OpenCV+CNN的Windows人脸识别多途径实现
以低技术门槛[常用环境、工具、人工智能AI编程手段,在Windows下用OpenCV+CNN实现人脸识别,两种类型库使用展现:OpenCV-TensorFlow[Keras]-CNN和OpenCV-PyTorch-CN。先做单机Windows基本功能实现,包括实时摄像或图片人脸方式;再转入Windows+Hadoop+Spark简易计算机集群环境做功能实现,以提升模型训练功效。方案和基础代码的形成

以低技术门槛[常用环境、工具、人工智能AI编程手段,在Windows下用OpenCV+CNN实现人脸识别,两种类型库使用展现:OpenCV-TensorFlow[Keras]-CNN和OpenCV-PyTorch-CN。先做单机Windows基本功能实现,包括实时摄像或图片人脸方式;再转入Windows+Hadoop+Spark简易计算机集群环境做功能实现,以提升模型训练功效。方案和基础代码的形成借力了AI工具:IMA-DeepSeek。AI应用过程涵盖数据准备、模型的训练/评估/测试。
涉及的Windows+Hadoop+Spark简易计算机集群构造,可参考本人的相关博文。
1 单机Windows基本功能实现
实时摄像或图片人脸识别,Windows+Python3.11支撑。
1.1 OpenCV+TensorFlow[Keras]+CNN
这里重点处理了Keras并入TensorFlow后的TensorFlow-Keras简易应用。
缺陷:由于TensorFlow-Keras预测函数固定可信度从大到小的排序,总是认为是第一类型人。
1.1.1 IMA-DS助力
咨询提示词:使用OpenCV-keras-CNN实现WINDOWS下的简单人脸识别,人脸图片集在E:/bImgIdtfct/imgLibs下[jpg文件]。给出一个文件实现的完整PYTHON编码。
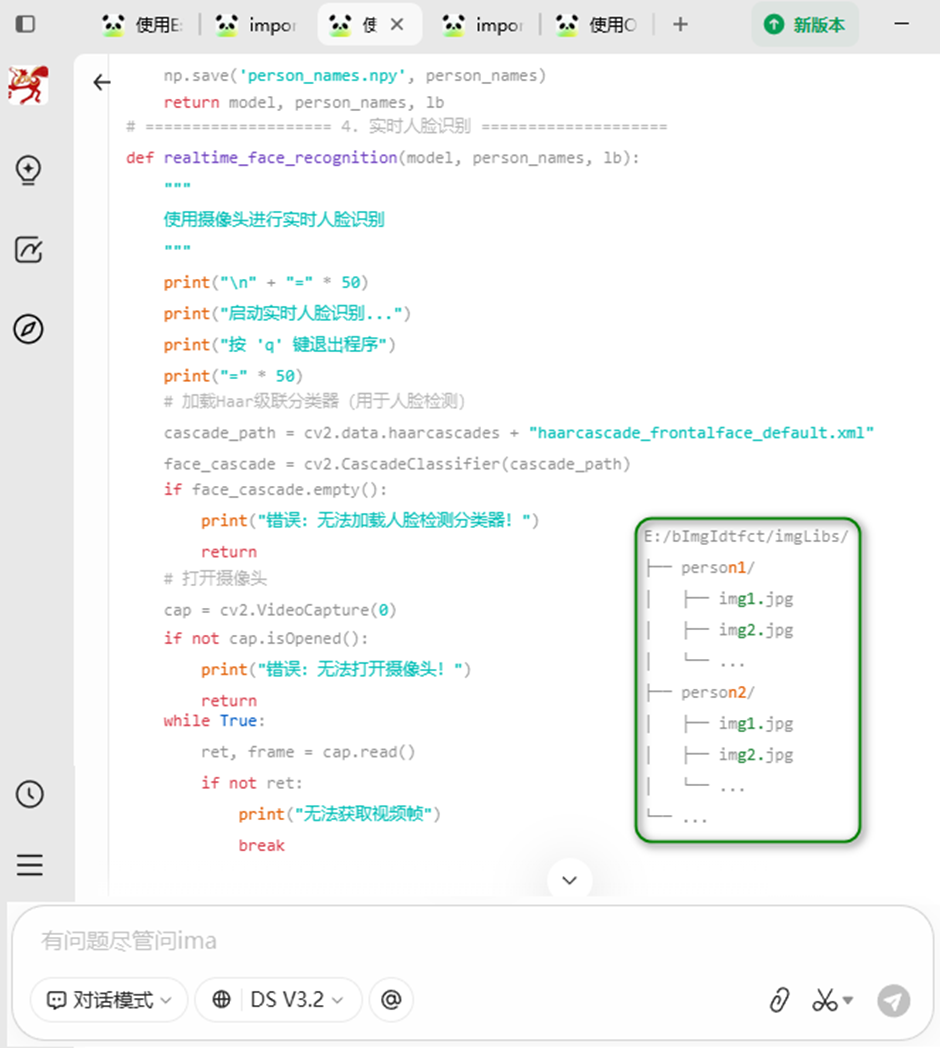
方案规划
A. 图片集目录结构
E:/bImgIdtfct/imgLibs/
├── person1/
│ ├── 001.jpg
│ ├── 002.jpg
│ └── ...
├── person2/
│ ├── 001.jpg
│ └── ...
└── ...
每个子文件夹代表一个需要识别的人物,文件夹名称将作为识别结果的标签。
B. 运行环境准备:pip install tensorflow keras opencv-python numpy scikit-learn
C. 运行程序
直接运行该Python文件,程序会提供交互式菜单:
首次运行:自动检测到无模型,进入训练模式
之后运行:可选择加载已有模型或重新训练
D. 关键功能说明
数据预处理:
- 将图片统一调整为64x64大小,并进行归一化
- 采用等比例缩放+填充的方式,保持图像不变形
CNN模型结构:
- 三层卷积层(32→64→128个滤波器)
- 三层最大池化层
- 三层Flatten展平层
- 一层全连接层(256个神经元)+ Dropout
- Softmax输出层
实时识别:
- 使用OpenCV的Haar级联分类器检测人脸
- 检测到人脸后送入CNN模型进行识别
- 显示识别结果和置信度
1.1.2 编码实现
"""
基于OpenCV + Keras + CNN的人脸识别系统,适用平台:Windows,图片路径:E:/bImgIdtfct/imgLibs
"""
import os, cv2, warnings
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from keras.optimizers import SGD
from keras.utils import to_categorical
from keras.models import load_model
warnings.filterwarnings('ignore')
# ==================== 配置参数 ====================
IMAGE_PATH = "E:/bImgIdtfct/imgLibs" # 人脸图片集路径
IMAGE_SIZE = 64 # 图片统一大小(64x64)
BATCH_SIZE = 20; EPOCHS = 50
MODEL_PATH = "face_recognition_model.h5" # 模型保存路径
TEST_SIZE = 0.2 # 测试集比例
# ==================== 1. 数据加载与预处理 ====================
def resize_with_padding(image, target_size=IMAGE_SIZE):
""" 将图片等比例缩放并填充为正方形,保持图像不变形 """
h, w = image.shape[:2]; longest_edge = max(h, w)
top = (longest_edge - h) // 2 # 计算填充
bottom = longest_edge - h - top
left = (longest_edge - w) // 2
right = longest_edge - w - left
padded = cv2.copyMakeBorder(image, top, bottom, # 填充黑色边框
left, right, cv2.BORDER_CONSTANT, value=[0, 0, 0])
resized = cv2.resize(padded, (target_size, target_size)) # 缩放到目标大小
return resized
def load_images_from_folder(folder_path):
""" 从文件夹加载图片,每个子文件夹作为一个类别
目录结构:imgLibs/person1/xxx.jpg, imgLibs/person2/xxx.jpg
"""
images = []; labels = []; person_names = [] # 保存人物名称
for person_name in os.listdir(folder_path): # 遍历子文件夹
person_path = os.path.join(folder_path, person_name)
if not os.path.isdir(person_path): # 跳过非目录文件
continue
person_names.append(person_name)
print(f"正在加载 {person_name} 的图片...")
