用豆包 + Codex 高效开发微信小游戏:《我在大明当首辅》开发首日实战
作为一名常年混迹 CSDN 的开发者,最近一直想做一款轻量化的微信小游戏 —— 主打明朝背景的文字养成策略类,核心玩法围绕 “科举入仕→回合制事件→晋升考核→多周目传承” 展开。借着 AI 辅助开发的风口,我尝试用「豆包打磨需求文档 + Codex 生成初始代码」的模式推进,本文就分享开发首日的完整流程、踩坑点和优化思路。
一、开发背景:为什么选 “文字类微信小游戏”+ AI 辅助?
文字类小游戏天生适配微信小程序的碎片化场景,无需复杂美术资源,核心靠规则和数值驱动;而 AI 辅助开发能大幅降低 “从想法到代码” 的门槛 —— 尤其是需求文档(PRD)打磨和基础代码生成环节,比纯手工效率提升至少 5 倍。
我的核心诉求很明确:
- 游戏规则要贴合明朝史实(官制、科举无错误);
- 新手友好,数值平衡,支持多周目玩法;
- 数据解耦(所有规则通过 JSON 配置,无需改代码即可调整);
- 适配微信小程序原生规范(rpx 单位、震动反馈、本地缓存等)。

二、第一步:用豆包打磨 1.3 万字的精准 PRD
2.1 从 “模糊想法” 到 “标准化 PRD” 的迭代
最初我的想法只有 “做明朝首辅养成游戏,有科举、晋升、事件”,连 PRD 的框架都不完整。这一步我选择用豆包作为 “需求分析师”,分阶段输出高质量 PRD:
阶段 1:生成 PRD 模板
首先给豆包输入精准 Prompt:
按照微信小程序游戏的标准,生成《我在大明当首辅》的产品需求文档(PRD)模板,要求涵盖产品概述、架构设计、角色系统、属性体系、科举系统、晋升系统、事件库,核心原则:历史合规、新手友好、数据解耦、多周目成瘾,所有规则需量化(无模糊表述)。
豆包返回了结构化的 PRD 模板,包含核心设计原则、全局约束、页面布局、系统规则等模块,避免了我遗漏关键维度(比如微信小程序的适配规范、渐进式解锁规则)。

阶段 2:分模块补充细节
模板只是骨架,关键是填充符合 “明朝背景 + 数值平衡” 的细节。我针对每个核心模块和豆包反复沟通迭代:
- 角色系统:要求豆包设计 8 个出身(3 个初始解锁 + 5 个成就解锁),初始属性总和固定 40 点(保证平衡),每个出身绑定专属特性、属性上限、晋升路线;
- 属性体系:量化 11 个核心属性(学识、人脉、威望等)的取值范围、增长 / 衰减规则,隐藏属性需满足 “新手期隐藏”;
- 科举系统:严格贴合明朝 “童试→院试→乡试→会试→殿试” 规制,输出简化版(新手)和完整版(成就解锁)的流程,附带精准计算公式;
- 事件系统:设计标准化 JSON 模板,要求每个事件的选项对应明确的属性变化、派系影响、后续事件触发概率。

