开源大模型加国产芯片:正在成形的组合拳
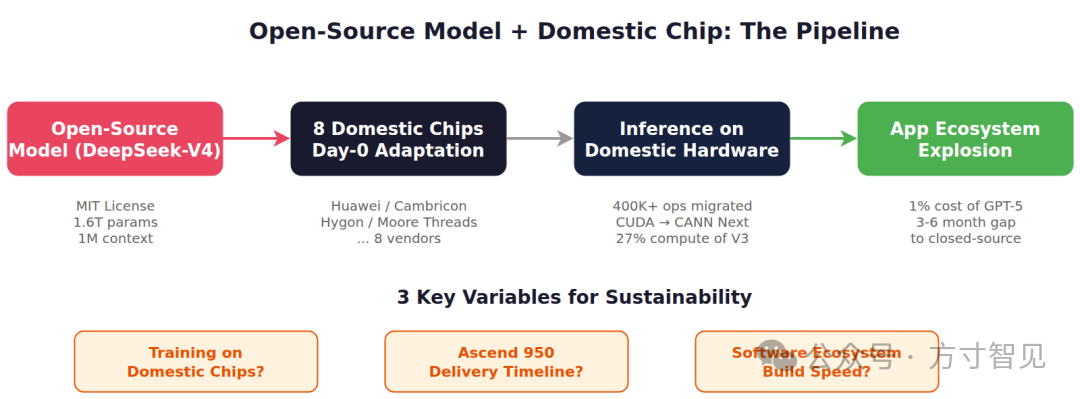
DeepSeek发布V4系列MoE模型引发国产AI芯片适配热潮。V4采用双轴稀疏架构等技术,推理效率显著提升,但训练仍依赖英伟达。8家国产芯片厂商完成推理适配,其中华为昇腾实现深度移植,其他厂商适配程度尚不明确。尽管国产芯片在推理端取得突破,但训练端仍存在明显差距。此次事件展示了“开源模型+国产芯片+性价比”的产业路径,但可持续性取决于训练国产化进度、昇腾950交付及软件生态建设。国产芯片首次在A
2026 年 4 月 24 日,DeepSeek 发布 V4 系列模型。
同一天,8 家国产 AI 芯片厂商宣布完成适配。资本市场闻风而动,5 月 6 日 A 股节后开盘,科创 50 涨 5.83%,海光信息市值突破 8000 亿。
热闹归热闹。但如果我们把视角从股价拉回到产业本身,会发现一些被忽视的事实。
V4 到底发布了什么
DeepSeek-V4 系列一次发了两个版本,都是 MoE 架构:
| 指标 | V4-Pro | V4-Flash |
|---|---|---|
| 总参数量 | 1.6T | 284B |
| 激活参数 | 49B | 13B |
| 训练数据 | 33T Token | 32T Token |
| 上下文长度 | 1M | 1M |
| 开源协议 | MIT | MIT |
从 V3 到 V4,间隔了 484 天。V4 以"预览版"姿态发布,技术报告中没有回避训练稳定性的问题。
值得注意的是推理效率的提升——官方数据称 V4 推理仅需 V3.2 的 27% 算力和 10% 显存。这不是靠堆硬件,而是靠架构创新:双轴稀疏架构、DSA 稀疏注意力、KV Cache 滑窗压缩。模型本身变聪明了,同时用更少的算力跑得更快。
8 家芯片"Day0 适配"的含金量
4 月 24 日当天,华为昇腾、寒武纪、海光信息、摩尔线程、沐曦股份、昆仑芯、平头哥真武、天数智芯先后宣布完成适配。
但"适配"这个词在芯片行业里的含义,比大多数人想象的要轻。
华为昇腾的适配是最深的。公开信息显示:V4 的对外 API 推理完全依托昇腾算力,单卡 Decode 吞吐达 1600-4700 TPS,时延 10-20ms。更关键的是,DeepSeek 耗时数月重写了 40 万+底层算子,从 CUDA 架构迁移到华为 CANN Next 软件栈。这不是"适配",是"移植"。
其他 7 家呢?寒武纪宣布基于 vLLM 完成 V4-Flash 推理,海光宣布 DCU 完成适配——但没有一家给出具体的 benchmark 数据。"完成适配"到什么程度,外界不得而知。
V4 的技术报告里有一个容易被忽略的细节:昇腾 NPU 和英伟达 GPU 第一次被并列写在硬件验证清单里。 一个国产芯片被写进大模型技术报告的硬件验证清单,这是第一次。
推理能跑 ≠ 训练能造
媒体叙事中最大的模糊地带,在于"推理"和"训练"的混用。
8 家芯片完成的都是推理适配——用模型。而 V4 的训练——造模型,预训练仍以英伟达为主。V4-Flash 的后训练和微调已在昇腾完成,但 V4-Pro 的完整训练链路还在推进中。
推理和训练对芯片的要求完全不在一个量级。推理是"按食谱做菜",计算模式相对固定;训练是"发明食谱",需要探索巨大的参数空间,对计算精度、显存带宽、分布式通信能力的要求高得多。