for img_file in os.listdir(person_path): # 遍历该人物的所有图片
if not img_file.lower().endswith(('.jpg', '.jpeg', '.png', '.bmp')):
continue
img_path = os.path.join(person_path, img_file)
img = cv2.imread(img_path)
if img is None:
print(f"警告:无法读取图片 {img_path}")
continue
img = resize_with_padding(img, IMAGE_SIZE) # 预处理:调整大小并归一化
img = img.astype(np.float32) / 255.0 # 归一化到[0,1]
images.append(img)
labels.append(person_name)
return np.array(images), np.array(labels), person_names
def preprocess_data(): # 加载并预处理所有数据
print("=" * 50); print("开始加载图片数据...")
print(f"图片路径:{IMAGE_PATH}"); print("=" * 50)
images, labels, person_names = load_images_from_folder(IMAGE_PATH) # 加载图片
if len(images) == 0:
raise ValueError("没有找到任何图片!请检查路径:{}".format(IMAGE_PATH))
print(f"\n成功加载 {len(images)} 张图片,共 {len(person_names)} 个人物")
print(f"人物列表:{person_names}")
lb = LabelBinarizer() # 标签编码(one-hot编码)
labels_encoded = lb.fit_transform(labels)
num_classes = len(person_names)
# 调整图像维度为 (samples, height, width, channels)
if len(images.shape) == 3: # 如果是灰度图
images = images.reshape(images.shape[0], IMAGE_SIZE, IMAGE_SIZE, 1)
else:
images = images.reshape(images.shape[0], IMAGE_SIZE, IMAGE_SIZE, 3)
X_train, X_test, y_train, y_test = train_test_split( # 划分训练集和测试集
images, labels_encoded, test_size=TEST_SIZE,
random_state=42,stratify=labels_encoded ) # 保持类别比例
print(f"\n训练集:{len(X_train)} 张图片")
print(f"测试集:{len(X_test)} 张图片")
print(f"类别数:{num_classes}")
return X_train, X_test, y_train, y_test, num_classes, person_names, lb
# ==================== 2. 构建CNN模型 ====================
def build_cnn_model(input_shape, num_classes): # 构建卷积神经网络模型
model = Sequential()
# 第一层卷积
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 第二层卷积
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 第三层卷积
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 展平层
model.add(Flatten())
# 全连接层
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5)) # 防止过拟合
# 输出层
model.add(Dense(num_classes, activation='softmax'))
# 编译模型
sgd = SGD(learning_rate=0.01, momentum=0.9)
model.compile( loss='sparse_categorical_crossentropy',
optimizer=sgd, metrics=['accuracy'] )
print("\n模型结构:"); model.summary()
return model
# ==================== 3. 训练模型 ====================
def train_model(): # 训练人脸识别模型
# 加载数据
X_train, X_test, y_train, y_test, num_classes, person_names, lb = preprocess_data()
# 确定输入形状
input_shape = (IMAGE_SIZE, IMAGE_SIZE, 3 if X_train.shape[3] == 3 else 1)
# 构建模型
model = build_cnn_model(input_shape, num_classes)
print("\n" + "=" * 50); print("开始训练模型...")
print(f"训练轮数:{EPOCHS},批次大小:{BATCH_SIZE}"); print("=" * 50)
# 训练模型
history = model.fit( X_train, y_train, batch_size=BATCH_SIZE,
epochs=EPOCHS, validation_data=(X_test, y_test), shuffle=True, verbose=1 )
# 评估模型
print("\n" + "=" * 50); print("模型评估结果:")
score = model.evaluate(X_test, y_test, verbose=0)
print(f"测试集损失:{score[0]:.4f}"); print(f"测试集准确率:{score[1]:.4f}")
print("=" * 50)
# 保存模型
model.save(MODEL_PATH); print(f"\n模型已保存至:{MODEL_PATH}")
# 保存类别标签
np.save('person_names.npy', person_names)
return model, person_names, lb
# ==================== 4. 实时人脸识别 ====================
def realtime_face_recognition(model, person_names, lb): # 使用摄像头进行实时人脸识别
print("\n" + "=" * 50); print("启动实时人脸识别...")
print("按 'q' 键退出程序"); print("=" * 50)
# 加载Haar级联分类器(用于人脸检测)
cascade_path = cv2.data.haarcascades + "haarcascade_frontalface_default.xml"
face_cascade = cv2.CascadeClassifier(cascade_path)
if face_cascade.empty():
print("错误:无法加载人脸检测分类器!")
return
cap = cv2.VideoCapture(0) # 打开摄像头
if not cap.isOpened():
print("错误:无法打开摄像头!")
return
while True:
ret, frame = cap.read()
if not ret:
print("无法获取视频帧"); break
# 转换为灰度图(用于人脸检测)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale( gray, # 打开摄像头
scaleFactor=1.1, minNeighbors=5, minSize=(30, 30) )
# 对检测到的每个人脸进行识别
for (x, y, w, h) in faces:
