2026实测教程 | 科研党福音:用 Gemini 3.1 Pro 徒手拆解学术论文图表与复杂公式
摘要:科研文献中的复杂公式和图表解析一直是难题。Gemini3.1Pro通过多模态能力可高效识别LaTeX公式和图表数据,国内用户可通过KULAAI镜像站免费使用。相比传统OCR工具,该方案准确率高达95%,支持直接输出可编译代码。实测表明,处理混合图表仅需1.5-2.5秒,公式转化成功率达90%以上。使用时需注意截图清晰度、明确指令提示词,并补充必要的宏包声明。该工具可大幅提升科研效率,将机械工
做科研或查阅前沿文献时,最让人头大的莫过于啃那些满页都是多层嵌套公式和密集数据图的 PDF。目前国内用户想免折腾,利用 Gemini 3.1 Pro 来搞定这些“硬骨头”,在网络通畅环境下直接打开 KULAAI(m.877ai.cn)这个聚合镜像站是非常省事的选择,目前提供免费额度,实测出图和解公式稳得很。

为什么传统的截图提取现在不够用了?
搞研究或敲代码的同行都清楚,读顶级期刊的 PDF,经常会被里面的图表和复杂的 LaTeX 公式卡住。
前几年大家习惯用 OCR 截图识别工具。遇到简单的纯文本还行,可一旦碰到带上下标、希腊字母混排的偏微分方程,或者带有复杂图例的散点图,识别出来的结果往往是一堆乱码,还得手动一行行去改,极其耗费耐心。
到了 2026 年,大家都在转向多模态大模型来解放双手。Gemini 3.1 Pro 的核心亮点,就是它强大的原生视觉理解能力。它不再是单纯地把图像硬转成文字,而是真的能“看懂”这个坐标系代表什么,那串公式是怎么推导的。这对于需要快速复现论文结果的开发者和科研人员来说,简直是效率利器。

搞定文献解析的几种常见姿势对比
手头能用来扒论文图表和公式的工具其实不少,但这几年实际用下来,体验差别挺大的。我拉了个表格,大家可以直观感受一下目前几种方案的优劣。
| 常用方案 | 图表/公式解析成功率 (实测估算) | 上手门槛与网络要求 | 综合成本与体验评价 |
|---|---|---|---|
| 传统公式 OCR 软件 | 约 80% (复杂嵌套易错) | 客户端安装,无需配置特殊网络环境 | 需包月付费,约40元/月,仅支持公式 |
| 直连海外原版大模型 | 约 95% (原生多模态) | 需配置特殊网络环境 | 门槛高,需外卡订阅,折腾时间成本大 |
| 国内多模型聚合镜像站 | 约 95% (与原版一致) | 网页端直连,网络通畅即可 | 聚合了各家模型,目前有免费额度,性价比极高 |
看得出来,想兼顾高准确率和低使用门槛,直接用聚合了主流大模型的网页端平台是目前比较优的解法。
实战演示:我是怎么用提示词(Prompt)干活的
怎么让模型乖乖干活?光丢一张截图过去是不够的,指令得给得明确。这里以我常用的 KULAAI 聚合平台为例,分享一套我平时自己用的“拆解连招”。
1. 截图要讲究,别太奔放
别随手用软件截图拉一下就完事。尽量保证截图的高清晰度,一定要把横纵坐标轴、图例说明全都框进去。在平台对话框里点击上传图片即可,因为它无需配置特殊网络环境,传个 2MB 左右的高清原图,一般两三秒就能加载完毕,不耽误事。
