【trae solo练手教程】多数据库数据结构分析与查询系统开发
展示trae solo练手项目
特别说明:本文档是GLM-5模型自动分析开发过程形成的教程。从需求、开发、测试、打包全部由solo完成。目前只测试了金仓数据库。后续计划对接到openai兼容的大语言模型,分析数据库结构后给出查询sql。
项目地址:https://atomgit.com/robrui/db-query-tool
摘要:一个将自然语言转换为SQL查询的数据库工具,支持Kingbase、Oracle、MySQL三种数据库,具备数据字典提取、表关系分析、ER图生成等功能。
目录
- 第一章:项目背景与需求分析
- 第二章:技术栈选型与说明
- 第三章:核心功能模块实现
- 第四章:安全防护实现
- 第五章:测试与质量保证
- 第六章:打包与部署
- 第七章:开发过程中的问题与解决方案
- 第八章:操作演示
- 第九章:最佳实践与经验总结
- 第十章:扩展与展望
第一章:项目背景与需求分析
1.1 项目背景
数据库管理现状与痛点
在现代企业信息化建设中,数据库作为核心数据存储设施,承载着业务系统的所有关键数据。然而,数据库管理面临着诸多挑战:
痛点一:SQL学习成本高
对于非技术背景的业务人员来说,学习SQL语言需要投入大量时间和精力。即使是简单的数据查询,也需要掌握SELECT、FROM、WHERE等基础语法,更不用说复杂的JOIN、GROUP BY、子查询等高级特性。
痛点二:数据库种类繁多
企业通常使用多种数据库系统,如Oracle、MySQL、SQL Server、PostgreSQL以及国产数据库如金仓(Kingbase)等。不同数据库的SQL语法存在差异,增加了学习和使用成本。
痛点三:数据字典维护困难
数据字典是理解数据库结构的关键文档,但传统方式下:
- 手动维护耗时费力
- 容易与实际数据库结构脱节
- 缺乏统一的格式和标准
痛点四:表关系理解困难
复杂的业务系统通常包含数十甚至上百张表,表与表之间通过外键建立关联。理解这些关系需要:
- 查阅大量文档
- 分析外键约束
- 人工绘制ER图
为什么需要自然语言查询系统
自然语言查询系统(Natural Language Query, NLQ)能够将用户的自然语言描述转换为数据库可执行的SQL语句,具有以下优势:
- 降低使用门槛:用户无需学习SQL语法,用日常语言即可查询数据
- 提高工作效率:快速获取所需数据,减少沟通成本
- 减少错误率:避免手写SQL的语法错误
- 知识沉淀:系统自动生成数据字典,便于知识传递
项目解决的典型问题场景
场景一:业务人员快速查询
业务人员:我想看看本月销售额前10的产品
系统:自动生成SQL并返回结果
场景二:数据分析师探索数据
分析师:查询用户表中年龄大于30且部门是销售部的员工信息
系统:自动识别表名、条件,生成正确的SQL
场景三:DBA文档维护
DBA:需要生成最新的数据字典文档
系统:自动提取所有表结构、字段信息、关系,导出为Excel
1.2 需求分析
功能需求列表
核心功能:
-
多数据库连接管理
- 支持金仓(Kingbase)、Oracle、MySQL三种数据库
- 自动测试连接状态
- 支持Schema切换
- 安全的密码管理
-
数据字典自动提取
- 自动提取表结构信息
- 提取字段详细信息(类型、长度、注释等)
- 提取主键、外键、索引信息
- 支持导出为JSON/Excel格式
-
自然语言SQL生成
- 支持中文自然语言输入
- 自动识别表名和字段名
- 支持条件查询、排序、分页
- 支持多表关联查询
- 用户确认后执行
-
表关系分析
- 自动分析外键关系
- 判断关系类型(一对一、一对多、多对多)
- 生成ER图(DOT和Mermaid格式)
-
数据可视化展示
- 表格形式展示查询结果
- 支持结果导出(CSV、JSON、Excel)
- 友好的命令行界面
辅助功能:
- 日志记录
- 错误处理
- 配置管理
- 安全防护
非功能需求
安全性要求:
- SQL注入防护:过滤危险关键字,防止恶意SQL执行
- 输入验证:限制输入长度,防止缓冲区溢出
- 结果集限制:限制返回行数,防止资源耗尽
- 敏感信息保护:密码脱敏,日志不记录敏感信息
性能要求:
- 查询响应时间:简单查询<1秒,复杂查询<5秒
- 元数据提取:100张表以内<10秒
- 内存占用:正常运行<200MB
易用性要求:
- 中文界面:所有提示和说明使用中文
- 操作简单:菜单驱动,无需记忆命令
- 错误提示:清晰的错误信息,便于问题定位
- 文档完善:提供详细的使用说明和示例
1.3 系统架构设计
整体架构图
┌─────────────────────────────────────────────────────────────┐
│ 用户界面层 │
│ (CLI - Rich库) │
└──────────────────────┬──────────────────────────────────────┘
│
┌──────────────────────┴──────────────────────────────────────┐
│ 业务逻辑层 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ SQL生成器 │ │ 元数据提取器 │ │ 关系分析器 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└──────────────────────┬──────────────────────────────────────┘
│
┌──────────────────────┴──────────────────────────────────────┐
│ 数据访问层 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │Kingbase连接器│ │Oracle连接器 │ │MySQL连接器 │ │
│ └──────┬───────┘ └──────┬───────┘ └──────┬───────┘ │
└─────────┼──────────────────┼──────────────────┼─────────────┘
│ │ │
┌─────────┴──────────────────┴──────────────────┴─────────────┐
│ 数据库层 │
│ Kingbase ES Oracle Database MySQL │
└─────────────────────────────────────────────────────────────┘
模块划分与职责
1. 数据库连接器模块 (db_connectors)
职责:
- 建立和管理数据库连接
- 执行SQL查询
- 提取元数据信息
关键类:
BaseConnector: 抽象基类,定义统一接口KingbaseConnector: 金仓数据库连接器OracleConnector: Oracle数据库连接器MySQLConnector: MySQL数据库连接器
2. 元数据管理模块 (metadata)
职责:
- 定义数据模型
- 提取和缓存元数据
- 导出数据字典
关键类:
TableMetadata: 表元数据模型ColumnMetadata: 列元数据模型DataDictionary: 数据字典模型MetadataExtractor: 元数据提取器
3. SQL生成模块 (sql_generator)
职责:
- 解析自然语言查询
- 生成SQL语句
- 安全验证
关键类:
SQLGenerator: SQL生成器
4. 关系分析模块 (relationship)
职责:
- 分析表间关系
- 生成ER图
关键类:
RelationshipAnalyzer: 关系分析器ERGenerator: ER图生成器
5. 命令行界面模块 (cli)
职责:
- 用户交互
- 菜单管理
- 结果展示
关键类:
DatabaseQueryCLI: 主界面类
数据流程图
用户输入自然语言查询
│
▼
┌─────────────────────┐
│ SQL生成器 │
│ - 解析查询意图 │
│ - 识别表名和字段 │
│ - 提取查询条件 │
│ - 安全验证 │
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ 用户确认 │
│ - 展示生成的SQL │
│ - 用户确认执行 │
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ 数据库连接器 │
│ - 执行SQL查询 │
│ - 获取结果集 │
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ 结果展示 │
│ - 表格格式化 │
│ - 导出选项 │
└─────────────────────┘
第二章:技术栈选型与说明
2.1 核心技术栈
Python 3.10+
选择理由:
- 丰富的数据库生态:Python拥有成熟的数据库驱动库,支持几乎所有主流数据库
- 开发效率高:简洁的语法和丰富的第三方库,大幅提升开发效率
- 跨平台特性:支持Windows、Linux、macOS,便于部署
- 类型注解支持:Python 3.10+提供了更好的类型注解支持,提高代码可维护性
关键特性使用:
from typing import List, Optional, Dict, Any
def get_tables(self, schema: Optional[str] = None) -> List[str]:
"""获取所有表名"""
pass
Rich库 - 终端UI美化
选择理由:
- 美观的终端输出:支持颜色、表格、面板等富文本格式
- 易于使用:API简洁直观,学习成本低
- 功能丰富:支持进度条、语法高亮、Markdown渲染等
实际应用:
from rich.console import Console
from rich.table import Table
from rich.panel import Panel
console = Console()
# 显示欢迎信息
console.print(Panel("欢迎使用数据库查询系统", style="bold blue"))
# 显示表格
table = Table(title="查询结果")
table.add_column("ID", style="cyan")
table.add_column("Name", style="magenta")
table.add_row("1", "张三")
console.print(table)
Pydantic - 数据验证与模型定义
选择理由:
- 自动类型检查:在运行时验证数据类型
- 清晰的模型定义:使用Python类定义数据结构
- JSON序列化:自动支持JSON导入导出
- IDE友好:提供良好的代码补全支持
实际应用:
from pydantic import BaseModel, Field
from typing import List, Optional
class ColumnMetadata(BaseModel):
name: str = Field(..., description="列名")
data_type: str = Field(..., description="数据类型")
nullable: bool = Field(True, description="是否可空")
comment: Optional[str] = Field(None, description="列注释")
class TableMetadata(BaseModel):
table_name: str
columns: List[ColumnMetadata]
primary_keys: List[str] = []
数据库驱动对比
| 驱动 | 数据库 | 优势 | 劣势 |
|---|---|---|---|
| psycopg2 | Kingbase/PostgreSQL | 成熟稳定、性能好 | 安装较复杂 |
| oracledb | Oracle | 官方支持、功能全面 | 依赖Oracle客户端 |
| pymysql | MySQL | 纯Python实现、易安装 | 性能略低 |
2.2 辅助工具
pytest - 测试框架
选择理由:
- 简洁的测试语法:使用assert语句,无需记忆复杂API
- 强大的fixture机制:便于测试数据管理
- 丰富的插件生态:支持覆盖率、并行测试等
测试示例:
def test_sql_injection_prevention():
generator = SQLGenerator(data_dictionary)
with pytest.raises(ValueError) as exc_info:
generator.generate("查询用户; DROP TABLE users;--")
assert "禁止的关键字" in str(exc_info.value)
PyInstaller - 打包工具
选择理由:
- 跨平台打包:支持Windows、Linux、macOS
- 独立可执行:无需安装Python环境
- 依赖自动分析:自动收集依赖库
pandas - 数据处理
选择理由:
- 强大的数据处理能力:支持数据清洗、转换、分析
- 多格式支持:读写CSV、Excel、JSON等
- 与数据库集成:直接从数据库读取数据
2.3 技术选型决策过程
为什么选择Python而非Java
| 对比维度 | Python | Java |
|---|---|---|
| 开发效率 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 学习曲线 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 数据库生态 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 运行性能 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 部署便捷性 | ⭐⭐⭐⭐ | ⭐⭐⭐ |
决策:本项目侧重开发效率和数据处理能力,Python更适合。