face_roi = frame[y:y+h, x:x+w] # 裁剪人脸区域
# 预处理:resize并归一化
face_roi = resize_with_padding(face_roi, IMAGE_SIZE)
face_roi = face_roi.astype(np.float32) / 255.0
# 调整维度以适应模型输入
if len(face_roi.shape) == 2: # 灰度图
face_roi = face_roi.reshape(1, IMAGE_SIZE, IMAGE_SIZE, 1)
else:
face_roi = face_roi.reshape(1, IMAGE_SIZE, IMAGE_SIZE, 3)
predictions = model.predict(face_roi, verbose=0) # 预测
predicted_class = np.argmax(predictions, axis=1)[0] # 取第一个样本
confidence = float(predictions[0, predicted_class])
# 获取人物名称
person_name = person_names[predicted_class] if predicted_class < len(person_names) else "Unknown"
# 在图像上绘制矩形框和标签
color = (0, 255, 0) if confidence > 0.7 else (0, 0, 255) # 置信度高显示绿色,低显示红色
cv2.rectangle(frame, (x, y), (x+w, y+h), color, 2)
# 显示标签和置信度
label = f"{person_name} ({confidence:.2f})"
cv2.putText(frame, label, (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 2)
cv2.imshow('Face Recognition - Press q to quit', frame) # 显示画面
if cv2.waitKey(1) & 0xFF == ord('q'): # 按 'q' 键退出
break
cap.release(); cv2.destroyAllWindows() # 释放资源
# ==================== 5. 单张图片测试 ====================
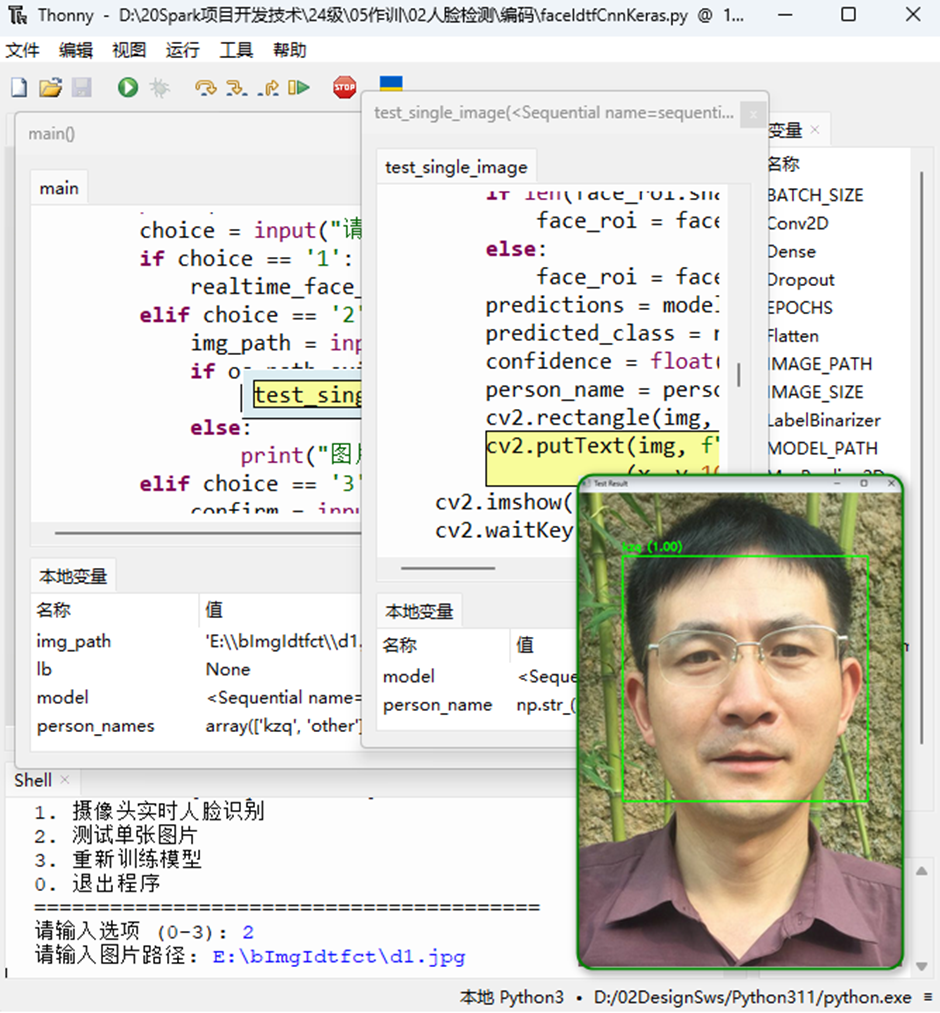
def test_single_image(model, person_names, lb, image_path): # 测试单张图片的人脸识别
img = cv2.imread(image_path)
if img is None:
print(f"无法读取图片:{image_path}")
return
# 检测人脸
cascade_path = cv2.data.haarcascades + "haarcascade_frontalface_default.xml"
face_cascade = cv2.CascadeClassifier(cascade_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.1, 5)
for (x, y, w, h) in faces:
face_roi = img[y:y+h, x:x+w]
face_roi = resize_with_padding(face_roi, IMAGE_SIZE) # 预处理
face_roi = face_roi.astype(np.float32) / 255.0
if len(face_roi.shape) == 2:
face_roi = face_roi.reshape(1, IMAGE_SIZE, IMAGE_SIZE, 1)
else:
face_roi = face_roi.reshape(1, IMAGE_SIZE, IMAGE_SIZE, 3)
predictions = model.predict(face_roi, verbose=0)
predicted_class = np.argmax(predictions, axis=1)[0] # 取第一个样本
confidence = float(predictions[0, predicted_class])
person_name = person_names[predicted_class] if predicted_class < len(person_names) else "Unknown"
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.putText(img, f"{person_name} ({confidence:.2f})",
(x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
cv2.imshow('Test Result', img)
cv2.waitKey(0); cv2.destroyAllWindows()
# ==================== 主程序入口 ====================
def main(): # 主函数:提供交互式操作菜单
print("=" * 50); print("基于OpenCV + Keras + CNN的人脸识别系统"); print("=" * 50)
model = None; person_names = None; lb = None # 检查模型是否已存在
if os.path.exists(MODEL_PATH) and os.path.exists('person_names.npy'):
print("检测到已训练的模型文件")
while True:
choice = input("是否加载已有模型?(y/n, 默认y): ").strip().lower()
if choice in ['', 'y', 'yes']:
try:
model = load_model(MODEL_PATH)
person_names = np.load('person_names.npy', allow_pickle=True)
print("模型加载成功!")
print(f"可识别的人物:{person_names}")
except Exception as e:
print(f"模型加载失败:{e}")
model = None
break
elif choice in ['n', 'no']:
break
else:
print("请输入 y 或 n")
if model is None:
print("\n需要训练新模型")
if not os.path.exists(IMAGE_PATH):
print(f"错误:图片路径 {IMAGE_PATH} 不存在!")
print("请确保目录结构为:")
print(" imgLibs/")
print(" person1/")
print(" xxx.jpg")
print(" person2/")
print(" xxx.jpg")
return
model, person_names, lb = train_model()
while True: # 交互菜单
print("\n" + "=" * 40); print("请选择操作:")
print("1. 摄像头实时人脸识别"); print("2. 测试单张图片")
print("3. 重新训练模型"); print("0. 退出程序"); print("=" * 40)
choice = input("请输入选项 (0-3): ").strip()
if choice == '1':
realtime_face_recognition(model, person_names, lb)
elif choice == '2':
img_path = input("请输入图片路径: ").strip()
if os.path.exists(img_path):
test_single_image(model, person_names, lb, img_path)
else:
print("图片路径不存在!")
elif choice == '3':
confirm = input("重新训练将覆盖现有模型,确认?(y/n): ").strip().lower()
if confirm in ['y', 'yes']:
model, person_names, lb = train_model()
elif choice == '0':
print("感谢使用,再见!")