-

阶段 3:校验与优化
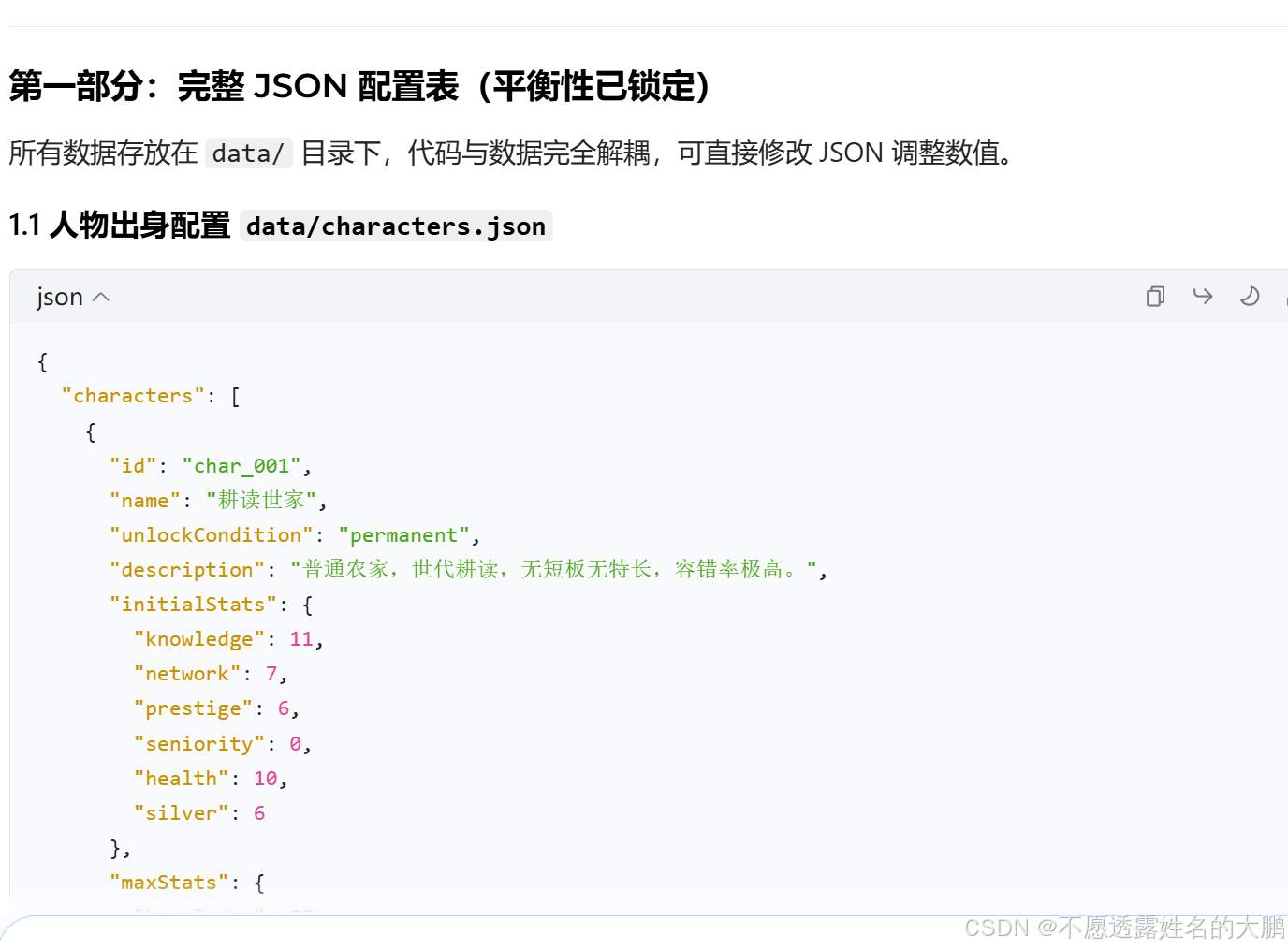
最后要求豆包 “校验 PRD 的历史合规性(明朝官制、科举规则)”“确保所有数值规则可量化(比如乡试成绩 = 学识 ×70%+ 前置加成 ×20%+ 出身加成 ×10%+ 随机值 (-5~+5))”,最终生成了 1.3 万字的完整 PRD(核心片段如下):
json
// PRD中角色配置示例(数据解耦核心)
{
"characters": [
{
"id": "char_001",
"name": "耕读世家",
"unlockCondition": "permanent",
"initialStats": {
"knowledge": 11,
"network": 7,
"prestige": 6,
"seniority": 0,
"health": 10,
"silver": 6
},
"maxStats": {
"knowledge": 85,
"network": 85,
"prestige": 85,
"health": 100,
"silver": 120000,
"integrity": 100
},
"traits": ["no_penalty", "exam_stability_10", "newbie_protection"]
}
]
}

