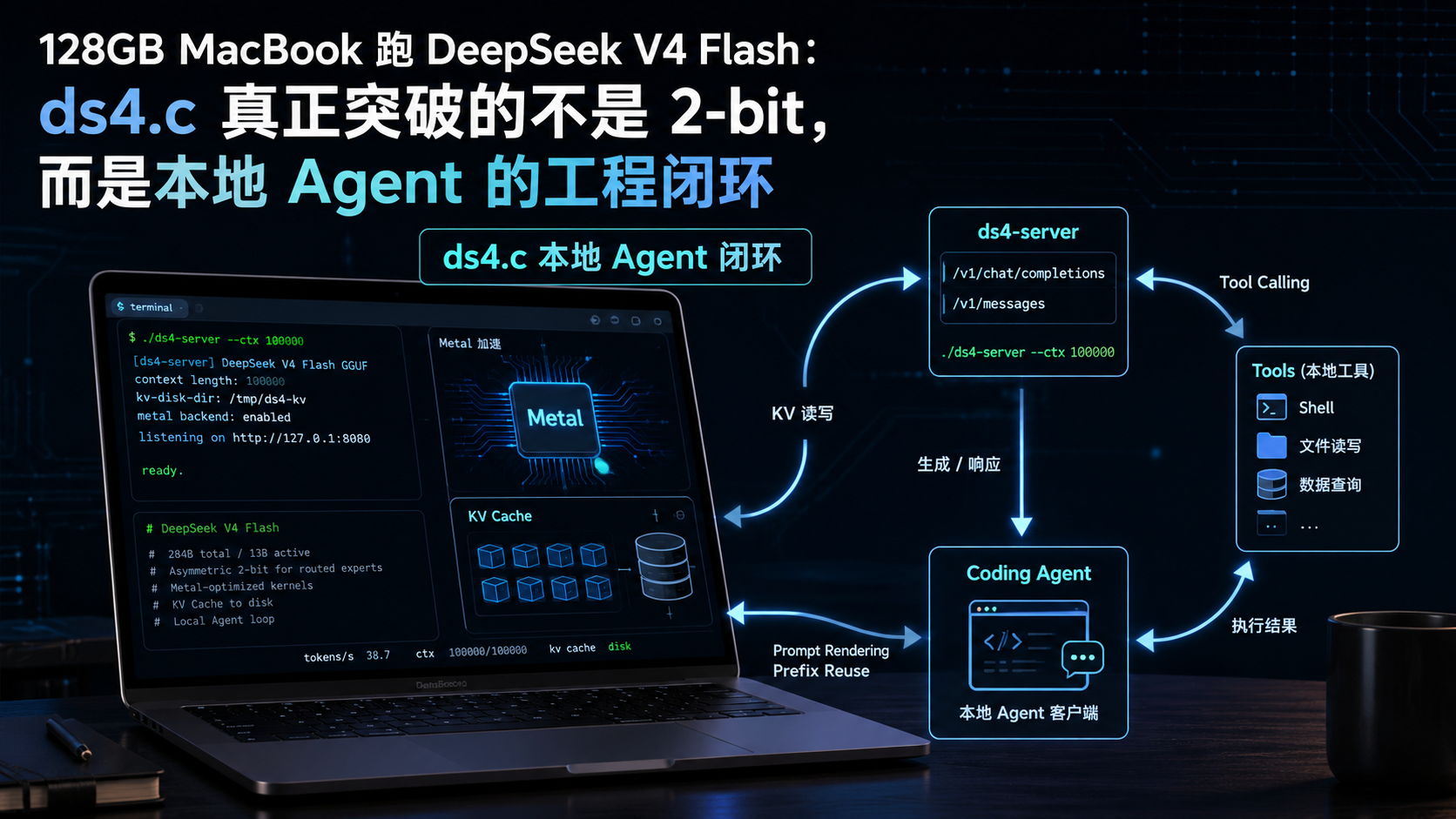
128GB MacBook 跑 DeepSeek V4 Flash:ds4.c 真正突破的不是 2-bit,而是本地 Agent 的工程闭环
如果只看传播标题,ds4 很容易被讲成一个“2-bit 奇迹”。用不对称 2-bit 量化把 DeepSeek V4 Flash 的 routed experts 压进 128GB 级别机器;用 Metal-only 的专用路径服务 Apple Silicon;把 KV Cache 从纯内存对象变成可落盘、可恢复、可淘汰、可观测的状态;提供 OpenAI / Anthropic 兼容 API,让
128GB MacBook 跑 DeepSeek V4 Flash:ds4.c 真正突破的不是 2-bit,而是本地 Agent 的工程闭环
文章目录
- 128GB MacBook 跑 DeepSeek V4 Flash:ds4.c 真正突破的不是 2-bit,而是本地 Agent 的工程闭环
-
- 1. 先别急着看 2-bit:本地 Agent 的问题不是“能不能加载模型”
- 2. 不对称 2-bit:只压最占空间的部分,而不是把全模型一刀切
- 3. KV Cache 变成磁盘一等公民:长上下文 Agent 的关键不只是内存大小
- 4. OpenAI / Anthropic API + 工具调用:本地模型要进 Agent 生态,接口比 Demo 更重要
- 5. 最小跑通路径:先证明 server 能工作,再谈 Agent 接入