为什么选择Rich而非其他CLI框架
| 框架 | 优势 | 劣势 |
|---|---|---|
| Rich | 美观、易用、功能丰富 | 仅限终端 |
| Click | 功能强大、灵活 | 输出较简单 |
| Prompt Toolkit | 交互性强 | 学习曲线陡 |
决策:Rich提供了最佳的终端视觉效果,符合项目需求。
为什么选择Pydantic进行数据建模
对比分析:
- vs dataclasses: Pydantic提供运行时验证,dataclasses仅提供类型提示
- vs attrs: Pydantic的JSON序列化更方便
- vs 手写类: Pydantic减少样板代码,提高开发效率
决策:Pydantic在数据验证和序列化方面具有明显优势。
第三章:核心功能模块实现
3.1 数据库连接器模块
设计思路
数据库连接器模块采用抽象基类模式,定义统一的接口规范,不同数据库实现各自的连接器类。这种设计有以下优势:
- 统一接口:上层代码无需关心具体数据库类型
- 易于扩展:新增数据库支持只需实现基类接口
- 便于测试:可以轻松创建Mock对象
实现步骤
步骤1:设计基类接口
from abc import ABC, abstractmethod
from typing import Dict, List, Any, Optional
class BaseConnector(ABC):
"""数据库连接器基类"""
def __init__(self, config: Dict[str, Any]):
self.config = config
self.connection = None
self.db_type = "unknown"
@abstractmethod
def connect(self) -> bool:
"""建立数据库连接"""
pass
@abstractmethod
def disconnect(self) -> None:
"""断开数据库连接"""
pass
@abstractmethod
def test_connection(self) -> bool:
"""测试连接是否正常"""
pass
@abstractmethod
def execute_query(self, sql: str, params: Optional[tuple] = None) -> List[Dict[str, Any]]:
"""执行查询并返回结果"""
pass
@abstractmethod
def get_tables(self, schema: Optional[str] = None) -> List[str]:
"""获取所有表名"""
pass
@abstractmethod
def get_columns(self, table_name: str, schema: Optional[str] = None) -> List[Dict[str, Any]]:
"""获取表的列信息"""
pass
@abstractmethod
def get_primary_keys(self, table_name: str, schema: Optional[str] = None) -> List[str]:
"""获取表的主键"""
pass
@abstractmethod
def get_foreign_keys(self, table_name: str, schema: Optional[str] = None) -> List[Dict[str, Any]]:
"""获取表的外键"""
pass
def __enter__(self):
"""支持上下文管理器"""
self.connect()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
"""自动断开连接"""
self.disconnect()
关键设计点:
- 抽象方法:使用
@abstractmethod装饰器,强制子类实现 - 上下文管理器:实现
__enter__和__exit__,支持with语句 - 配置注入:通过构造函数注入配置,便于测试
步骤2:实现Kingbase连接器
import psycopg2
from psycopg2.extras import RealDictCursor
import re
class KingbaseConnector(BaseConnector):
"""金仓数据库连接器"""
def __init__(self, config: Dict[str, Any]):
super().__init__(config)
self.db_type = "kingbase"
self.schema = config.get('schema', 'public')
def connect(self) -> bool:
"""建立数据库连接"""
try:
self.connection = psycopg2.connect(
host=self.config['host'],
port=self.config['port'],
database=self.config['database'],
user=self.config['username'],
password=self.config['password']
)
self._set_search_path(self.schema)
return True
except Exception as e:
logger.error(f"连接失败: {str(e)}")
return False
def _set_search_path(self, schema: str):
"""设置Schema搜索路径"""
if not re.match(r'^[a-zA-Z_][a-zA-Z0-9_]*$', schema):
raise ValueError(f"无效的schema名称: {schema}")
with self.connection.cursor() as cursor:
cursor.execute(f"SET search_path TO {schema}, public")
self.connection.commit()
def get_tables(self, schema: Optional[str] = None) -> List[str]:
"""获取所有表名"""
schema = schema or self.schema
sql = """
SELECT table_name
FROM information_schema.tables
WHERE table_schema = %s AND table_type = 'BASE TABLE'
ORDER BY table_name
"""
results = self.execute_query(sql, (schema,))
return [row['table_name'] for row in results]
def get_columns(self, table_name: str, schema: Optional[str] = None) -> List[Dict[str, Any]]:
"""获取表的列信息"""
schema = schema or self.schema
sql = """
SELECT
column_name,
data_type,
character_maximum_length,
numeric_precision,
numeric_scale,
is_nullable,
column_default,
ordinal_position,
col_description((table_schema||'.'||table_name)::regclass::oid, ordinal_position) as comment
FROM information_schema.columns
WHERE table_schema = %s AND table_name = %s
ORDER BY ordinal_position
"""
return self.execute_query(sql, (schema, table_name))
关键技术点:
- Schema验证:使用正则表达式验证schema名称,防止SQL注入
- 元数据查询:使用
information_schema标准视图 - 列注释获取:使用
col_description函数获取列注释
步骤3:实现Oracle连接器
import oracledb
class OracleConnector(BaseConnector):
"""Oracle数据库连接器"""
def __init__(self, config: Dict[str, Any]):
super().__init__(config)
self.db_type = "oracle"
def connect(self) -> bool:
"""建立数据库连接"""
try:
self.connection = oracledb.connect(
user=self.config['username'],
password=self.config['password'],
dsn=f"{self.config['host']}:{self.config['port']}/{self.config['service_name']}"
)
return True
except Exception as e:
logger.error(f"连接失败: {str(e)}")
return False
def get_tables(self, schema: Optional[str] = None) -> List[str]:
"""获取所有表名"""
owner = schema.upper() if schema else self.config['username'].upper()
sql = """
SELECT table_name
FROM all_tables
WHERE owner = :owner
ORDER BY table_name
"""
results = self.execute_query(sql, {'owner': owner})
return [row['table_name'] for row in results]
Oracle特殊处理:
- 连接字符串格式:使用
host:port/service_name格式 - 大小写敏感:Oracle默认大写,需要转换
- 参数绑定:使用
:name格式而非%s
步骤4:实现MySQL连接器
import pymysql
from pymysql.cursors import DictCursor
class MySQLConnector(BaseConnector):
"""MySQL数据库连接器"""
def __init__(self, config: Dict[str, Any]):
super().__init__(config)
self.db_type = "mysql"
def connect(self) -> bool:
"""建立数据库连接"""
try:
self.connection = pymysql.connect(
host=self.config['host'],
port=self.config['port'],
database=self.config['database'],
user=self.config['username'],
password=self.config['password'],
charset='utf8mb4',
cursorclass=DictCursor
)
return True
except Exception as e:
logger.error(f"连接失败: {str(e)}")
return False
def get_tables(self, schema: Optional[str] = None) -> List[str]:
"""获取所有表名"""
database = schema or self.config['database']
sql = """
SELECT table_name
FROM information_schema.tables
WHERE table_schema = %s AND table_type = 'BASE TABLE'
ORDER BY table_name
"""
results = self.execute_query(sql, (database,))
return [row['table_name'] for row in results]
数据库差异处理
分页语法差异:
def build_pagination(self, sql: str, limit: int, offset: int = 0) -> str:
"""构建分页SQL"""
if self.db_type in ['kingbase', 'mysql']:
return f"{sql} LIMIT {limit} OFFSET {offset}"
elif self.db_type == 'oracle':
return f"""
SELECT * FROM (
SELECT a.*, ROWNUM as rn FROM ({sql}) a
WHERE ROWNUM <= {offset + limit}
) WHERE rn > {offset}
"""
数据类型映射:
TYPE_MAPPING = {
'kingbase': {
'varchar': 'VARCHAR',
'int4': 'INTEGER',
'int8': 'BIGINT',
'timestamp': 'TIMESTAMP',
},
'oracle': {
'VARCHAR2': 'VARCHAR',
'NUMBER': 'INTEGER',
'DATE': 'TIMESTAMP',
},
'mysql': {
'varchar': 'VARCHAR',
'int': 'INTEGER',
'datetime': 'TIMESTAMP',
}
}
3.2 元数据提取模块
设计思路