2.2 豆包提效关键:精准 Prompt 设计
总结几个让豆包输出高质量 PRD 的技巧:
- 分模块迭代:避免一次性丢出所有需求,按 “产品概述→角色系统→属性规则→科举系统” 逐步拆解;
- 强制量化规则:明确要求 “所有属性变化、事件结果、晋升规则全部可量化,随机数范围严格锁定”;
- 绑定场景约束:比如 “符合微信小程序适配规范(375px 基准,rpx 单位,vibrateShort 震动反馈)”;
- 历史合规校验:要求 “严格贴合明朝九品十八级官制、科举规制,无朝代冲突”。
三、第二步:将 PRD 喂给 Codex 生成初始代码
PRD 落地的核心是代码,我选择 GitHub Copilot(基于 Codex)作为核心工具,核心思路是 “拆解 PRD 模块→分文件生成→聚焦核心逻辑”。
3.1 准备工作:拆解 PRD+Prompt 设计
首先把 PRD 拆解为 6 个核心模块,避免 Codex 因上下文过长生成混乱代码:
- 微信小程序项目基础配置(app.json、project.config.json);
- 页面结构(首页、角色创建页、游戏主页面、存档页、成就页);
- 配置文件解析(characters.json、events.json 加载);
- 核心数值计算(科举成绩、考核评分、属性增减);
- 事件系统(选项触发、属性变化、后续事件);
- 微信小程序原生能力(震动反馈、本地缓存)。
针对每个模块,设计精准的 Prompt,示例如下:
基于微信小程序规范,编写 pages/character/character.js 代码,功能:
- 加载 data/characters.json 配置;
- 实现姓名输入(仅 2-4 个汉字)、随机生成明朝男性姓名;
- 出身选择(初始解锁 / 成就解锁,未解锁显示灰色锁定);
- 实时预览选中出身的初始属性、专属特性;
- 确认开局按钮(姓名 + 出身选择完成后激活,二次确认后跳转游戏主页面)。
3.2 核心代码生成示例
示例 1:科举成绩计算函数(Codex 生成)
javascript
运行
// 乡试成绩计算(严格按PRD公式)
function calculateProvincialExamScore(knowledge, preBonus, traitBonus) {
// 公式:乡试成绩=当前学识值×70% + 前置事件加成×20% + 出身特性加成×10% + 随机值(-5~+5)
const baseScore = Math.floor(knowledge * 0.7 + preBonus * 0.2 + traitBonus * 0.1);
const randomOffset = Math.floor(Math.random() * 11) - 5; // -5~+5
let finalScore = baseScore + randomOffset;
// 边界值处理
if (finalScore < 0) finalScore = 0;
if (finalScore > 100) finalScore = 100;
return finalScore;
}
// 会试成绩计算(同逻辑)
function calculateMetropolitanExamScore(knowledge, preBonus, traitBonus) {
const baseScore = Math.floor(knowledge * 0.7 + preBonus * 0.2 + traitBonus * 0.1);
const randomOffset = Math.floor(Math.random() * 11) - 5;
let finalScore = baseScore + randomOffset;
if (finalScore < 0) finalScore = 0;
if (finalScore > 100) finalScore = 100;
return finalScore;
}
示例 2:微信小程序页面结构(首页 wxml,Codex 生成)
xml
<!-- pages/index/index.wxml -->
<view class="container">
<!-- 游戏LOGO -->
<view class="logo">
<text class="logo-text">我在大明当首辅</text>
</view>
<!-- 核心功能按钮组 -->
<view class="btn-group">
<button class="main-btn" bindtap="startGame">开始游戏</button>
<button class="sub-btn" bindtap="loadSave">读取存档</button>
<button class="sub-btn" bindtap="showAchievement">我的成就</button>
<button class="mini-btn" bindtap="showSetting">设置</button>
</view>
<!-- 底部版权信息 -->
<view class="copyright">
<text>© 2025 我在大明当首辅 版权所有</text>
</view>
</view>
3.3 首日生成的核心成果
- 完整的微信小程序项目结构(5 个核心页面 + 配置文件);
- 配置文件解析工具类(加载 characters.json/events.json);
- 核心数值计算函数(科举、考核、属性增减);
- 基础页面 UI(贴合 PRD 的布局规范,rpx 单位适配);
- 微信小程序原生能力封装(震动反馈、本地缓存)。

