人知识库"。它是一个独立的桌面应用,更像是 Obsidian 的 AI 强化版。
llm_wiki 的 4-Signal 权重模型挺有意思:Source overlap(共享来源,权重 ×4.0)> Direct link(直接引用,×3.0)> Adamic-Adar(共同邻居,×1.5)> Type affinity(类型相似,×1.0)。这套加权逻辑针对的是文档领域的关联强度,用在代码库上并不合适。
怎么选
-
你是开发者,主要想让 AI 更好地理解你的代码库 → 用 graphify,直接嵌进 Claude Code/Cursor,解决大项目导航的核心痛点。
-
你有大量文档、论文、笔记需要整理,想建一个"会自我维护"的个人知识库 → 试试 llm_wiki,图形界面友好,不需要折腾命令行。
-
两个都想用 → 完全可以并行。graphify 管代码,llm_wiki 管文档,各司其职。
我的实际感受
我在一个约 8 万行的 Python 后端项目上跑了一遍 graphify,整个过程大概 5 分钟(代码 AST 本地跑很快,主要时间花在 Markdown 文档的 LLM 提取上)。
生成的 graph.html 打开之后确实有点震撼,整个系统的模块关系一目了然。GRAPH_REPORT.md 里 Surprising Connections 那栏列出了几个我自己都没意识到的隐式依赖,其中一个确实是潜在的架构风险。
接进 Claude Code 之后的体验变化也比较明显——AI 回答架构相关问题时,能直接引用图里的节点,不再无脑 grep,上下文利用率明显更高。
当然也有不足:图的更新目前还是手动触发(文档层需要用 --update),全自动增量同步还做得不够流畅。不过项目更新很活跃(已发布 94 个版本),这块应该会持续改进。
如果你在用 Claude Code 或 Cursor 开发中大型项目,强烈建议试试。 安装成本极低,收益很直接。
你现在用什么方式让 AI 助手更好地理解你的代码库?欢迎评论区分享你的工具链~
我是顾北,关注我,获取更多好玩有趣的开源仓库!
谢谢你阅读我的文章~
我们下期再见!
相关仓库链接:
graphify 仓库地址:https://github.com/safishamsi/graphify
llm_wiki 仓库地址:https://github.com/nashsu/llm_wiki
PS:本文部分内容由AI辅助创作
推荐阅读
Karpathy 的知识库构想被人做成桌面应用了,而且做得相当扎实,已在 Github 上斩获 5.8k+ Star!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 7
7 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)