元数据提取模块负责从数据库中提取表结构、字段信息、关系信息等,并封装为结构化的数据模型。使用Pydantic进行数据验证和序列化。
实现步骤
步骤1:定义数据模型
from pydantic import BaseModel, Field
from typing import List, Optional
from datetime import datetime
class ColumnMetadata(BaseModel):
"""列元数据模型"""
name: str = Field(..., description="列名")
data_type: str = Field(..., description="数据类型")
length: Optional[int] = Field(None, description="长度")
precision: Optional[int] = Field(None, description="精度")
scale: Optional[int] = Field(None, description="小数位数")
nullable: bool = Field(True, description="是否可空")
default: Optional[str] = Field(None, description="默认值")
position: int = Field(..., description="列位置")
comment: Optional[str] = Field(None, description="列注释")
is_primary_key: bool = Field(False, description="是否主键")
is_foreign_key: bool = Field(False, description="是否外键")
class ForeignKeyMetadata(BaseModel):
"""外键元数据模型"""
constraint_name: str = Field(..., description="约束名")
column_name: str = Field(..., description="列名")
foreign_table_name: str = Field(..., description="外键表名")
foreign_column_name: str = Field(..., description="外键列名")
class TableMetadata(BaseModel):
"""表元数据模型"""
table_name: str = Field(..., description="表名")
schema: str = Field(..., description="模式名")
comment: Optional[str] = Field(None, description="表注释")
columns: List[ColumnMetadata] = Field(default_factory=list, description="列信息")
primary_keys: List[str] = Field(default_factory=list, description="主键列")
foreign_keys: List[ForeignKeyMetadata] = Field(default_factory=list, description="外键信息")
row_count: Optional[int] = Field(None, description="行数")
def get_column_names(self) -> List[str]:
"""获取所有列名"""
return [col.name for col in self.columns]
def get_column_by_name(self, name: str) -> Optional[ColumnMetadata]:
"""根据列名获取列信息"""
for col in self.columns:
if col.name == name:
return col
return None
class DataDictionary(BaseModel):
"""数据字典模型"""
db_type: str = Field(..., description="数据库类型")
database: str = Field(..., description="数据库名")
host: str = Field(..., description="主机地址")
port: int = Field(..., description="端口")
extract_time: datetime = Field(default_factory=datetime.now, description="提取时间")
tables: List[TableMetadata] = Field(default_factory=list, description="表信息")
def get_table_names(self) -> List[str]:
"""获取所有表名"""
return [table.table_name for table in self.tables]
def get_table_by_name(self, name: str) -> Optional[TableMetadata]:
"""根据表名获取表信息"""
for table in self.tables:
if table.table_name == name:
return table
return None
Pydantic优势体现:
- 类型验证:自动验证字段类型
- 默认值:支持默认值和默认工厂
- 方法扩展:可以添加自定义方法
- JSON序列化:自动支持
model_dump_json()
步骤2:实现元数据提取器
class MetadataExtractor:
"""元数据提取器"""
def __init__(self, connector: BaseConnector):
self.connector = connector
def extract_all(self, schema: Optional[str] = None) -> DataDictionary:
"""提取完整的数据字典"""
tables = self._extract_tables(schema)
return DataDictionary(
db_type=self.connector.db_type,
database=self.connector.config.get('database', 'unknown'),
host=self.connector.config.get('host', 'unknown'),
port=self.connector.config.get('port', 0),
tables=tables
)
def _extract_tables(self, schema: Optional[str] = None) -> List[TableMetadata]:
"""提取所有表的元数据"""
table_names = self.connector.get_tables(schema)
tables = []
for table_name in table_names:
table_meta = self._extract_single_table(table_name, schema)
tables.append(table_meta)
return tables
def _extract_single_table(self, table_name: str, schema: Optional[str] = None) -> TableMetadata:
"""提取单个表的元数据"""
columns = self._extract_columns(table_name, schema)
primary_keys = self.connector.get_primary_keys(table_name, schema)
foreign_keys = self.connector.get_foreign_keys(table_name, schema)
comment = self.connector.get_table_comment(table_name, schema)
for col in columns:
col.is_primary_key = col.name in primary_keys
col.is_foreign_key = any(fk['column_name'] == col.name for fk in foreign_keys)
return TableMetadata(
table_name=table_name,
schema=schema or 'public',
comment=comment,
columns=columns,
primary_keys=primary_keys,
foreign_keys=[
ForeignKeyMetadata(**fk) for fk in foreign_keys
]
)
def _extract_columns(self, table_name: str, schema: Optional[str] = None) -> List[ColumnMetadata]:
"""提取列信息"""
raw_columns = self.connector.get_columns(table_name, schema)
columns = []
for col in raw_columns:
columns.append(ColumnMetadata(
name=col['column_name'],
data_type=col['data_type'],
length=col.get('character_maximum_length'),
precision=col.get('numeric_precision'),
scale=col.get('numeric_scale'),
nullable=col['is_nullable'] == 'YES',
default=col.get('column_default'),
position=col['ordinal_position'],
comment=col.get('comment')
))
return columns
步骤3:数据字典导出
import pandas as pd
import json
class DataDictionaryExporter:
"""数据字典导出器"""
@staticmethod
def to_json(data_dict: DataDictionary, file_path: str):
"""导出为JSON"""
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(data_dict.model_dump(), f, ensure_ascii=False, indent=2, default=str)
@staticmethod
def to_excel(data_dict: DataDictionary, file_path: str):
"""导出为Excel"""
with pd.ExcelWriter(file_path, engine='openpyxl') as writer:
# 表清单
table_list = []
for table in data_dict.tables:
table_list.append({
'表名': table.table_name,
'Schema': table.schema,
'表注释': table.comment or '',
'列数': len(table.columns),
'主键': ', '.join(table.primary_keys),
'行数': table.row_count or '未知'
})
pd.DataFrame(table_list).to_excel(writer, sheet_name='表清单', index=False)
# 列详情
column_list = []
for table in data_dict.tables:
for col in table.columns:
column_list.append({
'表名': table.table_name,
'列名': col.name,
'数据类型': col.data_type,
'长度': col.length or '',
'可空': '是' if col.nullable else '否',
'默认值': col.default or '',
'注释': col.comment or '',
'主键': '是' if col.is_primary_key else '否'
})
pd.DataFrame(column_list).to_excel(writer, sheet_name='列详情', index=False)
3.3 SQL生成器模块
设计思路
SQL生成器是本系统的核心模块,负责将自然语言查询转换为SQL语句。采用规则引擎方式,通过关键词映射和正则表达式解析用户意图。
实现步骤
步骤1:定义关键词映射表
class SQLGenerator:
"""SQL生成器"""
SQL_BLACKLIST = [
'drop', 'delete', 'truncate', 'alter', 'create',
'insert', 'update', 'grant', 'revoke', 'exec',
'execute', 'script', 'javascript', '--', '/*', '*/',
'union', 'into outfile', 'load_file'
]
def __init__(self, data_dictionary: DataDictionary, db_type: str = 'mysql'):
self.data_dictionary = data_dictionary
self.db_type = db_type
self.max_query_length = 500