break
else:
print("无效选项,请重新选择")
# ==================== 启动程序 ====================
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("\n程序被用户中断")
except Exception as e:
print(f"\n程序异常:{e}")
import traceback
traceback.print_exc()1.1.3 运行测试
1.2 OpenCV+PyTorch+CNN
1.2.1 IMA-DS助力
咨询提示词:使用OpenCV-Pytorch-CNN实现WINDOWS下的简单人脸识别,人脸图片集在E:/bImgIdtfct/imgLibs下[jpg文件]。给出一个文件实现的完整PYTHON编码。
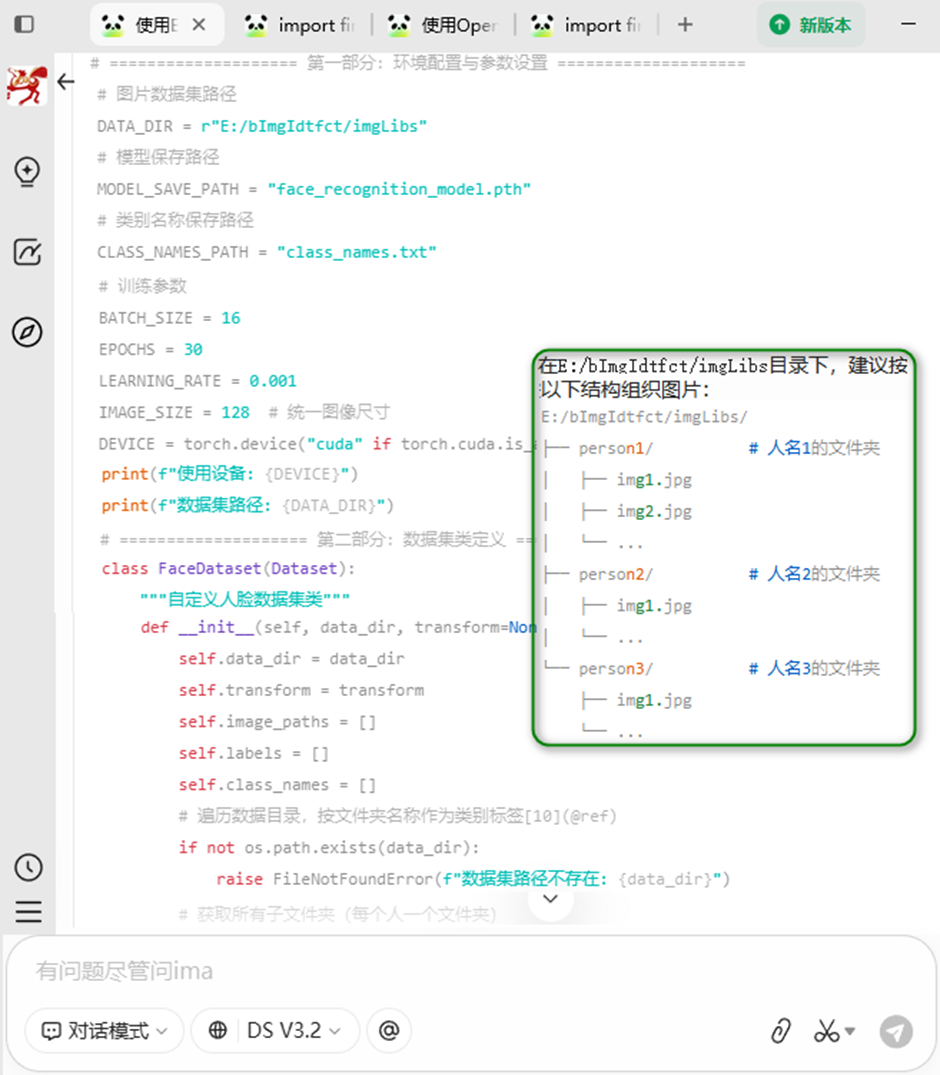
方案规划
A. 环境准备
安装必要的Python库: bash pip install torch torchvision opencv-python pillow numpy
B. 数据集组织
在E:/bImgIdtfct/imgLibs目录下,建议按以下结构组织图片:
E:/bImgIdtfct/imgLibs/
├── person1/ # 人名1的文件夹
│ ├── img1.jpg
│ ├── img2.jpg
│ └── ...
├── person2/ # 人名2的文件夹
│ ├── img1.jpg
│ └── ...
└── person3/ # 人名3的文件夹
├── img1.jpg
└── ...
如果图片都在根目录下,程序也会自动处理,但会归为一类。
C. 程序运行流程
a.首次运行:自动训练模型并保存
b.再次运行:检测到已有模型,可选择性重新训练
c.实时识别:打开摄像头进行实时人脸识别
D. 主要功能特点
• 使用OpenCV的Haar级联分类器进行人脸检测
• 使用PyTorch构建3层CNN进行特征提取和识别
• 支持GPU加速(如果可用) • 实时显示识别结果和置信度
• 支持截图保存功能
1.2.2 编码实现
"""
基于OpenCV + PyTorch + CNN的Windows人脸识别系统
功能:训练人脸识别模型,并使用摄像头或图片进行实时识别
"""
import os, cv2, torch, glob
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import numpy as np
from PIL import Image
# ==================== 第一部分:环境配置与参数设置 ====================
DATA_DIR = r"E:/bImgIdtfct/imgLibs" # 图片数据集路径
MODEL_SAVE_PATH = "face_recognition_model.pth" # 模型保存路径
CLASS_NAMES_PATH = "class_names.txt" # 类别名称保存路径
# 训练参数
BATCH_SIZE = 16; EPOCHS = 30; LEARNING_RATE = 0.001
IMAGE_SIZE = 128 # 统一图像尺寸
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {DEVICE}"); print(f"数据集路径: {DATA_DIR}")
# ==================== 第二部分:数据集类定义 ==========================
class FaceDataset(Dataset): # 自定义人脸数据集类
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir; self.transform = transform
self.image_paths = []; self.labels = []; self.class_names = []
# 遍历数据目录,按文件夹名称作为类别标签
if not os.path.exists(data_dir):
raise FileNotFoundError(f"数据集路径不存在: {data_dir}")
# 获取所有子文件夹(每个人一个文件夹)
person_dirs = [d for d in os.listdir(data_dir) if os.path.isdir(os.path.join(data_dir, d))]
if len(person_dirs) == 0: # 若无子文件夹,尝试直接读取所有jpg文件
print("未发现子文件夹,尝试直接读取jpg文件...")
jpg_files = glob.glob(os.path.join(data_dir, "*.jpg"))
if len(jpg_files) == 0:
jpg_files = glob.glob(os.path.join(data_dir, "*.png"))
if len(jpg_files) == 0:
raise ValueError(f"在 {data_dir} 下未找到任何图片文件")
self.class_names = ["unknown"]
for img_path in jpg_files:
self.image_paths.append(img_path)
self.labels.append(0) # 所有图片归为一类
else: # 按文件夹分类
for label, person_name in enumerate(person_dirs):
person_dir = os.path.join(data_dir, person_name)
img_extensions = ["*.jpg", "*.jpeg", "*.png", "*.bmp"] # 支持jpg和png格式
for ext in img_extensions:
for img_path in glob.glob(os.path.join(person_dir, ext)):
self.image_paths.append(img_path); self.labels.append(label)
self.class_names.append(person_name)
print(f"加载了 {len(self.image_paths)} 张图片,共 {len(self.class_names)} 个类别")
print(f"类别: {self.class_names}")
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
try:
image = Image.open(img_path).convert('RGB') # 使用PIL读取图像,更兼容
except Exception as e:
print(f"读取图片失败: {img_path}, 错误: {e}")
image = Image.new('RGB', (IMAGE_SIZE, IMAGE_SIZE), (0, 0, 0)) # 返回一个黑色图像作为替代
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, label
# ==================== 第三部分:CNN模型定义 ==========================
class FaceCNN(nn.Module): # 用于人脸识别的卷积神经网络模型, 包含3个卷积块和2个全连接层
def __init__(self, num_classes):
super(FaceCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1) # 卷积层1: 3 -> 32
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) # 卷积层2: 32 -> 64
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1) # 卷积层3: 64 -> 128
self.bn3 = nn.BatchNorm2d(128)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.dropout = nn.Dropout(0.5)
# 计算全连接层输入维度[经过3次池化,图像尺寸从128 -> 64 -> 32 -> 16]
self.fc_input_size = 128 * 16 * 16
self.fc1 = nn.Linear(self.fc_input_size, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, num_classes)
def forward(self, x):
x = self.pool(torch.relu(self.bn1(self.conv1(x)))) # 卷积块1
x = self.pool(torch.relu(self.bn2(self.conv2(x)))) # 卷积块2
x = self.pool(torch.relu(self.bn3(self.conv3(x)))) # 卷积块3
x = x.view(x.size(0), -1) # 展平
x = torch.relu(self.fc1(x)) # 全连接层
x = self.dropout(x)
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# ==================== 第四部分:训练函数 ==========================
def train_model(model, train_loader, criterion, optimizer, num_epochs): # 训练模型
model.train(); print("开始训练...")