- 6. 硬事实来源表:哪些是官方事实,哪些是工程推论
- 7. 现实边界:这是 alpha、串行推理、Metal-only,不是本地推理万能答案
- 8. 怎么判断 ds4 这类项目是否值得你折腾
- 总结:真正的突破是把“本地可运行”推进到“本地可做 Agent”
- 参考
过去讨论本地大模型,很多人会把问题简化成一句话:模型能不能塞进显存或内存。
但本地 coding agent 不是一次性的聊天 Demo。它会反复读取仓库、追加上下文、调用工具、接收工具结果、再发起下一轮推理。你会很快遇到几个更实际的问题:
- 模型权重怎么放进一台个人机器?
- 1M context 的 KV Cache 怎么处理?
- Agent 每轮都重发长 prompt,前缀能不能复用?
- 工具调用怎么从本地模型输出变成客户端能理解的 OpenAI / Anthropic 格式?
- 这个东西到底是“能跑”,还是能支撑一个真实 coding agent 循环?
Redis 作者 antirez 开源的 ds4,真正值得看的不是“一个 C 文件创造奇迹”,而是它把这些问题放进了同一个工程闭环里。
更准确地说,ds4 不是通用 GGUF runner,也不是套在别的推理框架外面的壳。它是一个很窄的 DeepSeek V4 Flash 专用本地推理引擎:Metal-only,面向高端 Apple Silicon 机器,从模型加载、量化布局、Metal graph、KV 状态、HTTP API、工具调用到 coding agent 验证,都围绕一个目标收敛:
让一个本地模型不只是能启动,而是尽量像一个可用的本地 Agent 后端。
这篇文章不复述传播口号。我们按工程账来拆:ds4 到底解决了哪几件事,又有哪些边界不能忽略。
1. 先别急着看 2-bit:本地 Agent 的问题不是“能不能加载模型”
DeepSeek 官方发布页给出的基础信息是:DeepSeek V4 Flash 是 284B total / 13B active params 的 MoE 模型,并支持 1M context。
这组数字很容易被误读。284B total 主要影响权重存储、下载体积和本地加载压力;13B active 主要影响每 token 推理时真正走过的计算路径。也就是说,active 参数少不等于权重不用装进机器。MoE 的优势是每次只激活一部分专家,但完整专家池仍然是模型权重的一部分。
对本地 coding agent 来说,完整链路至少包含这些部分:
| 层次 | 要解决的问题 |
|---|---|
| 模型权重 | 权重是否能装进内存,量化后质量是否还能支撑代码任务 |
| 推理后端 | 是否能高效利用 Apple Silicon / Metal |
| 上下文状态 | 长 prompt 和多轮对话是否能复用 KV,而不是每轮从零 prefill |
| API 兼容 | 是否能接入已有 OpenAI / Anthropic 风格 agent 客户端 |
| 工具调用 | 模型生成的工具调用能否被客户端可靠解析、回放、继续 |
| 验证体系 | 是否用官方 logits、长上下文、agent 场景做过验证 |