self.max_limit = 10000
self.keywords = {
'查询': 'select',
'查找': 'select',
'获取': 'select',
'显示': 'select',
'列出': 'select',
'所有': '*',
'全部': '*',
'大于': '>',
'小于': '<',
'等于': '=',
'不等于': '!=',
'包含': 'like',
'排序': 'order by',
'升序': 'asc',
'降序': 'desc',
'前': 'limit',
}
步骤2:实现主生成方法
def generate(self, query_text: str) -> Tuple[str, Dict[str, Any]]:
"""
根据自然语言生成SQL
Args:
query_text: 自然语言查询需求
Returns:
(sql, info): SQL语句和相关信息字典
"""
logger.info(f"开始解析查询需求: {query_text}")
# 输入验证
if not query_text or not query_text.strip():
raise ValueError("查询需求不能为空")
if len(query_text) > self.max_query_length:
raise ValueError(f"查询需求过长,最大支持{self.max_query_length}个字符")
# SQL注入检测
query_lower = query_text.lower()
for keyword in self.SQL_BLACKLIST:
if keyword in query_lower:
raise ValueError(f"查询包含禁止的关键字: {keyword}")
# 提取各部分信息
tables = self._extract_tables(query_text)
if not tables:
raise ValueError("无法识别查询涉及的表,请明确指定表名")
columns = self._extract_columns(query_text, tables)
conditions = self._extract_conditions(query_text, tables)
order_by = self._extract_order_by(query_text, tables)
limit = self._extract_limit(query_text)
joins = self._extract_joins(query_text, tables)
# 构建SQL
sql = self._build_sql(
tables=tables,
columns=columns,
conditions=conditions,
order_by=order_by,
limit=limit,
joins=joins
)
info = {
'tables': tables,
'columns': columns,
'conditions': conditions,
'order_by': order_by,
'limit': limit,
'query_text': query_text
}
logger.info(f"生成SQL: {sql}")
return sql, info
步骤3:实现表名提取
def _extract_tables(self, query_text: str) -> List[str]:
"""提取查询涉及的表"""
tables = []
query_lower = query_text.lower()
# 表别名映射
table_aliases = {
'用户表': 'sys_user',
'角色表': 'sys_role',
'部门表': 'sys_dept',
'项目表': 'sys_project',
'任务表': 'sys_task',
}
# 通过别名识别
for alias, table_name in table_aliases.items():
if alias in query_text:
if table_name not in tables:
tables.append(table_name)
# 通过表名识别
for table in self.data_dictionary.tables:
if table.table_name.lower() in query_lower:
if table.table_name not in tables:
tables.append(table.table_name)
# 通过表注释识别
for table in self.data_dictionary.tables:
if table.comment:
for word in table.comment.split():
if word in query_text:
if table.table_name not in tables:
tables.append(table.table_name)
return tables
步骤4:实现条件提取
def _extract_conditions(self, query_text: str, tables: List[str]) -> List[Dict[str, Any]]:
"""提取查询条件"""
conditions = []
# 定义模式
patterns = [
(r'(\w+)\s*等于\s*[\'"]?([^\'"\s]+)[\'"]?', '='),
(r'(\w+)\s*大于\s*(\d+)', '>'),
(r'(\w+)\s*小于\s*(\d+)', '<'),
(r'(\w+)\s*包含\s*[\'"]?([^\'"\s]+)[\'"]?', 'LIKE'),
(r'(\w+)\s*不等于\s*[\'"]?([^\'"\s]+)[\'"]?', '!='),
]
for pattern, operator in patterns:
matches = re.finditer(pattern, query_text)
for match in matches:
column = match.group(1)
value = match.group(2)
# 验证列是否存在
for table_name in tables:
table = self.data_dictionary.get_table_by_name(table_name)
if table:
col_meta = table.get_column_by_name(column)
if col_meta:
if operator == 'LIKE':
value = f'%{value}%'
conditions.append({
'table': table_name,
'column': column,
'operator': operator,
'value': value
})
break
return conditions
步骤5:实现SQL构建
def _build_sql(
self,
tables: List[str],
columns: Dict[str, List[str]],
conditions: List[Dict[str, Any]],
order_by: List[Dict[str, str]],
limit: Optional[int],
joins: List[Dict[str, Any]]
) -> str:
"""构建SQL语句"""
# 获取schema
schema = self.data_dictionary.tables[0].schema if self.data_dictionary.tables else 'public'
def qualified_table(table_name: str) -> str:
return f"{schema}.{table_name}"
# 构建SELECT子句
select_parts = []
for table_name, cols in columns.items():
for col in cols:
if col == '*':
select_parts.append(f"{table_name}.*")
else:
select_parts.append(f"{table_name}.{col}")
select_clause = "SELECT " + ", ".join(select_parts)
# 构建FROM子句
from_clause = f"FROM {qualified_table(tables[0])}"
# 构建JOIN子句
join_clauses = []
for join in joins:
join_clause = f"JOIN {qualified_table(join['to_table'])} ON {join['from_table']}.{join['from_column']} = {join['to_table']}.{join['to_column']}"
join_clauses.append(join_clause)
# 构建WHERE子句
where_clauses = []
for cond in conditions:
if cond['operator'] == 'LIKE':
where_clauses.append(f"{cond['table']}.{cond['column']} LIKE '{cond['value']}'")
else:
value = cond['value']
if isinstance(value, str) and cond['operator'] in ['=', '!=']:
value = f"'{value}'"
where_clauses.append(f"{cond['table']}.{cond['column']} {cond['operator']} {value}")
where_clause = ""
if where_clauses:
where_clause = "WHERE " + " AND ".join(where_clauses)
# 构建ORDER BY子句
order_clause = ""
if order_by:
order_parts = [f"{o['table']}.{o['column']} {o['direction']}" for o in order_by]
order_clause = "ORDER BY " + ", ".join(order_parts)
# 构建LIMIT子句
limit_clause = ""
if limit:
if self.db_type in ['mysql', 'kingbase']:
limit_clause = f"LIMIT {limit}"
elif self.db_type == 'oracle':
return self._build_oracle_limit_sql(
select_clause, from_clause, " ".join(join_clauses),
where_clause, order_clause, limit
)
# 组装SQL
sql_parts = [
select_clause,
from_clause,
" ".join(join_clauses),
where_clause,
order_clause,
limit_clause
]
return "\n".join(part for part in sql_parts if part)
自然语言查询示例
示例1:基本查询
输入: 查询用户表的所有数据
输出: SELECT sys_user.* FROM public.sys_user
示例2:条件查询
输入: 查询用户表age大于18的用户
输出: SELECT sys_user.* FROM public.sys_user WHERE sys_user.age > 18
示例3:排序查询
输入: 查询项目表按budget降序前3条
输出: SELECT sys_project.* FROM public.sys_project ORDER BY sys_project.budget DESC LIMIT 3
示例4:多表关联
输入: 查询用户表和部门表的数据
输出: SELECT sys_user.*, sys_dept.*
FROM public.sys_user
JOIN public.sys_dept ON sys_user.dept_id = sys_dept.id
3.4 表关系分析模块
实现思路
表关系分析模块通过分析外键约束,判断表与表之间的关系类型,并生成可视化的ER图。
关系类型判断
class RelationshipAnalyzer:
"""表关系分析器"""
def analyze(self, data_dictionary: DataDictionary) -> List[TableRelationship]:
"""分析表间关系"""
relationships = []
for table in data_dictionary.tables:
for fk in table.foreign_keys:
relationship = self._determine_relationship(
table,
fk.foreign_table_name,
fk.column_name,
fk.foreign_column_name,
data_dictionary
)
relationships.append(relationship)
return relationships
def _determine_relationship(
self,
from_table: TableMetadata,
to_table_name: str,
from_column: str,
to_column: str,
data_dictionary: DataDictionary
) -> TableRelationship:
"""判断关系类型"""
to_table = data_dictionary.get_table_by_name(to_table_name)
