【LangChain V1.0学习】第一课:基础模型调用包含国内大模型API调用和本地部署调用(deepseek/qwen/ollama/vllm)
langchain v1.0 基础大模型调用方法
LangChain 近期重磅官宣 V1.0 版本正式发布!这次更新最核心的亮点,就是将原本独立的 LangChain 核心框架与 LangGraph 工作流引擎进行了深度无缝整合,不仅完整保留了两者在 LLM 应用开发、复杂多智能体协作、状态管理等场景的核心能力,更通过更友好的 API 设计、更简洁的封装逻辑,彻底解决了过去多模块衔接繁琐、开发链路冗长的痛点,让 使用者上手体验丝滑度直接拉满。
作为AI使用者和开发者,我第一时间上手体验了 V1.0 的新特性,深刻感受到这次更新对生产级项目的实用性 —— 不管是快速搭建简单的问答链路,还是设计复杂的多智能体协作流程,都能少写不少重复代码,效率提升肉眼可见。
接下来我会把自己的学习历程、实操踩坑总结、核心功能拆解陆续分享出来,帮大家少走弯路、快速吃透 V1.0 的关键用法。如果你也在折腾 LangChain 相关开发,或者对新版本有疑问、有独家技巧,欢迎在评论区畅所欲言,咱们一起交流碰撞~
一、基础环境配置
推荐使用conda环境进行下面操作,如果不在conda环境下请忽略conda环境创建过程,conda下载链接
#conda环境创建
conda create -n langchanin python=3.12
#出现选项按y,等待安装完成后输入下列指令进入环境
conda activate langchanin
下面开始安装必要的包
pip install --upgrade langchain
pip install --upgrade langchain-community
pip install --upgrade langchain-deepseek
pip install --upgrade langchain-ollama
pip install --upgrade dashscope
pip install ipywidgets
pip install openai
pip install python-dotenv
二、大模型API调用
1、QWEN API
首先去qwen官网注册登录获取API QWEN API获取
该网站有详细的API获取流程,可以参考
我们在要运行的脚本的同级文件夹下创建.env文件,将申请的API放入,也可以将API放入系统环境中,具体步骤可以问AI或者CSDN搜索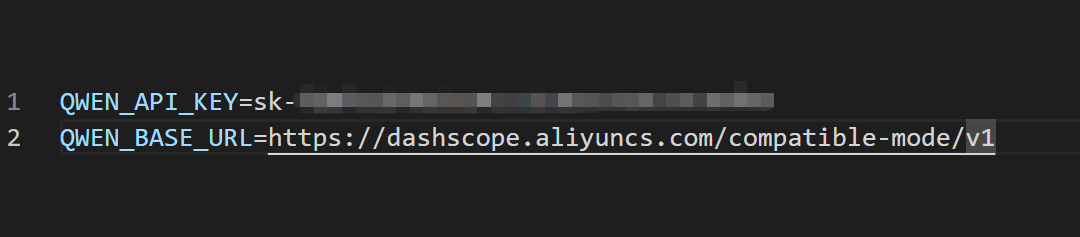
运行如下脚本,先使用OpenAI进行测试
import os
from openai import OpenAI
from dotenv import load_dotenv
#初始化大模型key 读取 .env文件中的key
load_dotenv(override=True)