四、开发首日踩坑与优化(更优解决方案)
AI 生成代码并非 “一键完美”,首日遇到 3 个核心问题,我总结了对应的优化方案:
坑 1:Codex 生成的数值计算逻辑遗漏边界条件
问题:PRD 要求随机值范围 - 5~+5,但 Codex 初始生成的代码随机值范围错误(0~10),且未处理分数边界(比如负数、超过 100)。优化方案:
- 将 PRD 中的计算公式单独提取,作为 Prompt 的核心,明确要求 “边界值处理 + 整数结果”;
- 生成后手动校验核心公式,或让 Codex 生成单元测试用例(比如 “为 calculateProvincialExamScore 函数生成 5 个测试用例,覆盖不同学识值、随机值边界”)。
坑 2:微信小程序适配不完整
问题:Codex 生成的代码未实现震动反馈、本地缓存的错误处理,且 wxss 样式未贴合 PRD 的 “大明红、藏青” 主色调。优化方案:
- 补充 Prompt 明确要求 “按钮点击调用 wx.vibrateShort (),缓存操作添加 try-catch”;
- 引入微信小程序官方 WeUI 组件库,替换 Codex 生成的基础样式,提升 UI 适配性;
- 手动补充主色调样式(#8B0000、#0F172A),确保视觉贴合 PRD。
坑 3:数据解耦未落地(配置写死在代码中)
问题:PRD 要求 “所有游戏内容与代码完全分离,通过 JSON 配置调整”,但 Codex 初始生成的代码把角色属性写死在 js 文件中。优化方案:
- 要求 Codex 生成 “配置解析工具类”(utils/configParser.js),专门加载 JSON 配置;
- 生成 JSON Schema 校验配置文件(比如 “为 characters.json 生成 JSON Schema,校验属性类型、取值范围”),避免配置错误;
- 采用懒加载模式,仅在需要时加载对应配置(比如角色创建页仅加载 characters.json),提升性能。
更优实践总结
- 分模块生成:将 PRD 拆解为≤500 字的模块,避免 Codex 上下文过载;
- TypeScript 替代 JS:让 Codex 生成 TypeScript 代码 + 接口定义(比如 Character、Event 接口),减少运行时错误;
- 配置优先:所有可变规则(角色、事件、数值)全部抽离为 JSON,代码仅负责解析和计算;
- 人工兜底:AI 负责 “重复劳动(UI、基础逻辑)”,人工聚焦 “核心规则、边界条件、体验优化”。
五、首日总结与后续计划
首日核心成果
- 完成从 “模糊想法” 到 “1.3 万字精准 PRD” 的落地;
- 生成微信小游戏的核心代码骨架,覆盖 80% 的基础功能;
- 验证了 “豆包打磨 PRD + Codex 生成代码” 的高效性,首日完成传统开发模式 2-3 天的工作量。
后续计划
- 调试代码适配微信开发者工具,修复 UI 和交互 bug;
- 完善事件系统的后续事件触发逻辑;
- 测试多周目传承、成就解锁功能;
- 校验历史合规性(明朝官制、科举规则);
- 优化性能(配置懒加载、缓存策略)。
六、最后:AI 辅助开发的核心逻辑
首日开发让我深刻体会到:AI 辅助开发的核心不是 “替代开发者”,而是 “把开发者从重复劳动中解放出来”。高质量的 PRD 是 AI 生成优质代码的前提 ——PRD 越详细、量化、贴合场景,Codex 生成的代码越精准。
对于想尝试 AI 开发微信小游戏的开发者,我的建议是:
- 先花时间打磨 PRD,避免 “想法模糊→AI 生成混乱代码”;
- 拆解需求模块,用精准 Prompt 驱动 AI;
- 人工聚焦核心规则和体验优化,AI 负责基础代码和重复逻辑。
后续我会持续更新《我在大明当首辅》的开发日志,包括事件系统完善、多周目传承实现、微信小程序提审等内容,感兴趣的同学可以关注~

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)