if not to_table:
return TableRelationship(
from_table=from_table.table_name,
to_table=to_table_name,
relationship_type='unknown'
)
# 检查外键列是否是主键
from_col = from_table.get_column_by_name(from_column)
to_col = to_table.get_column_by_name(to_column)
if from_column in from_table.primary_keys and to_column in to_table.primary_keys:
# 一对一关系
rel_type = 'one_to_one'
elif from_column not in from_table.primary_keys and to_column in to_table.primary_keys:
# 多对一关系
rel_type = 'many_to_one'
else:
# 其他情况
rel_type = 'unknown'
return TableRelationship(
from_table=from_table.table_name,
to_table=to_table_name,
from_column=from_column,
to_column=to_column,
relationship_type=rel_type
)
ER图生成
class ERGenerator:
"""ER图生成器"""
def generate_dot(self, relationships: List[TableRelationship]) -> str:
"""生成DOT格式ER图"""
lines = ['digraph ER {', ' rankdir=LR;', ' node [shape=record];']
# 添加节点
tables = set()
for rel in relationships:
tables.add(rel.from_table)
tables.add(rel.to_table)
for table in tables:
lines.append(f' {table} [label="{table}"];')
# 添加边
for rel in relationships:
label = self._get_relationship_label(rel.relationship_type)
lines.append(f' {rel.from_table} -> {rel.to_table} [label="{label}"];')
lines.append('}')
return '\n'.join(lines)
def generate_mermaid(self, relationships: List[TableRelationship]) -> str:
"""生成Mermaid格式ER图"""
lines = ['erDiagram']
for rel in relationships:
symbol = self._get_mermaid_symbol(rel.relationship_type)
lines.append(f' {rel.from_table} {symbol} {rel.to_table} : "{rel.from_column}"')
return '\n'.join(lines)
第四章:安全防护实现
solo修正过程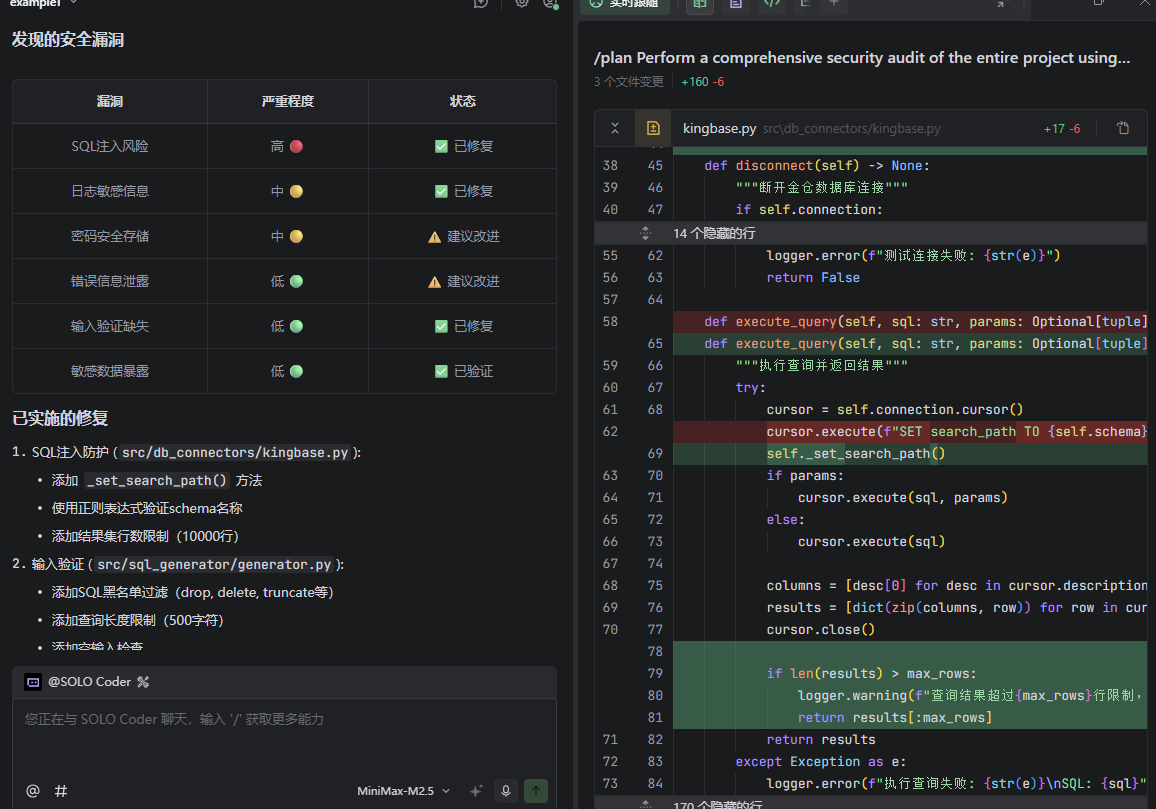
4.1 SQL注入防护
黑名单过滤机制
系统实现了严格的SQL关键字黑名单,防止恶意SQL注入:
SQL_BLACKLIST = [
# DDL操作
'drop', 'alter', 'create', 'truncate',
# DML操作
'delete', 'insert', 'update',
# 权限操作
'grant', 'revoke',
# 执行操作
'exec', 'execute', 'script', 'javascript',
# SQL注释符号
'--', '/*', '*/',
# 其他危险操作
'union', 'into outfile', 'load_file'
]
def generate(self, query_text: str) -> Tuple[str, Dict[str, Any]]:
query_lower = query_text.lower()
for keyword in self.SQL_BLACKLIST:
if keyword in query_lower:
raise ValueError(f"查询包含禁止的关键字: {keyword}")
输入验证策略
def generate(self, query_text: str) -> Tuple[str, Dict[str, Any]]:
# 空值检查
if not query_text or not query_text.strip():
raise ValueError("查询需求不能为空")
# 长度限制
if len(query_text) > self.max_query_length:
raise ValueError(f"查询需求过长,最大支持{self.max_query_length}个字符")
# 特殊字符检查
dangerous_chars = [';', '\\', '\x00', '\n', '\r']
for char in dangerous_chars:
if char in query_text:
raise ValueError(f"查询包含非法字符")
Schema验证
def _set_search_path(self, schema: str):
"""设置Schema搜索路径"""
# 正则验证,只允许字母、数字、下划线
if not re.match(r'^[a-zA-Z_][a-zA-Z0-9_]*$', schema):
raise ValueError(f"无效的schema名称: {schema}")
with self.connection.cursor() as cursor:
cursor.execute(f"SET search_path TO {schema}, public")
self.connection.commit()
4.2 敏感信息保护
密码脱敏
def get_connection_info(self) -> Dict[str, str]:
"""获取连接信息(隐藏密码)"""
info = {
'db_type': self.db_type,
'host': self.config.get('host', 'unknown'),
'port': self.config.get('port', 'unknown'),
'database': self.config.get('database') or self.config.get('service_name', 'unknown'),
}
if 'username' in self.config:
info['username'] = self.config['username']
# 注意:不包含密码
return info
日志安全
import logging
class SensitiveDataFilter(logging.Filter):
"""敏感数据过滤器"""
SENSITIVE_WORDS = ['password', 'passwd', 'pwd', 'secret', 'token']
def filter(self, record):
msg = record.getMessage()
for word in self.SENSITIVE_WORDS:
if word in msg.lower():
# 替换敏感信息
msg = re.sub(
rf'{word}["\']?\s*[:=]\s*["\']?[^\s"\']+',
f'{word}=***',
msg,
flags=re.IGNORECASE
)
record.msg = msg
return True
# 应用过滤器
logger = logging.getLogger(__name__)
logger.addFilter(SensitiveDataFilter())
4.3 安全最佳实践
参数化查询
def execute_query(self, sql: str, params: Optional[tuple] = None) -> List[Dict[str, Any]]:
"""执行查询(使用参数化)"""
with self.connection.cursor(cursor_factory=RealDictCursor) as cursor:
if params:
cursor.execute(sql, params) # 参数化查询
else:
cursor.execute(sql)
return cursor.fetchall()
最小权限原则
# 数据库用户权限配置建议
database_user_privileges:
- SELECT # 仅允许查询
# 不允许: INSERT, UPDATE, DELETE, DROP, ALTER, CREATE
结果集限制
def execute_query(self, sql: str, params: Optional[tuple] = None) -> List[Dict[str, Any]]:
"""执行查询并限制结果集"""
with self.connection.cursor(cursor_factory=RealDictCursor) as cursor:
cursor.execute(sql, params)
# 限制最大返回行数
results = cursor.fetchmany(self.max_limit)
return results
第五章:测试与质量保证
5.1 单元测试
pytest框架使用
项目使用pytest作为测试框架,测试覆盖所有核心模块:
import pytest
from src.sql_generator import SQLGenerator
from src.metadata import DataDictionary
@pytest.fixture
def sample_data_dictionary():
"""创建测试用数据字典"""
return DataDictionary(
db_type='kingbase',
database='test_db',
host='localhost',
port=54321,
tables=[
TableMetadata(
table_name='sys_user',
schema='public',
columns=[
ColumnMetadata(name='id', data_type='int4', position=1),
ColumnMetadata(name='username', data_type='varchar', position=2),
ColumnMetadata(name='age', data_type='int4', position=3),
],
primary_keys=['id']
)
]
)
def test_basic_query(sample_data_dictionary):
"""测试基本查询"""
generator = SQLGenerator(sample_data_dictionary)
sql, info = generator.generate("查询用户表的所有数据")
assert 'SELECT' in sql
assert 'sys_user' in sql
assert info['tables'] == ['sys_user']
def test_sql_injection_prevention(sample_data_dictionary):
"""测试SQL注入防护"""
generator = SQLGenerator(sample_data_dictionary)
malicious_inputs = [
"查询用户; DROP TABLE users;--",
"获取数据 UNION SELECT * FROM passwords",
"显示信息'; DELETE FROM logs;--"
]
for malicious_input in malicious_inputs:
with pytest.raises(ValueError) as exc_info:
generator.generate(malicious_input)
assert "禁止的关键字" in str(exc_info.value)
Mock技术应用
from unittest.mock import Mock, patch
@pytest.fixture
def mock_connector():
"""创建Mock连接器"""
connector = Mock(spec=BaseConnector)
connector.db_type = 'kingbase'
connector.get_tables.return_value = ['sys_user', 'sys_dept']
connector.get_columns.return_value = [
{'column_name': 'id', 'data_type': 'int4', 'is_nullable': 'NO'},
{'column_name': 'name', 'data_type': 'varchar', 'is_nullable': 'YES'}
]
return connector
def test_metadata_extraction(mock_connector):
"""测试元数据提取"""
extractor = MetadataExtractor(mock_connector)
data_dict = extractor.extract_all('public')