for epoch in range(num_epochs):
running_loss = 0.0; correct = 0; total = 0
for i, (images, labels) in enumerate(train_loader):
images = images.to(DEVICE); labels = labels.to(DEVICE)
optimizer.zero_grad() # 清零梯度
outputs = model(images) # 前向传播
loss = criterion(outputs, labels)
loss.backward() # 反向传播
optimizer.step()
running_loss += loss.item() # 统计
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 每10个批次打印一次
if (i + 1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], '
f'Loss: {loss.item():.4f}')
epoch_loss = running_loss / len(train_loader)
epoch_acc = 100 * correct / total
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {epoch_loss:.4f}, Accuracy: {epoch_acc:.2f}%')
print("训练完成!")
return model
# ==================== 第五部分:人脸检测与识别函数 =====================
def detect_faces_opencv(frame): # 使用OpenCV Haar级联检测人脸,返回人脸区域列表#
# 加载预训练的人脸检测模型
face_cascade_path = cv2.data.haarcascades + 'haarcascade_frontalface_default.xml'
face_cascade = cv2.CascadeClassifier(face_cascade_path)
if face_cascade.empty():
print("Error: 无法加载人脸检测模型")
return []
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转换为灰度图
# 检测人脸
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
return faces
def recognize_face(model, face_img, class_names, transform): # 识别单张人脸
model.eval()
with torch.no_grad():
face_img = transform(face_img) # 预处理
face_img = face_img.unsqueeze(0).to(DEVICE)
outputs = model(face_img) # 预测
_, predicted = torch.max(outputs.data, 1)
probabilities = torch.nn.functional.softmax(outputs, dim=1)
confidence = torch.max(probabilities).item()
predicted_class = predicted.item()
if predicted_class < len(class_names):
name = class_names[predicted_class]
else:
name = "Unknown"
return name, confidence
# ==================== 第六部分:主程序 ============================
def main(): # 主函数:训练模型并进行实时人脸识别
# 1. 准备数据
print("=" * 50); print("第一步:准备数据"); print("=" * 50)
transform = transforms.Compose([ # 定义数据预处理
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)), transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ])
try: # 创建数据集
dataset = FaceDataset(DATA_DIR, transform=transform)
except Exception as e:
print(f"创建数据集失败: {e}")
return
if len(dataset) == 0: # 检查是否有足够的样本
print("错误:数据集中没有图片,请检查路径")
return
train_size = int(0.8 * len(dataset)) # 划分训练集和验证集[80%训练,20%验证]
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(
dataset, [train_size, val_size] )
train_loader = DataLoader( train_dataset, # 创建数据加载器
batch_size=BATCH_SIZE, shuffle=True, num_workers=0 ) # Windows下建议设为0
val_loader = DataLoader( val_dataset, batch_size=BATCH_SIZE,
shuffle=False, num_workers=0 )
# 2. 检查是否已有训练好的模型
model_trained = False
if os.path.exists(MODEL_SAVE_PATH) and os.path.exists(CLASS_NAMES_PATH):
print(f"发现已训练的模型: {MODEL_SAVE_PATH}")
print("是否重新训练?(y/n,默认n): ", end="")
choice = input().strip().lower()
if choice == 'y':
model_trained = False
else:
model_trained = True
if not model_trained:
# 3. 构建模型
print("=" * 50); print("第二步:构建CNN模型"); print("=" * 50)
num_classes = len(dataset.class_names)
model = FaceCNN(num_classes).to(DEVICE)
print(f"模型结构:\n{model}"); print(f"类别数量: {num_classes}")
# 4. 训练模型
print("=" * 50); print("第三步:开始训练模型"); print("=" * 50)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
model = train_model(model, train_loader, criterion, optimizer, EPOCHS)
# 5. 保存模型和类别名称
print("=" * 50); print("第四步:保存模型"); print("=" * 50)
torch.save(model.state_dict(), MODEL_SAVE_PATH)
with open(CLASS_NAMES_PATH, 'w', encoding='utf-8') as f:
for name in dataset.class_names:
f.write(name + '\n')
print(f"模型已保存至: {MODEL_SAVE_PATH}")
print(f"类别名称已保存至: {CLASS_NAMES_PATH}")
else: # 加载已有模型
print("=" * 50); print("加载已训练的模型"); print("=" * 50)
with open(CLASS_NAMES_PATH, 'r', encoding='utf-8') as f:
class_names = [line.strip() for line in f.readlines()]
num_classes = len(class_names)
model = FaceCNN(num_classes).to(DEVICE)
model.load_state_dict(torch.load(MODEL_SAVE_PATH, map_location=DEVICE))
model.eval()
dataset = FaceDataset(DATA_DIR, transform=transform)
dataset.class_names = class_names
print(f"模型加载成功,类别: {class_names}")
# 6. 实时人脸识别
print("=" * 50); print("第五步:启动实时人脸识别")
print("按 'q' 退出,按 's' 截图保存"); print("=" * 50)
cap = cv2.VideoCapture(0) # 打开摄像头
if not cap.isOpened():
print("无法打开摄像头,尝试使用图片识别模式")
test_images = glob.glob(os.path.join(DATA_DIR, "E:/bImgIdtfct/*.jpg"))
if test_images:
for test_img in test_images:
frame = cv2.imread(test_img)
result_frame = process_frame(frame, model, dataset.class_names, transform)
cv2.imshow('show', result_frame); cv2.waitKey(0)
else:
print("未找到测试图片,程序退出")
return
while True:
ret, frame = cap.read()
if not ret:
print("无法获取摄像头画面"); break
result_frame = process_frame(frame, model, # 处理每一帧
dataset.class_names, transform)
cv2.imshow('人脸识别系统 - 按q退出', result_frame) # 显示结果
key = cv2.waitKey(1) & 0xFF # 按键处理
if key == ord('q'):
break
elif key == ord('s'):
timestamp = int(time.time())
save_path = f"capture_{timestamp}.jpg"
cv2.imwrite(save_path, result_frame)
print(f"截图已保存: {save_path}")
cap.release(); cv2.destroyAllWindows()
print("程序已退出")
def process_frame(frame, model, class_names, transform): # 处理单帧图像:检测并识别人脸
result_frame = frame.copy() # 复制图像用于绘制
faces = detect_faces_opencv(frame) # 检测人脸
for (x, y, w, h) in faces:
face_roi = frame[y:y+h, x:x+w] # 提取人脸区域
face_pil = Image.fromarray(cv2.cvtColor(face_roi, cv2.COLOR_BGR2RGB))
try: # 识别人脸
name, confidence = recognize_face(model, face_pil, class_names, transform)
except Exception as e:
name = "Error"
confidence = 0
if confidence > 0.7: # 绘制检测框和标签,根据置信度设置颜色[绿=高,红=低]
color = (0, 255, 0) # 绿色
elif confidence > 0.4:
color = (0, 255, 255) # 黄色
else:
color = (0, 0, 255) # 红色
cv2.rectangle(result_frame, (x, y), (x+w, y+h), color, 2)
label = f"{name} ({confidence:.2f})" # 显示姓名和置信度
cv2.putText(result_frame, label, (x, y-10),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 2)
cv2.putText(result_frame, "Press 'q' to quit, 's' to save", # 显示帧率信息
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 255, 255), 2)
return result_frame
# ==================== 第七部分:程序入口 ====================
if __name__ == "__main__":
import time
try: # 检查必要的库
import torch, cv2
from PIL import Image
except ImportError as e:
print(f"缺少必要的库: {e}")
print("请安装: pip install torch torchvision opencv-python pillow")
exit(1)
print("人脸识别系统启动中...")