2. 数据扒皮,指令要像派活儿
要提取图表数据时,提示词得写得像在给实习生安排工作。 你可以这么发:“假装你是我的数据分析助理,请仔细看这张实验折线图。帮我把蓝色实线(控制组)和红色虚线(实验组)的关键数据点估算出来,严格按照 Markdown 表格格式整理给我。”
3. 复杂公式直接输出可编译代码
看到那种占了半页纸的长串积分公式,千万别手敲,容易漏符号还费眼睛。 直接把公式部分截图传上去,配上这句指令:“请识别图里的数学公式,并转化为可以直接在 Overleaf 中编译的 LaTeX 代码。请在代码前注明需要调用哪些宏包(比如 amsmath),注意矩阵的对齐。”
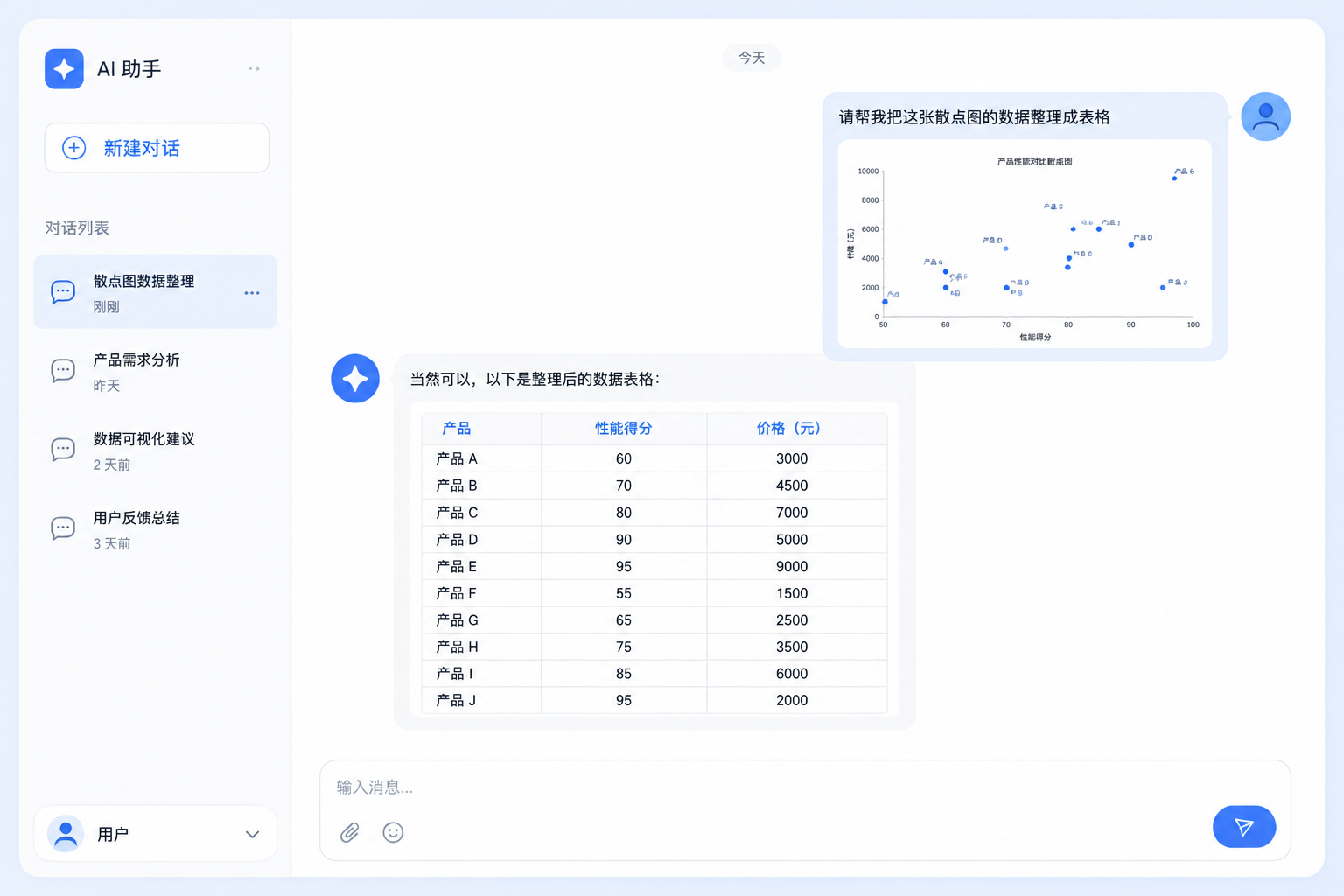
到底好不好用?拿近期实测数据说话
为了看看这套工作流到底靠不靠谱,我最近在写技术综述时,顺手测了大概 40 多篇计算机视觉和深度学习领域的经典论文。
在响应速度方面,处理那种包含多条折线和散点的混合图表,平均大概 1.5 秒到 2.5 秒钟就能给出反馈。在国内不搞特殊网络环境的情况下,这个出结果的流畅度让人相当满意。
在公式转化的准确度上,基础公式的转化成功率基本能飙到 90% 以上。生成的 LaTeX 代码直接粘贴到本地编辑器里,很少出现飘红报错的情况。
至于图表数据提取,常规的柱状图基本能做到零误差。即使是颜色渐变复杂的热力图,数值的估算偏差也控制在了极小的范围内,用来做早期的实验复现评估完全够用。
那些你大概率会遇到的坑(FAQ)
大家在刚开始用多模态大模型辅助读论文时,难免会遇到些小状况。我整理了 3 个网友经常问的高频问题,帮你提前避坑。
Q1:代码复制过去还是报错了,怎么办? A:十有八九是少包了。可以在提示词里加一句:“请在输出内容的最上方,单独用一行列出这段 LaTeX 代码必须包含的 \usepackage{} 声明。” 把包补全基本就能跑通。
Q2:论文截图实在太糊了,它死活认不出来咋办? A:年代久远的 PDF 确实是个麻烦。建议先把页面放大到 150% 再截图。如果是一个超大图表,试着把它切分成“左半部分”和“右半部分”两张图分别上传,能大幅降低 AI 的识别难度。
Q3:图表里好几根线缠在一起,它分不清谁是谁怎么办? A:对于重叠密集的图,别指望 AI 靠猜。截图前,可以用画图工具给你要提取的那条线做个简单的箭头标记。然后告诉它:“仅提取我用红色箭头指出的那条实线的数据。”
总结与一点心得
读文献、推公式本身就已经够耗费脑细胞了,真的没必要在机械的抄数据和敲代码上浪费时间。把这些毫无技术含量的“脏活累活”甩给 AI,咱们留着精力去思考创新点和实验设计,才是正经事。
如果你平时查阅前沿资料、写代码需求很大,又不想每天折腾复杂的网络环境,想一站式体验最新的模型能力,建议直接把 KULAAI 存在书签栏里备用。工具顺手了,效率自然就上去了。
注:图中配图均由chatgpt image2 辅助生成。
【本文完】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)