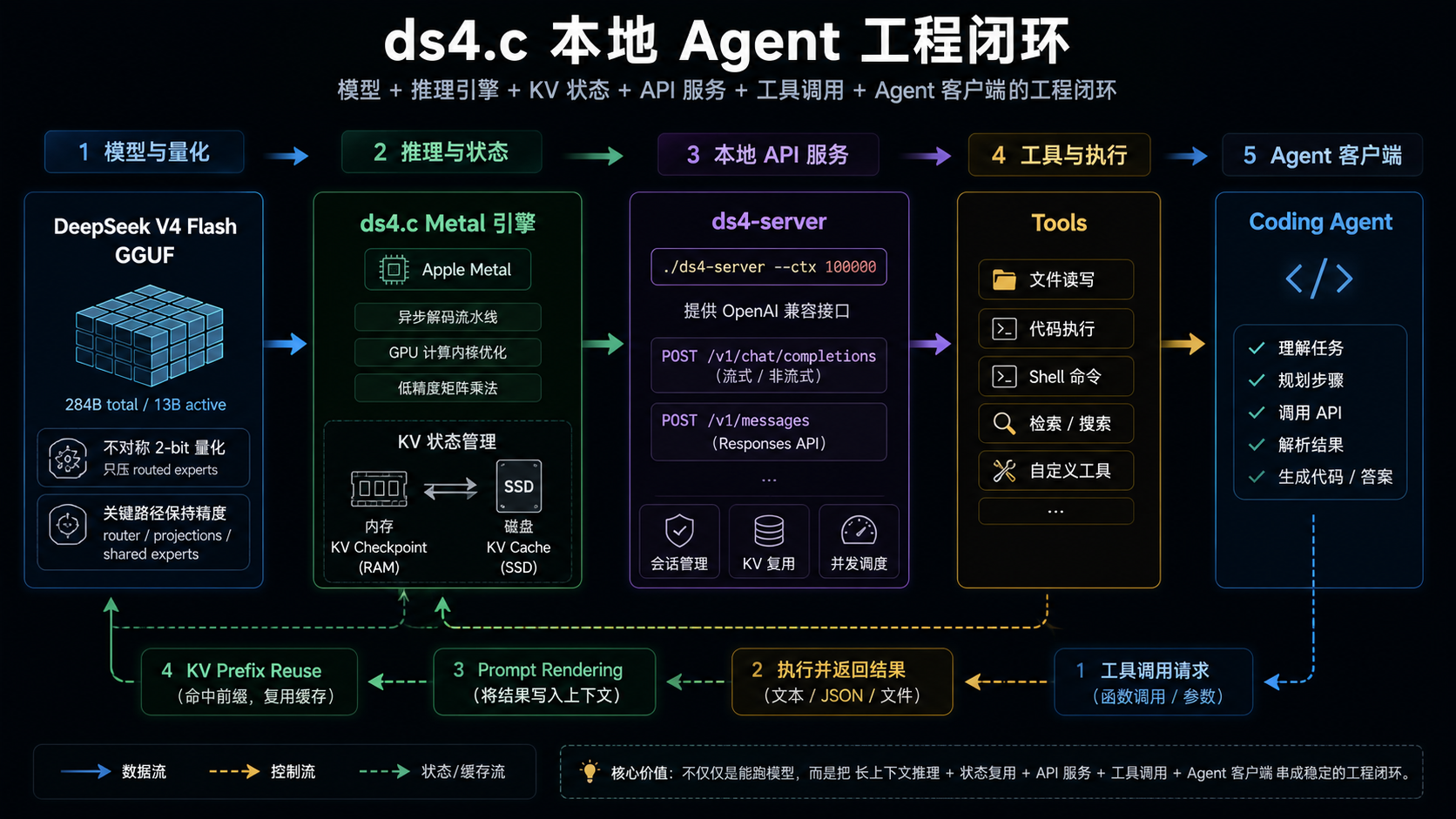
这也是 ds4 和普通“模型跑起来了”之间的差别。项目 README 的主线不是单点推理,而是三件事一起工作:推理引擎 HTTP API、为这个引擎专门制作的 GGUF、以及 coding agent 验证。
本地 Agent 的失败,经常不是失败在第一轮回答,而是失败在第二轮、第三轮:上下文变长,工具结果插回 prompt,客户端重发历史,模型输出工具调用,服务端需要把这些状态稳定地接住。
所以 ds4 的主线不是“2-bit 很神奇”,而是:
在一个非常窄的模型和硬件范围内,把本地 Agent 需要的状态管理、接口兼容和长上下文复用做成闭环。
2. 不对称 2-bit:只压最占空间的部分,而不是把全模型一刀切
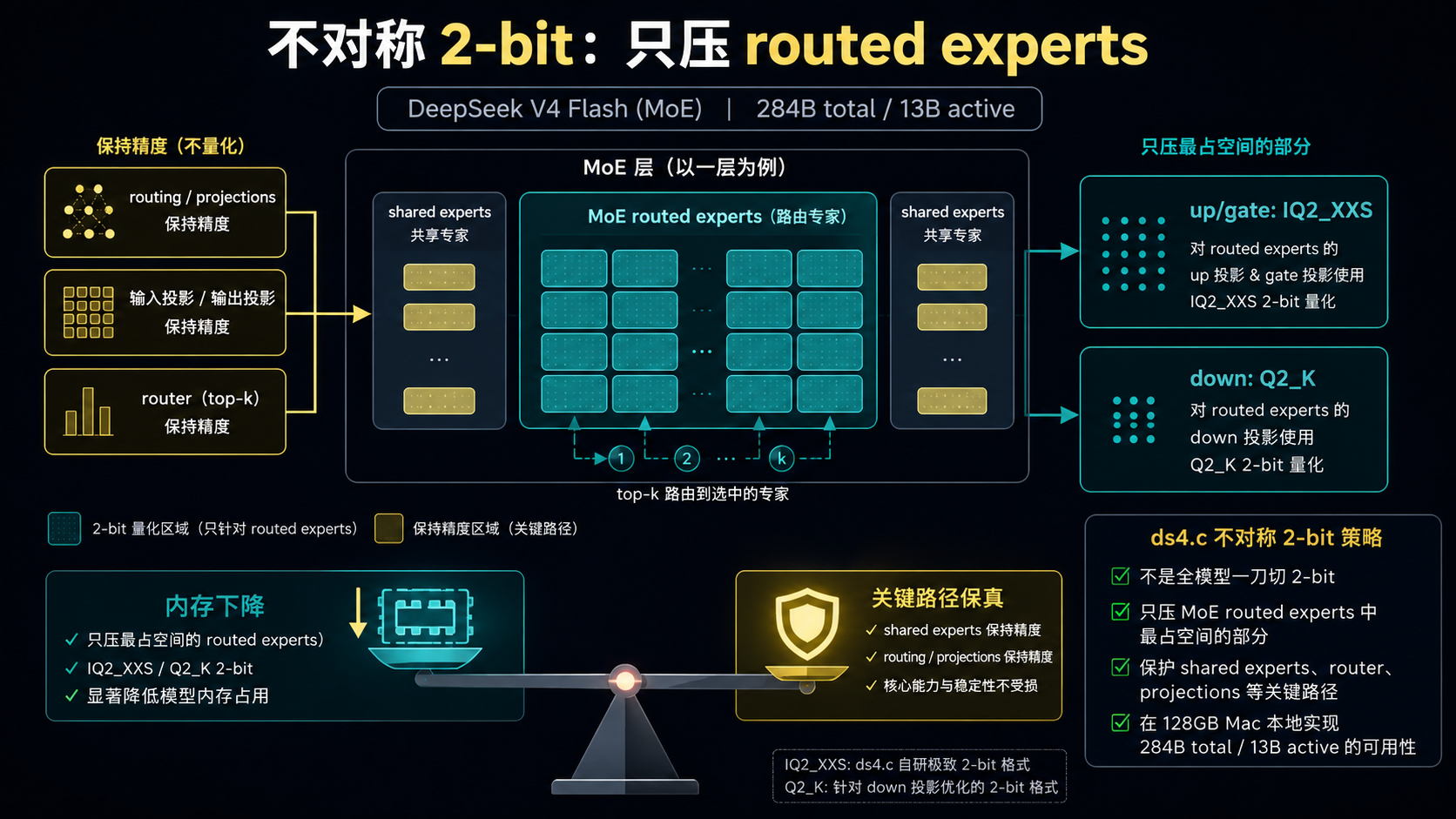
推文里最容易传播的点是 2-bit 量化。但如果只记住“2-bit”,反而会误解 ds4 的关键。
ds4 的 2-bit 量化是非常不对称的。README 里说明,它只量化 routed MoE experts,其中 up/gate 使用 IQ2_XXS,down 使用 Q2_K。这些 routed experts 占据了模型空间的大头;而 shared experts、projections、routing 等关键组件保持不动,用来保护质量。
这背后的第一性原理很简单。
如果你想把模型塞进本地机器,不能平均地对所有参数动刀。你要先问两个问题:
- 哪部分最占空间?
- 哪部分一旦损伤,最容易破坏模型行为?