print(f"Python版本: {os.sys.version}")
print(f"OpenCV版本: {cv2.__version__}")
print(f"PyTorch版本: {torch.__version__}")
main()1.1.3 运行测试

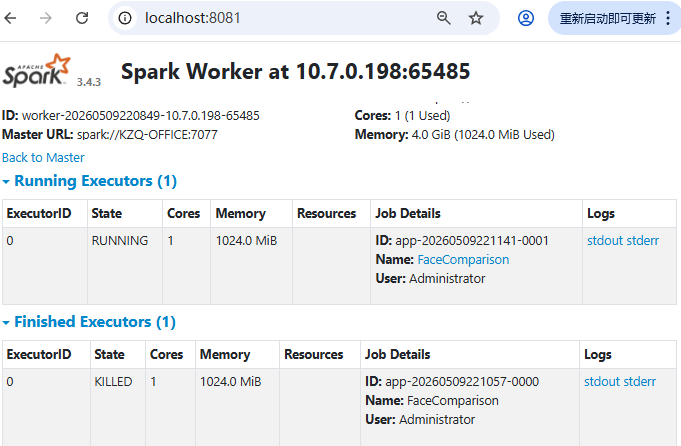
2 Windows+Hadoop+Spark简易计算机集群功能实现
图片人脸识别,Windows+Hadoop+Spark简易计算机集群环境,Python3.11+PySpark支撑。
2.1 OpenCV+TensorFlow[Keras]+CNN
2.1.1 编码实现
pip install pyspark opencv-python tensorflow scikit-learn numpy -i https://pypi.tuna.tsinghua.edu.cn/simpleimport findspark
findspark.init("E:\\spark-3.5.1-bin-hadoop3") # 指明SPARK_HOME
from pyspark import SparkContext
from pyspark.sql import SparkSession
# 初始化Spark配置和上下文
sc = SparkContext("spark://KZQ-OFFICE:7077", "FaceComparison")
#sc = SparkContext("local", "FaceComparison")
spark=SparkSession.builder.appName('rcmdSystem').getOrCreate()
spark
import os, cv2, warnings
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, Activation
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.models import load_model
warnings.filterwarnings('ignore')
# ==================== 配置参数 ====================
DATASET_PATH = r'E:/bImgIdtfct/imgLibs' # 图片数据集路径
IMAGE_SIZE = 64 # 图片尺寸(64x64)
BATCH_SIZE = 20 # 批次大小
EPOCHS = 50 # 训练轮数
MODEL_PATH = 'face_recognition_model.h5' # 模型保存路径
# ==================== 第一步:图片预处理 ====================
def resize_image(image, height=IMAGE_SIZE, width=IMAGE_SIZE):
""" 将图片调整为正方形并缩放到指定尺寸, 使用黑色填充保持宽高比"""
top, bottom, left, right = (0, 0, 0, 0)
h, w, _ = image.shape; longest_edge = max(h, w)
if h < longest_edge:
dh = longest_edge - h; top = dh // 2; bottom = dh - top
elif w < longest_edge:
dw = longest_edge - w; left = dw // 2; right = dw - left
else:
pass
BLACK = [0, 0, 0]
constant = cv2.copyMakeBorder(image, top, bottom, left, right,
cv2.BORDER_CONSTANT, value=BLACK)
return cv2.resize(constant, (height, width))
def preprocess_image(image_path): #预处理单张图片:读取 -> 调整大小 -> 归一化
image = cv2.imread(image_path)
if image is None:
return None
image = resize_image(image)
image = image.astype(np.float32) / 255.0 # 归一化到[0,1]
return image
# ==================== 第二步:加载数据集 ====================
def load_dataset(data_path):
"""从指定路径加载人脸数据集,期望目录结构:数据集根目录/人物姓名/图片.jpg"""
images = []; labels = []
# 检查数据集路径是否存在
if not os.path.exists(data_path):
raise FileNotFoundError(f"数据集路径不存在: {data_path}")
# 遍历所有人物文件夹
person_folders = [f for f in os.listdir(data_path)
if os.path.isdir(os.path.join(data_path, f))]
if len(person_folders) == 0:
raise ValueError("未找到任何人物子文件夹,请确保每个子文件夹代表一个人物")
print(f"发现 {len(person_folders)} 个人物文件夹")
for person_name in person_folders:
person_path = os.path.join(data_path, person_name)
image_files = [f for f in os.listdir(person_path)
if f.lower().endswith('.jpg')]
print(f" 加载 {person_name}: {len(image_files)} 张图片")
for img_file in image_files:
img_path = os.path.join(person_path, img_file)
processed_img = preprocess_image(img_path)
if processed_img is not None:
images.append(processed_img); labels.append(person_name)
if len(images) == 0:
raise ValueError("未加载到任何有效图片,请检查数据集")
return np.array(images), np.array(labels)
# ==================== 第三步:构建CNN模型 ====================
def build_cnn_model(num_classes): # 构建卷积神经网络模型[架构:卷积层+池化层+Dropout+全连接层]
model = Sequential()
# 第一层卷积:32个3x3滤波器
model.add(Conv2D(32, (3, 3), padding='same', input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3)))
model.add(Activation('relu')); model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu')); model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 第二层卷积:64个3x3滤波器
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu')); model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu')); model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 第三层卷积:128个3x3滤波器
model.add(Conv2D(128, (3, 3), padding='same'))
model.add(Activation('relu')); model.add(Conv2D(128, (3, 3)))
model.add(Activation('relu')); model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 全连接层
model.add(Flatten()); model.add(Dense(512))
model.add(Activation('relu')); model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
# 使用Adam优化器,学习率为0.0001
optimizer = Adam(learning_rate=0.0001)
model.compile(optimizer=optimizer,
loss='categorical_crossentropy', metrics=['accuracy'])
return model
# ==================== 第四步:训练模型 ====================
def train_model(X_train, y_train, X_val, y_val): # 训练CNN模型
num_classes = y_train.shape
model = build_cnn_model(num_classes)
print("\n模型结构:")
model.summary()
print(f"\n开始训练,共 {EPOCHS} 轮...")