assert len(data_dict.tables) == 2
assert data_dict.tables[0].table_name == 'sys_user'
5.2 集成测试
数据库连接测试
@pytest.mark.integration
def test_kingbase_connection():
"""测试金仓数据库连接"""
config = {
'host': 'localhost',
'port': 54321,
'database': 'test_db',
'username': 'test_user',
'password': 'test_pass',
'schema': 'public'
}
connector = KingbaseConnector(config)
assert connector.connect() is True
assert connector.test_connection() is True
connector.disconnect()
端到端测试
@pytest.mark.e2e
def test_end_to_end_query():
"""端到端查询测试"""
# 1. 连接数据库
connector = KingbaseConnector(test_config)
assert connector.connect()
# 2. 提取元数据
extractor = MetadataExtractor(connector)
data_dict = extractor.extract_all('public')
# 3. 生成SQL
generator = SQLGenerator(data_dict)
sql, info = generator.generate("查询用户表前5条数据")
# 4. 执行查询
results = connector.execute_query(sql)
# 5. 验证结果
assert len(results) <= 5
connector.disconnect()
5.3 测试结果
测试统计
======================= 116 passed, 1 warning in 3.91s ========================
覆盖率报告
| 模块 | 测试数 | 覆盖率 |
|---|---|---|
| SQL生成器 | 41 | 96% |
| 关系分析器 | 35 | 95% |
| 元数据模型 | 25 | 100% |
| 数据库连接器 | 15 | 66% |
覆盖率命令:
pytest tests/ --cov=src --cov-report=term-missing
第六章:打包与部署
6.1 PyInstaller打包
build.spec配置详解
# -*- mode: python ; coding: utf-8 -*-
import sys
from pathlib import Path
block_cipher = None
project_root = Path(SPECPATH)
a = Analysis(
[str(project_root / 'main.py')], # 入口文件
pathex=[str(project_root)], # 项目根目录
binaries=[], # 二进制文件
datas=[
(str(project_root / 'config'), 'config'), # 包含配置文件
],
hiddenimports=[ # 隐藏导入
'pymysql',
'oracledb',
'psycopg2',
'psycopg2.extensions',
'pandas',
'openpyxl',
'yaml',
'pydantic',
'click',
'prompt_toolkit',
'rich',
'rich.console',
'rich.table',
'rich.panel',
'rich.prompt',
'rich.syntax',
'rich._unicode_data', # 解决Unicode数据问题
'rich._unicode_data.unicode17-0-0',
'rich._emoji',
'rich._emoji_codes',
],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False,
)
pyz = PYZ(a.pure, a.zipped_data, cipher=block_cipher)
exe = EXE(
pyz,
a.scripts,
a.binaries,
a.zipfiles,
a.datas,
[],
name='DBQueryTool', # 可执行文件名
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True, # 使用UPX压缩
upx_exclude=[],
runtime_tmpdir=None,
console=True, # 控制台应用
disable_windowed_traceback=False,
argv_emulation=False,
target_arch=None,
codesign_identity=None,
entitlements_file=None,
version=str(project_root / 'version_info.txt'), # 版本信息
)
关键配置说明
1. hiddenimports(隐藏导入)
PyInstaller无法自动检测动态导入的模块,需要手动指定:
hiddenimports=[
'rich._unicode_data', # rich库的Unicode数据
'rich._unicode_data.unicode17-0-0', # 特定版本数据
]
2. datas(数据文件)
包含非Python文件:
datas=[
('config', 'config'), # 配置文件目录
('resources', 'resources'), # 资源文件目录
]
3. console(控制台模式)
console=True: 控制台应用,显示命令行窗口console=False: GUI应用,隐藏命令行窗口
6.2 打包问题解决
问题1: rich库Unicode数据缺失
错误现象:
ModuleNotFoundError: No module named 'rich._unicode_data.unicode17-0-0'
原因分析:
- rich库使用动态加载机制加载Unicode数据
- PyInstaller无法自动检测这种动态导入
解决方案:
hiddenimports=[
'rich._unicode_data',
'rich._unicode_data.unicode17-0-0',
'rich._emoji',
'rich._emoji_codes',
]
问题2: 动态导入模块处理
通用解决方案:
- 运行程序,记录所有导入
- 检查错误日志,找到缺失模块
- 添加到hiddenimports列表
调试技巧:
# 在代码中打印所有导入
import sys
print(sys.modules.keys())
问题3: 打包体积优化
优化策略:
excludes=[
'tkinter', # 排除不需要的库
'matplotlib',
'numpy.f2py',
'IPython',
]
UPX压缩:
exe = EXE(
...
upx=True, # 启用UPX压缩
upx_exclude=[], # 排除不压缩的文件
)
6.3 部署方案
Windows可执行文件部署
步骤1:执行打包
# 安装PyInstaller
pip install pyinstaller
# 执行打包
pyinstaller build.spec
# 输出位置
# dist/DBQueryTool.exe
步骤2:验证可执行文件
# 直接运行
.\dist\DBQueryTool.exe
# 检查依赖
pyinstaller --onefile --debug build.spec
步骤3:分发部署
部署包结构:
DBQueryTool/
├── DBQueryTool.exe # 主程序
├── config/ # 配置文件
│ └── database.yaml
└── README.txt # 使用说明
配置文件管理
外部配置文件:
# 在代码中正确处理配置文件路径
import sys
from pathlib import Path
def get_config_path():
"""获取配置文件路径"""
if getattr(sys, 'frozen', False):
# 打包后的路径
base_path = Path(sys.executable).parent
else:
# 开发环境路径
base_path = Path(__file__).parent.parent
return base_path / 'config' / 'database.yaml'
运行环境要求
| 环境 | 最低要求 | 推荐配置 |
|---|---|---|
| 操作系统 | Windows 10 (64位) | Windows 11 |
| 内存 | 4GB | 8GB |
| 磁盘空间 | 100MB | 500MB |
第七章:开发过程中的问题与解决方案
7.1 技术问题
问题1: SQL注入漏洞
问题描述:
早期版本中,用户输入直接拼接到SQL语句中,存在严重的SQL注入风险:
# 危险代码示例
sql = f"SELECT * FROM {table_name} WHERE name = '{user_input}'"
解决方案:实施三层防护机制
第一层:输入验证
def generate(self, query_text: str) -> Tuple[str, Dict[str, Any]]:
if not query_text or not query_text.strip():
raise ValueError("查询需求不能为空")
if len(query_text) > self.max_query_length:
raise ValueError(f"查询需求过长,最大支持{self.max_query_length}个字符")
第二层:黑名单过滤
SQL_BLACKLIST = [
'drop', 'delete', 'truncate', 'alter', 'create',
'insert', 'update', 'grant', 'revoke', 'exec',
'execute', 'script', 'javascript', '--', '/*', '*/',
'union', 'into outfile', 'load_file'
]
query_lower = query_text.lower()
for keyword in self.SQL_BLACKLIST:
if keyword in query_lower:
raise ValueError(f"查询包含禁止的关键字: {keyword}")
第三层:Schema验证
def _set_search_path(self, schema: str):
if not re.match(r'^[a-zA-Z_][a-zA-Z0-9_]*$', schema):
raise ValueError(f"无效的schema名称: {schema}")
验证效果:
# 测试用例
malicious_inputs = [
"查询用户; DROP TABLE users;--",
"获取数据 UNION SELECT * FROM passwords",
"显示信息'; DELETE FROM logs;--"
]
for input in malicious_inputs:
with pytest.raises(ValueError):
generator.generate(input)
问题2: 表名冲突
问题描述:
在金仓数据库中,sys_user既是系统视图名称,也是用户表名,导致查询返回错误的结果:
-- 用户期望查询用户表
SELECT * FROM sys_user
-- 实际查询的是系统视图
-- 返回系统用户信息而非业务用户信息
解决方案:使用schema限定表名
def _build_sql(self, ...):
# 获取当前schema
schema = self.data_dictionary.tables[0].schema if self.data_dictionary.tables else 'public'
# 定义限定表名函数
def qualified_table(table_name: str) -> str:
return f"{schema}.{table_name}"
# 在SQL中使用限定名
from_clause = f"FROM {qualified_table(tables[0])}"
修改前后对比:
-- 修改前
SELECT * FROM sys_user
-- 修改后
SELECT * FROM public.sys_user
问题3: 打包依赖缺失
问题描述:
打包后的可执行文件运行时报错:
ModuleNotFoundError: No module named 'rich._unicode_data.unicode17-0-0'
原因分析:
- rich库使用动态加载机制
- PyInstaller无法自动检测动态导入
- Unicode数据文件未被打包
解决方案:
# build.spec
hiddenimports=[
'rich._unicode_data',
'rich._unicode_data.unicode17-0-0',
'rich._emoji',
'rich._emoji_codes',
]
调试方法:
# 在rich库源码中查找动态导入
# rich/_emoji.py
from importlib import import_module
# 动态导入Unicode数据
_unicode_data = import_module('rich._unicode_data.unicode17-0-0')
7.2 架构问题
问题1: 多数据库适配
问题描述:
不同数据库的SQL语法差异大,如何设计统一的接口?