MoE 模型给了一个天然分层。专家参数很多,体积大,但每次只激活一部分;路由、投影、共享专家等路径更像“控制面”和关键连接层,随便压会影响模型稳定性。ds4 的做法是把压缩集中打到体积最大的 routed experts 上,而不是对全模型做均匀低比特处理。
这也解释了为什么它不是一个通用 GGUF runner。通用 runner 需要接很多模型、很多 layout、很多 quant mix;ds4 反过来:固定 DeepSeek V4 Flash 的形状,固定它期望的 GGUF 布局,尽早验证 metadata 和 tensor layout,不匹配就失败。
这类设计的代价是适用面窄。
收益是:当你只服务一个模型,就能把加载、量化、Metal 图、KV 状态和 agent API 全部做成一条垂直路径,减少通用框架层面的抽象成本。
3. KV Cache 变成磁盘一等公民:长上下文 Agent 的关键不只是内存大小
1M context 很吸引人,但在本地机器上,真正的账要算 KV Cache:
权重内存 + KV/indexer + Metal/系统余量 > 128GB 时,不能盲目拉满 1M context
README 给了一个很现实的提醒:在 128GB RAM 的机器上,2-bit quant 本身已经大约 81GB。完整 1M context 还会使用大约 26GB 内存,其中 compressed indexer 大约 22GB。这样一算,1M context 并不是“有 128GB 就随便开”。
所以在 128GB RAM 机器上,配置 100k 到 300k context 更理智。
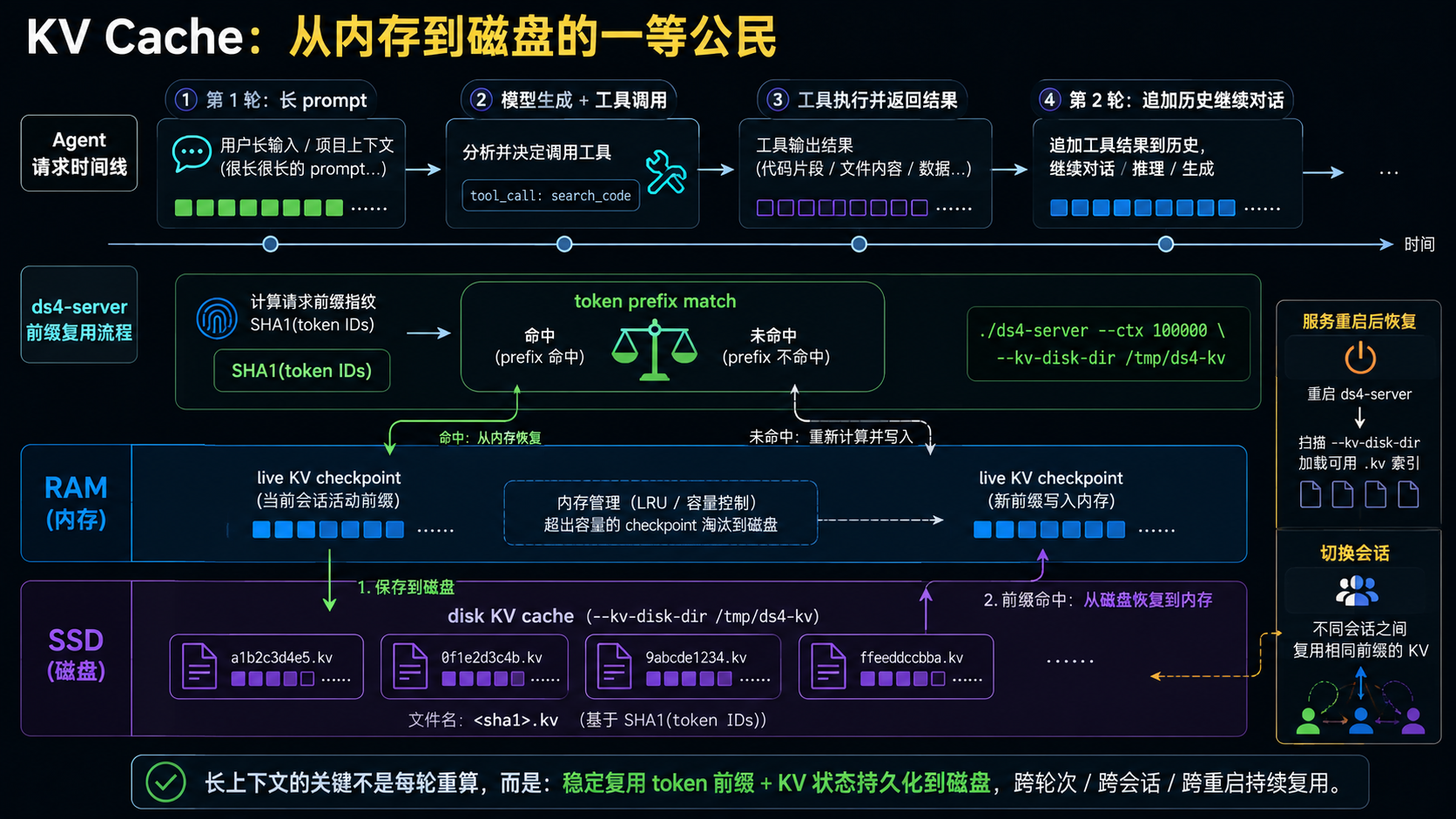
这就是 ds4 对 KV Cache 的核心判断:不要默认 KV Cache 必须只属于 RAM。DeepSeek V4 Flash 的 KV Cache 足够压缩,现代 MacBook 的 SSD 又足够快,于是 KV Cache 可以成为磁盘上的一等公民。
在 server 场景下,这个问题更明显。
OpenAI / Anthropic 风格的 Chat API 通常是 stateless 的。Agent 客户端每轮请求会把完整对话历史重新发给服务端。对于云服务来说,这背后可以有复杂缓存系统;但本地服务如果每次都从 token zero 重新 prefill,长上下文 agent 很快就不可用了。
ds4-server 的做法是:
- 先把请求渲染成模型实际看到的 token stream;
- 用 token 前缀匹配当前 live KV checkpoint;
- 如果当前内存里的 checkpoint 覆盖了这个前缀,就直接继续;
- 如果切换到了另一个 session 或重启了服务,则尝试从磁盘 KV cache 恢复;
- 磁盘 cache 的 key 是 token IDs 的 SHA1,而不是原始文本;
- cache 文件保存 DS4-specific session payload,而不是通用图状态。
这里有两个细节值得注意。
第一,key 是 token ID,而不是 raw text。因为模型真正消费的是 token 序列,同样文本在不同模板、特殊 token、工具渲染下可能并不等价。按 token IDs 做 hash,才是在模型输入层面做缓存。
第二,磁盘缓存不是简单保存一段文本,而是保存可以恢复推理状态的 DS4 session payload,包括 checkpoint tokens、下一 token logits、KV rows、indexer rows 等状态。这样恢复后,不必从头处理长 prompt,甚至可以从保存的状态继续推理。
这就是“磁盘一等公民”的意思:磁盘不是事后 dump 日志,而是 Agent 长上下文生命周期的一部分。
4. OpenAI / Anthropic API + 工具调用:本地模型要进 Agent 生态,接口比 Demo 更重要
很多本地推理项目停在 CLI。CLI 能证明模型能回答问题,但不能证明它能接进真实 agent 工具链。
ds4-server 提供本地 OpenAI / Anthropic 兼容接口,支持:
GET /v1/modelsPOST /v1/chat/completionsPOST /v1/completionsPOST /v1/messages