history = model.fit( X_train, y_train, batch_size=BATCH_SIZE,
epochs=EPOCHS, validation_data=(X_val, y_val), shuffle=True, verbose=1 )
model.save(MODEL_PATH) # 保存模型
print(f"模型已保存至: {MODEL_PATH}")
return model, history
# ==================== 第五步:识别指定图片 ====================
def recognize_face(model, label_encoder, image_path): # 识别指定图片中的人脸
# 加载人脸检测器
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# 读取图片
image = cv2.imread(image_path)
if image is None:
print(f"无法读取图片: {image_path}")
return
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 人脸检测
faces = face_cascade.detectMultiScale( gray,
scaleFactor=1.2, minNeighbors=5, minSize=(30, 30) )
if len(faces) == 0:
print("未检测到任何人脸!"); cv2.imshow('Result', image)
cv2.waitKey(0); cv2.destroyAllWindows()
return
print(f"检测到 {len(faces)} 张人脸")
# 对每个检测到的人脸进行识别
for i, (x, y, w, h) in enumerate(faces):
face_roi = image[y:y+h, x:x+w] # 裁剪人脸区域
# 预处理:调整大小并归一化
processed_face = cv2.resize(face_roi, (IMAGE_SIZE, IMAGE_SIZE))
processed_face = processed_face.astype(np.float32) / 255.0
processed_face = processed_face.reshape(1, IMAGE_SIZE, IMAGE_SIZE, 3)
# 预测
predictions = model.predict(processed_face, verbose=0)
print(f"预测结果形状: {predictions.shape}") # 例如 (1, 3)
print(f"预测结果: {predictions}") # 例如 [[0.1, 0.7, 0.2]]
predicted_class = np.argmax(predictions)
confidence = np.max(predictions)
# 获取人物名称
person_name = label_encoder.inverse_transform([predicted_class])
# 绘制边框和标签
color = (0, 255, 0) if confidence > 0.5 else (0, 0, 255)
cv2.rectangle(image, (x, y), (x+w, y+h), color, 2)
label = f"Face {i+1}: {person_name} ({confidence:.2f})"
cv2.putText(image, label, (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 2)
print(f"人脸 {i+1}: 预测为 {person_name}, 置信度: {confidence:.2f}")
# 显示结果
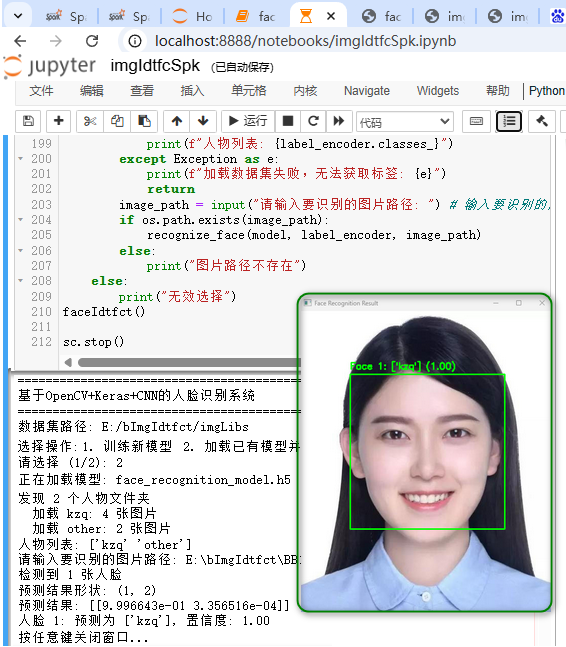
cv2.imshow('Face Recognition Result', image); print("\n按任意键关闭窗口...")
cv2.waitKey(0); cv2.destroyAllWindows()
# ==================== 主程序 ====================
def faceIdtfct(): # 主函数:训练模型或识别指定图片
print("="*50); print("基于OpenCV+Keras+CNN的人脸识别系统")
print("="*50); print(f"数据集路径: {DATASET_PATH}")
# 检查模型是否存在
model_exists = os.path.exists(MODEL_PATH)
print("\n选择操作:"); print("1. 训练新模型")
print("2. 加载已有模型并识别图片")
choice = input("请选择 (1/2): ")
if choice == '1': # 训练新模型
print("\n正在加载数据集...")
try:
images, labels = load_dataset(DATASET_PATH)
except Exception as e:
print(f"加载数据集失败: {e}")
return
print(f"\n共加载 {len(images)} 张图片,{len(np.unique(labels))} 个人物")
label_encoder = LabelEncoder() # 标签编码
integer_labels = label_encoder.fit_transform(labels)
categorical_labels = to_categorical(integer_labels)
print(f"人物列表: {label_encoder.classes_}")
X_train, X_val, y_train, y_val = train_test_split( # 划分训练集和验证集
images, categorical_labels, test_size=0.2, random_state=42, stratify=integer_labels )
print(f"训练集: {len(X_train)} 张, 验证集: {len(X_val)} 张")
model, history = train_model(X_train, y_train, X_val, y_val) # 训练模型
val_loss, val_acc = model.evaluate(X_val, y_val, verbose=0) # 评估模型
print(f"\n验证集准确率: {val_acc:.4f}")
if input("\n是否进行图片识别? (y/n): ").lower() == 'y': # 询问是否进行图片识别
image_path = input("请输入要识别的图片路径: ")
if os.path.exists(image_path):
recognize_face(model, label_encoder, image_path)
else:
print("图片路径不存在")
elif choice == '2':
if not model_exists:
print(f"模型文件 {MODEL_PATH} 不存在,请先训练模型")
return
print(f"\n正在加载模型: {MODEL_PATH}")
model = load_model(MODEL_PATH) # 加载已有模型
try: # 重新加载数据集以获取标签编码器
images, labels = load_dataset(DATASET_PATH)
label_encoder = LabelEncoder()
label_encoder.fit(labels)
print(f"人物列表: {label_encoder.classes_}")
except Exception as e:
print(f"加载数据集失败,无法获取标签: {e}")
return
image_path = input("请输入要识别的图片路径: ") # 输入要识别的图片
if os.path.exists(image_path):
recognize_face(model, label_encoder, image_path)
else:
print("图片路径不存在")
else:
print("无效选择")
faceIdtfct()
sc.stop()2.1.2 运行测试
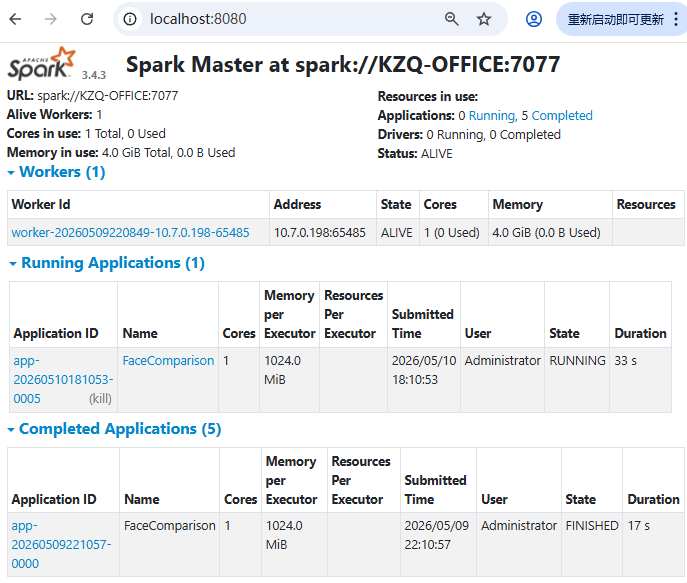
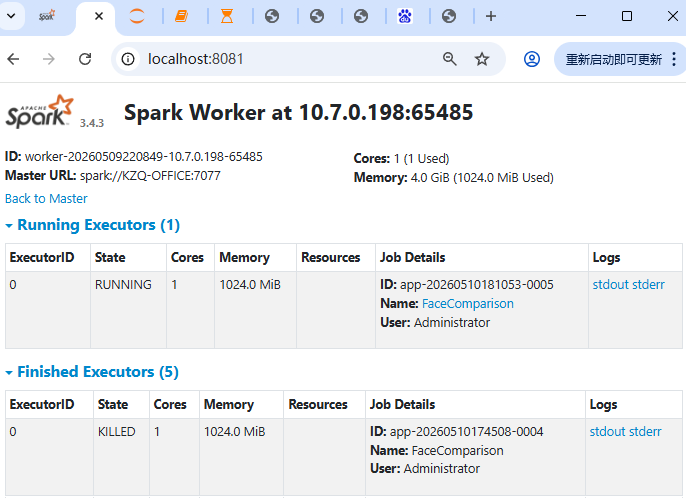
2.2 OpenCV+PyTorch+CNN
2.2.1 编码实现