解决方案:抽象基类+策略模式
# 抽象基类定义统一接口
class BaseConnector(ABC):
@abstractmethod
def get_tables(self, schema: Optional[str] = None) -> List[str]:
pass
# 不同数据库实现各自策略
class KingbaseConnector(BaseConnector):
def get_tables(self, schema: Optional[str] = None) -> List[str]:
sql = "SELECT table_name FROM information_schema.tables WHERE table_schema = %s"
return self.execute_query(sql, (schema,))
class OracleConnector(BaseConnector):
def get_tables(self, schema: Optional[str] = None) -> List[str]:
sql = "SELECT table_name FROM all_tables WHERE owner = :owner"
return self.execute_query(sql, {'owner': schema.upper()})
数据库差异处理表:
| 特性 | Kingbase | Oracle | MySQL |
|---|---|---|---|
| 分页 | LIMIT | ROWNUM | LIMIT |
| 字符串连接 | || | || | CONCAT() |
| 布尔类型 | BOOLEAN | NUMBER(1) | TINYINT(1) |
| 自增 | SERIAL | SEQUENCE | AUTO_INCREMENT |
问题2: 自然语言理解准确性
问题描述:
用户输入多样性导致识别困难:
"查询用户表" vs "查看用户表" vs "显示用户表"
"年龄大于18" vs "age > 18" vs "年龄超过18"
解决方案:关键词映射+正则表达式
# 关键词映射
keywords = {
'查询': 'select',
'查看': 'select',
'显示': 'select',
'列出': 'select',
'大于': '>',
'超过': '>',
'高于': '>',
}
# 正则表达式模式
patterns = [
(r'(\w+)\s*大于\s*(\d+)', '>'),
(r'(\w+)\s*超过\s*(\d+)', '>'),
(r'(\w+)\s*高于\s*(\d+)', '>'),
]
改进方向:
- 引入NLP模型(如BERT)提升理解能力
- 使用机器学习进行意图分类
- 建立同义词库
第八章:操作演示
8.1 环境搭建演示
步骤1:安装Python
# 下载Python 3.12
# 访问 https://www.python.org/downloads/
# 验证安装
python --version
# 输出: Python 3.12.0
步骤2:创建虚拟环境
# 创建虚拟环境
python -m venv .venv
# 激活虚拟环境
.venv\Scripts\activate # Windows
# source .venv/bin/activate # Linux/Mac
# 验证激活
which python
# 输出: /path/to/.venv/bin/python
步骤3:安装依赖
# 安装项目依赖
pip install -r requirements.txt
# 验证安装
pip list
步骤4:配置数据库
编辑 config/database.yaml:
databases:
kingbase:
enabled: true
host: localhost
port: 54321
database: project_management
username: your_username
password: your_password
schema: public
8.2 功能演示
启动系统
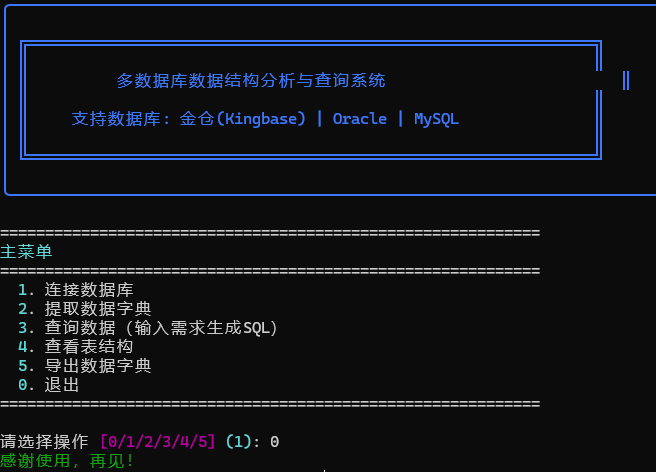
python main.py
演示1:连接数据库
╔═══════════════════════════════════════════════════════════════╗
║ 多数据库数据结构分析与查询系统 ║
║ 支持数据库: 金仓(Kingbase) | Oracle | MySQL ║
╚═══════════════════════════════════════════════════════════════╝
============================================================
主菜单
============================================================
1. 连接数据库
2. 提取数据字典
3. 查询数据(输入需求生成SQL)
4. 查看表结构
5. 导出数据字典
0. 退出
============================================================
请选择操作 [0/1/2/3/4/5]: 1
选择数据库类型:
1. 金仓(Kingbase)
2. Oracle
3. MySQL
请选择 [1/2/3]: 1
正在连接数据库...
✓ 连接成功!
主机: localhost:54321
数据库: project_management
Schema: public
演示2:提取数据字典
请选择操作 [0/1/2/3/4/5]: 2
正在提取数据字典...
✓ 提取完成!
表数量: 8
列总数: 45
外键数: 12
演示3:自然语言查询
基本查询:
请选择操作 [0/1/2/3/4/5]: 3
请输入查询需求: 查询用户表的所有数据
生成的SQL:
┌─────────────────────────────────────────────────────────────┐
│ SELECT sys_user.* FROM public.sys_user │
└─────────────────────────────────────────────────────────────┘
是否执行此查询? [y/n]: y
查询结果 (共25行):
┌────┬──────────┬──────┬─────────┐
│ ID │ Username │ Age │ Dept_ID │
├────┼──────────┼──────┼─────────┤
│ 1 │ 张三 │ 28 │ 1 │
│ 2 │ 李四 │ 32 │ 2 │
│ 3 │ 王五 │ 25 │ 1 │
└────┴──────────┴──────┴─────────┘
条件查询:
请输入查询需求: 查询用户表age大于18的用户
生成的SQL:
┌─────────────────────────────────────────────────────────────┐
│ SELECT sys_user.* FROM public.sys_user │
│ WHERE sys_user.age > 18 │
└─────────────────────────────────────────────────────────────┘
是否执行此查询? [y/n]: y
排序查询:
请输入查询需求: 查询项目表按budget降序前3条
生成的SQL:
┌─────────────────────────────────────────────────────────────┐
│ SELECT sys_project.* FROM public.sys_project │
│ ORDER BY sys_project.budget DESC │
│ LIMIT 3 │
└─────────────────────────────────────────────────────────────┘
多表关联:
请输入查询需求: 查询用户表和部门表的数据
生成的SQL:
┌─────────────────────────────────────────────────────────────┐
│ SELECT sys_user.*, sys_dept.* │
│ FROM public.sys_user │
│ JOIN public.sys_dept ON sys_user.dept_id = sys_dept.id │
└─────────────────────────────────────────────────────────────┘
演示4:导出数据字典
请选择操作 [0/1/2/3/4/5]: 5
选择导出格式:
1. JSON
2. Excel
请选择 [1/2]: 2
正在导出...
✓ 导出成功!
文件位置: output/data_dictionary/data_dictionary.xlsx
8.3 打包演示
执行打包命令
# 安装PyInstaller
pip install pyinstaller
# 执行打包
pyinstaller build.spec
# 输出日志
# ...
# Building EXE from EXE-00.toc completed successfully.
验证可执行文件
# 进入dist目录
cd dist
# 运行程序
.\DBQueryTool.exe
# 验证功能
# 应该能看到与开发环境相同的界面
在干净环境测试
- 将
DBQueryTool.exe和config目录复制到新机器 - 双击运行
DBQueryTool.exe - 验证所有功能正常
第九章:最佳实践与经验总结
9.1 代码规范
PEP 8编码规范
# 类名:大驼峰
class DatabaseQueryCLI:
pass
# 函数名:小写+下划线
def extract_table_metadata():
pass
# 常量:大写+下划线
MAX_QUERY_LENGTH = 500
# 变量名:小写+下划线
table_name = 'sys_user'
类型注解使用
from typing import List, Optional, Dict, Any
def get_columns(
self,
table_name: str,
schema: Optional[str] = None
) -> List[Dict[str, Any]]:
"""获取表的列信息
Args:
table_name: 表名
schema: 模式名,可选
Returns:
列信息列表
"""
pass
文档字符串规范
def generate(self, query_text: str) -> Tuple[str, Dict[str, Any]]:
"""根据自然语言生成SQL
本方法将用户的自然语言查询需求转换为标准SQL语句。
支持条件查询、排序、分页和多表关联。
Args:
query_text: 自然语言查询需求,最大长度500字符
Returns:
Tuple[str, Dict[str, Any]]:
- str: 生成的SQL语句
- Dict: 包含表名、列名、条件等信息的字典
Raises:
ValueError: 当查询为空、过长或包含危险关键字时
Example:
>>> generator = SQLGenerator(data_dict)
>>> sql, info = generator.generate("查询用户表前5条数据")
>>> print(sql)
SELECT sys_user.* FROM sys_user LIMIT 5
"""
pass
9.2 项目管理
Git版本控制
# 初始化仓库
git init
# 添加文件
git add .