OpenAI 风格的 /v1/chat/completions 支持 messages、采样参数、stream、tools、tool_choice 等字段。Anthropic 风格的 /v1/messages 面向 Claude Code 类客户端,支持 system、messages、tools、tool_choice、thinking controls 和 SSE streaming。
更关键的是工具调用。
ds4-server 会把 OpenAI tool schema 渲染成 DeepSeek 的 DSML tool 格式,再把模型生成的 DSML tool calls 映射回 OpenAI tool calls。可以把 DSML 理解成模型可读、可采样的工具协议文本:它既要让模型知道有哪些工具,也要让服务端能把模型输出还原成客户端 API 里的结构化 tool call。Anthropic 的 tool_use block 也会被转换到内部消息结构里。工具结果再进入后续 prompt,继续影响下一轮推理。
这里最容易被忽视的是“精确回放”。
工具调用不是普通文本。客户端可能保存 JSON 形式的 tool call history,下一轮再发回来。服务端如果重新渲染出来的 DSML 和模型当时采样出来的不一致,就可能破坏 token prefix match,进而让 KV cache 失效。
README 提到 ds4-server 维护了 exact-DSML replay map,用不可猜测的 tool IDs 映射回模型原始采样出的 DSML block。这个映射甚至可以写进磁盘 KV cache 的 optional tool-id map section。这样服务重启后,后续客户端历史仍有机会按原来的字节形态渲染回来。
这听起来像小细节,但对 Agent 来说很关键。
因为 Agent 的上下文不是一段干净的自然语言聊天记录,而是由 system prompt、工具 schema、assistant tool calls、tool results、用户输入、thinking mode 控制符混合出来的协议文本。只要协议文本不稳定,prefix cache 就很难稳定。
所以 ds4-server 不是简单“兼容一下 API 字段”,而是在尝试把工具调用、prompt rendering 和 KV cache 命中率绑在一起看。
5. 最小跑通路径:先证明 server 能工作,再谈 Agent 接入
如果你只是想理解 ds4,不建议一上来就拉满 1M context 或直接接复杂 agent。更短的路径是先跑通四件事:下载 q2、编译、启动 server、用最小 chat completion 验证接口。
前提是:你有高内存 Apple Silicon 机器,预留足够磁盘空间,装好 Xcode Command Line Tools,并且能接受 alpha 项目的不稳定性。模型下载体积很大,第一次下载和启动都不要按普通小模型的节奏预期。
git clone https://github.com/antirez/ds4.git
cd ds4
./download_model.sh q2
make
./ds4-server --ctx 100000 --kv-disk-dir /tmp/ds4-kv --kv-disk-space-mb 8192
另开一个终端,用 OpenAI 兼容接口做最小验证:
curl http://127.0.0.1:8000/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{
"role": "user",
"content": "用三句话解释 Redis streams 的设计目标。"
}
],
"stream": true
}'
如果这个请求能稳定返回,再考虑接 opencode、Pi 或 Claude Code 这类客户端。
这里有一个很重要的配置原则:客户端 context 不能高于 ds4-server --ctx 的值。如果 server 用的是 --ctx 100000,客户端配置里也应该把 context window 设为 100000 或更低。否则客户端以为自己可以塞更多上下文,服务端实际接不住,长对话和工具循环就会变得不可预测。
这一步的目标不是做性能炫技,而是确认三件事:
| 验证点 | 说明 |
|---|---|
| 模型能加载 | q2 GGUF 能被 ds4 识别,路径和符号链接正确 |