qwen_key = os.getenv("QWEN_API_KEY")
qwen_base_url = os.getenv("QWEN_BASE_URL")
client = OpenAI(
api_key = qwen_key,
base_url = qwen_base_url
)
completion = client.chat.completions.create(
model="qwen-plus",
messages=[
{"role":"system", "content":"你是一个问题回答助手,善于回答各种问题"},
{"role":"user","content":"你是谁?"}
],
)
print(completion.model_dump_json())
运行后等待片刻即可看到输出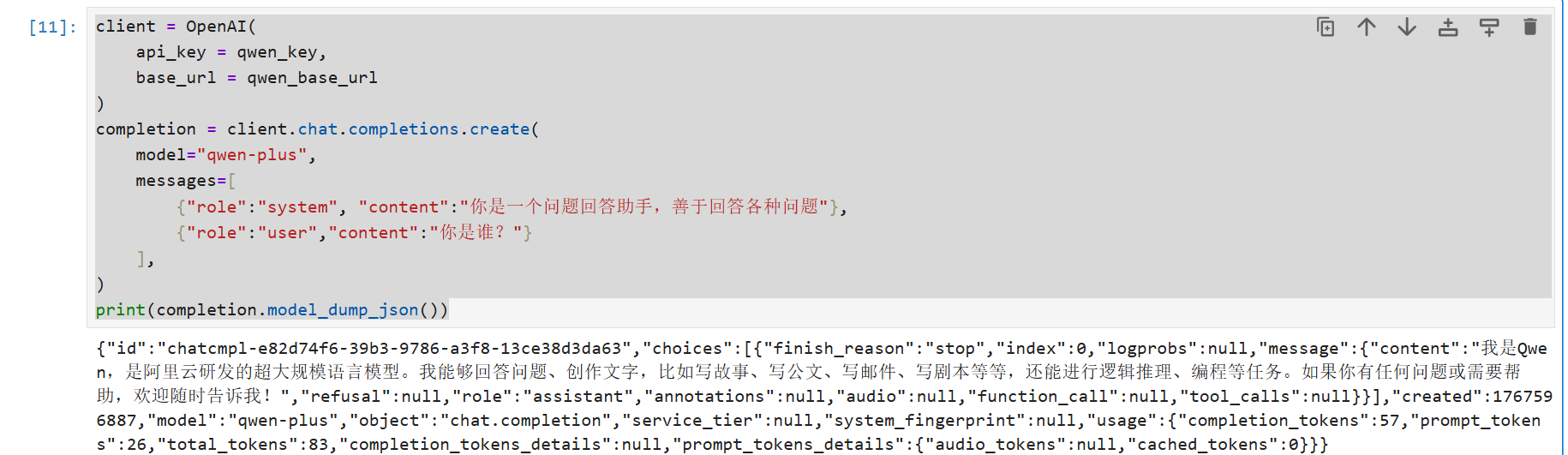
成功后使用langchain进行调用
import os
from openai import OpenAI
from dotenv import load_dotenv
from langchain_community.chat_models.tongyi import ChatTongyi
load_dotenv(override=True)
qwen_key = os.getenv("QWEN_API_KEY")
qwen_base_url = os.getenv("QWEN_BASE_URL")
model = ChatTongyi(
api_key = qwen_key,
base_url = qwen_base_url
)
question = "请问俄罗斯的首都是哪里"
result = model.invoke(question)
print(result.content)
运行成功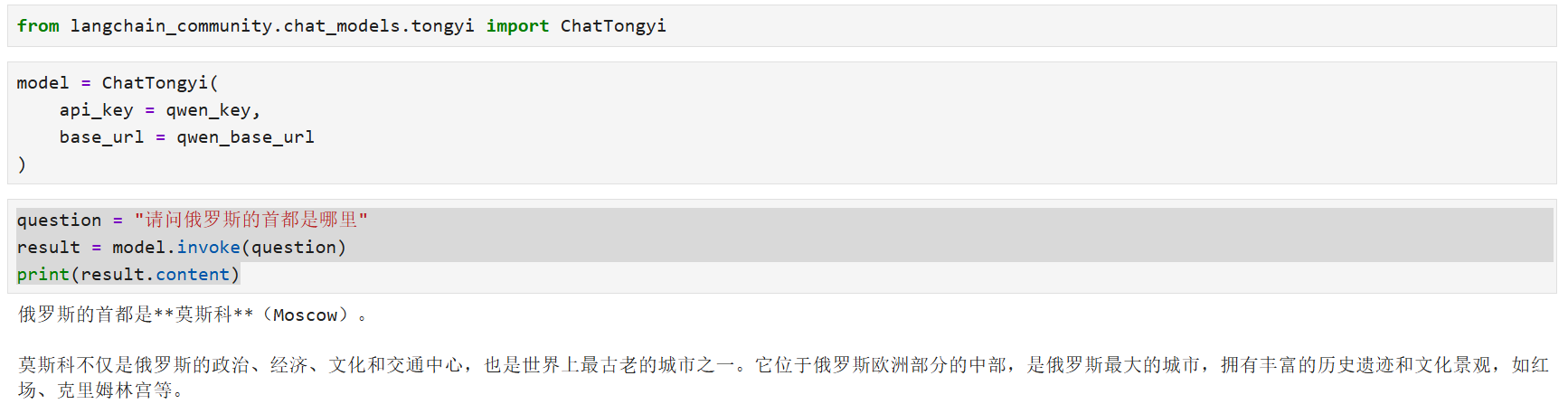
1、DeepSeek API
首先去官网申请一个deepseek API deepseek API申请
写入.env 文件
进行API连接测试
import os
from openai import OpenAI
from dotenv import load_dotenv
#初始化大模型key 读取 .env文件中的key
load_dotenv(override=True)
deepseek_key = os.getenv("DEEP_API_KEY")
deepseek_base_url = os.getenv("DEEP_BASE_URL")
client = OpenAI(
api_key = deepseek_key,
base_url = deepseek_base_url
)
completion = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role":"system", "content":"你是一个问题回答助手,善于回答各种问题"},