pip install pyspark torch torchvision opencv-python pillow numpy -i https://pypi.tuna.tsinghua.edu.cn/simpleimport findspark
findspark.init("E:\\spark-3.5.1-bin-hadoop3") # 指明SPARK_HOME
from pyspark import SparkContext
from pyspark.sql import SparkSession
import cv2
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import transforms
from PIL import Image
# 初始化Spark配置和上下文
sc = SparkContext("spark://KZQ-OFFICE:7077", "FaceComparison")
#sc = SparkContext("local", "FaceComparison")
spark=SparkSession.builder.appName('rcmdSystem').getOrCreate()
spark
# 加载训练数据集
face_data = sc.textFile("E:/bImgIdtfct/face_data.txt")
face_labels = sc.textFile("E:/bImgIdtfct/face_labels.txt")
# 定义预处理函数,将图像转换为灰度图像并进行尺寸调整
def preprocess_image(image):
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
resized = cv2.resize(gray, (100, 100))
return resized
# 定义特征提取函数,构建CNN模型并提取特征
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# 经过 conv1 (100x100 -> 100x100, padding=1) + pool (100x100 -> 50x50)
# 展平后大小为 32 * 50 * 50
self.fc1 = nn.Linear(32 * 50 * 50, 128)
self.fc2 = nn.Linear(128, 1)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # 输入: [N, 1, 100, 100] -> [N, 32, 50, 50]
x = x.view(-1, 32 * 50 * 50) # 展平: [N, 32*50*50]
x = F.relu(self.fc1(x)) # [N, 128]
x = torch.sigmoid(self.fc2(x))
return x
def extract_cnn_features(images, labels):
model = CNN()
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
transform = transforms.Compose([transforms.ToTensor()])
images = [transform(Image.fromarray(img)) for img in images]
images = torch.stack(images)#.unsqueeze(1) # 正确形状: [N, 1, 100, 100]
# 使用传入的labels参数
labels = torch.tensor(labels, dtype=torch.float32).view(-1, 1)
for epoch in range(10):
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
features = model(images).detach().numpy()
return features
# 定义模型训练函数
def train_model(images, labels):
model = CNN()
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
transform = transforms.Compose([transforms.ToTensor()])
images = [transform(Image.fromarray(img)) for img in images]
images = torch.stack(images)#.unsqueeze(1) # 正确形状: [N, 1, 100, 100]
# 确保labels形状正确
labels = torch.tensor(labels, dtype=torch.float32).view(-1, 1)
for epoch in range(10):
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
return model
# 定义人脸识别函数
def recognize_face(test_image, model):
test_image = preprocess_image(test_image)
# 单张图像: ToTensor()后为[1, 100, 100],需要增加batch维度 -> [1, 1, 100, 100]
test_image = transforms.ToTensor()(test_image).unsqueeze(0)#.unsqueeze(0)
output = model(test_image)
label = 1 if output > 0.5 else 0
confidence = output.item()
return label, confidence
# 读取训练数据集中的图像和标签数据
images = face_data.map(lambda x: cv2.imread(x.strip())).collect()
#labels = face_labels.map(lambda x: int(x.strip())).collect()
names = face_labels.map(lambda x: x.strip()).collect()
labels=[]
label_index=0
for nm in names:
labels.append(label_index % 2) # 注意:二分类问题需要标签为0或1
label_index += 1
# 对图像进行预处理和特征提取
preprocessed_images = [preprocess_image(img) for img in images]
print("预处理后的图像数量:", len(preprocessed_images))
print("标签数量:", len(labels))
# 特征提取——传入labels参数
features = extract_cnn_features(np.array(preprocessed_images), labels)
# 训练模型
model = train_model(preprocessed_images, labels)
# 读取待识别的人脸图像
test_image = cv2.imread("E:/bImgIdtfct/a1.jpg")
if test_image is None:
print("错误:无法读取测试图像,请检查路径")
sc.stop()
exit()
#test_image = preprocess_image(test_image)
# 进行人脸识别
label, confidence = recognize_face(test_image, model)
# 输出结果
print(label, names[label], len(names), len(images))
print("Recognized label:", names[label] if label < len(names) else "Unknown")
print("Confidence:", confidence)
# 显示识别结果
if label < len(images):
cv2.imshow('Recognized Face', images[label])
cv2.waitKey(0) # 等待按键按下
cv2.destroyAllWindows()
sc.stop()2.2.2 运行测试
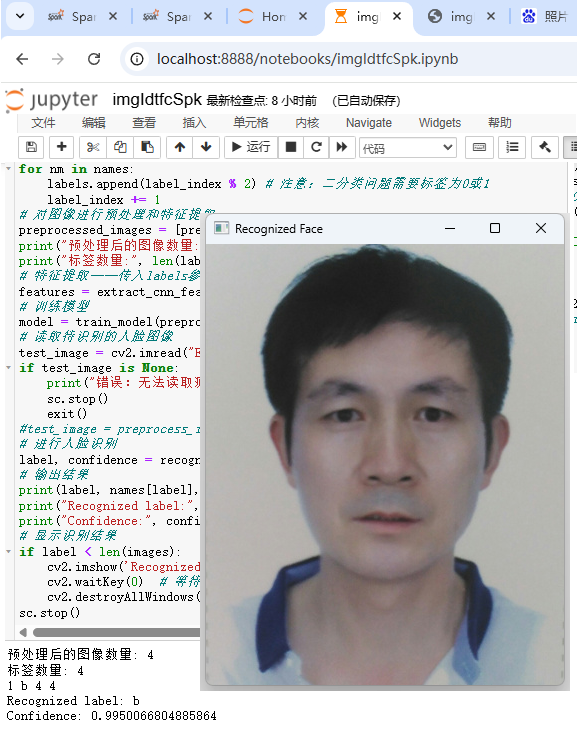
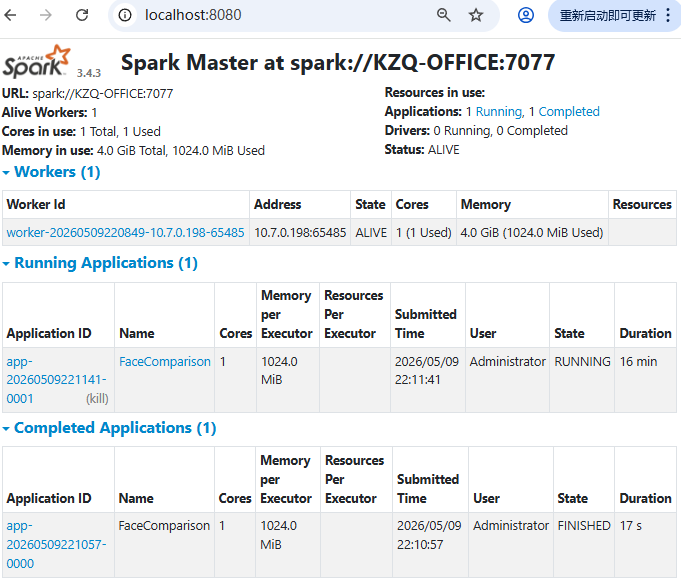
恺肇乾,2026.5.11

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)