| server 能服务 | OpenAI 兼容接口能返回 streaming 响应 |
| context 策略一致 | server 和客户端对 context 上限的理解一致 |
等这三件事稳定以后,再去验证工具调用、长上下文 prefix reuse、磁盘 KV 恢复,才比较有意义。
6. 硬事实来源表:哪些是官方事实,哪些是工程推论
为了避免把传播判断、README 描述和本文推论混在一起,这里把关键事实拆开。
| 事实或判断 | 来源类型 | 说明 |
|---|---|---|
| DeepSeek V4 Flash 是 284B total / 13B active params | DeepSeek 官方发布页 | 官方发布页明确列出 V4 Flash 的总参数和激活参数 |
| DeepSeek V4 系列支持 1M context | DeepSeek 官方发布页 | 官方发布页说明 1M context 是 DeepSeek 官方服务的默认能力 |
| DeepSeek V4 API 支持 OpenAI ChatCompletions 和 Anthropic APIs | DeepSeek 官方发布页 | 这是官方 API 层面的兼容说明 |
| ds4 是 DeepSeek V4 Flash 专用,不是通用 GGUF runner | ds4 README | README 明确强调项目 intentionally narrow,只支持为该项目准备的 GGUF |
| q2 面向 128GB RAM,q4 面向 256GB 以上机器 | ds4 README | 模型下载说明中给出 q2/q4 的机器内存建议 |
2-bit 量化只作用在 routed MoE experts,up/gate 为 IQ2_XXS,down 为 Q2_K |
ds4 README | README 的 Model Weights 部分描述了不对称量化策略 |
| q2 权重大约 81GB,完整 1M context 额外约 26GB,128GB 机器更建议 100k 到 300k context | ds4 README | README 的 Agent Client Usage 部分给出内存账和 context 建议 |
ds4-server 是 Metal-only,推理通过单个 Metal worker 串行执行,当前不 batch 独立请求 |
ds4 README | README 的 Server / Backends 部分描述 server 限制 |
| 磁盘 KV cache 用 token IDs 的 SHA1 做 key,cache 文件为 DS4-specific session payload | ds4 README | README 的 Disk KV Cache 部分描述 cache key、文件结构和恢复机制 |
| HF 模型页显示模型为 284B params,且量化文件偏向 DS4 inference engine | Hugging Face 模型页 | HF 页面提供模型 size 和 DS4-specific quants 的说明 |
| “本地 Agent 的关键是状态管理” | 本文工程推论 | 基于 stateless API、prefix reuse、disk KV、tool replay 这些事实推导 |
| “ds4 的价值在于本地 Agent 闭环,而不是单点 2-bit” | 本文工程推论 | 基于模型专用化、server API、KV 状态、agent 验证综合判断 |
7. 现实边界:这是 alpha、串行推理、Metal-only,不是本地推理万能答案
如果要写得严谨,就必须把边界说清楚。
| 边界 | 含义 |
|---|---|
| DeepSeek V4 Flash 专用 | 只支持为这个项目发布的 DeepSeek V4 Flash GGUF,不是任意 GGUF loader |
| Metal-only | 主要面向 Apple Silicon,server 是 Metal-only |
| 高内存机器取向 | 128GB RAM 是 q2 入门线,q4 更偏向 256GB 以上机器 |
| 1M context 不等于建议拉满 | 128GB 机器更现实是 100k 到 300k context |
| alpha quality | README 明确说项目还处于 alpha quality |