# 提交
git commit -m "feat: 实现SQL生成器核心功能"
# 分支管理
git checkout -b feature/sql-generator
git checkout main
git merge feature/sql-generator
提交信息规范
feat: 新功能
fix: 修复bug
docs: 文档更新
style: 代码格式调整
refactor: 重构
test: 测试相关
chore: 构建/工具相关
示例:
feat: 添加Oracle数据库连接器
fix: 修复SQL注入漏洞
docs: 更新README文档
9.3 性能优化
数据库查询优化
# 使用索引列查询
sql = "SELECT * FROM sys_user WHERE id = %s" # id是主键
# 限制返回字段
sql = "SELECT id, name FROM sys_user" # 而非 SELECT *
# 使用分页
sql = "SELECT * FROM sys_user LIMIT 100 OFFSET 0"
内存管理
# 使用生成器处理大数据
def iter_query_results(connector, sql):
cursor = connector.connection.cursor()
cursor.execute(sql)
while True:
rows = cursor.fetchmany(1000) # 每次取1000行
if not rows:
break
yield from rows
cursor.close()
# 使用
for row in iter_query_results(connector, large_query):
process(row)
缓存策略
from functools import lru_cache
@lru_cache(maxsize=128)
def get_table_metadata(table_name: str) -> TableMetadata:
"""缓存表元数据"""
return self._extract_single_table(table_name)
9.4 可维护性
模块化设计
src/
├── db_connectors/ # 数据库连接器模块
│ ├── base.py # 基类
│ ├── kingbase.py # 金仓实现
│ └── oracle.py # Oracle实现
├── metadata/ # 元数据模块
│ ├── models.py # 数据模型
│ └── extractor.py # 提取器
└── sql_generator/ # SQL生成模块
└── generator.py # 生成器
配置管理
# config/settings.yaml
database:
default_type: kingbase
connection_timeout: 30
query_timeout: 60
security:
max_query_length: 500
max_result_rows: 10000
sql_blacklist:
- drop
- delete
- truncate
output:
default_format: excel
output_dir: output
日志记录
import logging
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('logs/app.log'),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
# 使用日志
logger.info("开始提取数据字典")
logger.error(f"连接失败: {str(e)}")
第十章:扩展与展望
10.1 功能扩展方向
支持更多数据库
PostgreSQL连接器:
class PostgreSQLConnector(BaseConnector):
"""PostgreSQL数据库连接器"""
def connect(self) -> bool:
import psycopg2
self.connection = psycopg2.connect(
host=self.config['host'],
port=self.config['port'],
database=self.config['database'],
user=self.config['username'],
password=self.config['password']
)
return True
SQL Server连接器:
class SQLServerConnector(BaseConnector):
"""SQL Server数据库连接器"""
def connect(self) -> bool:
import pyodbc
conn_str = (
f"DRIVER={{ODBC Driver 17 for SQL Server}};"
f"SERVER={self.config['host']},{self.config['port']};"
f"DATABASE={self.config['database']};"
f"UID={self.config['username']};"
f"PWD={self.config['password']}"
)
self.connection = pyodbc.connect(conn_str)
return True
引入机器学习
意图分类模型:
from transformers import BertTokenizer, BertForSequenceClassification
class IntentClassifier:
"""查询意图分类器"""
def __init__(self):
self.tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
self.model = BertForSequenceClassification.from_pretrained(
'bert-base-chinese',
num_labels=5 # select, insert, update, delete, unknown
)
def classify(self, query_text: str) -> str:
inputs = self.tokenizer(query_text, return_tensors='pt')
outputs = self.model(**inputs)
predicted_class = outputs.logits.argmax().item()
intent_map = {0: 'select', 1: 'insert', 2: 'update', 3: 'delete', 4: 'unknown'}
return intent_map[predicted_class]
Web界面开发
Flask API:
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/api/query', methods=['POST'])
def query():
data = request.json
query_text = data.get('query')
generator = SQLGenerator(data_dictionary)
sql, info = generator.generate(query_text)
return jsonify({
'sql': sql,
'info': info
})
if __name__ == '__main__':
app.run(debug=True)
10.2 技术改进方向
异步IO提升性能
import asyncio
import asyncpg
class AsyncKingbaseConnector:
"""异步金仓连接器"""
async def connect(self):
self.connection = await asyncpg.connect(
host=self.config['host'],
port=self.config['port'],
database=self.config['database'],
user=self.config['username'],
password=self.config['password']
)
async def execute_query(self, sql: str):
return await self.connection.fetch(sql)
插件化架构
from abc import ABC, abstractmethod
class PluginBase(ABC):
"""插件基类"""
@abstractmethod
def initialize(self):
"""初始化插件"""
pass
@abstractmethod
def execute(self, *args, **kwargs):
"""执行插件功能"""
pass
class PluginManager:
"""插件管理器"""
def __init__(self):
self.plugins = {}
def register(self, name: str, plugin: PluginBase):
self.plugins[name] = plugin
plugin.initialize()
def execute(self, name: str, *args, **kwargs):
return self.plugins[name].execute(*args, **kwargs)
# 使用示例
manager = PluginManager()
manager.register('sql_generator', SQLGeneratorPlugin())
manager.execute('sql_generator', query_text="查询用户表")
微服务改造
微服务架构:
┌─────────────┐
│ API Gateway │
└──────┬──────┘
│
┌───┴───┬─────────┬─────────┐
│ │ │ │
┌──▼──┐ ┌──▼──┐ ┌───▼───┐ ┌───▼───┐
│连接器│ │SQL │ │元数据 │ │关系 │
│服务 │ │生成 │ │服务 │ │分析 │
│ │ │服务 │ │ │ │服务 │
└──────┘ └─────┘ └───────┘ └───────┘
附录
A. 项目文件结构
d:\code-workspace\example1\
├── config/ # 配置文件目录
│ ├── database.yaml # 数据库连接配置
│ └── settings.yaml # 系统配置
├── src/ # 源代码目录
│ ├── __init__.py
│ ├── cli.py # 命令行界面
│ ├── utils.py # 工具函数
│ ├── db_connectors/ # 数据库连接器模块
│ │ ├── base.py # 连接器基类
│ │ ├── kingbase.py # 金仓连接器
│ │ ├── oracle.py # Oracle连接器
│ │ └── mysql.py # MySQL连接器
│ ├── metadata/ # 元数据管理模块
│ │ ├── extractor.py # 元数据提取器
│ │ └── models.py # 数据模型定义
│ ├── sql_generator/ # SQL生成模块
│ │ └── generator.py # SQL生成器
│ └── relationship/ # 关系分析模块
│ ├── analyzer.py # 关系分析器
│ └── er_generator.py # ER图生成器
├── tests/ # 测试代码目录
│ ├── conftest.py # pytest配置
│ ├── test_db_connectors/ # 连接器测试
│ ├── test_metadata/ # 元数据测试
│ ├── test_sql_generator/ # SQL生成器测试
│ └── test_relationship/ # 关系分析测试
├── examples/ # 示例代码目录
│ ├── kingbase_demo.py # 金仓演示
│ └── kingbase_quickstart.py # 快速入门
├── docs/ # 文档目录
│ └── PROJECT_SPECIFICATION.md
├── dist/ # 打包输出目录
│ └── DBQueryTool.exe # 可执行文件
├── main.py # 程序入口
├── requirements.txt # Python依赖
├── pytest.ini # pytest配置
├── build.spec # PyInstaller配置
├── .gitignore # Git忽略规则
├── README.md # 项目说明
├── PUBLISH_TO_ATOMGIT.md # 发布指南
└── TECHNICAL_TUTORIAL.md # 本教程
B. 常用命令速查
# 项目运行
python main.py
# 安装依赖
pip install -r requirements.txt
# 运行测试
pytest tests/ -v
# 测试覆盖率
pytest tests/ --cov=src --cov-report=term-missing
# 打包构建
pyinstaller build.spec
# Git操作
git add .
git commit -m "message"
git push origin main
C. 参考资源
- Python官方文档: https://docs.python.org/3/
- Pydantic官方文档: https://docs.pydantic.dev/
- Rich库文档: https://rich.readthedocs.io/
- PyInstaller文档: https://pyinstaller.org/en/stable/
- pytest文档: https://docs.pytest.org/
- psycopg2文档: https://www.psycopg.org/docs/
- oracledb文档: https://python-oracledb.readthedocs.io/
- PyMySQL文档: https://pymysql.readthedocs.io/
文档版本: v1.0.0
创建日期: 2026-02-26
作者: Trae Solo模式
项目: 多数据库数据结构分析与查询系统

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)