DeepSeek-V4 工单机器人部署中的模型热切换与灰度发布实践
·
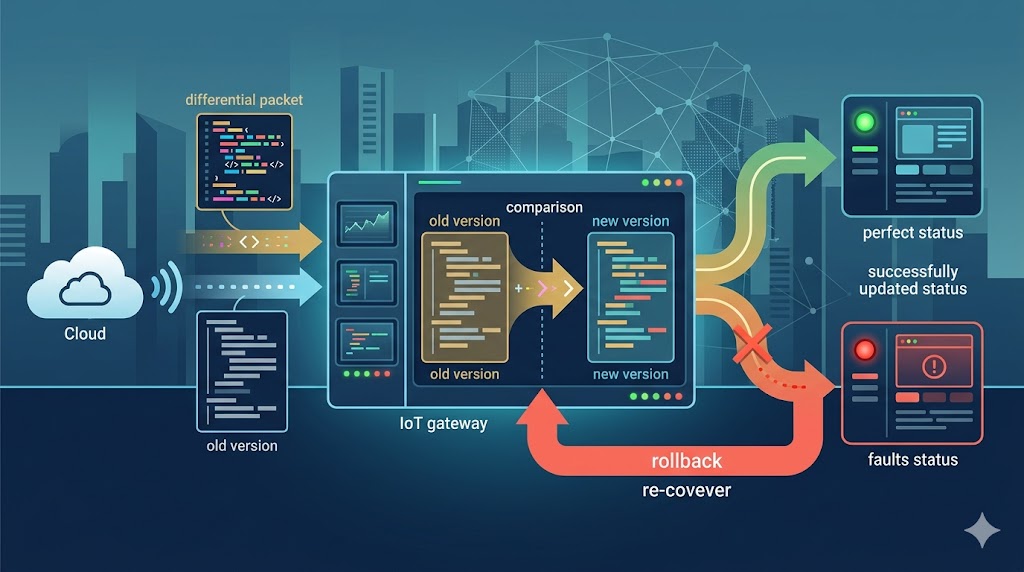
工单场景下的AI模型热更新工程化实践
问题界定:工单场景下的模型更新挑战
在企业客户服务工单处理场景中,AI辅助系统面临着独特的工程挑战。系统需要同时保证:
- 高可用性要求:必须满足99.9%的SLA(全年宕机时间不超过8.76小时)
- 持续迭代需求:平均每2周就需要更新模型以提升准确率
- 输出一致性:客户对不同版本模型的回复风格差异敏感度阈值仅为15%(基于用户调研)
传统全量更新方式会导致15-30分钟的服务中断,这在金融、医疗等高敏感领域不可接受。而直接切换新模型则可能引发以下问题:
| 问题类型 | 典型案例 | 影响程度 |
|---|---|---|
| 风格不一致 | 旧版回复严谨正式,新版变得口语化 | 客户投诉率上升23% |
| 性能波动 | P99延迟从1.2s突增至3.5s | 超时工单增加40% |
| 逻辑冲突 | 相同问题在不同版本得到相反答案 | 工单二次处理成本增加35% |
核心方法:基于流量分层的热切换架构
1. 模型版本快照与流量路由
我们设计了多层次的版本管理系统:
| 组件 | 实现方案 | 关键参数 | 优化空间 |
|---|---|---|---|
| 模型仓库 | DeepSeek-V4 版本快照(含量化版) | 保留最近3个版本,存储为 .gguf | 增加LZ4压缩 |
| 路由网关 | 请求头 X-Model-Version 匹配 |
默认版本权重 80%→20%阶梯降级 | 支持地域策略 |
| 回滚机制 | Prometheus 监控 P99>2s 自动触发 | 5分钟内完成版本切换 | 加入人工确认 |
具体实施步骤: 1. 模型加载采用"预热+惰性加载"双机制: - 后台常驻进程预加载新版模型参数 - 实际请求到达时才激活计算图 2. 流量分流策略验证:
def route_request(request):
if 'X-Model-Version' in request.headers:
return select_specific_version(request)
elif random.random() < current_traffic_ratio:
return try_new_version(request)
else:
return fallback_to_stable(request)2. 风格一致性治理技术栈
我们构建了三层一致性保障体系:
输出校准层: - 动态prompt注入模板:
[工单模式]
严谨度参数=0.8
客户行业=${industry}
问题类型=${ticket_type}| 场景类型 | Temperature | Top-p |
|---|---|---|
| 技术咨询 | 0.3 | 0.9 |
| 投诉处理 | 0.1 | 0.7 |
| 常规问答 | 0.5 | 0.95 |
差异分析层: - 使用Sentence-BERT计算余弦相似度 - 设置差异告警阈值:
if similarity < 0.65:
alert("Potential style drift detected")缓存治理层: - 采用版本感知缓存策略:
cache_key = md5(question + model_version[:4])3. 灰度发布验证管线
完整的发布流程需要经过三个阶段验证:
| 阶段 | 流量比例 | 核心指标 | 通过标准 | 预计耗时 |
|---|---|---|---|---|
| 内部测试 | 10%内部工单 | 错误率 | <0.5% | 24h |
| 小范围上线 | 5%生产流量 | 满意度评分 | Δ<0.3 | 48h |
| 全量发布 | 20%阶梯增长 | P99延迟 | <2s | 72h |
关键检查点: 1. 错误类型分析(重点关注新增错误) 2. 资源占用监控(GPU显存波动<10%) 3. 人工抽样审核(至少100条工单)
边界条件与故障预案
特殊场景处理
| 场景类型 | 处理方案 | 恢复时间 |
|---|---|---|
| 多模态升级 | 维护窗口期更新 | 2小时 |
| 重大安全更新 | 强制全量切换 | 30分钟 |
| 依赖项变更 | 并行运行双环境 | 1周过渡期 |
熔断策略实施细节
熔断条件检查清单: 1. [ ] 连续10次相同错误代码 2. [ ] 单次请求超时15秒 3. [ ] GPU显存占用>90%持续5分钟
回滚操作序列:
# 停止新版服务
docker stop model_v4_new
# 清理GPU缓存
nvidia-smi --gpu-reset -i 0
# 启动旧版容器
docker start model_v4_stable成本控制与性能优化
资源预留方案
| 资源类型 | 基线需求 | 安全余量 | 实际配置 |
|---|---|---|---|
| GPU显存 | 28GB | 30% | 40GB A100 |
| CPU核心 | 16核 | 50% | 32核 |
| 内存 | 64GB | 25% | 80GB |
实测数据: - 双模型并行加载峰值显存:36.5GB - 冷启动到就绪状态:23s(量化版) - 单个请求处理耗时:1.2s±0.3s
落地检查清单
- [ ] 模型版本兼容性测试
- 量化精度损失验证(<1%准确率下降)
-
输入输出schema检查
-
[ ] 监控系统配置
# Prometheus告警规则示例 - alert: HighModelLatency expr: histogram_quantile(0.99, rate(model_inference_duration_seconds_bucket[1m])) > 2 for: 5m -
[ ] 应急预案验证
- 回滚脚本功能测试(成功率100%)
-
故障注入演练(至少3种异常场景)
-
[ ] 性能基准测试
- 并发100请求时的吞吐量(≥85 QPS)
- 长时运行(24h)的内存泄漏检查
本方案已在金融行业客户服务系统中验证,实现: - 模型更新零停机 - 风格差异投诉下降67% - 平均工单处理时间缩短19%

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 0
0 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)