| server 推理串行 | 请求解析在 client threads,真正 inference 通过一个 Metal worker 串行执行 |
| 暂无批处理 | 当前 server 不 batch 多个独立请求,并发请求会排队 |
| CPU path 非生产目标 | CPU 路径主要用于 correctness check,不应当当成生产路径 |
这些边界并不削弱 ds4 的价值,反而说明它的工程取舍很清楚。
如果目标是“支持所有模型、所有硬件、所有客户端”,你大概率会走向 llama.cpp、vLLM、SGLang 这类通用系统。
如果目标是“让一个具体模型在一类具体个人机器上尽量可用”,就可以反过来做垂直优化:固定模型形状,固定 GGUF,固定 Metal 后端,固定 agent API 适配,然后围绕长上下文和工具调用打磨状态复用。
ds4 选择的是后者。
它不是要替代通用推理框架,而是在展示另一种路线:当模型结构、硬件和 agent 目标都足够明确时,专用系统可以把很多通用系统暂时顾不上的细节做深。
8. 怎么判断 ds4 这类项目是否值得你折腾
如果你只是想本地跑一个聊天模型,ds4 可能不是最短路径。更成熟的通用工具通常更省心:模型选择更多,文档更全,社区踩坑更多,硬件覆盖也更广。
但如果你关心本地 coding agent,尤其是长上下文、多轮工具调用、服务重启后的状态恢复,ds4 很值得研究。原因不是“省 API 费”这么简单,而是它把几个未来会越来越重要的问题摆到了台面上。
| 你的需求 | 更合理的选择 |
|---|---|
| 只是本地聊天、摘要、普通问答 | 优先考虑成熟通用工具和更轻模型 |
| 想快速试多个模型 | 优先用通用 runner,不要被单模型专用系统绑住 |
| 想研究本地 coding agent 的长上下文状态管理 | ds4 值得读 README、server 和 KV cache 设计 |
| 想做本地工具调用 | 重点看工具 schema、tool call、tool result 的协议渲染是否稳定 |
| 想提高多轮效率 | 关键不是单轮 tok/s,而是长 prompt 前缀能不能复用 |
| 想做专用推理引擎 | 固定模型 layout 可以换来更垂直的优化空间 |
| 想评估本地模型是否可用 | 不只测问答,还要测 agent 循环、工具调用、长上下文、重启恢复 |
本地 Agent 的工程重心,可能会从“有没有模型”转向“状态怎么管理”。
云端 API 把很多状态管理藏起来了。本地部署以后,这些问题会重新暴露:上下文如何渲染,KV 如何保存,工具调用如何回放,多 session 如何切换,服务重启后怎样恢复,哪些缓存可以跨 quant 复用,哪些必须严格隔离。
ds4 的价值在于,它没有把这些问题当成外围功能,而是放进了推理引擎和 server 的核心路径。
总结:真正的突破是把“本地可运行”推进到“本地可做 Agent”
如果只看传播标题,ds4 很容易被讲成一个“2-bit 奇迹”。
但从工程角度看,它更像一个本地 Agent 后端原型:
- 用不对称 2-bit 量化把 DeepSeek V4 Flash 的 routed experts 压进 128GB 级别机器;
- 用 Metal-only 的专用路径服务 Apple Silicon;
- 把 KV Cache 从纯内存对象变成可落盘、可恢复、可淘汰、可观测的状态;
- 提供 OpenAI / Anthropic 兼容 API,让 opencode、Pi、Claude Code 风格客户端能接进来;
- 把工具调用的 DSML 渲染、解析、回放和 KV prefix match 放在同一个系统里考虑;
- 用官方 logits、长上下文测试和 agent 场景验证,而不是只做短 prompt Demo。
所以这件事不应该被理解成“个人电脑已经取代云端 GPU 集群”。
更准确的结论是:
对一部分高端个人机器、本地代码任务和长上下文 Agent 场景来说,专用模型 + 专用量化 + 专用 KV 状态管理 + 兼容 API 的工程闭环,正在把本地推理从玩具 Demo 推向可用系统。
今天的 ds4 还很窄,也还是 alpha。
但它指向的问题很大:本地 Agent 的核心不是模型一次回答,而是状态能否跨轮、跨工具、跨重启稳定延续。
参考

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)