DeepSeek 自己也坦承,V4 的整体能力落后同期闭源对手约 3-6 个月。这 6 个月的差距,很大程度上就是算力差距。V4-Pro 的服务吞吐目前十分有限,DeepSeek 预计下半年昇腾 950 超节点批量上市后,价格才会大幅下调。
另一个被忽视的代价:40 万算子的迁移。CUDA 生态经过十几年积累,拥有数百万开发者、数万个优化算子、完善的调试工具链。从 CUDA 迁移到任何其他平台都是巨大的工程投入,而且这次只适配了华为一家。如果未来要适配寒武纪、海光、摩尔线程各自的软件栈,每一套都是一次新的迁移。
"组合拳"为什么值得关注
尽管有上述差距,这次 V4 事件之所以引发资本市场如此剧烈的反应,不只是因为技术本身,而是它展示了一条清晰的产业路径:
1. 开源模型降低了芯片适配的门槛。 以前闭源模型绑定英伟达硬件,芯片厂商连模型权重都拿不到。DeepSeek 开源后,所有芯片厂商都能拿到权重做优化。
2. 推理场景是国产芯片最现实的切入点。 推理对精度要求比训练低一个量级,FP8 甚至 INT4 量化后就能跑,这恰好是国产芯片擅长的。
3. 性价比是杀手锏。 V4 的 API 定价是 GPT-5 的 1%。能力差距 3-6 个月,成本差 100 倍,对绝大多数应用场景来说选择显而易见。
这套组合拳的核心不是"国产替代",而是"够用 + 便宜"。和当年国产手机芯片的路径一模一样——先在性价比市场站稳,再逐步向高端爬。
路径可行,但有几个变量要看
这条路的可持续性,取决于几个关键节奏:
训练端国产化推进速度。 华为昇腾已经在 V4-Flash 的后训练上有了进展,V4-Pro 的完整训练链路还在推进中。如果训练永远依赖英伟达,"组合拳"就永远是半套。
昇腾 950 超节点的交付节奏。 DeepSeek 明确说 V4-Pro 吞吐受限于高端算力,下半年昇腾 950 超节点批量上市是关键节点。交付延迟,V4 的性价比优势就落不了地。
软件生态的建设周期。 CUDA 的护城河不在硬件性能,在十几年的软件生态积累。CANN 在推理端已有进展,但训练端的算子库、调试工具、分布式训练框架,至少还需要 2-3 年的建设周期。
时间窗口在于:如果英伟达下一代芯片在 2027 年如期交付,CUDA 生态持续演进,国产芯片的追赶窗口就会收窄。反过来,如果美国对高端 GPU 的出口管制持续收紧,国产芯片反而获得了被市场"逼着用"的机会——海光信息已经证明了这一点:Intel 交期半年以上,国产 CPU 交期短+政策优惠,替代是供给侧硬推出来的。
4 月 24 日同一天,OpenAI 发布了 GPT-5.5。一条路线卷极致性能、封闭生态、高价服务;另一条路线卷极致性价比、开源模型、国产底座。两条路线的竞争才刚开始。
推理端的突破是真实的,训练端的差距也是真实的。用"摆脱英伟达依赖"描述当前状态,是对事实的过度简化。更准确的说法是:国产芯片第一次在 AI 推理这个最重要的增量市场上,找到了一条可行路径。走通还需要时间,但方向被验证了。
作者:方寸智见。芯片行业老兵,关注 AI 如何改变半导体的每一个角落。
数据来源:DeepSeek-V4 官方技术报告、华为昇腾 CANN 直播、芯东西、每日经济新闻、华尔街见闻、财联社等公开资料。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)