{"role":"user","content":"你是谁?"}
],
)
print(completion.choices[0].message.content)
成功后使用langchain进行调用
import os
from openai import OpenAI
from dotenv import load_dotenv
from langchain_deepseek import ChatDeepSeek
load_dotenv(override=True)
deepseek_key = os.getenv("DEEP_API_KEY")
deepseek_base_url = os.getenv("DEEP_BASE_URL")
model = ChatDeepSeek(
model="deepseek-chat"
api_key = deepseek_key,
base_url = deepseek_base_url
)
question ="俄罗斯的首都是哪个城市"
result =model.invoke(question)
print(result.content)
三、本地部署模型调用
1、ollama模型调用
首先安装完成ollama
使用ollama list查看模型
使用langchain调用本地部署ollama模型
from langchain_ollama import ChatOllama
model = ChatOllama(model="qwen3:latest")
question = "俄罗斯的首都是哪个城市"
result = model.invoke(question)
print(result)
成功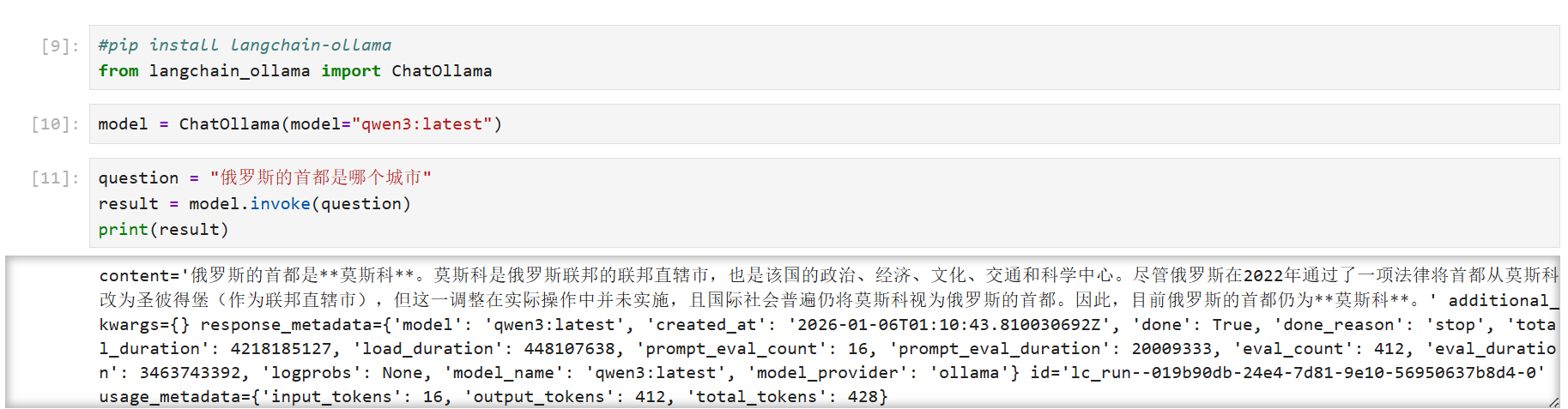
2、VLLM模型调用
本地部署完成VLLM模型
使用下列代码调用
from langchain_openai import ChatOpenAI
# 配置本地 vLLM 服务
llm = ChatOpenAI(
base_url="http://localhost:4788/v1", # vLLM 的 OpenAI 兼容 API 地址
api_key="token-abc123", # vLLM 不验证 API key,但必须提供非空字符串
model="qwen2vl8b", # 必须与 --served-model-name 一致,或使用实际模型路径名
temperature=0.7,
max_tokens=512,
)
# Running a simple query
print(llm.invoke("俄罗斯的首都是哪个城市"))

上述就是目前主流的模型调用方式,希望可以帮到你,如果有疑问可以在评论区讨论。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)